 基于知識的對話生成任務
基于知識的對話生成任務
研究動機
基于知識的對話生成任務(Knowledge-Grounded Dialogue Generation,KGD)是當前對話系統的研究熱點,這個任務旨在基于對話歷史和外部知識來生成的富含信息量的回復語句。目前的工作通常使用結構化知識圖(KGs)或非結構化文本作為知識來源。這些外部的知識來源可以緩解傳統生成模型產生的無意義和乏味的回復,比如“我不知道”和“是的”。
最近的一些工作使得有些學者認識到實體(Entity)之間的相關性在多輪對話中起著重要的作用,因此他們提出在知識圖譜中挖掘實體之間有價值的結構信息,以預測下一個回復中可能出現的實體,并利用預測的實體進一步指導回復語句的生成。然而,這種方法也存在兩個缺陷:
? 一方面,entity-guided KGD方法將對話中的實體作為唯一的知識去指導模型對上下文的理解和回復的生成,而忽略了KG中實體之間的關系(relation)的重要性。然而,人類對話背后的規律性可以概括為一系列話題的轉換,其中每個話題可能對應于一個關系邊,而不是KG中的單個實體。
?另一方面,現有的KGD方法僅利用最后一個對話回合中的知識去預測后續回復中的知識,這種方式并不足以學習人類如何在多輪對話中如何轉換話題。
下圖是一個知識對話的示例。Dialogue Context(a)展示了一個對話上下文,兩個用戶從萊昂納多的職業聊到了他的代表作泰坦尼克號,然后討論了泰坦尼克號這部電影的類型和主演陣容,并將最后的焦點實體落在凱特溫斯萊特上。KG(b)展示了在這個對話過程中所有涉及到的實體以及它們在KG中的三元組。由這兩個信息源可以得到兩種貫穿這段對話的語言邏輯:
a. 回合級實體過渡路徑:萊昂納多——>泰坦尼克號——>凱特溫斯萊特
b.對話級關系轉換路徑:職業——>代表作——>電影類型/主演
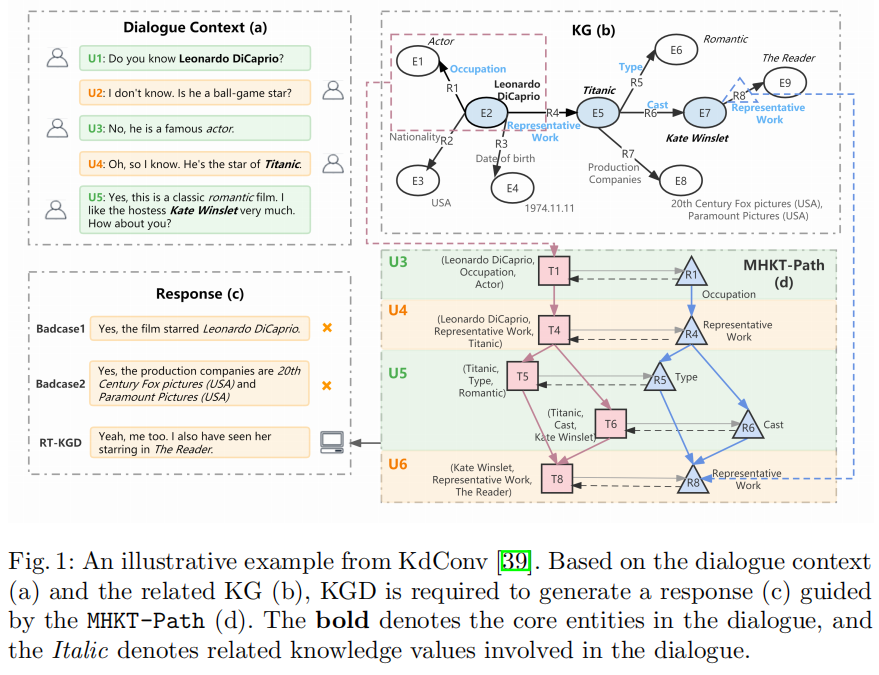
由此可見,如果不建模多輪知識,生成的回復可能是冗余且不連貫的,如Badcase1;如果只關注回合級的實體過渡路徑,而忽略整個對話中話題的潛在轉換路徑時,模型生成的回復可能非常突兀,無法和對話上下文的語言邏輯順暢地銜接起來,如Badcase2。
PART 02
貢 獻
