") 評估3D-CoCo在三個廣泛使用的自動駕駛數(shù)據(jù)集上的有效性和泛化性
評估3D-CoCo在三個廣泛使用的自動駕駛數(shù)據(jù)集上的有效性和泛化性
摘要
大多數(shù)現(xiàn)有的點云檢測模型都需要大規(guī)模、密集標注的數(shù)據(jù)集。由于不同的物理環(huán)境或激光雷達傳感器配置引起的幾何變化,它們通常在域適應(yīng)設(shè)置中表現(xiàn)不佳。因此,在不訪問目標域的標簽的情況下,學(xué)習(xí)有標記的源域和新的目標域之間的可遷移特征具有挑戰(zhàn)性但很有價值。為了解決這個問題,我們引入了3D對比協(xié)同訓(xùn)練(3D-CoCo)框架,該框架有兩項技術(shù)貢獻。
1)首先,3D-CoCo 的靈感來自于我們的觀察,即鳥瞰圖 (BEV) 特征比低級幾何特征更容易轉(zhuǎn)移。因此,我們提出了一種新的協(xié)同訓(xùn)練架構(gòu),其中包括具有特定域參數(shù)的單獨 3D 編碼器,以及用于學(xué)習(xí)域不變特征的 BEV 轉(zhuǎn)換模塊。
2)其次,3D-CoCo 將對比實例對齊的方法擴展到點云檢測,其性能在很大程度上受到偽標簽導(dǎo)致的BEV特征的虛擬分布與真實分布之間不匹配的阻礙。通過考慮特定幾何先驗,精心設(shè)計的具有變換點云的3D-CoCo,大大減少了不匹配。 我們使用三個大型 3D 數(shù)據(jù)集構(gòu)建新的域適應(yīng)benchmarks。實驗結(jié)果表明,我們提出的 3D-CoCo 有效地縮小了域差距,并大大優(yōu)于SOTA方法。
一、引言
3D 點云檢測在現(xiàn)實場景中顯示出重要的意義,例如自動駕駛 ,而最近的進展主要是由高精度 LiDAR 傳感器和大規(guī)模、密集標注的點云數(shù)據(jù)集 的出現(xiàn)推動的。
大多數(shù)現(xiàn)有的 3D 檢測模型都假設(shè)訓(xùn)練域和測試域是獨立且同分布的。然而,在實踐中,由于物理環(huán)境或 LiDAR 傳感器配置的差異,包括不同數(shù)量的激光束和安裝位置等,域轉(zhuǎn)移通常是不可避免的。
為了解決這個問題,關(guān)于點云檢測的無監(jiān)督域適應(yīng)問題的早期研究,其目的是通過學(xué)習(xí)可遷移特征,將3D檢測器從有標記的源域有效地適配到新的無標記的目標域。
以前的圖像數(shù)據(jù)的域適應(yīng)方法并不容易適用于點云。如圖 1 所示,與 2D 場景的域偏移通常存在于圖像外觀不同,3D 場景的域偏移主要體現(xiàn)在點云的幾何變化上。由于來自不同域的 2D 圖像具有相同的均勻分布像素的網(wǎng)格拓撲,因此大多數(shù)域適應(yīng)方法都利用了具有域共享參數(shù)的圖像編碼器,現(xiàn)有的 3D 遷移學(xué)習(xí)模型(如 PointDAN )也采用了這種方法。然而,由于不同點集之間存在嚴重的low-level幾何偏移,我們認為某些特征是可遷移的,而某些特征不能用于 3D 目標檢測,這需要重新考慮不同級的點云表征的可遷移性。
為此,我們提出了一個名為 3D Contrastive Co-training (3D-CoCo) 的新框架,其架構(gòu)包含具有特定域參數(shù)的單獨 3D 編碼器、與領(lǐng)域無關(guān)的 BEV 轉(zhuǎn)換模塊和最終檢測頭。架構(gòu)設(shè)計的關(guān)鍵思想是,具有類似于圖像的網(wǎng)格結(jié)構(gòu)的 BEV 特征可以比低級 3D 特征更具可遷移性,從而可以更好地與 2D 視覺中的高級遷移學(xué)習(xí)技術(shù)集成,從而大大減少幾何偏移。與特定域編碼器協(xié)同訓(xùn)練架構(gòu)的另一個好處是,除了改善域適應(yīng)結(jié)果外,它還保持了域內(nèi)的性能。
