 eBPF安全可觀測性的前景展望
eBPF安全可觀測性的前景展望
一、eBPF安全可觀測性的前景展望
本次分享將從監控和可觀測性、eBPF安全可觀測性分析、內核安全可觀測性展望三個方面展開。
1.監控(Monitoring)vs可觀測性(Observability)
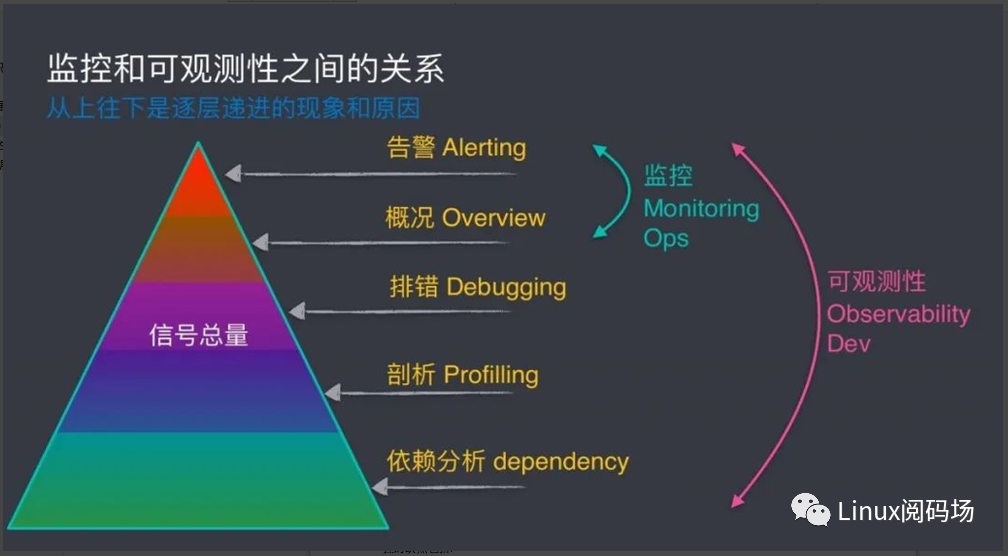
從上圖可以看到,監控只是可觀測性的冰山一角,而大部分都隱藏在水面之下的深層次問題無法簡單通過監控解決。
目前監控也開始可視化,但絕大部分都是事先預定義參數,然后事后查看日志,進行分析。監控的缺點包括:
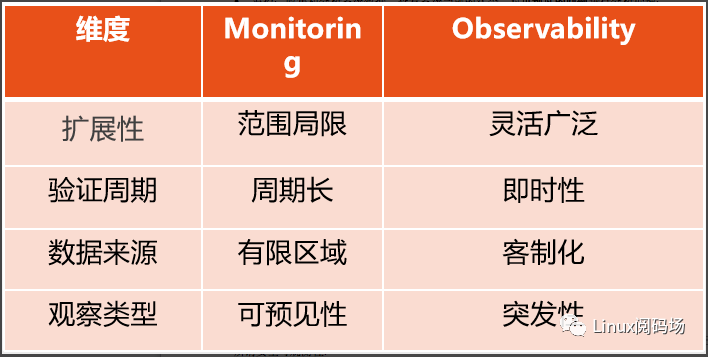
可擴展性差,需要修改代碼和編譯;驗證周期長;數據來源窄等問題。
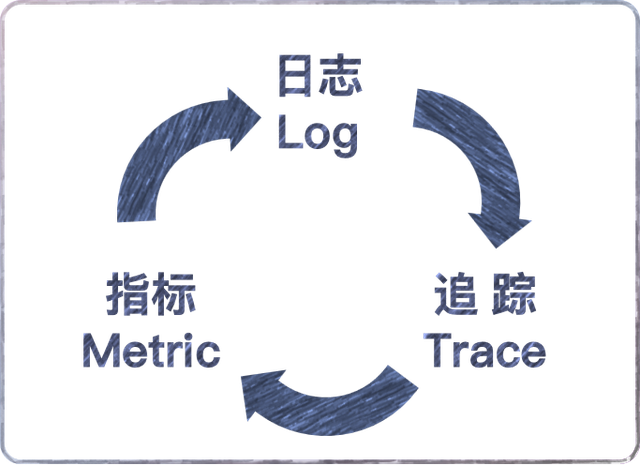
可觀測性是通過主動定制度量的搜集和內核數據聚合,包括以下三種:
Logging
實時或者事后特定事件信息
分布式服務器集群的海量數據溯源圖
離散信息整理各種異步信息
Tracing
數據源:提供數據來源
采集框架:往上對接數據源,采集解析發送數據,往下對用戶態提供接口
前端交互:對接Tracing內核框架,直接與用戶交互,負責采集配置和數據分析
Metrics(度量)這也是可觀測性與監控最主要的區別
系統中某一類信息的統計聚合,比如CPU、內存、網絡吞吐、硬盤 I/O、硬盤使用等情況。當度量值觸發異常閾值時,系統可以發出告警信息或主動處理,比如殺死或隔離進程;
主要目的:監控(Monitoring)和預警(Alert)
總結一下監控和觀測的區別:
監控:收集和分析系統數據,查看系統當前的狀態,對可預見的問題進行分析處理;
可觀測性:通過觀察系統并衡量系統的內部狀態,從其外部輸出的數據推斷出來系統此時處于某種程度的度量,特別是我們所關心的場景和事件;
2.eBPF安全可觀測性分析
先簡單定義下什么是安全:安全指的是某種對象或者對象屬性不受威脅的狀態。
所謂安全可觀測性:
通過觀測整個系統,從低級別的內核可見性到跟蹤文件訪問、網絡活動或能力(capability)變化,一直到應用層,涵蓋了諸如對易受攻擊的共享庫的函數調用、跟蹤進程執行或解析發出的 HTTP 請求。因此這里的安全是整體的概念。
