 基于小樣本增量學習 NER 的框架
基于小樣本增量學習 NER 的框架
之前的面向 NER 的類增量學習的工作都是基于新類有豐富的監督數據的情況,本文聚焦更具挑戰且更實用的問題:少樣本 NER 的增量學習。模型只用少量新類樣本進行訓練,保證新類效果的前提下不遺忘舊類知識。為了解決少樣本類增量學習的災難性遺忘問題,我們使用訓練好的 NER 模型對舊類生成合成數據來提升新類訓練效果。我們還提出一個框架,通過合成數據和真實數據將 NER 模型從過去 step 中進行蒸餾。實驗結果表明我們的方法對比 baseline 取得了很大的提升。
傳統的 NER 通常在大規模的數據集上訓練,然后直接應用到測試數據上不進行更多的適配。實際上,測試數據的實體類往往在訓練集中沒有出現過,因此我們希望模型可以增量地學習新的實體類。其中一個問題就是之前舊的訓練數據可能由于各種原因不可用了(隱私等原因),這樣會使在新類上微調時造成災難性遺忘。
之前的工作(Monaikul 等人,2021)通過對新實體類添加輸出層(AddNER)以及對輸出層進行擴展(ExtandNER)兩種知識蒸餾的方式解決。但是這種方式需要大量的數據,這在實際問題中不太現實。因此本文遵循了一個更加實際的設置:
(i)使用少量新類樣本進行增量學習;
(ii)不需要舊類訓練數據。
對于 Monaikul 等人的工作,作者認為,大量的新類監督數據也包含大量舊類的實體,雖然這些實體在新類數據上沒有標注,可以看作一種無標簽的舊類實體的“替代”數據集,可以通用知識蒸餾簡單的解決災難性遺忘。然而在小樣本設置下,不能寄希望于使用少量樣本來進行知識蒸餾。
以此為背景,本文提出一個小樣本增量學習 NER 的框架。受到上述問題的啟發,作者認為既然使用少量樣本不行,那就生成一些合成的數據進行蒸餾。本文通過翻轉 NER 模型來生成合成的數據。
具體來說,給定一個舊類訓練的模型,我們可以優化合成數據的 embeddings 使得舊類模型以合成數據為輸入的預測結果包含舊實體類,因此使用這些合成數據進行蒸餾可以保留舊類的信息。此外,為了保證合成數據相對真實,我們提出利用新類的真實數據,對抗地將合成數據和真實數據的 token 隱藏特征相匹配。通過對抗匹配得到的合成數據在語義上更加接近于新類的真實數據。與只在少量樣本上訓練相比,合成數據提供了更多樣化的信息。
本文的貢獻如下:
