") 一種將知識(shí)圖譜與語言模型結(jié)合的具體方式分享
一種將知識(shí)圖譜與語言模型結(jié)合的具體方式分享
知識(shí)嵌入(Knowledge Embedding)將知識(shí)圖譜中的關(guān)系和實(shí)體嵌入向量空間進(jìn)行表示。現(xiàn)有工作主要分為兩類:傳統(tǒng)的基于結(jié)構(gòu)的方法(如TransE)在向量空間建模KG的結(jié)構(gòu)信息,此類方法無法良好地表示真實(shí)知識(shí)圖譜中大量結(jié)構(gòu)信息匱乏的長尾實(shí)體;新興的基于文本的方法(如Kepler)引入額外的文本信息和語言模型, 但該方向的現(xiàn)有工作相較于基于結(jié)構(gòu)的方法存在以下不足,包括效率較低、表現(xiàn)不佳、限制性文本依賴等問題。
知識(shí)工場(chǎng)實(shí)驗(yàn)室提出了一個(gè)將語言模型用作知識(shí)嵌入的方法 LMKE,以期在提升長尾實(shí)體表示的同時(shí)解決現(xiàn)存基于文本方法的以上問題。LMKE 首次提出將基于文本的知識(shí)嵌入學(xué)習(xí)建模在對(duì)比學(xué)習(xí)框架下,顯著提升了模型在訓(xùn)練和下游應(yīng)用中的效率。實(shí)驗(yàn)結(jié)果表明,LMKE在多個(gè)知識(shí)嵌入評(píng)價(jià)基準(zhǔn)上取得了超越現(xiàn)有方法的表現(xiàn),尤其是針對(duì)長尾實(shí)體。研究成果《Language Models as Knowledge Embeddings》已被IJCAI 2022錄用。

一、背 景
知識(shí)圖譜(Knowledge Graphs)以三元組的形式儲(chǔ)存了大量的知識(shí)。其中,三元組(h,r,t)表示,頭實(shí)體h與尾實(shí)體t間存在關(guān)系 r,如(法國,包含,盧浮宮)。
知識(shí)嵌入(Knowledge Embeddings, KEs)將知識(shí)圖譜上的實(shí)體和關(guān)系嵌入到向量空間中進(jìn)行表示,以便在向量空間中推理,用于三元組分類、鏈接預(yù)測(cè)等任務(wù)。比如說,TransE 將實(shí)體“法國”、“盧浮宮”和關(guān)系“包含”分別表示為向量“法國”、“盧浮宮”、“包含”,而如果“法國”+“包含”≈“盧浮宮”,則認(rèn)為該三元組為真。近年來,知識(shí)嵌入也越來越多地被用于與預(yù)訓(xùn)練語言模型相結(jié)合,以賦予語言模型更多的知識(shí)。
現(xiàn)有的知識(shí)嵌入方法可以被大致分為兩類:傳統(tǒng)的基于結(jié)構(gòu)的方法(Structure-based Methods)和近期興起的基于文本的方法(Description-based Methods)。
基于結(jié)構(gòu)的方法在向量空間中表達(dá)知識(shí)圖譜的結(jié)構(gòu)信息,包括 TransE、RotatE 等。這類方法可以建模多種特殊的關(guān)系模式,如對(duì)稱模式、逆模式、組合模式等。比如,已知“A 的父親是 B”,“B 的父親是 C”,且“父親的父親是爺爺”,則這類方法可以推理出“A 的爺爺是 C”,如下圖所示。