提供對各種內核子系統的可觀測性,涵蓋了命名空間逃逸、Capabilities 和特權升級、文件系統和數據訪問、HTTP、DNS、TLS 和 TCP 等協議的網絡活動,以及系統調用層的事件,以審計系統調用和跟蹤進程執行。
從日志、跟蹤及度量三個維度檢查相關輸出,進而來衡量系統內部安全狀態的能?。
eBPF的安全可觀測性表現為對內核來說其存在感極低但觀測能力卻異常強大(藥效好,副作用小):
程序沙箱化:通過eBPF驗證器保護內核穩定運行。
侵入性低:無須修改內核代碼,且無須停止程序運行。
透明化:從內核中透明搜集數據,保證企業最重要的數據資產。
可配置:Cilium等自定義乃至自動化配置策略,更新靈活性高,過濾條件豐富。
快速檢測:在內核中直接處理各種事件,不需要回傳用戶態,使得異常檢測方便和快速。
其中的程序沙箱話離不開更安全的eBPF Verifier(其中最重要的是邊界檢查):
擁有加載eBPF程序的流程所需的特權
無crash或其他異常導致系統崩潰的情況
程序可以正常結束,無死循環
檢查內存越界
檢查寄存器溢出
eBPF的可觀測性應用場景主要有以下三類:
1.云原生容器的安全可觀測性
這也是傳統BPF基于網絡應用場景的進一步發展:
隨著云網邊端的急速發展,人們的目光越發的聚焦在目前最火熱的云原生場景上。Falco、Tracee、Tetragon、Datadog-agent、KubeArmor是現階段云原生場景下比較流行的幾款運行時防護方案。
這些方案主要是基于eBPF掛載內核函數并編寫過濾策略,在內核層出現異常攻擊時觸發預置的策略,無需再返回用戶層而直接發出告警甚至阻斷。
以預防的方式在整個操作系統中執行安全策略,而不是對事件異步地做出反應。除了能夠為多個層級的訪問控制指定允許列表外,還能夠自動檢測特權和 Capabilities 升級或命名空間提權(容器逃逸),并自動終止受影響的進程。
安全策略可以通過 Kubernetes(CRD)、JSON API 或 Open Policy Agent(OPA)等系統注入。
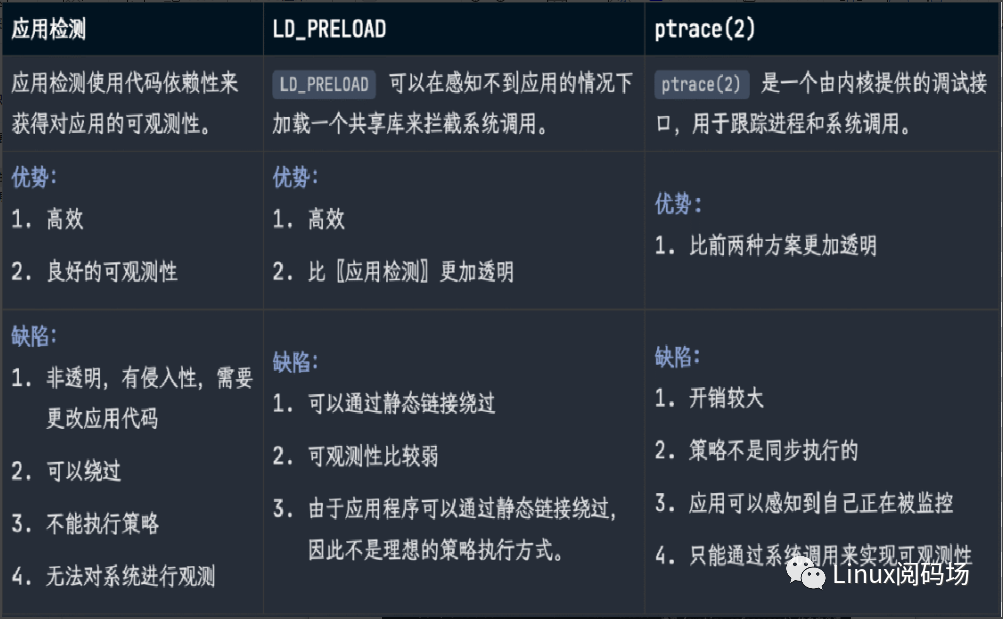
2.應用層安全可觀測方案
3.內核層安全可觀測方案

3.內核安全可觀測性展望
下面從傳統內核安全、Android內核安全、KRSI等幾個方面展開討論。
