") 淺析歸納偏置對模型縮放的影響
淺析歸納偏置對模型縮放的影響
谷歌、DeepMind:以 Transformer 為例,淺析歸納偏置對模型縮放的影響。
Transformer 模型的縮放近年來引發(fā)了眾多學(xué)者的研究興趣。然而,對于模型架構(gòu)所施加的不同歸納偏置的縮放性質(zhì),人們了解得并不多。通常假設(shè),在特定標(biāo)度(計算、大小等)的改進(jìn)可以遷移到不同的規(guī)模和計算區(qū)域。
不過,理解架構(gòu)和標(biāo)度律之間的相互作用至關(guān)重要,設(shè)計在不同標(biāo)度上表現(xiàn)良好的模型具有重要的研究意義。有幾個問題還需要搞清楚:模型體系架構(gòu)之間的縮放性不同嗎?如果是這樣,歸納偏置如何影響縮放表現(xiàn)?又如何影響上游(預(yù)訓(xùn)練)和下游(遷移)任務(wù)?
在最近的一篇論文中,谷歌的研究者試圖了解歸納偏置(體系架構(gòu))對語言模型標(biāo)度律的影響。為此,研究者在多個計算區(qū)域和范圍內(nèi)(從 1500 萬到 400 億參數(shù))預(yù)訓(xùn)練和微調(diào)了十種不同的模型架構(gòu)。總體來說,他們預(yù)訓(xùn)練和微調(diào)了 100 多種不同體系架構(gòu)和大小的模型,并提出了在縮放這十種不同體系架構(gòu)方面的見解和挑戰(zhàn)。

論文鏈接:https://arxiv.org/pdf/2207.10551.pdf
他們還注意到,縮放這些模型并不像看起來那么簡單,也就是說,縮放的復(fù)雜細(xì)節(jié)與本文中詳細(xì)研究的體系架構(gòu)選擇交織在一起。例如,Universal Transformers (和 ALBERT) 的一個特性是參數(shù)共享。與標(biāo)準(zhǔn)的 Transformer 相比,這種體系架構(gòu)的選擇不僅在性能方面,而且在計算指標(biāo)如 FLOPs、速度和參數(shù)量方面顯著 warp 了縮放行為。相反,像 Switch Transformers 這樣的模型則截然不同,它的 FLOPs 和參數(shù)量之間的關(guān)系是不尋常的。