1. 本文提出了第一個少樣本增量學習的 NER 模型; 2. 我們使用真實數據和生成的合成數據來進行蒸餾的模型框架; 3. 實驗表明我們的方法在少樣本 NER 中取得了很好的效果。
Method
代表數據流, 是大規模源域數據, 之后都是小樣本的目標域數據。每個時間步上的數據集包含 個新實體。每個時間步的數據集只在當前時間步使用,在 t 時間步上,在 上進行評估。下圖是增量學習的示例:  ▲ 增量學習的示例,每個時間步分別有不同的實體類,最終預測時三個實體類都要預測。
▲ 增量學習的示例,每個時間步分別有不同的實體類,最終預測時三個實體類都要預測。
2.1 The Proposed Framework
本文使用 BERT-CRF 作為基礎 NER 模型, 代表 t 時間步的模型,其由 初始化。假設我們已經得到了合成數據(如何生成合成數據在后面會講到)。
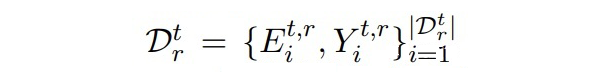
其中
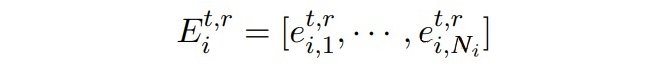
是 token 的 embeddings:
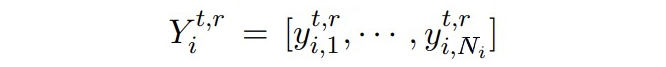
是從過去 t-1 個時刻的實體類中隨機采樣構成的標簽序列。token 的 embeddings 通過讓 模型的輸出匹配上隨機采樣的標簽序列來進行優化,隨后使用真實數據和合成數據進行知識蒸餾。
2.1.1 Distilling with Real Data
本文在 CRF 解碼方面采用 topK 個預測序列,例如對于 模型,有: 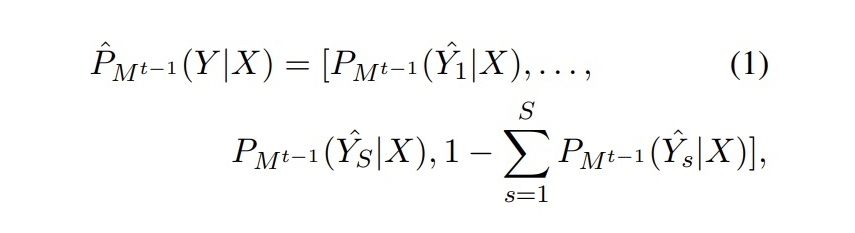 ▲ Mt-1對于Dt數據X的topK序列的預測概率分布 但是對于 來說, 無法準確預測 的新類別。為了從 中蒸餾知識,我們對 模型的預測序列進行了校正。示例如下圖所示:
▲ Mt-1對于Dt數據X的topK序列的預測概率分布 但是對于 來說, 無法準確預測 的新類別。為了從 中蒸餾知識,我們對 模型的預測序列進行了校正。示例如下圖所示: 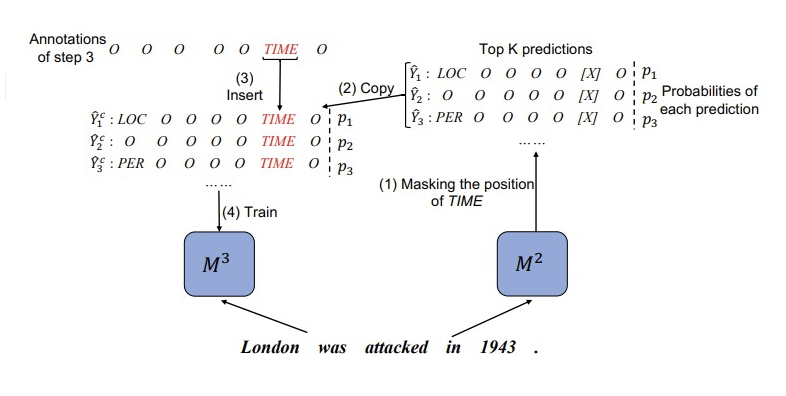 ▲?將step2生成的標注結果其中1943位置的標簽替換為“TIME” 這一步就是在訓練 之前,將 的新類數據 X 輸入到 中得到 topK 個預測結果,然后找到 X 中屬于新類別的位置,將 得到的標簽序列對應位置直接替換為新類標簽。根據校正后的標簽序列,計算預測的分布:
▲?將step2生成的標注結果其中1943位置的標簽替換為“TIME” 這一步就是在訓練 之前,將 的新類數據 X 輸入到 中得到 topK 個預測結果,然后找到 X 中屬于新類別的位置,將 得到的標簽序列對應位置直接替換為新類標簽。根據校正后的標簽序列,計算預測的分布:
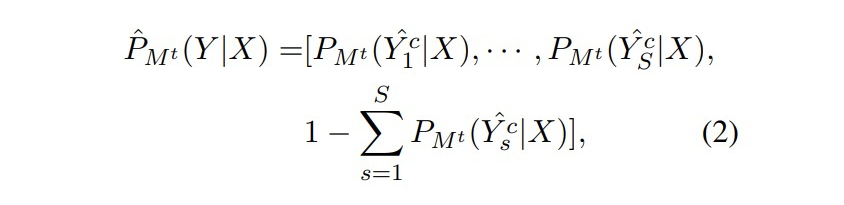 ▲?Mt對于校正后的topK序列的預測概率分布
▲?Mt對于校正后的topK序列的預測概率分布
真實數據蒸餾的損失為一個交叉熵損失:
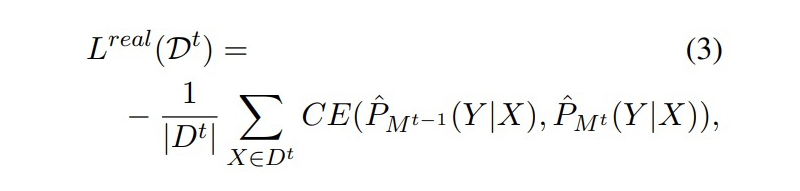 ▲?CE Loss 注:校正后的標簽中“O”類別的語義在 M2 和 M3 中是一致的,因此這種校正不會造成額外的影響。 2.1.2 Distilling with Synthetic Data
▲?CE Loss 注:校正后的標簽中“O”類別的語義在 M2 和 M3 中是一致的,因此這種校正不會造成額外的影響。 2.1.2 Distilling with Synthetic Data
與真實數據不同的是,合成數據只包含 t 步之前的標簽,因此無法像真實數據一樣對 CRF 的輸出結果進行校正( 預測的“O”有可能在中是“O”也有可能是新類)。
這里對于合成數據每個 token 的 embeddings,定義:
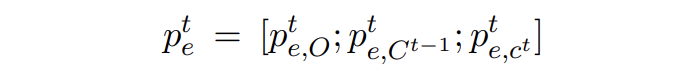 ▲ Mt模型預測的邊緣概率分布
▲ Mt模型預測的邊緣概率分布
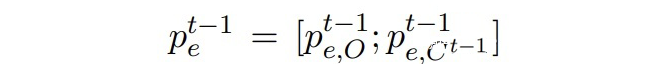 ▲?Mt-1模型預測的邊緣概率分布
▲?Mt-1模型預測的邊緣概率分布
其中:
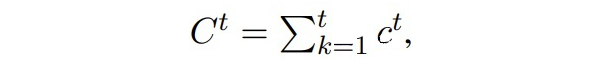
▲1~t步累積的實體類數目
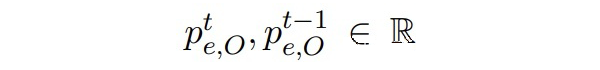
▲屬于“O”類的邊緣概率
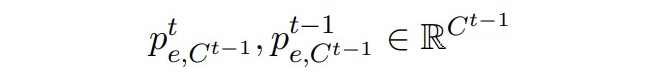 ▲?屬于Ct-1實體類的邊緣概率
▲?屬于Ct-1實體類的邊緣概率
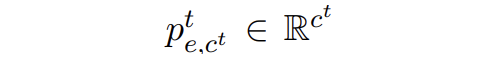