傳統內核安全方案存在著諸多需要解決的問題:
正如Linus Torvalds曾經說過的,大多數安全問題都是bug造成的,而bug又是軟件開發過程的一部分,是軟件就有bug。
至于是安全還是非安全漏洞bug,內核社區的做法就是盡可能多的測試,找出更多潛在漏洞這樣近似于黑名單的做法。
內核代碼提交走的流程比較繁瑣,應用到具體內核版本上,又存在周期長以及版本適配的問題,所以導致內核在安全方面發展的速度明顯慢于其他模塊。同時,隨著智能化、數字化、云化的飛速發展,全球基于Linux系統的設備數以百億計,而這些設備的安全保障主要取決于主線內核的安全性和健壯性,當某一內核LTS版本被發有漏洞,這樣相關的機器都會面臨被攻破利用的局面,損失難以估量。
嵌入式領域的Android內核安全:
現如今,世界上越來越多的智能終端包括手機、TV、SmartBox和IoT、汽車、多媒體設備等等,均深度使用Android系統,而Android的底層正是Linux內核,這也讓Linux內核的安全性對Android產生重大影響。
由于歷史原因,Google在Android內核開源的問題上,理念和Linux內核社區不是十分的匹配,這也導致了Android對內核做了大量的針對性修改,但是無法合入到Upstream上。這也導致了Android內核在安全側有部分不同于Linux內核,側重點也存在不同。
在操作系統級別,Android平臺不僅提供Linux內核的安全功能,而且還提供安全的進程間通信 (IPC)機制,以便在不同進程中運行的應用之間安全通信。操作系統級別的這些安全功能旨在確保即使是原生代碼也要受應用沙盒的限制。無論相應代碼是自帶應用行為導致的結果,還是利用應用漏洞導致的結果,系統都能防止違規應用危害其他應用、Android 系統或設備本身。
Android內核安全特性:
HWAddressSanitizer(硬件支持的內存檢測工具)
KASAN
Top-byte Ignore
KCFI(流控完整性校驗)
ShadowCallStack(堆棧保護)
目前工作的關注重點是內核安全可觀測性利器-KRSI:
KRSI (Kernel Runtime Security Instrumentation)的原型通過LSM (Linux security module)形式實現,可以將eBPF program掛載到kernel的security hook(安全掛鉤點)上。內核的安全性主要包括兩個方面:Signals和Mitigations,這兩者密不可分。
Signals:意味著系統有一些異常活動的跡象、事件
Mitigations:在檢測到異常行為之后所采取的告警或阻斷措施
KRSI基于LSM來實現,這也就使其能夠進行訪問控制策略的決策,但這不是KRSI的工作重心,主要是為了全面監視系統行為,以便檢測攻擊(最重要的應用場景,但目前主要還是只做檢測居多,因為貿然做阻斷處理可能會比較危險)。從這種角度來看,KRSI可以說是內核審計機制的擴展,使用eBPF來提供比目前內核審計子系統更高級別的可配置性。
KRSI工具可以看作是eBPF和LSM的強強聯合:KRSI = eBPF + LSM
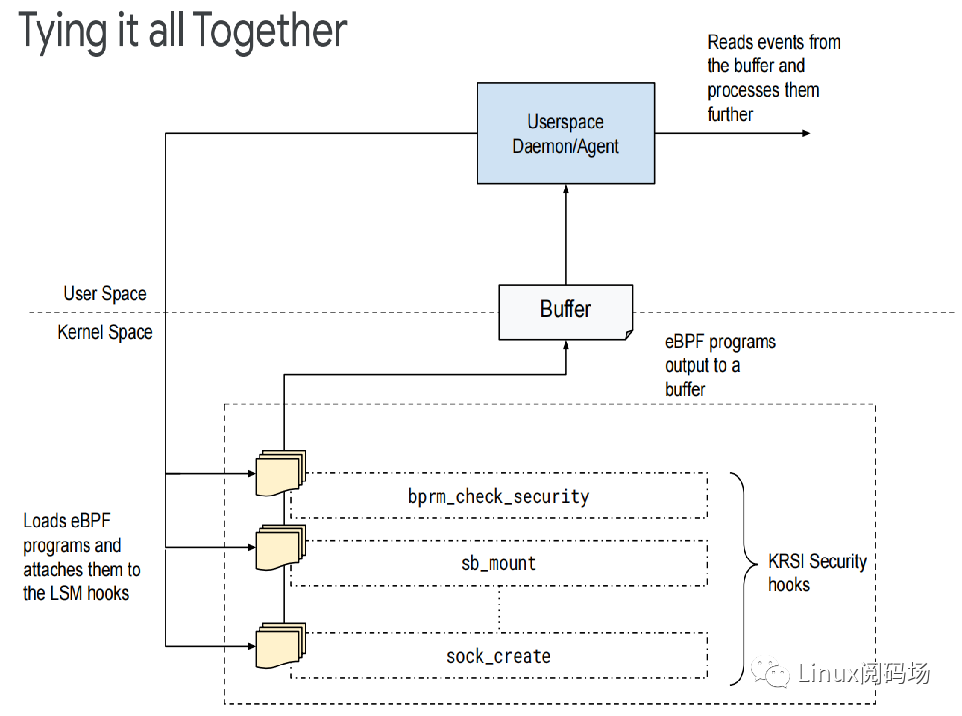
1.KRSI允許適當的特權用戶將BPF程序掛載到LSM子系統提供的數百個鉤子中的任何一個上面。
2.為了簡化這個步驟,KRSI在/sys/kernel/security/bpf下面導出了一個新的文件系統層次結構——每個鉤子對應一個文件。
3.可以使用bpf()系統調用將BPF程序(新的BPF_PROG_TYPE_LSM 類型)掛載到這些鉤子上,并且可以有多個程序掛載到任何給定的鉤子。
4.每當觸發一個安全鉤子時,將依次調用所有掛載的BPF程序,只要任一BPF程序返回錯誤狀態,那么請求的操作將被拒絕。
5.KRSI能夠從函數級別做阻斷操作,相比進程具有更細粒度,危險程度也會小得多。
后續計劃
內核安全問題是個非常復雜的話題,牽一發而動全身,防御機制、加固配置、漏洞利用等等挑戰性的技術。在進行加固防御的過程中,又會產生性能或者系統穩定性相關的影響。
從eBPF + LSM的角度可以更加可視化、數據豐富的觀測內核安全情況,進而在內核Livepatch、漏洞檢測以及防御提權相關攻擊手段上,有著進一步的發展空間。
二、Linux進程調度與性能優化
本次分享將從進程調度概念、進程調度框架、進程調度算法和性能優化四個方面展開。
1.進程調度概念
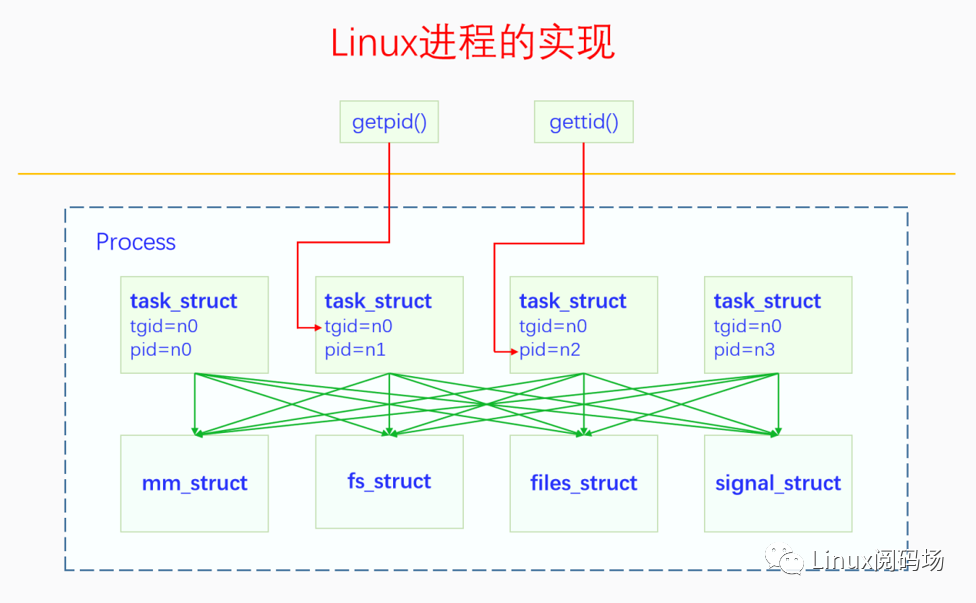