具體來說,本文的主要貢獻(xiàn)如下:
首次推導(dǎo)出不同歸納偏置和模型架構(gòu)的標(biāo)度律。研究者發(fā)現(xiàn)這個標(biāo)度系數(shù)在不同的模型中有很大的不同,并指出這是模型開發(fā)中的一個重要考慮因素。事實證明,在他們考慮的所有十種體系架構(gòu)中,普通的 Transformer 擁有最好的縮放性能,即使它在每個計算區(qū)域的絕對性能不是最好的。
研究者觀察到,在一個計算標(biāo)度區(qū)域中運行良好的模型不一定是另一個計算標(biāo)度區(qū)域中的最佳模型。此外,他們發(fā)現(xiàn),某些模型盡管在低計算區(qū)域表現(xiàn)良好 ,但是難以進(jìn)行縮放。這意味著很難通過在某個計算區(qū)域進(jìn)行逐點對比來獲得模型縮放性的全貌。
研究者發(fā)現(xiàn),當(dāng)涉及到縮放不同的模型架構(gòu)時,上游預(yù)訓(xùn)練的困惑度可能與下游遷移不太相關(guān)。因此,底層架構(gòu)和歸納偏置對于下游遷移也是至關(guān)重要的。
研究者強調(diào)了在某些架構(gòu)下進(jìn)行縮放的困難,并展示了一些模型沒有進(jìn)行縮放(或以消極趨勢進(jìn)行縮放)。他們還發(fā)現(xiàn)線性時間注意力模型(比如 Performer)難以進(jìn)行擴(kuò)展的趨勢。
方法與實驗
在論文的第三章,研究者概述了整體的實驗設(shè)置,并介紹了實驗中評估的模型。
下表 1 展示了本文的主要結(jié)果,包括可訓(xùn)練參數(shù)量、FLOPs(單次正向傳遞)和速度(每秒步數(shù))等,此外還包括了驗證困惑度(上游預(yù)訓(xùn)練)和 17 個下游任務(wù)的結(jié)果。
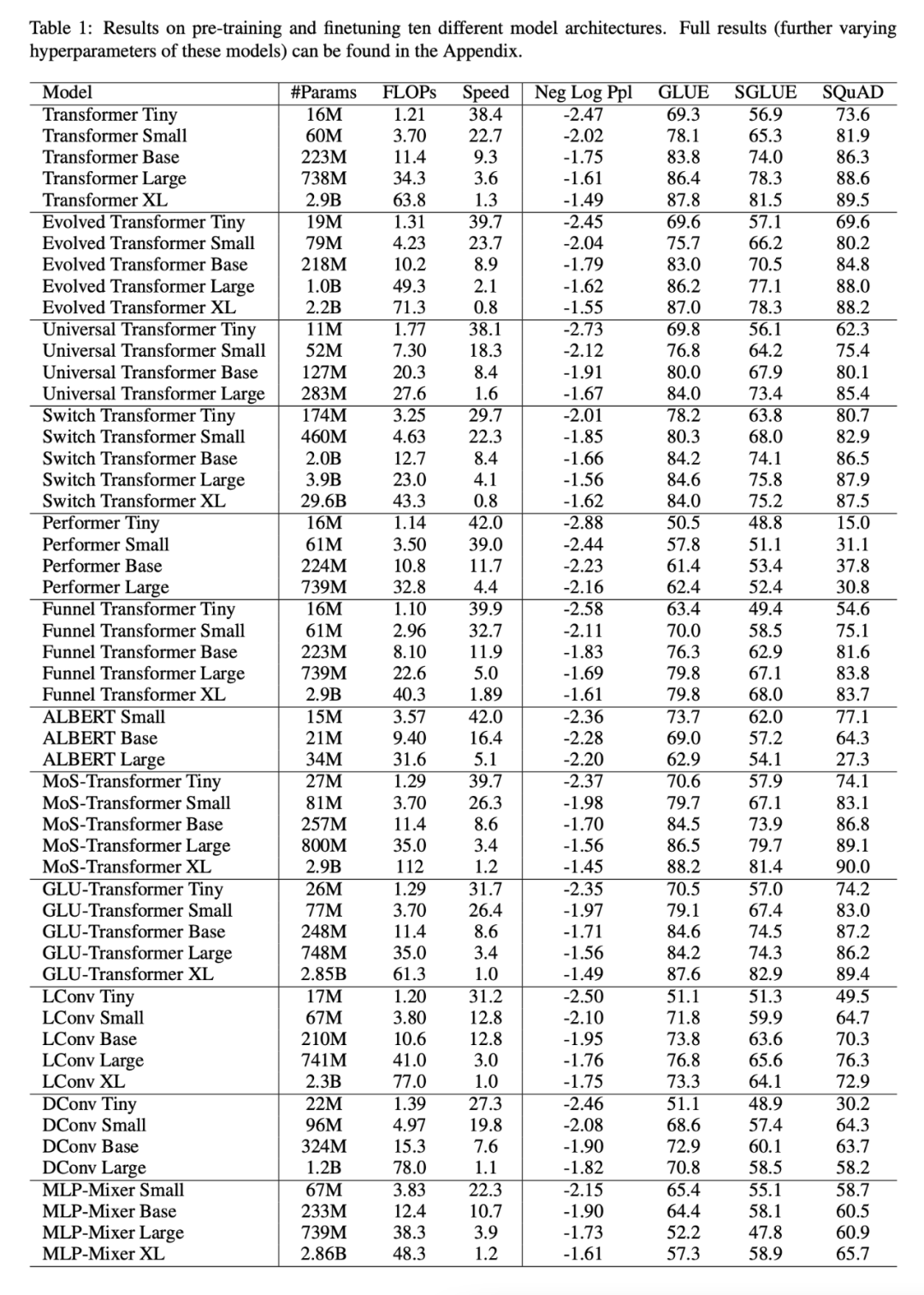
所有模型的縮放方式是否相同?