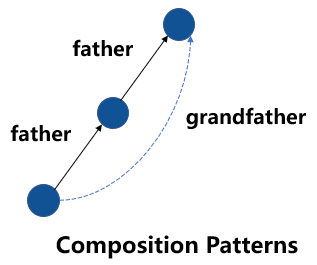
圖1 知識(shí)圖譜中的組合模式
然而,這類方法單純依賴知識(shí)圖譜的結(jié)構(gòu)信息,因此自然難以良好地表示結(jié)構(gòu)信息匱乏的長尾實(shí)體。在真實(shí)世界的知識(shí)圖譜中,實(shí)體的度數(shù)分布服從power-law定律,形成一條長長的尾巴,意味著大量實(shí)體缺乏充足的結(jié)構(gòu)信息。比如,下方左圖展示了知識(shí)圖譜數(shù)據(jù)集WN18RR中的實(shí)體度數(shù)分布,其中14.1%的實(shí)體度數(shù)為1,60.7%的實(shí)體度數(shù)不超過3,這意味著這些實(shí)體在知識(shí)圖譜上連邊極少。下方右圖的結(jié)果則表明,以RotatE為代表的典型基于結(jié)構(gòu)的方法在長尾實(shí)體上表現(xiàn)不佳。
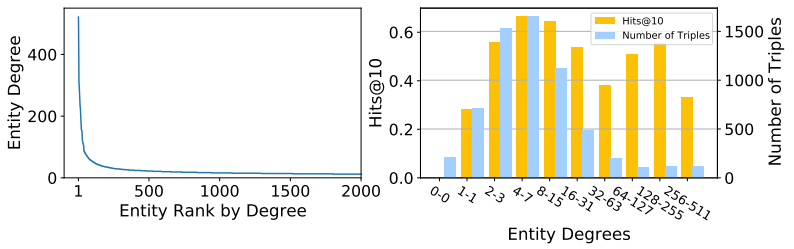
圖2 WN18RR上的節(jié)點(diǎn)度數(shù)分布及基于結(jié)構(gòu)的方法在該數(shù)據(jù)集上的表現(xiàn)
基于文本的方法引入了文本信息和語言模型進(jìn)行知識(shí)的嵌入與推理,如 DKRL、KEPLER 等。許多知識(shí)圖譜提供了實(shí)體和關(guān)系的文本描述,而這些豐富的文本信息可以良好地用于實(shí)體和關(guān)系的表示,并彌補(bǔ)結(jié)構(gòu)信息的不足。同時(shí),近期關(guān)于語言模型的相關(guān)研究表明:
①語言模型在預(yù)訓(xùn)練時(shí)不僅掌握了語言知識(shí),還學(xué)會(huì)了大量事實(shí)知識(shí)
②語言模型可以同基于結(jié)構(gòu)的知識(shí)嵌入方法一樣,掌握對(duì)稱模式、逆模式、隱含模式等部分關(guān)系模式[2]。
因此,我們認(rèn)為語言模型非常適合作為知識(shí)嵌入使用。
此前已有工作嘗試將語言模型用于知識(shí)嵌入的三元組分類、鏈接預(yù)測(cè)任務(wù)上。然而,現(xiàn)存的基于文本的方法存在以下缺陷:
①效率較低。語言模型規(guī)模龐大,因此現(xiàn)有工作在訓(xùn)練及下游任務(wù)中或是時(shí)間復(fù)雜度過高,或進(jìn)行了大量的 trade-off。一方面,它們?cè)谟?xùn)練時(shí)限制負(fù)采樣率。比如基于文本的 KEPLER 中正樣本和負(fù)樣本的數(shù)量是 1:1 的,而基于結(jié)構(gòu)的 TransE 中一個(gè)正樣本會(huì)搭配上千個(gè)負(fù)樣本。另一方面,現(xiàn)有方法的模型結(jié)構(gòu)在鏈接預(yù)測(cè)等下游任務(wù)上復(fù)雜度也過高。
②表現(xiàn)不佳。盡管引入了更多的信息與更大的模型,現(xiàn)存的基于文本的方法在許多數(shù)據(jù)集和指標(biāo)上并未超越基于結(jié)構(gòu)的方法,其中效率問題帶來的負(fù)采樣率不足等 trade-off 一定程度上造成了負(fù)面影響。