圖 1:2D場景 和 3D 場景之間域偏移的比較。
1)左圖:2D 場景中的域偏移主要體現(xiàn)在外觀變化上,例如自動駕駛中的天氣或環(huán)境變化。
2)右圖:3D 域偏移通常表示為幾何變化,這不僅來自外部環(huán)境,還來自內(nèi)部傳感器配置。 此外,3D-CoCo 還具有一個新的端到端對比學(xué)習(xí)框架,該框架包含兩個主要組件,即基于鳥瞰圖 (BEV) 特征的對比實例對齊,以及使用轉(zhuǎn)換的點云的困難樣本挖掘。對比實例對齊的目的是,將由偽標簽誘導(dǎo)的相似樣本簇的特征質(zhì)心推到彼此更近的位置,無論它們是在同一域還是不同域中。
此外,我們考慮了 BEV 特征的真實分布與用于對比學(xué)習(xí)的虛擬特征分布之間的不匹配,這是由有偏差的偽標簽引起的。具體來說,我們利用點云的可編輯性,通過對 3D 數(shù)據(jù)應(yīng)用特定的變換函數(shù)來執(zhí)行困難樣本挖掘。困難樣本作為對比協(xié)同訓(xùn)練的有效補充,可以進一步減少跨域的幾何偏移,防止自適應(yīng)模型陷入局部最小值。 值得注意的是,還有另一項工作討論了點云檢測的遷移學(xué)習(xí),它利用了自訓(xùn)練pipeline,使用目標域數(shù)據(jù)上的偽標簽重新訓(xùn)練模型。
與這些方法相比,我們采用了不同的問題設(shè)置,使用有標記的源域數(shù)據(jù)和未標記的目標域數(shù)據(jù)進行協(xié)同訓(xùn)練。通過消融研究,我們觀察到單獨編碼器和對比協(xié)同訓(xùn)練方案,可以逐步過濾特定域的特征,并學(xué)習(xí)更多跨域的可轉(zhuǎn)移知識。 我們評估了 3D-CoCo 在三個廣泛使用的自動駕駛數(shù)據(jù)集上的有效性和泛化性,這些數(shù)據(jù)集由異構(gòu)激光雷達傳感器收集,包括Waymo、nuScenes和KITTI。
3D-CoCo 被證明在不同的無監(jiān)督域適應(yīng)benchmarks上,顯著優(yōu)于現(xiàn)有的點云檢測方法。
二、預(yù)備工作 問題設(shè)置。
點云檢測的傳統(tǒng)設(shè)置是學(xué)習(xí)一個基本的 3D對象檢測器 D,它從點云P中對由Y表示的m個對象進行分類和定位:


與點云檢測的典型設(shè)置相比,我們更關(guān)注模型在目標域測試集上的性能,這需要額外的精心設(shè)計的模塊來學(xué)習(xí)可遷移的特征。
當(dāng)前的點云探測器。
當(dāng)前的 3D 點云檢測器通常由三個模塊組成:3D 編碼器 E、鳥瞰圖 (BEV) 轉(zhuǎn)換模塊 U 和檢測頭 H。

為了證明所提出方法的通用性,我們采用了兩種主流架構(gòu),即 VoxelNet 和 PointPillars ,并使用不同的點云處理pipelines作為 3D 編碼器的替代方案。VoxelNet 將點云量化為小的 3D 體素特征,然后使用 3D CNN 沿體素高度將它們壓縮成 2D BEV 空間,而 PointPillars 將點云量化為固定尺寸大小的 2D 網(wǎng)格上的垂直柱,然后對每個柱執(zhí)行線性轉(zhuǎn)換和最大池化以獲得 BEV 表征。但他們都沒有明確考慮遷移學(xué)習(xí)設(shè)置中的域偏移。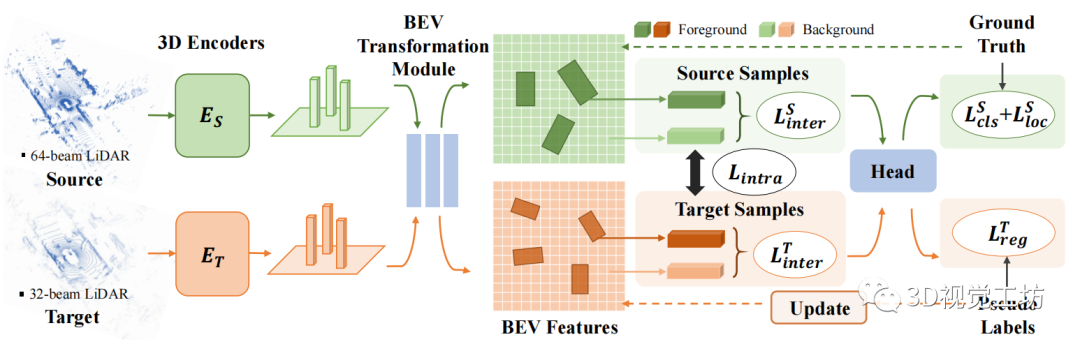