▲屬于新實體類的邊緣概率 文章中將 t 步的邊緣概率分布進行了一個合并,因為中的“O”類實際上包含了 t 步的新實體類,合并方式如下:
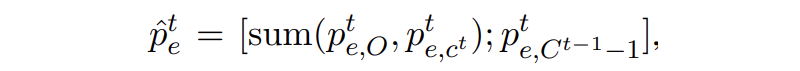 ▲?合并(個人認為這里書寫錯誤,Ct-1不應該再減個1)
▲?合并(個人認為這里書寫錯誤,Ct-1不應該再減個1)
保證合并后 t 和 t-1 步的邊緣概率分布維度一致。
合成數據的蒸餾損失為 KL 散度損失:
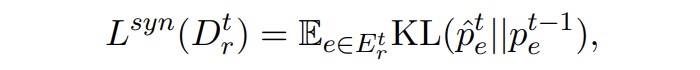 ▲?KL散度損失
▲?KL散度損失
最后,模型訓練總的損失為 CE 和 KL 損失的加權和,本文權重參數設為 1:
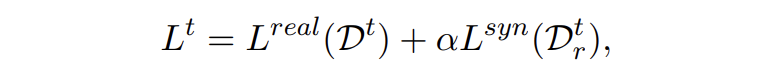 ▲?總loss
▲?總loss
這里簡單分析一下,CE 損失的目的是讓模型學到新實體的知識,因為采用了類似于 teacher forcing 的方式,直接將正確標簽插進去了,所以也能一定程度上減少模型對于其他位置預測結果的偏差,保留舊知識。KL 損失的目的是讓兩個模型對于合成數據預測的邊緣概率分布盡可能一致,主要使模型保留舊知識,避免災難性遺忘。
2.2 Synthetic Data Reconstruction
合成數據的構建一個很自然的想法是,隨機采樣舊實體類的序列 Y,然后隨機初始化合成數據的嵌入 E,優化 E 使得模型輸出匹配上 Y。其損失函數為:
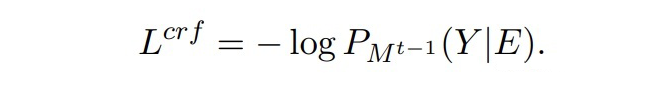 ▲ 負對數損失
▲ 負對數損失
但是這樣合成的數據可能并不真實,在合成數據上訓練并且在真實數據上測試會存在 domain gap。因此本文提出使用對抗訓練,利用真實數據使合成數據更加真實。 定義:
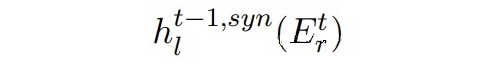
▲ Mt-1中BERT第l層的輸出(合成數據)
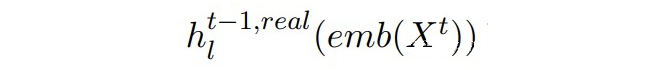
▲Mt-1中BERT第l層的輸出(Dt中真實數據) 作者希望兩個隱藏狀態能夠彼此靠近。這里引入一個二分類判別器,由一個線性層和一 sigmoid 激活函數組成。二分類判別器的訓練目標和對抗損失如下:
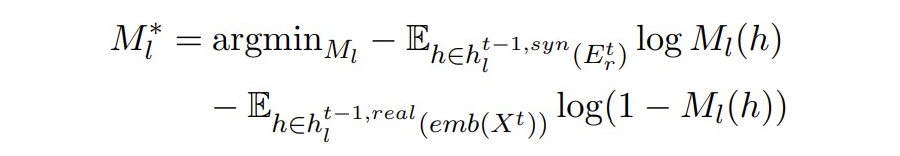 ▲ 二分類器的目標
▲ 二分類器的目標