③限制性文本依賴。現(xiàn)存方法只適用于有文本描述的實(shí)體,而往往舍棄掉大量沒有文本信息(但有結(jié)構(gòu)信息)的實(shí)體。現(xiàn)存方法對(duì)數(shù)據(jù)的嚴(yán)苛要求限制了他們?cè)谙掠稳蝿?wù)中的使用。
二、方 法
在本文中,我們提出了一個(gè)更好地將語言模型用作知識(shí)嵌入的方法LMKE(Language Models as Knowledge Embeddings),同時(shí)利用結(jié)構(gòu)信息和文本信息,在提升長尾實(shí)體表示的同時(shí)解決基于文本方法的上述問題。在 LMKE 中,實(shí)體和關(guān)系被視作額外的詞(token),并從相關(guān)實(shí)體、關(guān)系和文本描述中學(xué)習(xí)表示。本文進(jìn)一步提出將基于文本的知識(shí)嵌入學(xué)習(xí)建模在對(duì)比學(xué)習(xí)框架下,使得一個(gè)三元組里的實(shí)體表示可以作為同 batch 中其他三元組的負(fù)樣本,從而避免了編碼負(fù)樣本帶來的額外開銷。LMKE 也是一種將知識(shí)圖譜與語言模型結(jié)合的具體方式。
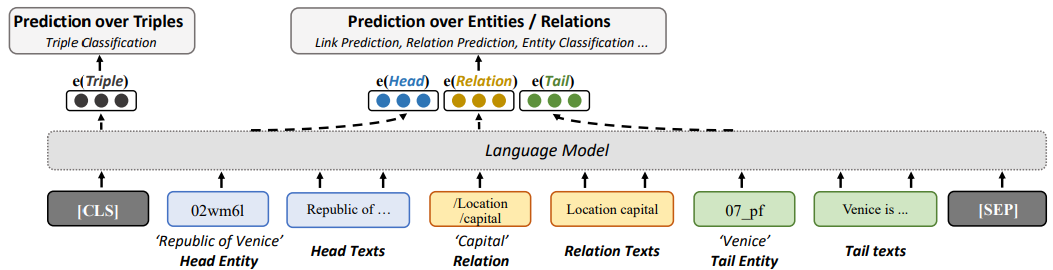
圖3 LMKE的模型結(jié)構(gòu)(用于三元組分類)
LMKE 用語言模型作為知識(shí)嵌入,即用語言模型獲得實(shí)體和關(guān)系的嵌入向量表示,從而對(duì)三元組或?qū)嶓w進(jìn)行預(yù)測(cè)。在 LMKE 中,實(shí)體和關(guān)系的嵌入向量與文本中的詞被表示在同一個(gè)向量空間中。如圖3所示,給定一個(gè)特定的三元組u=(h,r,t),LMKE 利用相應(yīng)的文本描述信息,將它們拼為一個(gè)序列。將該序列作為語言模型的輸入,h,r,t的相應(yīng)輸出向量 h,r,t,即是相應(yīng)的實(shí)體和關(guān)系的嵌入向量。一個(gè)實(shí)體(或關(guān)系)的嵌入向量同時(shí)依賴于其自身、其自身的文本描述、其相關(guān)實(shí)體和關(guān)系、以及相關(guān)實(shí)體和關(guān)系的文本描述,對(duì)文本信息進(jìn)行了最大程度的利用。
因此,長尾實(shí)體可以利用文本信息而被良好表示,而缺乏文本信息的實(shí)體則可以利用相關(guān)實(shí)體和關(guān)系(結(jié)構(gòu)信息)以及它們的文本描述被良好表示。語言模型中的CLS token(或 BOS token)對(duì)應(yīng)的向量聚合了整個(gè)序列的信息,因此我們將其視作代表整個(gè)三元組u的向量u。