圖 2:所提出的 3D-CoCo 模型的示意圖,其中包含特定域的 3D 編碼器,并對 BEV 特征執(zhí)行對比自適應(yīng)以實現(xiàn)實例級的特征對齊。
三、方法
我們提出 3D-CoCo 作為點云檢測中無監(jiān)督域適應(yīng)任務(wù)的可行解決方案。它對從異構(gòu)幾何中學(xué)習(xí)可遷移特征有兩個貢獻,分別是:位于新架構(gòu)設(shè)計中,如圖 2 所示;以及通過困難樣本挖掘來增強的對比實例對齊框架,如圖 3所示。
3.1 3D-CoCo 架構(gòu) 特定域的 3D 編碼器。
由于不同的物理環(huán)境和傳感器配置,3D 場景中的遷移學(xué)習(xí)可能會遭受劇烈的幾何變化,例如點云的密度變化和不同的遮擋率。盡管一些工作已經(jīng)探索了 3D 前置任務(wù)的模型預(yù)訓(xùn)練 ,但與 2D 場景相比,3D 視覺仍然缺乏可轉(zhuǎn)移的、經(jīng)過良好預(yù)訓(xùn)練的backbone。一個可能的原因是很難減少 3D 編碼器底層幾何表示的域偏移。
直觀地說,我們期望 3D 檢測網(wǎng)絡(luò)能夠逐步處理特定域的不可遷移特征,并學(xué)習(xí)領(lǐng)域不變的語義特征。如圖 2 所示,我們提出了一種具有特定域 3D 編碼器的新型模型架構(gòu),它學(xué)習(xí)不同的映射函數(shù)來解析 LiDAR 點,并將其轉(zhuǎn)換為不同領(lǐng)域的鳥瞰圖 (BEV) 空間。值得注意的是,協(xié)同訓(xùn)練架構(gòu)不僅有利于目標域的適應(yīng)性能,而且有助于保持源域的性能,因為在不同編碼器上學(xué)習(xí)可遷移特征可以促進雙向的知識共享。
與領(lǐng)域無關(guān)的 BEV 轉(zhuǎn)換模塊。
2D 轉(zhuǎn)換模塊與來自源域和目標域的數(shù)據(jù)樣本共同訓(xùn)練。它進一步將特定域的 3D 編碼器的輸出壓縮到 BEV 特征圖 M 中。BEV 特征應(yīng)該更具可遷移性,因為它們與 2D 視覺中基于網(wǎng)格的特征圖具有相似的結(jié)構(gòu),因此可以輕松集成到現(xiàn)有的遷移學(xué)習(xí)技術(shù)。基于 M,我們執(zhí)行對比對齊訓(xùn)練方案,以鼓勵學(xué)習(xí)域不變特征。
檢測頭。
檢測頭對 BEV 特征圖 M 中的 3D 對象進行分類和定位。給定來自源域的標記樣本,檢測頭被訓(xùn)練以最小化:

算法 1: 3D 對比協(xié)同訓(xùn)練 (3D-CoCo) 的學(xué)習(xí)過程

3.2 困難樣本增強對比對齊
由于點云的特征分布稀疏,使用全局分布對齊很難實現(xiàn)域間的有效匹配。因此,我們建議在實例級別利用細粒度對齊,這通過困難樣本挖掘得到增強,以避免不良的局部最小值。



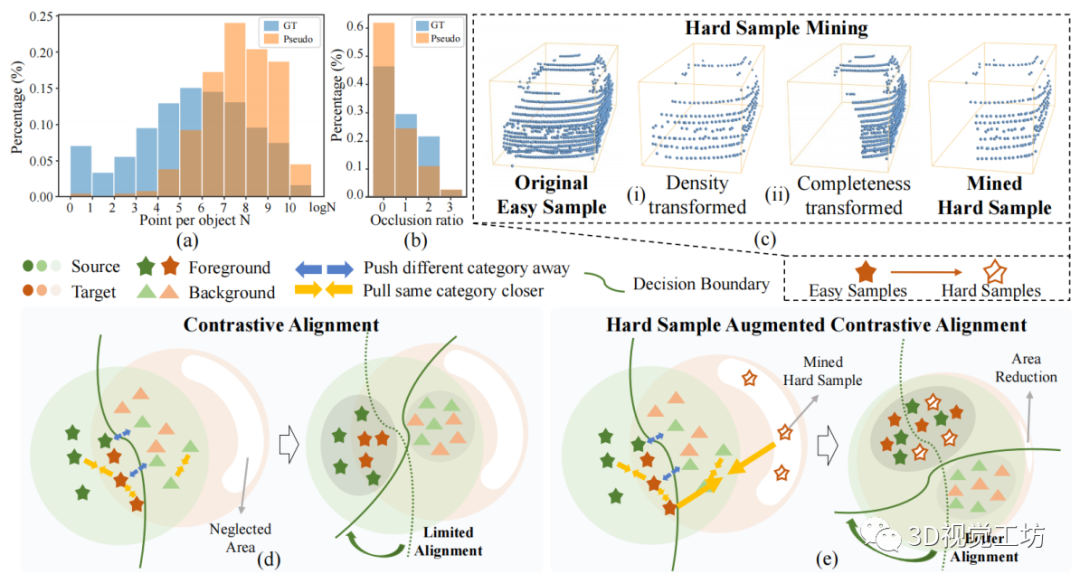
圖 3:困難樣本增強對比對齊的idea。
(a-b) 一個簡單的對比對齊的使用,引入了目標域中偽標簽的樣本分布和ground truth之間的點密度和遮擋率不匹配。
(c) 困難樣本挖掘通過考慮特定的幾何不匹配來轉(zhuǎn)換點云。