下圖 2 展示了增加 FLOPs 數(shù)量時所有模型的縮放行為。可以觀察到,所有模型的縮放行為是相當(dāng)獨特和不同的,即其中大多數(shù)不同于標(biāo)準(zhǔn) Transformer。也許這里最大的發(fā)現(xiàn)是,大多數(shù)模型(例如 LConv、Evolution)似乎都與標(biāo)準(zhǔn) Transformer 表現(xiàn)相當(dāng)或更好,但無法按照更高的計算預(yù)算去縮放。
另一個有趣的趨勢是,「線性」Transformer,如 Performer,不能按比例縮放。如圖 2i 所示,從 base 到 large scale 相比,預(yù)訓(xùn)練的困惑度只下降了 2.7% 。而對于 vanilla Transformer 來說這一數(shù)字是 8.4%。
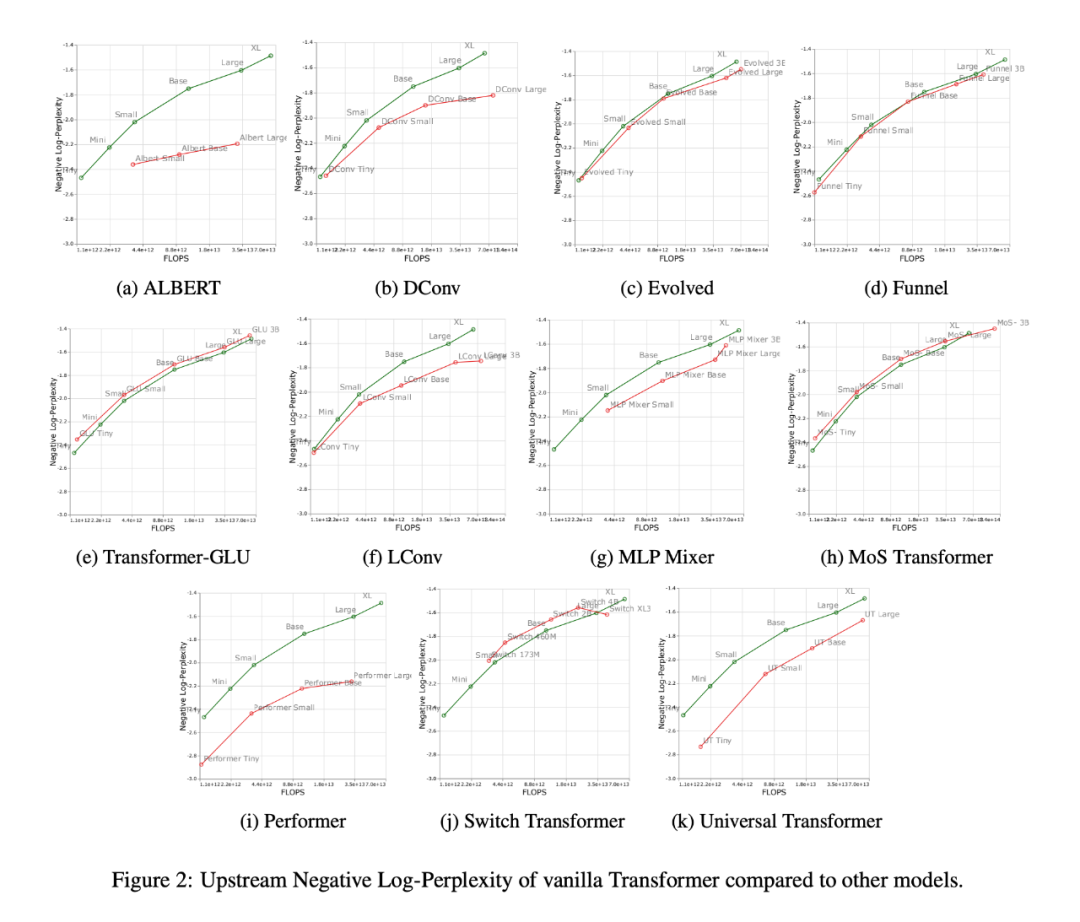