與KG-BERT相似,LMKE 將向量u輸入一個(gè)線性層,來計(jì)算三元組為真的概率p(u):知識(shí)嵌入的主要應(yīng)用是預(yù)測(cè)缺失的鏈接(鏈接預(yù)測(cè))和對(duì)可能的三元組進(jìn)行分類(三元組分類)。其中,三元組分類基于上述p(u)即可進(jìn)行。鏈接預(yù)測(cè)則需要預(yù)測(cè)出不完整三元組(?,r,t)或(h,r,?)的缺失實(shí)體。具體來說,模型需要將候選實(shí)體(一般為所有實(shí)體)填入不完整三元組,并將相應(yīng)的三元組進(jìn)行打分,從而對(duì)候選實(shí)體按照得分進(jìn)行排序。然而,對(duì)于上述 LMKE 模型,以及大部分現(xiàn)有的基于文本的方法,這一流程的計(jì)算時(shí)間復(fù)雜度都過高,如表1所示。
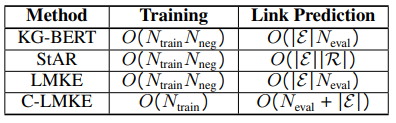
表1 部分基于文本的方法在訓(xùn)練和鏈接預(yù)測(cè)上的時(shí)間復(fù)雜度
為了將語言模型高效地用于鏈接預(yù)測(cè)任務(wù),一個(gè)簡(jiǎn)單的方法是不完整地編碼三元組,而僅編碼部分三元組。實(shí)體遮蓋模型(MEM-KGC)可以視為 LMKE 的 masked變體,將待預(yù)測(cè)的缺失實(shí)體和其文本描述 mask,并將相應(yīng)的向量表示q輸入一個(gè)線性層來預(yù)測(cè)缺失實(shí)體。因?yàn)閮H需要編碼一個(gè)不完整的三元組,MEM-KGC顯著降低了時(shí)間復(fù)雜度。然而,MEM-KGC 忽視了待預(yù)測(cè)實(shí)體的文本信息,降低了文本信息的利用率。
我們提出了一個(gè)對(duì)比學(xué)習(xí)框架來更充分地利用文本信息。在我們的對(duì)比學(xué)習(xí)框架中,給定的實(shí)體關(guān)系對(duì)被視作查詢q,而目標(biāo)實(shí)體被視作鍵k,我們通過匹配q和k進(jìn)行對(duì)比學(xué)習(xí)。在這一框架的視角下,MEM-KGC 中的向量q即為查詢的向量表示,而MEM-KGC的線性層權(quán)重的每一行則是每一個(gè)實(shí)體作為鍵的向量表示。因此,將q輸入到線性層即為查詢q匹配鍵。差別在于,MEM-KGC的鍵是用可學(xué)習(xí)的向量表示,而非像查詢一樣是文本信息的語言模型編碼。我們提出的對(duì)比學(xué)習(xí)框架也使得語言模型能夠被高效地用于鏈接預(yù)測(cè)。
C-LMKE是對(duì)比學(xué)習(xí)框架下的LMKE變體,將MEM-KGC中的可學(xué)習(xí)實(shí)體權(quán)重改進(jìn)為目標(biāo)實(shí)體的文本描述編碼,如圖4所示。C-LMKE進(jìn)行批次內(nèi)的對(duì)比匹配,從而避免了編碼負(fù)樣本帶來的額外開銷。具體來說,對(duì)于 batch 中的第i個(gè)三元組,它的給定實(shí)體關(guān)系對(duì)q和目標(biāo)實(shí)體k構(gòu)成一個(gè)正樣本,而同batch內(nèi)其他三元組的目標(biāo)實(shí)體k’與q構(gòu)成負(fù)樣本。由表1可見,C-LMKE在訓(xùn)練和鏈接預(yù)測(cè)時(shí)的時(shí)間復(fù)雜度均顯著優(yōu)于現(xiàn)有基于文本的方法。
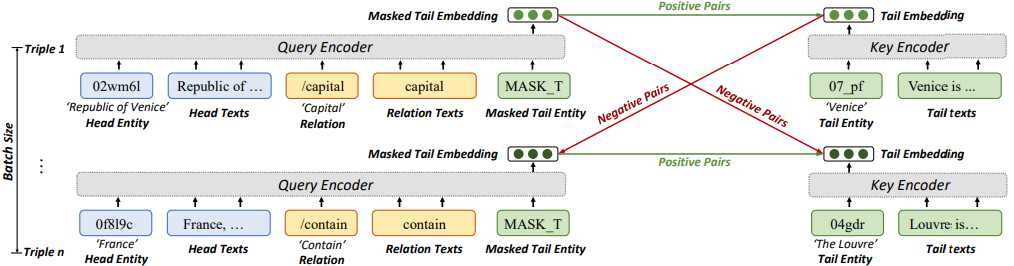
圖4 C-LMKE的模型結(jié)構(gòu)(用于鏈接預(yù)測(cè))