因此,本文提出了一種新的KGD模型:RT-KGD(Relation Transition aware Knowledge-Grounded Dialogue Generation),該模型通過將對話級的關系轉換規律與回合級的實體語義信息相結合,來模擬多輪對話過程中的知識轉換。具體來說,作者利用多輪對話上下文中包含的所有關系和實體,構建了MHKT-Path(Multi-turn Heterogeneous Knowledge Transition Path),它可以看作是外部KG的一個子圖,同時又結合了多輪對話中關系和實體出現的順序信息。基于所構建的MHKT-Path,作者設計了一個知識預測模塊,從外部KG中檢索三元組作為后續回復中可能出現的知識,最后融合對話上下文和預測的三元組以生成回復語句。本文的主要貢獻有以下三點:
? 本文是第一個將跨多輪對話中的關系轉換引入KGD任務的工作,通過整合關系轉換路徑和實體語義信息來學習人類對話背后的規律性。
? RT-KGD為每個對話都構建一個多輪異構知識轉換路徑(MHKT-Path),它將外部KG的結構信息和知識的順序信息結合起來。基于MHKT-Path,模型可以從KG中檢索適當的知識,以指導下一個回復的生成。
? 在多領域知識驅動的對話數據集KdConv上的實驗結果表明,RT-KGD在自動評估和人工評估方面都優于基線模型。
PART 03
模 型
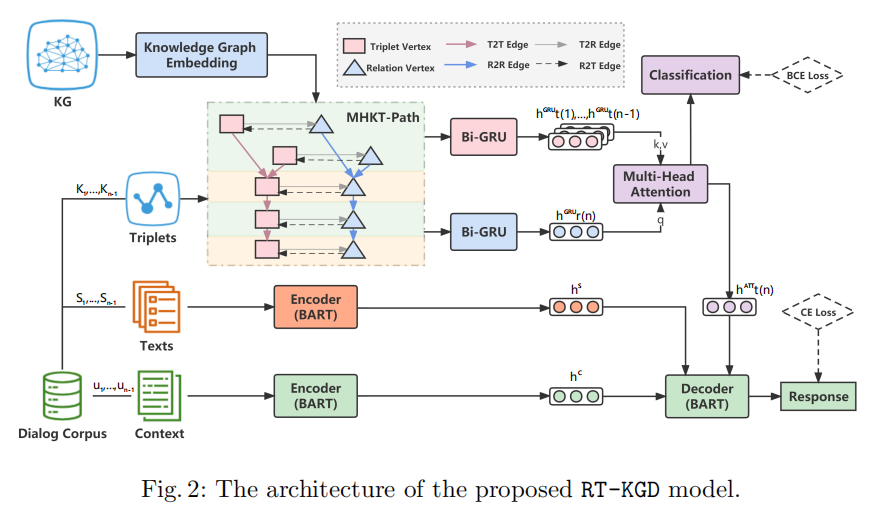
1.任務定義
給定一個對話上下文C={u1,...,un-1}、其中每一條語句ui都對應一個三元組集合Ki和一個非結構化文本集合Si。模型的目標是利用對話上下文、結構化三元組和非結構化文本生成一句合適的回復語句un。
2.Multi-turn Heterogeneous Knowledge Transition Path(MHKT-Path)
作者為每個對話上下文都構建了一個多輪異構知識轉移路徑圖,來將對話級的關系轉換規律與回合級的實體語義信息結合起來。
MHKT-Path有兩類節點:
? 三元組節點 ? 關系節點(關系節點是從對應三元組中抽取得到的) MHKT-Path 有四種邊: ? 連接三元組節點到三元組節點的邊(邊的方向按照三元組在對話上下文中出現的順序決定) ?連接關系節點到關系節點的邊(邊的方向按照關系在對話上下文中出現的順序決定,即與它們對應的三元組之間的邊的方向相同) ?連接三元組節點到關系節點的邊 ?連接關系節點到三元組節點的邊
