 AutoAI在人工智能全生命周期中自動建模
AutoAI在人工智能全生命周期中自動建模
前言:
深度學習問世以來,隨著神經網絡架構趨于固定和成熟,轉而尋找改進數據的方法,已經成了AI 研發的新出口。
AutoAI自動執行高度復雜的任務,為數據尋找并優化最好的機器學習模型、特征和模型超參數。
AutoAI在人工智能全生命周期中自動建模
AutoAI是最先進的自動化機器學習產品可以有效地分析歷史數據,創建自定義機器學習管道并對其進行排名。
它包括自動化特征工程——可擴展和增強數據的特征空間以優化模型性能。
AutoAI可以在幾分鐘內完成通常需要整個數據科學家團隊數個小時到數天才能完成的工作。自動化功能包括數據準備、模型開發、特征工程和超參數優化。
整個建模過程端到端的自動化可以顯著節省資源。AutoAI顯著提高了生產力,只需點擊幾下鼠標,即使是只有基本數據科學技能的人,也可以使用自定義數據自動選擇、訓練并調優高性能機器學習模型。
然而,專業的數據科學家可以快速迭代可能的模型和管道,并試驗最新的模型、特征工程技術和公平算法,無需從頭開始編寫管道代碼就可以完成這一切。
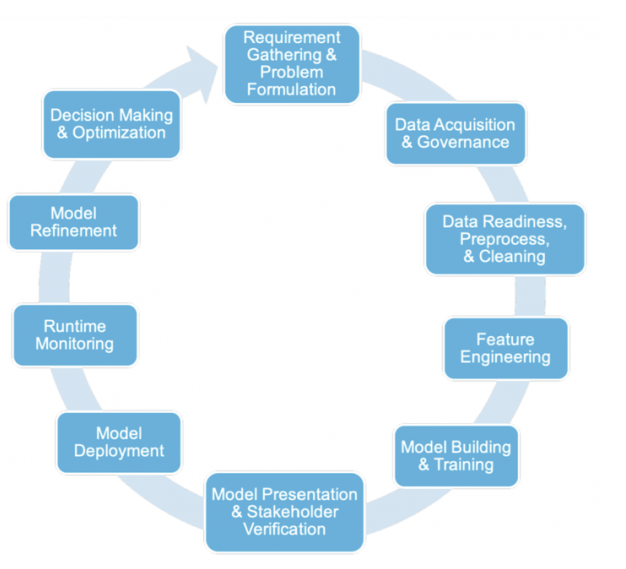
數據科學家的新語義能力
數據科學家理解了數據的語義,就有可能利用領域知識來擴展特征空間,從而提高模型準確性,這種擴展可以使用來自內部或外部數據源的補充數據來完成。
AutoAI檢測到正確的語義概念,程序就會使用這些概念廣泛搜索現有代碼、數據和文獻中可能存在的相關特征和特征工程操作。
AutoAI可以使用這些新的、語義豐富的特征來提高生成模型的準確性,并通過這些生成的特征提供可供人類閱讀的解釋。
即使沒有評估這些語義概念或者新功能的專業知識,數據科學家們還是可以試用AutoAI。但是,想要理解發現的語義概念并與之交互的數據科學家可以使用Semantic Feature Discovery(語義特征發現)可視化資源管理器來探索發現的關系。
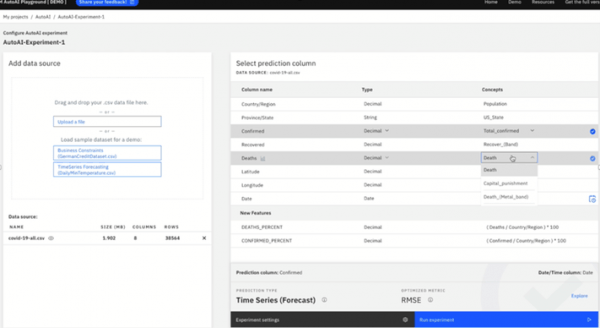
AutoAI 的三個階段
第一階段:模型設計、調參自動化
當前,很多學者都已經注意到,學術界或者工業界的優秀人才所聚焦的研發,花費太多時間用于模型結構設計以及調參,但實際上它本不應該成為研究的主要內容。有沒有一種自動化的方法,讓深度學習的網絡架構在面對一個問題的時候,能自主的演化其架構,這才是關鍵。
第二階段:簡單模型訓練的軟件化
第一階段的自動化主要面向專業的算法研究人員,第二階段的系統化則面向一般的 AI 從業人員。主要目標是在給定標注好的數據的情況下,通過可視化的操作界面實現模型的訓練。
第三階段:數據迭代自動化
在算法設計自動化的基礎上,正在發生一些變化。模型和數據到底哪一個更重要 ,在設計化的工業生產中,以模型為中心的技術研發已經轉化成以數據為中心的技術研發。
數據的迭代越來越重要