不同于一般的對(duì)比學(xué)習(xí)方法,C-LMKE采用一個(gè)雙層MLP而非余弦相似度來計(jì)算q和k的匹配度。假設(shè)查詢q=(法國,包含)同時(shí)與=(盧浮宮)和=(巴黎)匹配,則基于相似度的得分會(huì)迫使和的表示相似,這在知識(shí)嵌入的場(chǎng)合是不被期望的。同時(shí),我們還發(fā)現(xiàn),引入度數(shù)信息和(相應(yīng)實(shí)體在訓(xùn)練集中的三元組個(gè)數(shù))對(duì)于鏈接預(yù)測(cè)任務(wù)相當(dāng)有幫助。
基于得分 p(q, k),我們使用二元交叉熵作為損失函數(shù)進(jìn)行訓(xùn)練,并參考RotatE 中提出的自對(duì)抗負(fù)采樣來提高難負(fù)樣本的損失權(quán)重。
三、實(shí)驗(yàn)結(jié)果
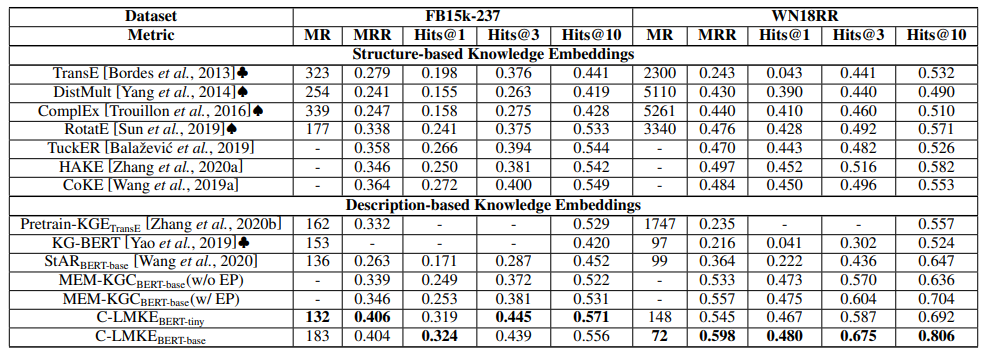
表2 FB15k-237及WN18RR上的鏈接預(yù)測(cè)結(jié)果
我們?cè)?strong>鏈接預(yù)測(cè)和三元組分類兩個(gè)任務(wù)上對(duì)我們的方法進(jìn)行了實(shí)驗(yàn),以BERT-tiny和BERT-base作為基本模型。在鏈接預(yù)測(cè)上,我們的模型顯著超越了現(xiàn)有模型。使用BERT-BASE的C-LMKE在WN18RR上取得了80.6%的 Hits@10,而此前最好的結(jié)果僅為70.4%。即使我們使用 BERT-tiny 作為語言模型,我們的方法取得的表現(xiàn)也優(yōu)于或相當(dāng)于使用更大模型的現(xiàn)有方法。同時(shí),使用BERT-tiny的C-LMKE在FB15k-237上取得了57.1%的Hits@10,是首個(gè)超越基于結(jié)構(gòu)方法的基于文本方法。
一個(gè)有趣的現(xiàn)象是,基于文本的方法在WN18RR上顯著超越基于結(jié)構(gòu)的方法,但在FB15k-237上卻不然。我們認(rèn)為背后的原因是數(shù)據(jù)集的差異。WN18RR來源于字典知識(shí)圖譜WordNet,其中的實(shí)體是詞而文本描述是詞的定義,而從詞的定義中可以很容易推出詞之間的關(guān)系。相對(duì)地,F(xiàn)B15k-237來源于真實(shí)知識(shí)圖譜Freebase,其中的文本僅部分地描述了一個(gè)實(shí)體最廣為人知的知識(shí),比如(愛因斯坦,是,和平主義者)這一知識(shí)就不被它們的文本描述所涵蓋。因此,過度依賴于文本而非結(jié)構(gòu)信息可能導(dǎo)致模型表現(xiàn)不佳。這也解釋了在該數(shù)據(jù)集上使用BERT-tiny替換 BERT-base后表現(xiàn)沒有下降。
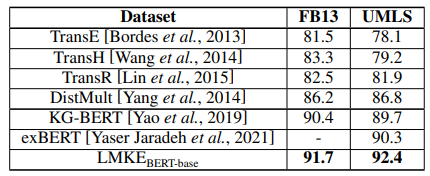
表3 FB13和UMLS上的三元組分類結(jié)
LMKE 在三元組分類任務(wù)上也取得了最優(yōu)的表現(xiàn)。其中,LMKE和KG-BERT的差距代表了引入實(shí)體和關(guān)系作為特殊詞的有效性。