最初的Linux只有進程,task_struct相當于進程控制塊(PCB),后來出現了線程,task_struct就開始對應線程。Linux沒有從概念上直接區分兩者,如果不同的task_struct間共享資源,它們屬于同一進程中的線程,否則就屬于不同的進程。
這里要注意,用戶態中的進程和線程與內核態間的映射關系:用戶態函數getpid()得到的是內核中的tgid;用戶態函數gettid()得到的是內核中的pid。
Posix支持一級調度和二級調度兩種模式,二級調度會先調度進程,然后才是進程中的線程。而Linux選擇的是直接調度線程的一級調度,效率會比二級調度高。
Linux進程調度體系如下圖:
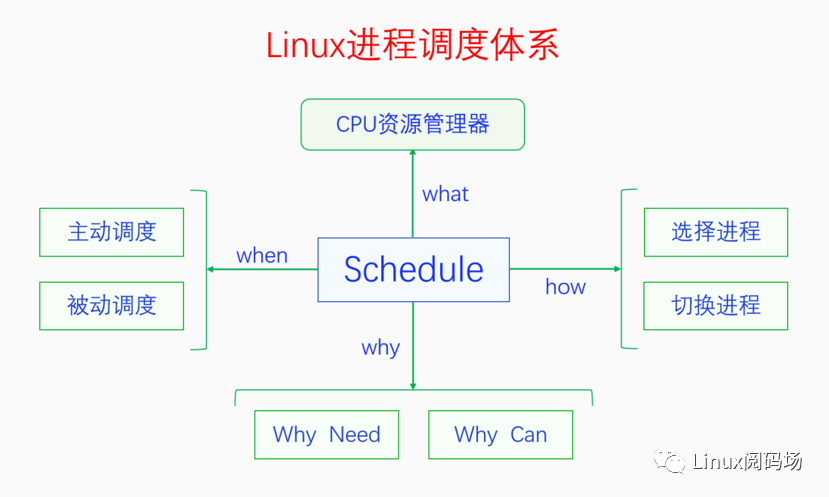
CPU資源管理器(what):調度器(scheduler)就是CPU資源管理器,因為操作系統的重要作用之一是管理各種系統資源,而CPU是其中最重要的資源。常用直接共享型資源的管理方法有時分、空分、獨占等,IO一般是獨占資源,內存支持空分管理,而CPU只支持時分,因此這種時分管理方法就是進程調度。
為什么要及為什么能調度(why):
為什么要調度:宏觀并行,微觀串行,支持多任務的協作與搶占。最初是協作,后來為了防止個別進程長期霸占CPU,引入了搶占機制。
為什么能調度:包括主動調度和被動調度,線程上下文可切換。
調度時機(when):
主動調度:通過主動調用sched_yield的自愿性主動調度,以及進程由于等待資源而阻塞的非自愿性主動調度。
被動調度:
觸發點:設置 TIF_NEED_RESCHED 標志,主要是時鐘中斷和喚醒搶占。
執行點:檢查 TIF_NEED_RESCHED 標志 和 滿足preempt_count == 0的條件。
主要包括以下四種場景:
系統調用完成返回用戶空間
完成返回用戶空間
中斷完成返回內核空間
出禁用搶占臨界區
如何進行調度(how):調用pick_next_task()選擇下一個調度進程和通過context_switch切換進程(上下文:內存空間,寄存器和棧)。
下面按時間順序簡單介紹一下linux調度器的發展歷史:
傳統Unix調度器:區分IO密集型和CPU密集型,但全局只有一個未排序的運行隊列,多CPU會有競爭,而且調度選擇需要遍歷整個隊列,復雜度為O(n)。