下圖 3 展示了下游遷移任務(wù)上所有模型的縮放曲線,可以發(fā)現(xiàn),和 Transformer 相比,大多數(shù)模型有著不同的縮放曲線,在下游任務(wù)中變化明顯。值得注意的是,大多數(shù)模型都有不同的上游或下游縮放曲線。
研究者發(fā)現(xiàn),一些模型如 Funnel Transformer 和 LConv,似乎在上游表現(xiàn)相當(dāng)不錯,但在下游受到很大影響。至于 Performer,上游和下游的性能差距似乎更大。值得注意的是,SuperGLUE 的下游任務(wù)通常需要編碼器上的偽交叉注意力,而卷積這樣的模型是無法處理的(Tay et al., 2021a)。
因此,研究者發(fā)現(xiàn)盡管某些模型擁有良好的上游性能,但可能還是難以學(xué)習(xí)下游任務(wù)。
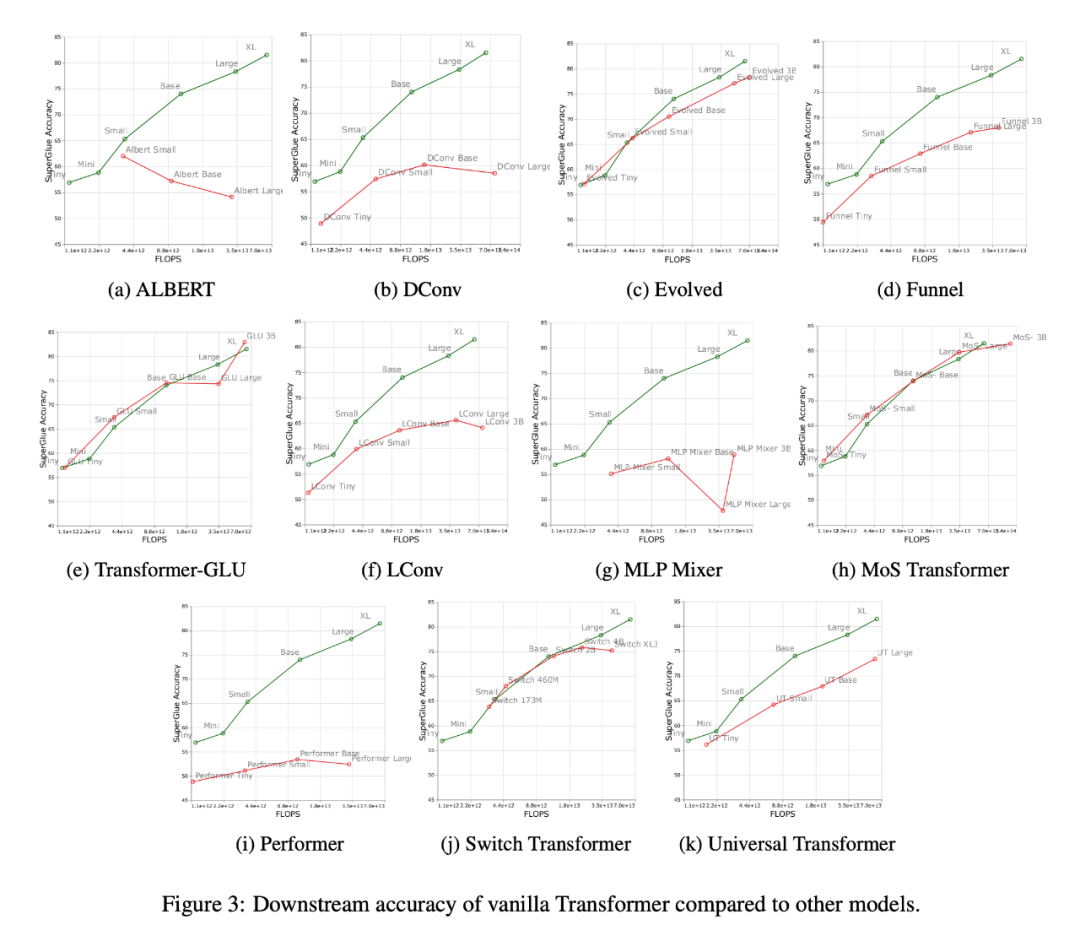
每一標(biāo)度的最佳模型是否有所不同?
