") 「自行科技」一文了解生成式對(duì)抗網(wǎng)絡(luò)GAN
「自行科技」一文了解生成式對(duì)抗網(wǎng)絡(luò)GAN
一、什么是GAN網(wǎng)絡(luò)
生成式對(duì)抗網(wǎng)絡(luò)(Generative adversarial network, GAN)是一種深度學(xué)習(xí)模型,是近年來復(fù)雜分布上無監(jiān)督學(xué)習(xí)最具前景的方法之一。
主要包含兩個(gè)模塊:生成器(Generator)和判別器(Discriminator)。生成器要不斷優(yōu)化自己生成的數(shù)據(jù)讓判別器判斷不出來,判別器也要進(jìn)行優(yōu)化讓自己判斷得更準(zhǔn)確。二者關(guān)系形成對(duì)抗,因此叫生成式對(duì)抗網(wǎng)絡(luò)。
二、 GAN的意義及用途
意義:GAN網(wǎng)絡(luò)可以幫助我們建立模型,相比于在已有模型上進(jìn)行參數(shù)更新的傳統(tǒng)網(wǎng)絡(luò),更具研究價(jià)值。同時(shí),GAN網(wǎng)絡(luò)是一種無監(jiān)督的學(xué)習(xí)方式,它的泛化性非常好。用途:(1)數(shù)據(jù)生成,主要指圖像生成。圖像生成:基于訓(xùn)練的模型,生成類似于訓(xùn)練集的新的圖片。
文本描述生成圖像:給定一個(gè)文本描述句,生成符合描述句內(nèi)容的圖像。
(2)圖像數(shù)據(jù)增強(qiáng):增強(qiáng)圖像中的有用信息,改善圖像的視覺效果。
(3)圖像外修復(fù):從受限輸入圖像生成具有語義意義結(jié)構(gòu)的新的視覺和諧內(nèi)容來擴(kuò)展圖像邊界。
(4)圖像超分辨率:由一幅低分辨率圖像或圖像序列恢復(fù)出高分辨率圖像。
(5)圖像風(fēng)格遷移:通過某種方法,把圖像從原風(fēng)格轉(zhuǎn)換到另一個(gè)風(fēng)格,同時(shí)保證圖像內(nèi)容沒有變化。
三、 GAN的發(fā)展
自2014年GAN的第一次提出,GAN在圖像領(lǐng)域、語音與自然語言處理(Natural language processing, NLP)領(lǐng)域以及其他領(lǐng)域開始快速發(fā)展,衍生出了一系列模型。其中,比較流行的有DCGAN(Deep convolutional generative adversarial networks),StyleGAN,BigGAN,StackGAN,Pix2pix,CycleGAN等。
DCGNN:這是第一次在GAN中使用卷積神經(jīng)網(wǎng)絡(luò)(Convolutional neural network, CNN)并取得了非常好的結(jié)果。它是GAN研究的一個(gè)里程碑,因?yàn)樗岢隽艘粋€(gè)重要的架構(gòu)變化來解決訓(xùn)練不穩(wěn)定,模式崩潰和內(nèi)部協(xié)變量轉(zhuǎn)換等問題。從那時(shí)起,基于DCGAN的架構(gòu)就被應(yīng)用到了許多GAN架構(gòu)。StyleGAN:GAN研究領(lǐng)域的重大突破,在面部生成任務(wù)中創(chuàng)造了新紀(jì)錄。算法的核心是風(fēng)格轉(zhuǎn)移技術(shù)或風(fēng)格混合。除了生成面部外,它還可以生成高質(zhì)量的汽車,臥室等圖像。BigGAN:用于圖像生成的最新進(jìn)展,生成的圖像質(zhì)量足以以假亂真,這是GAN首次生成具有高保真度和低品種差距的圖像。StackGAN:2017年,由“StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks”論文中提出。作者使用StackGAN完成文本到圖像的生成過程,并得到了非常好的結(jié)果。Pix2pix:對(duì)于圖像到圖像的翻譯任務(wù),Pix2pix也顯示出了令人印象深刻的結(jié)果。無論是將夜間圖像轉(zhuǎn)換為白天的圖像還是給黑白圖像著色,或者將草圖轉(zhuǎn)換為逼真的照片等,Pix2pix都呈現(xiàn)出很好的效果。CycleGAN:將對(duì)偶學(xué)習(xí)與GAN進(jìn)行結(jié)合,能將一類圖片自動(dòng)轉(zhuǎn)化為另一類圖片。其中對(duì)偶學(xué)習(xí)是一種類似于雙語翻譯任務(wù)的雙重學(xué)習(xí)機(jī)制,利用原始任務(wù)和雙重任務(wù)之間的反饋信號(hào)對(duì)模型進(jìn)行訓(xùn)練。與輸入必須是成對(duì)數(shù)據(jù)的Pix2pix模型相比,CycleGAN對(duì)非成對(duì)數(shù)據(jù)也能進(jìn)行訓(xùn)練,更具普適性。