O(1)調度器:運行隊列從全局變成每個CPU一個,鏈表分成活動和過期兩個數組,引入位圖,復雜度降為為O(1)。
SD調度器:考慮到會因為個別進程的偽裝而造成的實際調度不公平,不再區分IO和CPU密集型,未合入內核。
RSDL調度器:組時間配額,有點像Cgroup,但未合入內核。
CFS(完全公平調度器):從SD/RSDL中吸取了完全公平的思想,目前內核主流調度器。
可以從以下幾個方面來評價調度器:
1.響應性:存在大量人機交互的PC和手機要重視響應。
2.吞吐量:服務器更關心吞吐量,而提高響應性會增加進程切換的評論,也就會降低吞吐量。所以響應和吞吐是一對矛盾。
3.公平性:相對公平,實際和理論的運行時間應該相符。
4.適應性:也就是可擴展性。
5.節能性:智能手機的需求,需要通過調度均衡來省電。
2.進程調度框架
如下圖所示,Linux一共有5個調度類:(stop和idle每個CPU一個)
stop:無調度策略,用戶空間不可用,內核用來處理線程遷移等優先級極高的事情。
idle:無調度策略,用戶空間不可用,無其他進程調用時才調用idle進程。
deadline:硬實時,要在確定時延內完成調度。
realtime:軟實時,盡力而為保證實時性。
time-share:按優先級分配時間片。

調度類之間的關系:除非資源限制,優先調度高優先級進程。但要注意,Linux考慮到在惡劣環境下,普通進程應該仍有被調度的機會,會默認預留有5%的帶寬給普通進程。
如下圖所示,從用戶空間到內核空間,進程優先級會發生轉換:
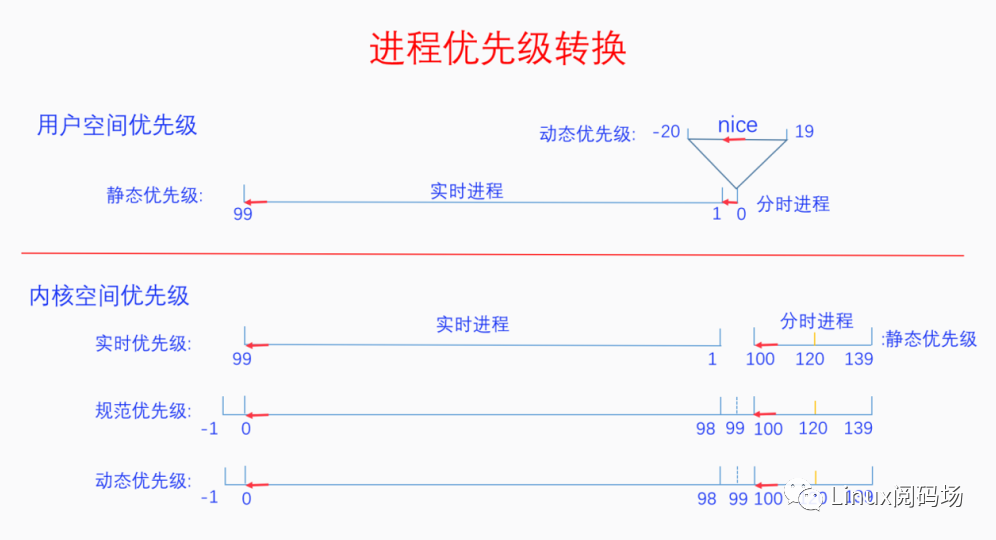
用戶空間優先級:分為1~99優先級從低到高的實時進程,以及nice值-20~19動態優先級從高到低的分時進程。
映射到內核空間優先級分為三步:
1.實時優先級:實時進程不變,分時進程從動態優先級映射為100~139靜態優先級由高到低。
2.規范優先級:實時進程映射為-1~98優先級由高到低,99為空,分時進程靜態優先級不變。
3.動態優先級:可以看到動態優先級幾乎等于規范優先級,只有在解決優先級反轉問題時采用優先級繼承策略時才會變化,此時會體現為動態優先級。
注意:-1和-2分別對應deadline和stop的邏輯優先級。
那如何進行進程切換呢?