下圖 1 展示了根據(jù)上游或下游性能進(jìn)行計算時的帕累托邊界。圖的顏色代表不同的模型,可以觀察到,每個標(biāo)度和計算區(qū)域的最佳模型可能是不同的。此外,從上圖 3 中也可以看到這一點。例如,Evolved Transformer 似乎在微小(tiny)到小(small)的區(qū)域(下游)和標(biāo)準(zhǔn) Transformer 一樣表現(xiàn)很好,但是當(dāng)放大模型時,這種情況迅速改變。研究者在 MoS-Transformer 也觀察到了這一點,它在某些區(qū)域的表現(xiàn)明顯優(yōu)于普通的 Transformer ,但在其他區(qū)域則不然。
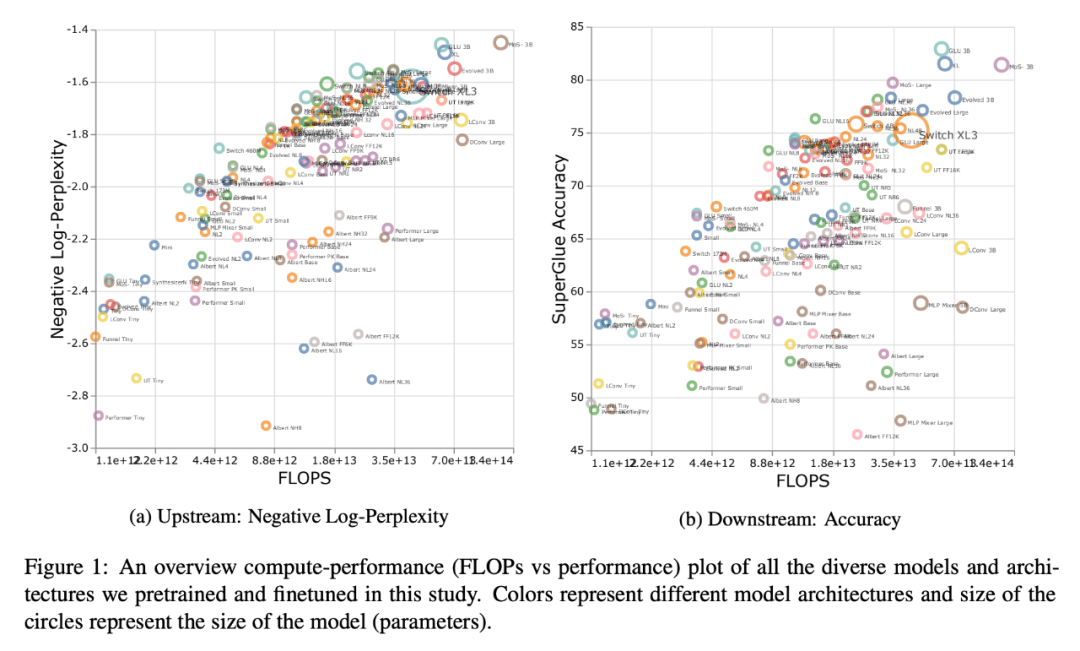