(d) 原始的對比對齊更側(cè)重于對 3D 場景中 easy samples對齊,而不是易被忽略的、具有嚴重遮擋或密度變化的困難樣本。
(e) 3D-CoCo的對比對齊方案,通過轉(zhuǎn)換后的困難樣本有效地增強,以實現(xiàn)進一步的對齊
點云轉(zhuǎn)換為困難樣本。
對比實例對齊的直接使用,往往會導(dǎo)致由偽標簽獲得的樣本分布與目標域上的ground truths之間的不匹配。
首先,如圖 3(a) 所示,偽標簽更集中在點云密集的模式中,而不是點云稀疏的模式中。
其次,如圖 3(b) 所示,偽標簽不能完全覆蓋嚴重遮擋的模式。 因此,大多數(shù)由正偽標簽誘導(dǎo)的實例,可以被視為具有足夠點或完整幾何的“簡單樣本”。然而,我們認為被忽視的“困難樣本”更可能分布在如圖 3(d) 所示的邊緣區(qū)域,對于 3D 遷移學(xué)習(xí)同樣重要。 如圖 3(e) 所示,挖掘困難樣本可以進一步促進分布對齊,并防止模型過擬合不良的局部最小值。創(chuàng)建虛擬困難樣本的關(guān)鍵是考慮圖 3(a-b) 所示的幾何變化的先驗。我們在這里提出了兩種機制來創(chuàng)建虛擬的困難樣本。
如圖 3(c) 所示,第一種變換方法,均勻地丟棄現(xiàn)有密集點云中的點,模擬激光束數(shù)量的變化。第二種方法通過破壞簡單樣本的完整幾何形狀,來模擬對象遮擋。具體來說,我們計算某個樣本的視點,隨機選擇一部分視點,丟棄這些角度上的點云。與以前應(yīng)用于 3D 檢測的常見增強策略(例如旋轉(zhuǎn)和翻轉(zhuǎn))相比 ,變換后的點云通過減少偽標簽引起的目標域的分布不匹配,來專注于有效的對比實例對齊,而不是旨在豐富源域的樣本多樣性。
整體訓(xùn)練流程。
我們提出了一個帶有 warm-up 過程的逐步訓(xùn)練程序,如算法1所示。具體來說,我們首先在有標記的源域上預(yù)訓(xùn)練一個源檢測器,并使用它在目標集上生成偽標簽。然后我們進行困難樣本挖掘(HSM)并增加目標集。接下來,我們按照方程式 (6) 來預(yù)熱 3D-CoCo 檢測模型。這允許在訓(xùn)練的早期階段,更穩(wěn)定的收斂。對于剩余的epochs,我們使用集成和投票機制,更新偽標簽。在逐步協(xié)同訓(xùn)練中,Dθ 逐漸適應(yīng)目標域,同時保持域內(nèi)的性能。
四、實驗
4.1 實驗設(shè)置 數(shù)據(jù)集。
我們在三個廣泛使用的、基于 LiDAR 的數(shù)據(jù)集上評估 3D-CoCo,包括 Waymo 、nuScenes和 KITTI 。每個數(shù)據(jù)集在外部環(huán)境(即交通狀況)和內(nèi)部傳感器配置(即光束數(shù)量)中,都有特定的屬性,因此它們之間存在巨大的域差距。具體來說:
1)Waymo 數(shù)據(jù)集,在美國全天使用 5 光束LiDAR 傳感器,在多種天氣條件下收集的。
2)nuScenes 數(shù)據(jù)集,由 32 光束激光雷達傳感器在美國和新加坡收集。
3)KITTI數(shù)據(jù)集,在陽光明媚的白天由德國的 64 光束 LiDAR 傳感器收集。 我們在數(shù)據(jù)集之間構(gòu)建了 4 個域適應(yīng)benchmarks,包括:(i)Waymo→nuScenes,(ii)nuScenes→Waymo,(iii)Waymo→KITTI,和(iv)nuScenes→KITTI。我們使用三個數(shù)據(jù)集的共同類別,即 Car/Vehicle。在這里,KITTI 僅用作目標域,因為它比其他兩個數(shù)據(jù)集小得多。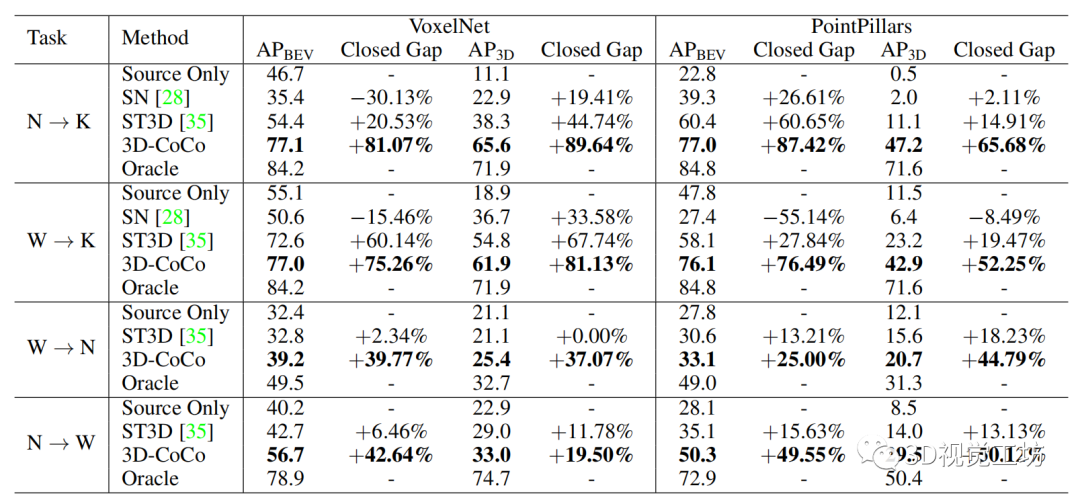