切換用戶空間:不同進程的用戶空間不同,需要切換。
切換內核棧:不同進程共享內核空間,但需要切換內核棧。進程切換就像火車切換軌道,換道后,車上的人感覺火車沒變,但是因為軌道變了,行程也就跟著變了。線程的執行過程就是函數調用樹的深度優先遍歷,進程的切換點是__schedule函數,該函數前半部分在進程A的調用棧上執行,后半部分就跑到進程B的調用棧上執行了,返回則在新進程上執行。
3.進程調度算法
CFS調度器定義:通過引入虛擬運行時間vruntime(realtime / weight),每次選擇vruntime最小的進程(紅黑樹來管理)來調度,在真實硬件上模擬理想多任務處理器。
枯燥的定義不太容易理解的話,下面我們通過一個與實際生活比較貼近的例子來解釋CFS調度模型。
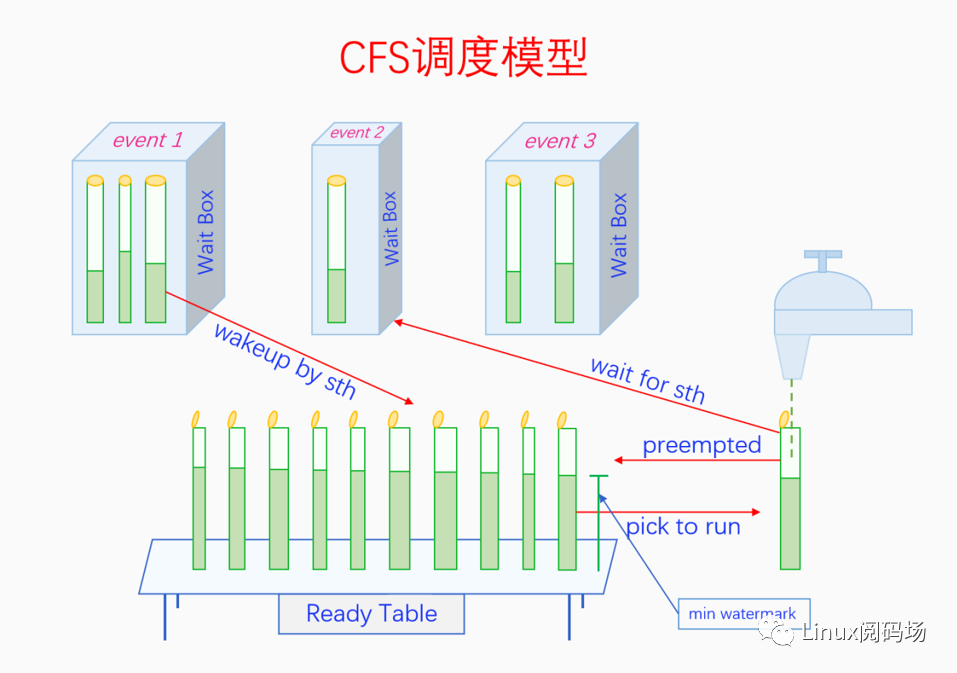
請仔細觀察上圖,圖中事物與進程調度的映射關系如下:
水杯:表示進程,蓋子打開的水杯表示進程處于就緒和執行狀態,其中Ready Table上的水杯都是就緒態進程,水龍頭下的水杯是運行態進程。蓋子閉合的表示阻塞態的進程,它們都在不同的Wait Box中。
水杯的粗細:表示不同的優先級。
watermark:表示虛擬運行時間vruntime,min watermark會被pick to run。
Ready Table:表示可運行隊列rq。
Wait Box:表示不同Event對應的等待隊列,如果只能由對應的Event喚醒的話,就屬于不可中斷的深睡眠,否則就是也可由signal喚醒的可中斷淺睡眠。
水龍頭:表示CPU,水龍頭中放出來的水就是CPU時間。
操作pick to run的手:表示調度算法,如果調度過于頻繁,那杯子接的水就少,水龍頭的水掉地上浪費了(響應好但性能差);反之調度周期長的話,杯子接的水太多會造成不平均(性能好但響應差)。權衡下來既不能接太少,最小值就是調度粒度;也不能接太多,最大值就是時間片。
這里需要特別注意的幾點:
1.進程的狀態
注意區別進程的5種狀態中的運行態和就緒態,所有就緒態進程都位于cpu的運行隊列中,而每個cpu上當前只有一個運行態進程。可以看到下面的代碼分別通過on_rq和on_cpu來確定進程是runnable的就緒態還是running的運行態。對應上面的例子,桌子上的開口水杯表示就緒(on_rq),水龍頭下的開口水杯表示運行(on_cpu)。

2.優先級與權重
CFS中的nice值會提前轉換為權重,nice的范圍是 [-20 -- 19],為了使得兩個相鄰的權重的占比差為10%,將以nice 0 為基準轉化為1024,整個數列是以1.25為公比的等比數列。將原來的等差數列轉為等比數列,因為調度策略的絕對值不重要,相對值(比例)才重要。
3.調度周期
調度周期 = 調度粒度 * 就緒和運行進程的數量,對應上面的例子就是所有開蓋玻璃杯數量(桌子上和水龍頭下的)與調度粒度的乘積,等于調度周期(所有杯子都接了一次水)。最小調度周期等于最小粒度乘以數量,如果計算算出來的時間片小于最小調度周期,內核就會讓時間片直接等于最小調度周期。
4.調度延遲
調度延遲是另一個概念,對應上面的例子就是從開口玻璃杯放到到桌子上開始計算,到送到水龍頭下接水的時間。但要注意,Linux中的調度延遲卻不這個意思,內核代碼體現的調度延遲是最小調度周期,也就是調度周期的最小值。