在工業化大規模發展中,大家正在慢慢地從模型為中心的生產轉化為以數據為中心。
可從兩個維度來提高它的性能,一是以模型為中心的方法,即想盡各種辦法提高模型設計的復雜度、技術含量等;
二是以數據為中心的方法,比如加數據(加數據也是有一些科學方法的,并不是加了數據后性能一定會提高)、檢查數據有沒有問題等等。
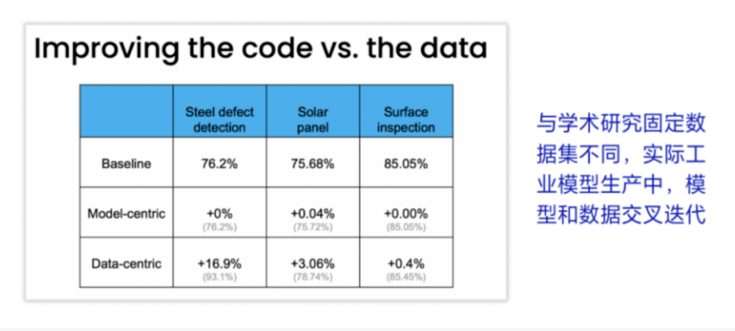
會發現,以數據為中心的方法比以模型為中心的方法能更多地提高性能。
做模型生產時也得到這樣一個結論:越到后面,數據的迭代越來越重要。因為所有模型的服務實際上是針對某一個特定場景,使用的是特定的數據。
結尾:AutoAI未來適配率極高
如今,有自動化 AI 模型生產平臺需求的,已經不僅僅是谷歌、微軟、Meta、IBM、蘋果等大公司了,我們國內就有不少房地產公司開始投入 AI。他們都有人才的需求,自動化的 AI 可以降低他們的成本。地產公司、物業公司,以及像寧德時代這樣做電池的公司,都在慢慢引入AI來解決實際問題。
AI是一個非常基礎的能力,可以提高我們做事情的效率,AI并不改變行業,但是可以提升所在行業的生產效率,所以這種影響是全方位的,已經慢慢地波及到非技術類公司了。
更不用說現在廣泛的制造業,制造過程中的很多環節都可以利用到AI的能力。如果想提高自己的國際競爭力,提升自己的生產質量,就需要AI的能力去賦能生產。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100541 -
AI
+關注
關注
87文章
30146瀏覽量
268421 -
機器學習
+關注
關注
66文章
8377瀏覽量
132411
原文標題:趨勢丨下一代 AutoAI:算法的迭代變成數據的迭代
文章出處:【微信號:World_2078,微信公眾號:AI芯天下】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是PLM產品生命周期管理系統?
PLM助力企業實現產品全生命周期管理與智能化升級
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
PLM如何推動企業實現全生命周期管理的數字化轉型
如何確保車規級芯片全生命周期的安全

半導體產業背后的“守護者”:全生命周期測試設備解析

FPGA在人工智能中的應用有哪些?
新型儲能全產業鏈、全生命周期質量提升解決方案

半導體全生命周期測試:哪些設備在默默守護你的電子產品?

鴻蒙開發組件:DataAbility的生命周期
鴻蒙開發:【PageAbility的生命周期】
設備全生命周期管理流程有哪些?

什么是設備全生命周期管理系統?

半導體測試設備大盤點:全生命周期無死角檢測

服務汽車全生命周期,Imagination詳解智能座艙解決方案






 工商網監
工商網監
評論