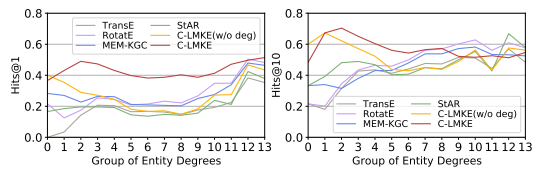
圖5 不同模型對(duì)于FB15k-237中包含不同度數(shù)實(shí)體的三元組的平均表現(xiàn)
為了展示我們的方法在長尾實(shí)體表示上的有效性,我們將實(shí)體按度數(shù)的對(duì)數(shù)進(jìn)行分組,統(tǒng)計(jì)包含不同度數(shù)實(shí)體的三元組,并研究包含不同度數(shù)實(shí)體的三元組上的表現(xiàn)。實(shí)驗(yàn)結(jié)果表明,基于文本的方法在低度數(shù)組 0,1,2(即包含度數(shù)低于 4 的實(shí)體的三元組)上的表現(xiàn)顯著優(yōu)于基于結(jié)構(gòu)的方法,而C-LMKE又顯著優(yōu)于其他的基于文本的方法。同時(shí),在加入了度數(shù)信息后,C-LMKE在中高度數(shù)組上的表現(xiàn)有了顯著提升。
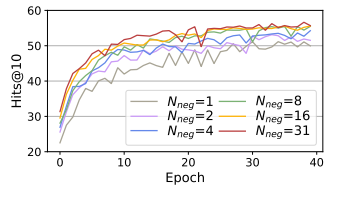
圖6 不同負(fù)采樣率下C-LMKE在FB15k-237上的表現(xiàn)
我們進(jìn)一步研究了負(fù)采樣率對(duì)基于文本的知識(shí)嵌入學(xué)習(xí)的影響。我們將batch size 設(shè)為32,因此 1 個(gè)正樣本最多配有31個(gè)負(fù)樣本,而我們進(jìn)一步限制可見負(fù)樣本數(shù)為{1, 2, 4, 8, 16}。實(shí)驗(yàn)結(jié)果表明,更大的負(fù)采樣率能顯著提升模型的表現(xiàn),證明了負(fù)采樣率對(duì)基于文本的方法的重要性。然而,現(xiàn)有基于文本方法受限于負(fù)樣本編碼代價(jià),一般僅使用1個(gè)或5個(gè)負(fù)樣本。
總結(jié)起來,我們的貢獻(xiàn)主要有以下三點(diǎn):
①我們注意到基于結(jié)構(gòu)的知識(shí)嵌入在表示長尾實(shí)體上的不足,并首次提出利用文本信息和語言模型來提升長尾實(shí)體的表示。
②我們提出了一個(gè)基于文本的新模型LMKE,解決了現(xiàn)有基于文本方法的三個(gè)不足之處。同時(shí),我們也首次提出將基于文本的知識(shí)嵌入學(xué)習(xí)建模為對(duì)比學(xué)習(xí)問題。
③我們?cè)诙鄠€(gè)知識(shí)嵌入數(shù)據(jù)集上進(jìn)行了廣泛實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果表明LMKE 在三元組分類和鏈接預(yù)測(cè)任務(wù)上取得了state-of-the-art 的表現(xiàn),顯著超越現(xiàn)有知識(shí)嵌入方法,使得基于文本的方法首次在數(shù)據(jù)集FB15K-237 上超越基于結(jié)構(gòu)的方法。
筆者認(rèn)為,LMKE提出的對(duì)比學(xué)習(xí)框架將是基于文本的知識(shí)嵌入的發(fā)展方向。在這一方向上,我們?nèi)钥蓞⒖紝?duì)比學(xué)習(xí)領(lǐng)域的優(yōu)秀方法來取得進(jìn)一步提升。同時(shí),信息檢索、實(shí)體鏈接在本質(zhì)上也是鏈接預(yù)測(cè)任務(wù),近年來也越來越多地采用了對(duì)比學(xué)習(xí),我們也可以從這些領(lǐng)域的工作中吸取經(jīng)驗(yàn)。