表 1:無監(jiān)督域適應(yīng)的平均精度和相應(yīng)的封閉差距的結(jié)果。請參閱文本以了解度量的定義。
N:nuScenes ;K:KITTI ;W:Waymo 。
模型比較。
如表 1 所示,首先將 3D-CoCo 與僅使用源域數(shù)據(jù)訓(xùn)練的“Source Only”模型進行比較。我們使用包括兩種現(xiàn)有的跨域 3D 檢測方法: 1)SN 通過利用目標域的對象級統(tǒng)計數(shù)據(jù),來規(guī)范源域的對象大小。 2)ST3D [35] 是一種自訓(xùn)練pipeline,通過使用目標域數(shù)據(jù)的偽標簽進行再訓(xùn)練,實現(xiàn)了SOTA的域適應(yīng)結(jié)果。
在與我們相同的base檢測器上,我們重新實現(xiàn)了 SN 和 ST3D。最后,還將 3D-CoCo 與“Oracle”模型進行了比較,該模型使用有標記的目標域數(shù)據(jù)進行訓(xùn)練,以粗略地表示一個適應(yīng)模型在目標域上的最佳性能。

實施細節(jié)。
我們關(guān)注Yin等人,用兩個交替的 3D 編碼器構(gòu)建base檢測器,包括 VoxelNet 和 PointPillars。對于 VoxelNet,我們將體素大小設(shè)置為 (0.1, 0.1, 0.15) m,對于 PointPillars,我們將體素大小設(shè)置為 (0.1, 0.1) m。我們使用學(xué)習(xí)率為 1.5 × 10?3 的 Adam 優(yōu)化器 。我們將 KITTI 數(shù)據(jù)集的最大訓(xùn)練 epoch 數(shù)設(shè)置為 30,Waymo 數(shù)據(jù)集和 nuScenes 數(shù)據(jù)集設(shè)置為 20,warm-up占總 epoch 的一半。
對于偽標簽生成,我們將 0.7 的high-pass閾值應(yīng)用于 IoU ,以獲得前景樣本,并將 0.2 的low-pass閾值應(yīng)用于背景樣本。為了減少數(shù)據(jù)集之間對象大小的域偏移,我們使用隨機對象縮放 (ROS) 策略 ,在使模型適應(yīng) KITTI 數(shù)據(jù)集時,縮放因子在 [0.75, 0.9] 范圍內(nèi)。這樣,與統(tǒng)計歸一化(SN)不同,我們的方法不需要目標域統(tǒng)計的準確先驗知識。
4.2 主要結(jié)果
如表 1 所示,3D-CoCo 在所有適應(yīng)benchmarks上,都大大優(yōu)于所有其他模型。尤其是在基于 VoxelNet 主干的 nuScenes→KITTI 和 Waymo→KITTI 上,3D-CoCo 將 AP3D 中的域差距縮小了大約 81% ~89%。此外,對于兩個大規(guī)模數(shù)據(jù)集(即 Waymo 和 nuScenes)之間的適應(yīng)任務(wù),3D-CoCo 也取得了相當(dāng)大的改進,在 VoxelNet 上將 AP3D 的域差距縮小了 37%,在 PointPillars 上縮小了 50%。