4.性能優化
單個進程的性能優化:
對于單個進程來說,可以通過下面的系統調用來改變進程(線程)的調度策略和優先級,只有特權進程才能調高自己的調度策略或者優先級。一般不要輕易地把進程設置為實時進程或者提高其優先級,除非有充足的理由。
系統響應性與吞吐量的優化:
系統的響應性和吞吐量是一對矛盾,很多時候我們要根據具體的情況來對系統進行配置。CONFIG_PREEMPT:是否開啟內核搶占,開啟可增加響應性,不開啟可增加吞吐量。一般服務器系統不會開啟,桌面和移動系統會開啟。
定時器tick頻率HZ:
定時器tick的頻率HZ,對系統的響應性和吞吐量也有很大的影響,HZ取值較大,系統響應性好,但是吞吐量會降低,HZ取值較小,吞吐量會增大,但是響應性會降低。
避免實時進程過度占用CPU:
為此內核提供了一對參數,可以設置一個運行周期內,實時進程最多只能用多少CPU時間,這樣就可以給普通進程留下一些執行時間。這兩個參數對應的文件是:
/proc/sys/kernel/sched_rt_period_us/proc/sys/kernel/sched_rt_runtime_us
可以通過cat和echo來查看和設置具體的值,單位是微妙默認值分別是1000000,950000,也就是說在每一秒內實時進程最多運行0.95s,會給普通進程保留0.5s。當然如果此時沒有普通進程,實時進程還是可以使用100%的CPU時間的。如果我們不希望實時進程使用過多的CPU時間的話,可以修改這個值。
子進程是否優先運行的問題:
默認情況下父進程與剛fork出來的子進程,誰會先得到執行是不確定的。如果在我們的環境中經常會fork子進程,并且我們總是希望子進程比父進程先得到執行,那么我們可以將/proc/sys/kernel/sched_child_runs_first值設為1。
-
數據
+關注
關注
8文章
6909瀏覽量
88849 -
監控
+關注
關注
6文章
2178瀏覽量
55103 -
服務器
+關注
關注
12文章
9029瀏覽量
85205 -
代碼
+關注
關注
30文章
4753瀏覽量
68368
原文標題:PODS2022: eBPF安全可觀測性的前景展望&Linux進程調度與性能優化速記(Day2)
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
openEuler 倡議建立 eBPF 軟件發布標準
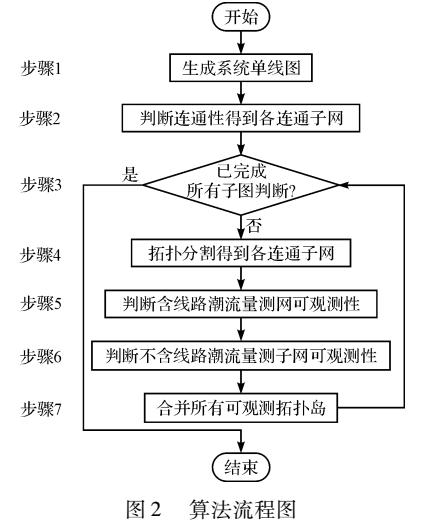
基于拓撲分割的網絡可觀測性分析方法
如何將可觀測性策略與APM工具結合起來
介紹eBPF針對可觀測場景的應用
六大頂級、開源的數據可觀測性工具
eBPF,何以稱得上是革命性的內核技術?

華為云應用運維管理平臺獲評中國信通院可觀測性評估先進級
使用APM無法實現真正可觀測性的原因
如何構建APISIX基于DeepFlow的統一可觀測性能力呢?
華為云發布全棧可觀測平臺 AOM,以 AI 賦能應用運維可觀測

【質量視角】可觀測性背景下的質量保障思路
破局新生丨基調聽云可觀測性與應用安全技術研討會在平潭圓滿舉辦

eBPF技術實踐之virtio-net網卡隊列可觀測





 工商網監
工商網監
評論