這樣,兩種粒度的知識信息就得到了充分交互和融合,共同促進模型對上下文知識和對話邏輯順序的理解。
3. Knowledge Encoder
Knowledge Encoder用知識圖譜表示學習模型和異構圖神經網絡將MHKT-Path中的節點轉化為向量表示。
1. 初始化MHKT-Path中的所有節點。作者利用TransR得到KG中所有元素(實體和關系)的表示,這些表示融合了KG中的全局信息。因此,MHKT-Path中的節點表示就可以用這些元素的表示計算得到:對于關系節點,其向量表示就是該關系在KG中的表示;對于三元組節點,其向量表示由該三元組包含的頭尾實體和關系的向量拼接而成。
2. HGT(Heterogeneous Graph Transformer)可利用MHKT-Path中的局部結構信息來更新節點的表示。
最后,結合上兩步的結果得到節點的最終表示。
4. Knowledge Predictor
Knowledge Predictor用來預測下一句回復中可能出現的知識,此模塊分為三部分:
1. 由于知識編碼器只聚合局部鄰域信息,作者進一步采用Bi-GRU來分別豐富關系節點和三元組節點的時序特征。具體來說,將此時間步中出現的所有關系節點和三元組節點的平均向量分別作為Bi-GRU的輸入。
2.基于前面的n-1輪(即n-1個時間步)的關系表示,通過Bi-GRU預測第n輪(t=n)的關系節點的表示:
與關系節點不同,作者先用Bi-GRU得到前n-1輪每輪三元組節點的表示:
然后利用多頭注意力機制將對話級的第n輪關系節點的表示和回合級的前n-1輪三元組節點的表示結合起來,共同預測第n輪三元組節點的表示:
3. 因為一輪語句中可能包含多個知識,所以作者用多標簽分類將得到的第n輪的三元組向量映射到一個標簽向量上,其長度為KG中所有的三元組數量,并用二元交叉熵(BCE)損失函數來監督分類的效果。
5. Knowledge-Enhanced Encoder-Decoder
在Knowledge-Enhanced Encoder-Decoder中,BART用來給上下文語句和其中對應的非結構化描述文本S分別進行編碼,Si代表第i輪語句中對應的非結構化描述文本。