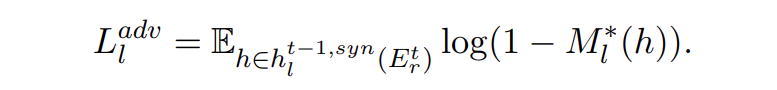
▲對抗損失
最后,構建合成數據的總損失如下:
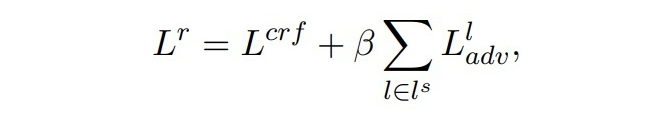
▲總損失
其中,,即每兩層之間進行匹配,β 是一個超參數,本文設置為 10。本文在訓練過程中,凍結了 token embedding 層,目的有兩點,第一是讓每一個時間步之間的模型共享相同的 token embedding,第二是對于小樣本設置來說,更新所有的參數會導致過擬合。
作者在這里分析,因為合成數據的實體標簽都是舊類的標簽,但是與其相匹配的數據卻是只包含新類標簽的中的數據,作者認為這樣會造成一些偏差。因此作者修改了匹配的方式,只將合成數據中標簽為“O”的 token 與真實數據的 token 相匹配。
最后是生成合成數據的算法偽代碼:
 ▲ 生成合成數據的偽代碼
▲ 生成合成數據的偽代碼
Experiments 3.1 數據集和設置 數據集采用 CoNLL2003(8 種實體類的順序)和 Ontonote 5.0(按照字母排序,2 種組合方式)。 對于 CoNLL2003 采用 5-shot 和 10-shot 進行試驗,OntoNote 5.0 采用 5-shot 訓練。step1 是基數據集,只包含 step1 對應的實體類,few-shot 樣本采用貪心采樣的方式(Yang 和 Katiyar,2020)進行采樣。
3.2 Baselines和消融實驗
CI NER:類增量學習 NER 的 SOTA; EWC++:一個解決災難性遺忘的方法; FSLL:類增量學習圖片分類的 SOTA; AS-DFD:無數據蒸餾的文本分類的 SOTA; L-TAPNet+CDT:少樣本序列標注的 SOTA。
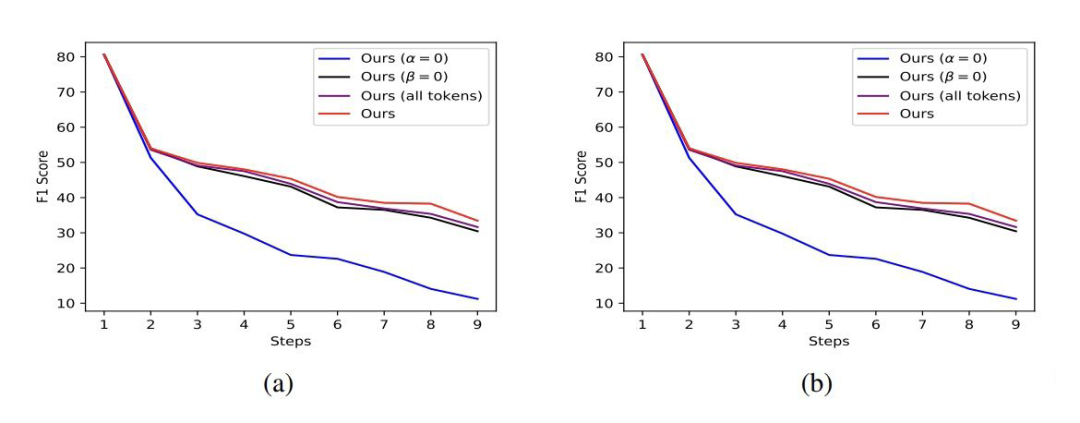 ▲ OntoNote上的消融實驗
▲ OntoNote上的消融實驗
3.3 主實驗
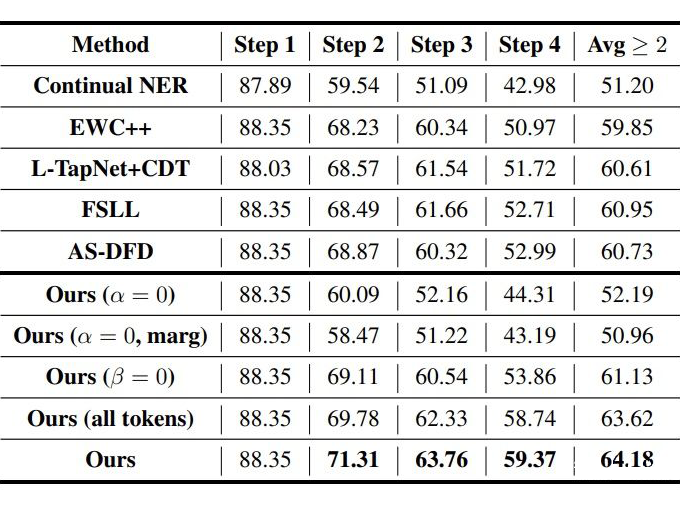
▲ CoNLL2003 5-shot
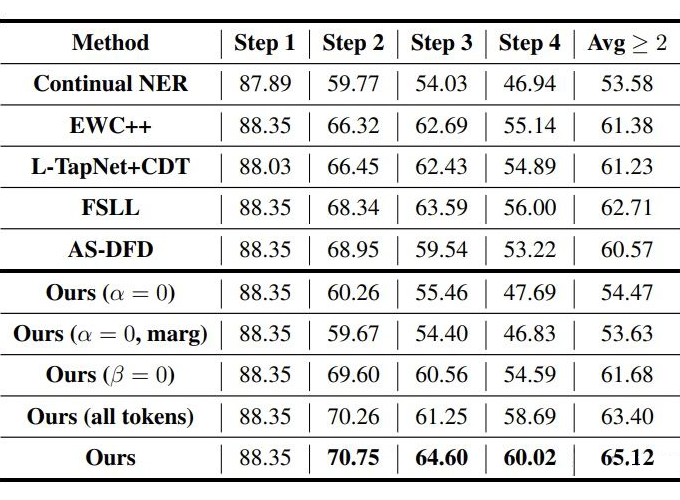
▲ CoNLL2003 10-shot
▲ OntoNote 5.0 5-shot P1(左)P2(右)
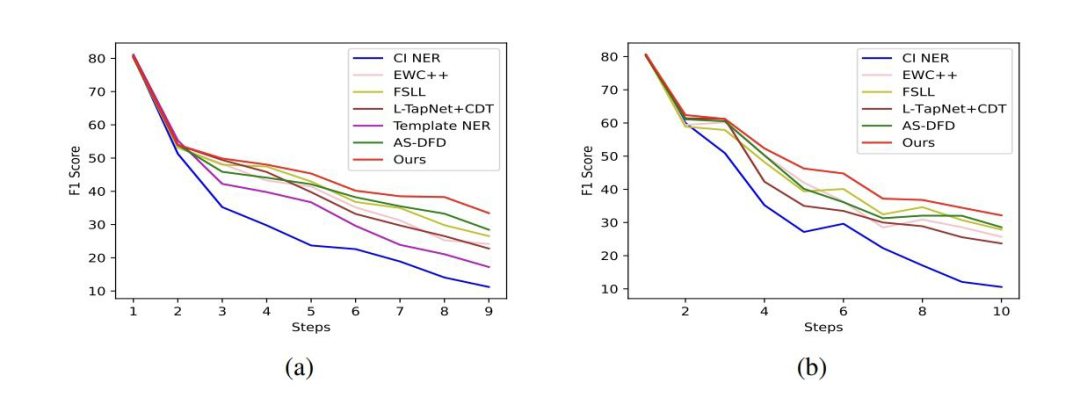