每個模型的標(biāo)度律
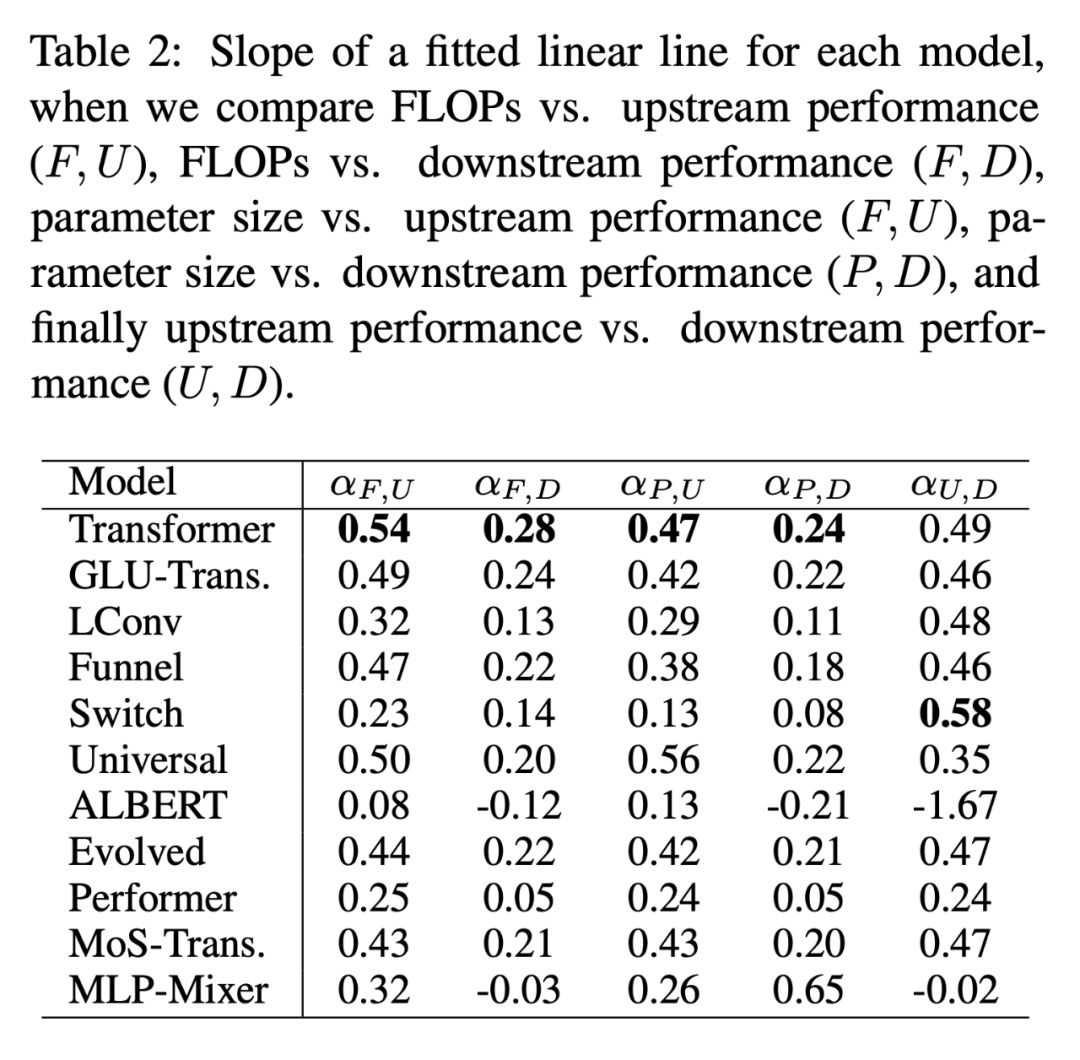
下表 2 給出了多種情況下每個模型的擬合線性直線 α 的斜率。研究者通過繪制 F(FLOPs)、U (上游困惑度)、D (下游準(zhǔn)確率)和 P(參數(shù)量)得到了α。一般來說,α 描述了模型的縮放性,例如 α_F,U 根據(jù)上游性能繪制 FLOPs。唯一的例外是α_U,D,它是衡量上游和下游性能的度量,高的 α_U,D 值意味著向下游任務(wù)遷移的模型縮放更佳。總體來說,α 值是一個度量,表示一個模型在縮放上的相對表現(xiàn)。
Scaling Protocols 是否以同樣的方式影響模型體系架構(gòu)?