值得注意的是,盡管考慮了 3D 域偏移,SN 和 ST3D 在域適應(yīng)設(shè)置下取得了相對較小的改進,甚至對base模型產(chǎn)生了負面影響(僅源域)。相比之下,盡管從低質(zhì)量的偽標簽開始,3D-CoCo 仍然表現(xiàn)良好,因為有效的協(xié)同訓(xùn)練結(jié)合了有標記的源數(shù)據(jù)和增強的困難樣本。總體結(jié)果驗證了 3D-CoCo 在不同無監(jiān)督域適應(yīng)benchmarks上的可遷移性,以及其泛化到不同檢測網(wǎng)絡(luò)的能力。
4.3 消融研究 架構(gòu)設(shè)計。
所有消融研究都是在 nuScenes→KITTI 上進行的,使用 VoxelNet 作為網(wǎng)絡(luò)backbone。首先,表2 (I) 比較了在模型架構(gòu)中使用不同參數(shù)共享策略的結(jié)果。通過用域共享編碼器替換 3D-CoCo 的特定域 3D 編碼器,我們觀察到 AP3D 的域內(nèi)性能下降了 6.5%,跨域性能下降了 5.3%,這表明由于低級幾何偏移,難以在原始點云上學(xué)習(xí)可遷移的特征。
我們進一步評估了一個包含單獨 BEV 轉(zhuǎn)換模塊的baseline模型,發(fā)現(xiàn)域適應(yīng)性能在 AP3D 中下降了 5.3%。它展示了 BEV 特征的可轉(zhuǎn)移性。此外,我們的模型可以很好地與 ROS 配合使用,ROS 旨在減少目標域上的對象大小偏差,但不可避免地會降低源域上的定位精度。使用不同的 ROS 比例因子值,如表 2(II) 所示,我們的模型在域內(nèi)和跨域評估設(shè)置中始終實現(xiàn)性能提升。
表 2:架構(gòu)設(shè)計的消融研究。
圖1E和2E分別表示使用域共享3D編碼器和單獨的特定域編碼器。1U/2U 表示使用共享/分離的 BEV 轉(zhuǎn)換模塊。所有模型都在所提出的對比對齊框架中,使用了隨機對象縮放ROS 技術(shù)進行訓(xùn)練。在 (I) 中,ROS 比例因子在 [0.75, 0.9] 范圍內(nèi);在 (II) 中,它的范圍在 [0.75, 1.1]。我們報告了域內(nèi)和跨域的性能。
對比學(xué)習(xí)方案。
通過比較表3中的baseline模型 (a) 和 (b) ,我們觀察到平衡背景采樣策略有效地提高了適應(yīng)結(jié)果。通過進一步將模型 (c) 納入比較,這是最終提出的模型,我們驗證了使用相似性優(yōu)先標準的有效性。我們進一步將 3D-CoCo 與現(xiàn)有的prototype-level 對齊方法 進行比較,這些方法計算每個類別的所有樣本的歸一化特征作為對齊的類別級prototypes。
從表 3 中可以看出,由于原型的模糊性,baseline模型 (d) 在實例級對齊情況下比提出的模型 (c) 的性能差得多。此外,如表 4 所示,困難樣本挖掘 (i) 顯著提高了原始的對比實例對齊算法 (e) 的性能,mAP 為 6.8%。通過比較模型(e-g-i),我們可以看到均勻去除和遮擋模擬兩種變換方法,漸進地提高了模型性能。
表 3:對比對齊方案的消融研究。
Bkgd:平衡背景采樣策略;Sim:相似性優(yōu)先準則;Proto:prototype-level對齊,而不是instance-level對齊。
表 4:困難樣本挖掘的消融研究。
Rand:隨機地去除點;Unif:均勻地去除點;Pers:去除某些視角的點以模擬遮擋。
與自訓(xùn)練pipeline的比較。