作者還做了一個可視化的實驗:

(a)中有少量 LOC 標簽的合成數據和真實分布很接近,但是其他的更多合成數據與真實分布差的很遠。這可能是因為“O”類可能包含多種多樣的信息造成其很難構造,使用這樣的合成數據會導致 domain shift。
(b)中合成數據匹配真實數據分布,但是只有很少一部分合成數據與 LOC 標簽的 token 相近,這是由于上文所說 D2 中并不存在 LOC 標簽,將合成數據所有 token 與 D2 數據匹配會導致偏離 LOC 標簽,丟失很多舊標簽的信息。 (c)中作者采用的方法合成數據中很多 token 與 LOC 接近,且其余 token 也與真實數據分布相匹配。
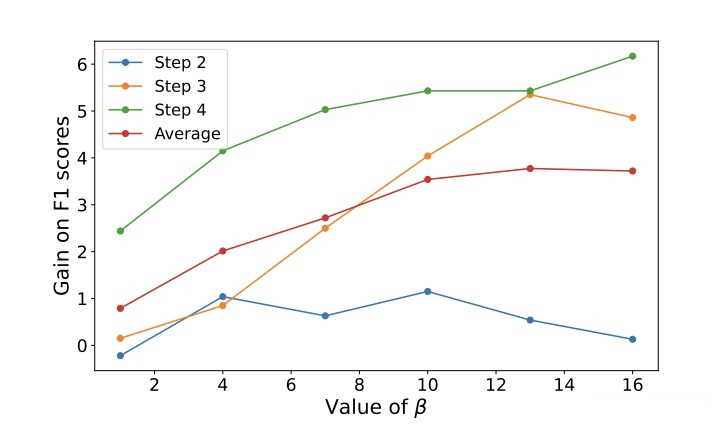
▲ 采用不同β
Conclusion
本文提出第一個類增量學習的少樣本 NER 模型來解決災難性遺忘。提出了使用上一時間步的模型來構建包含舊實體類的合成數據。合成數據提供了更加多樣的包含新實體和舊實體的信息,使模型在少樣本設置下不容易過擬合。本文也算是一篇啟發性的論文,通過隨機采樣舊類實體標簽序列以及只將“O”類與真實的新類數據以對抗的方式匹配,使合成數據更真實,且包含更多信息。
-
解碼
+關注
關注
0文章
180瀏覽量
27364 -
模型
+關注
關注
1文章
3174瀏覽量
48718 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:ACL2022 | 類增量學習的少樣本命名實體識別
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于小樣本重用的混合盲均衡算法
高維小樣本分類問題中特征選擇研究綜述
增量流形學習正則優化算法
答疑解惑探討小樣本學習的最新進展
深度學習:小樣本學習下的多標簽分類問題初探
一種針對小樣本學習的雙路特征聚合網絡

一種為小樣本文本分類設計的結合數據增強的元學習框架

融合零樣本學習和小樣本學習的弱監督學習方法綜述

一種基于偽標簽半監督學習的小樣本調制識別算法
基于深度學習的小樣本墻壁缺陷目標檢測及分類
FS-NER 的關鍵挑戰
常見的小樣本學習方法
IPMT:用于小樣本語義分割的中間原型挖掘Transformer
小樣本學習領域的未來發展方向






 工商網監
工商網監
評論