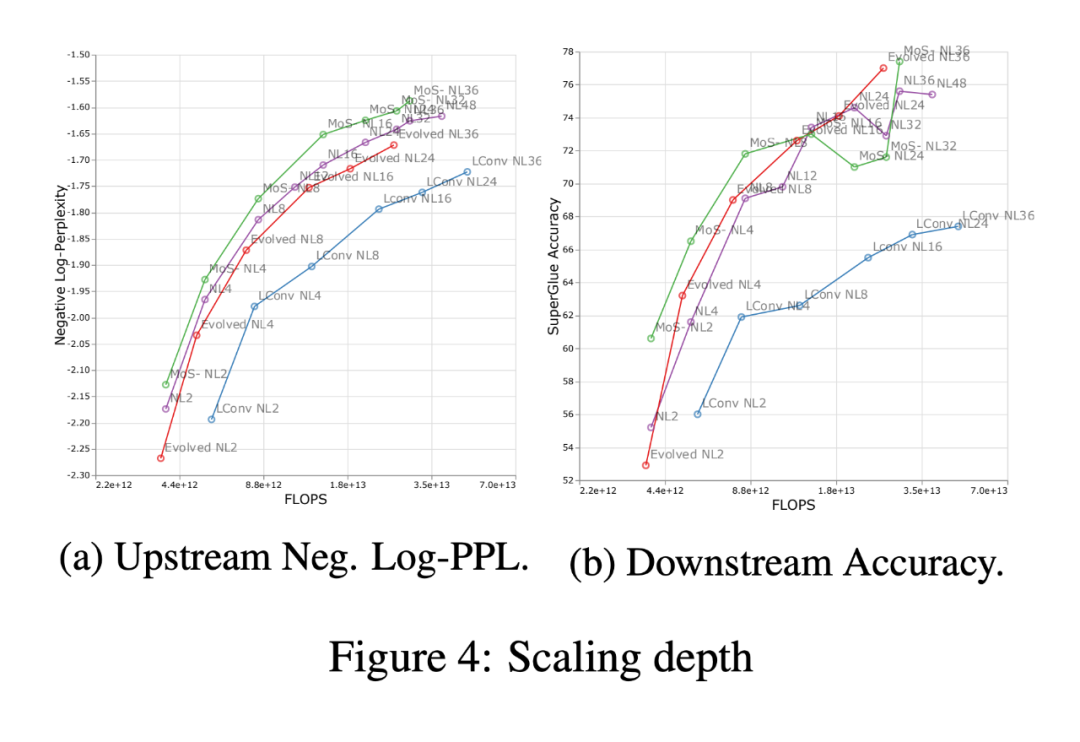
下圖 4 展示了四個模型體系架構(gòu)(MoS-Transformer、Transformer、Evolved Transformer、LConv)中縮放深度的影響。
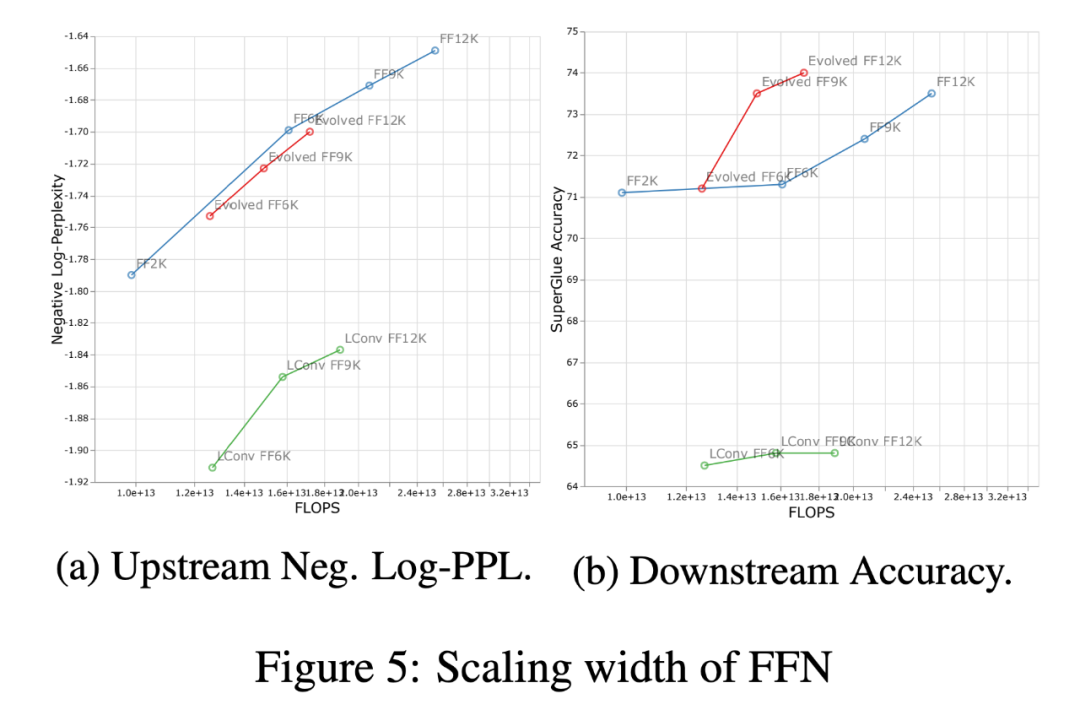
下圖 5 展示了在相同的四個體系架構(gòu)中縮放寬度的影響。首先,在上游(負(fù)對數(shù)困惑)曲線上可以注意到,雖然不同的架構(gòu)在絕對性能上有明顯的差異,但縮放趨勢仍然非常相似。在下游,除了 LConv 之外,深度縮放(上圖 4)在大多數(shù)體系架構(gòu)上的作用似乎是一樣的。同時,相對于寬度縮放,似乎 Evolved Transformer 在應(yīng)用寬度縮放時會稍微好一點。值得注意的是,與寬度縮放相比,深度縮放對下游縮放的影響要大得多。
審核編輯 :李倩
-
谷歌
+關(guān)注
關(guān)注
27文章
6141瀏覽量
105087 -
模型
+關(guān)注
關(guān)注
1文章
3171瀏覽量
48711 -
Transformer
+關(guān)注
關(guān)注
0文章
141瀏覽量
5981
原文標(biāo)題:谷歌、DeepMind新研究:歸納偏置如何影響模型縮放?
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Llama 3 模型訓(xùn)練技巧

什么是偏置器
OPA277共模電阻是250GΩ。電壓的正負(fù)是不是由偏置電流的方向決定的?
【《大語言模型應(yīng)用指南》閱讀體驗】+ 基礎(chǔ)篇
PN結(jié)正向偏置和反向偏置的原理
ai大模型訓(xùn)練方法有哪些?
偏置電路的作用是什么呢
偏置電路是由什么電路構(gòu)成的?
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
1-2B參數(shù)規(guī)模大模型的使用心得





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論