基于相同的初始化預(yù)訓(xùn)練源模型,我們將協(xié)同訓(xùn)練過程(在圖 4 中表示為 CT)與自訓(xùn)練(表示為 ST)進行比較。在圖 4(a1) 中,在不更新偽標簽的情況下,兩個模型在早期訓(xùn)練階段都有波動,但 3D-CoCo 收斂更快、更穩(wěn)定,比自訓(xùn)練模型具有更高的性能。圖 4(a2)顯示了true positive和false positive預(yù)測的比率,表示為 TPs/FPs。這表明我們的協(xié)同訓(xùn)練方法比自訓(xùn)練baseline產(chǎn)生了更低的檢測噪聲。
此外,通過在訓(xùn)練過程中更新偽標簽,如圖 4(b1-b2) 所示,所提出的協(xié)同訓(xùn)練框架在檢測精度上始終優(yōu)于自訓(xùn)練,并且隨著偽標簽的逐步改善,產(chǎn)生的檢測噪聲極低。
最后,我們對通過不同置信度分數(shù)過濾后的偽標簽進行敏感性分析,其中較低的置信度分數(shù)會帶來更多的噪聲標簽,而較高的置信度分數(shù)往往會錯過positive標簽。如圖 4(c1) 所示,由于自訓(xùn)練完全依賴于偽標簽,因此它對過濾分數(shù)更敏感,而我們的協(xié)同訓(xùn)練框架對偽標簽的質(zhì)量更加魯棒。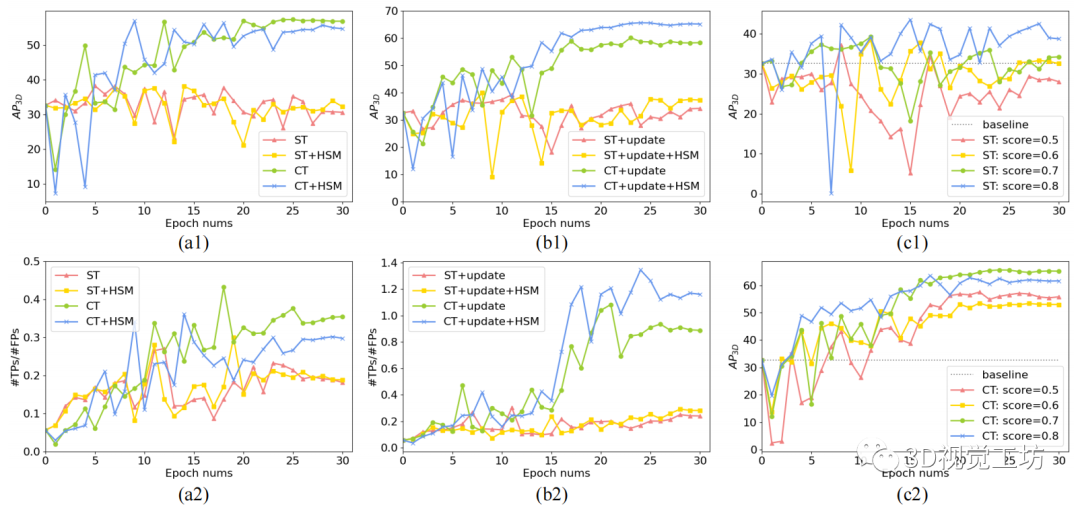
圖 4:自訓(xùn)練 (ST) 和提出的協(xié)同訓(xùn)練 (CT) 方法的比較。(a1-a2) 不更新偽標簽的訓(xùn)練。(b1-b2) 使用逐步更新的偽標簽進行訓(xùn)練。(c1-c2) 使用由不同置信度分數(shù)過濾的偽標簽進行訓(xùn)練。AP3D 表示檢測精度。TPs/FPs 的比率表示檢測噪聲。HSM:困難樣本挖掘。
五、相關(guān)工作 3D點云檢測。
基于 LiDAR 的 3D 檢測器旨在從點云中定位并分類 3D 對象,點云可大致分為兩類:基于點的和基于網(wǎng)格的。基于點的方法將原始點作為輸入,并應(yīng)用 PointNet 來提取逐點特征并為每個點生成proposals。基于網(wǎng)格的方法 提出將點云轉(zhuǎn)換為規(guī)則網(wǎng)格作為模型輸入,其中 Voxelization 是將點云映射為規(guī)則3D 體素的常用技術(shù)。其他方法將點云量化為某些類型的 2D 視圖,例如鳥瞰圖 和范圍視圖 。
與基于點的方法相比,它們效率更高,加速了大規(guī)模數(shù)據(jù)集的訓(xùn)練,如 nuScenes 和 Waymo 。在這項工作中,為了計算效率,我們采用基于anchor-free檢測頭的 VoxelNet 和 PointPillars作為base檢測器。
2D 無監(jiān)督域適應(yīng)。
在 2D 視覺任務(wù)中提出了多種解決方案,包括分類 、檢測 和分割 ,大致可分為兩類:分布對齊 和自訓(xùn)練 。對于第一組,對抗學(xué)習(xí)被用來在特征空間中執(zhí)行對齊。此外,對比學(xué)習(xí)也被用于細粒度的特征對齊[10,31,24,40]。此外,一些作品借用圖像轉(zhuǎn)換技術(shù)在像素級別執(zhí)行對齊 。至于第二組,自訓(xùn)練方法通常分配偽標簽來指導(dǎo)目標域上的再訓(xùn)練過程。
與這些方法相比,3D-CoCo 源于 3D 幾何位移的獨特屬性。通過使用特定域的編碼器、與領(lǐng)域無關(guān)的 BEV 轉(zhuǎn)換模塊和轉(zhuǎn)換后的點集,它有效地將原始的對比適應(yīng)方法擴展到 3D 對象檢測。
3D 無監(jiān)督域適應(yīng)。