最后,我們注意到被 ACL 2022 接收的同期工作SimKGC同樣提出了基于文本的知識(shí)嵌入的對(duì)比學(xué)習(xí)框架,在 WN18RR 上取得了與我們相當(dāng)?shù)谋憩F(xiàn),并研究了負(fù)采樣對(duì)于基于文本方法的重要性。這進(jìn)一步說明了對(duì)比學(xué)習(xí)框架在基于文本的知識(shí)嵌入的發(fā)展上的必然性。SimKGC相較于LMKE,使用了更龐大的算力(32 倍的 batch size)、余弦相似度度量、InfoNCE損失以及基于圖的Reranking策略,產(chǎn)出了值得我們借鑒的結(jié)果,不過他們?cè)谑聦?shí)知識(shí)圖譜FB15k-237上的表現(xiàn)仍未超越基于結(jié)構(gòu)的方法。LMKE相較于SimKGC,則還關(guān)注了長尾實(shí)體表示、三元組分類任務(wù)以及度信息的重要性。
審核編輯:劉清
-
編碼
+關(guān)注
關(guān)注
6文章
935瀏覽量
54763 -
CLS
+關(guān)注
關(guān)注
0文章
9瀏覽量
9696 -
語言模型
+關(guān)注
關(guān)注
0文章
506瀏覽量
10245
原文標(biāo)題:語言模型用作知識(shí)嵌入
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
三星自主研發(fā)知識(shí)圖譜技術(shù),強(qiáng)化Galaxy AI用戶體驗(yàn)與數(shù)據(jù)安全
【《大語言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)知識(shí)學(xué)習(xí)
【《大語言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)篇
【《大語言模型應(yīng)用指南》閱讀體驗(yàn)】+ 俯瞰全書
三星電子將收購英國知識(shí)圖譜技術(shù)初創(chuàng)企業(yè)
知識(shí)圖譜與大模型之間的關(guān)系
rup是一種什么模型
Al大模型機(jī)器人
【大語言模型:原理與工程實(shí)踐】大語言模型的應(yīng)用
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實(shí)踐】揭開大語言模型的面紗
利用知識(shí)圖譜與Llama-Index技術(shù)構(gòu)建大模型驅(qū)動(dòng)的RAG系統(tǒng)(下)

大語言模型中的語言與知識(shí):一種神秘的分離現(xiàn)象
知識(shí)圖譜基礎(chǔ)知識(shí)應(yīng)用和學(xué)術(shù)前沿趨勢(shì)
一種新穎的大型語言模型知識(shí)更新微調(diào)范式






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論