在解碼階段,作者將上述步驟中得到的前n-1輪對話上下文C的表示、前n-1輪非結構化描述文本S的表示、和預測的第n輪三元組的表示拼接后輸入BART的解碼器中,生成第n輪富含信息量的回復語句:
模型最終的loss為知識分類標簽的BCE損失函數和解碼語句的交叉熵損失函數的加權和:
PART 04
實 驗
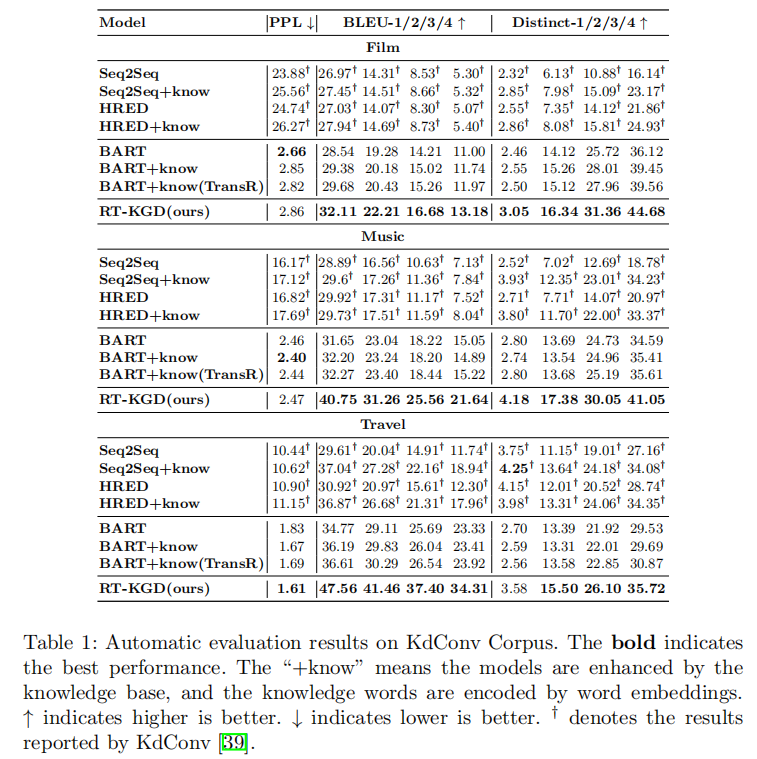
為了驗證提出的模型,在數據集的選擇時應該滿足兩個要求:(1)每輪語句都用相關的知識三元組進行標注;(2)在每個對話段中包含足夠多輪次的語句。因此,KdConv是最佳的實驗數據集。從實驗結果來看,RT-KGD生成了更高質量的回復,利用了更合適的知識,并更接近人類的表達方式。
?自動評估指標
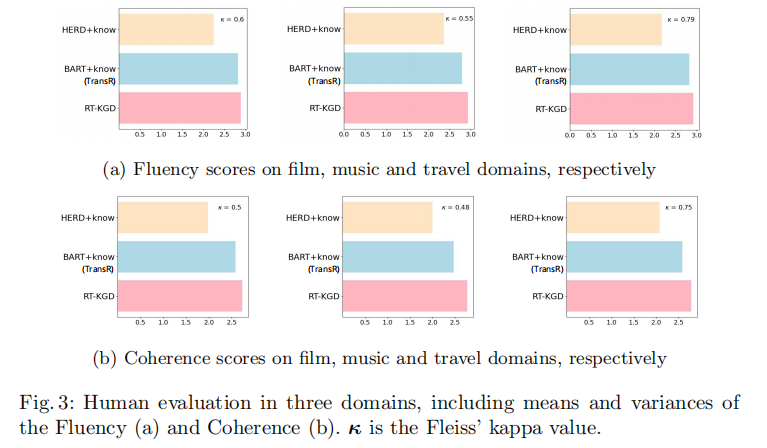
? 人工評估指標
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
模型
+關注
關注
1文章
3171瀏覽量
48711 -
數據集
+關注
關注
4文章
1205瀏覽量
24641
原文標題:RT-KGD:多輪對話過程中的知識轉換模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
結合NLU在面向任務的對話系統中的具體應用進行介紹
【安富萊原創】【STemWin教程】第39章 對話框基礎知識
第39章 對話框基礎知識
基于分層編碼的深度增強學習對話生成
四大維度講述了一個較為完整的智能任務型對話全景
一種可轉移的對話狀態生成器
對話系統最原始的實現方式 檢索式對話
華為公開 “人機對話”相關專利:可根據對話內容生成準確回復
口語語言理解在任務型對話系統中的探討

視覺問答與對話任務研究綜述

一種結合回復生成的對話意圖預測模型

NLP中基于聯合知識的任務導向型對話系統HyKnow
受控文本生成模型的一般架構及故事生成任務等方面的具體應用
NVIDIA NeMo 如何支持對話式 AI 任務的訓練與推理?

基于主觀知識的任務型對話建模






 工商網監
工商網監
評論