最近的一些工作有效地減少了點云分類 和語義分割 中的域偏移。在本文中,我們專注于 3D 目標檢測的域適應(yīng)任務(wù),該任務(wù)只有少數(shù)研究工作進行了討論。統(tǒng)計歸一化方法 通過使用目標域的已知統(tǒng)計數(shù)據(jù)來歸一化源域的對象大小,進而縮小 3D 域偏移,這在無監(jiān)督自適應(yīng)任務(wù)中通常是不可用的。
為了解決這個問題,SF-UDA 使用時間相關(guān)性來估計目標域中的尺度,并通過轉(zhuǎn)換偽標簽的尺度來重新訓(xùn)練目標域數(shù)據(jù)上的檢測模型。目前的工作 進一步探索了目標域數(shù)據(jù)上的偽標簽生成機制,作為自訓(xùn)練的監(jiān)督信號。由于自訓(xùn)練方法的適應(yīng)過程可能會被有噪聲的偽標簽誤導(dǎo),這些方法利用復(fù)雜的策略來提高偽標簽的質(zhì)量。與自訓(xùn)練相比,3D-CoCo 利用協(xié)同訓(xùn)練框架,在該框架中,有標記的源數(shù)據(jù)可以在適應(yīng)過程中為檢測模型提供更穩(wěn)定的監(jiān)督。
六、結(jié)論
在本文中,我們提出了用于點云檢測的無監(jiān)督域適應(yīng)的 3D-CoCo。3D-CoCo 包含一個新穎的模型架構(gòu)和一個新的對比學(xué)習(xí)框架。基于 BEV 特征在 3D 場景中比低級幾何特征更具可轉(zhuǎn)移性的特點,我們創(chuàng)新性地提出集成領(lǐng)域特定的 3D 編碼器與領(lǐng)域無關(guān)的 BEV 轉(zhuǎn)換模塊。然后,我們對 BEV 特征進行了對比實例對齊,通過困難樣本挖掘來增強。三個自動駕駛數(shù)據(jù)集的實驗,顯示了 3D-CoCo 的有效性。作為 3D 點云檢測關(guān)于遷移學(xué)習(xí)問題的試點工作,我們遵循無監(jiān)督域適應(yīng)的典型訓(xùn)練設(shè)置,在訓(xùn)練時比現(xiàn)有的自訓(xùn)練方法占用更多的內(nèi)存。
審核編輯:劉清
-
編碼器
+關(guān)注
關(guān)注
45文章
3595瀏覽量
134150 -
檢測器
+關(guān)注
關(guān)注
1文章
860瀏覽量
47651 -
轉(zhuǎn)換模塊
+關(guān)注
關(guān)注
0文章
20瀏覽量
7117
原文標題:3D-CoCo: 3D 對比協(xié)同訓(xùn)練學(xué)習(xí)點云檢測的可遷移特征(NeurIPS2021)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
標貝科技:自動駕駛中的數(shù)據(jù)標注類別分享

標貝科技:自動駕駛中的數(shù)據(jù)標注類別分享

Apollo自動駕駛開放平臺10.0版即將全球發(fā)布


FPGA在自動駕駛領(lǐng)域有哪些優(yōu)勢?
FPGA在自動駕駛領(lǐng)域有哪些應(yīng)用?
未來已來,多傳感器融合感知是自動駕駛破局的關(guān)鍵
自動駕駛數(shù)據(jù)集的生成模型之WoVoGen框架原理

自動駕駛領(lǐng)域的數(shù)據(jù)集匯總

萬集激光基于車路協(xié)同的自動駕駛方案亮相
如何搞定自動駕駛3D目標檢測!

語音數(shù)據(jù)集在自動駕駛中的應(yīng)用與挑戰(zhàn)
LabVIEW開發(fā)自動駕駛的雙目測距系統(tǒng)
自動駕駛“十問十答”





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論