四、 GAN的網(wǎng)絡(luò)結(jié)構(gòu)
在介紹GAN網(wǎng)絡(luò)結(jié)構(gòu)之前,我們先了解兩個(gè)概念:生成器和判別器。
生成器:輸入為隨機(jī)數(shù)據(jù),輸出為生成數(shù)據(jù)(通常是圖像)。通常這個(gè)網(wǎng)絡(luò)選用最普通的多層隨機(jī)網(wǎng)絡(luò)即可,網(wǎng)絡(luò)太深容易引起梯度消失或者梯度爆炸。判別器:我們把生成器生成的數(shù)據(jù)稱為假數(shù)據(jù),對(duì)應(yīng)的,來自真實(shí)數(shù)據(jù)集的數(shù)據(jù)稱為真數(shù)據(jù)。判別器輸入為數(shù)據(jù)(這里指代真實(shí)圖像和生成圖像),輸出是一個(gè)判別概率。需注意的是,這里判別的是圖像的真假,而非圖像的類別。輸入一個(gè)圖片后,我們并不需要確認(rèn)這張圖片是什么,而是判別圖像來源于真實(shí)數(shù)據(jù)集,還是由生成器輸出得到。網(wǎng)絡(luò)實(shí)現(xiàn)同樣可用最基本的多層神經(jīng)網(wǎng)絡(luò)。
圖1 GAN網(wǎng)絡(luò)結(jié)構(gòu)
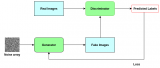
GAN 的主要思想就是在生成數(shù)據(jù)的過程中加入一個(gè)可以判斷真實(shí)數(shù)據(jù)和生成數(shù)據(jù)的判別器,使生成器和判別器相互對(duì)抗,判別器的作用是努力地分辨真實(shí)數(shù)據(jù)和生成數(shù)據(jù),生成器的作用是努力改進(jìn)自己從而生成可以迷惑判別器的數(shù)據(jù)。GAN的網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。GAN網(wǎng)絡(luò)結(jié)構(gòu)主要包含判別器D和生成器G,判別器D和生成器G通常由包含卷積或全連接層的多層網(wǎng)絡(luò)實(shí)現(xiàn)。判別器D:使用了混合整流器線性激活函數(shù)和sigmoid激活函數(shù),輸入為真實(shí)數(shù)據(jù)x和生成器G輸出的假數(shù)據(jù)G(z)。目標(biāo)是實(shí)現(xiàn)對(duì)數(shù)據(jù)來源的二分類判別:真(來源于真實(shí)數(shù)據(jù)的分布)或者假(來源于生成器的假數(shù)據(jù)G(z))生成器G:使用了maxout激活函數(shù),輸入為隨機(jī)噪聲z。目標(biāo)是使自己生成的假數(shù)據(jù)G(z)在D上的表現(xiàn)D(G(z)),和真實(shí)數(shù)據(jù)x在D上的表現(xiàn)D(x)一致。GAN的訓(xùn)練包括兩個(gè)方面:最大化判別器分類準(zhǔn)確率的判別器的參數(shù)和找到最大程度混淆判別器的生成器的參數(shù)。當(dāng)更新一個(gè)模型生成器的參數(shù)時(shí),另一個(gè)模型判別器的參數(shù)是固定的,反之亦然。通常是兩個(gè)網(wǎng)絡(luò)單獨(dú)且交替訓(xùn)練,先訓(xùn)練判別器,再訓(xùn)練生成器,再訓(xùn)練判別器,如此反復(fù),直到達(dá)到納什均衡。
圖2 生成器樣本示例
GAN網(wǎng)絡(luò)訓(xùn)練用到的數(shù)據(jù)集:MNIST,the Toronto Face Database(TFD)和CIFAR-10數(shù)據(jù)集。圖2展示了經(jīng)過訓(xùn)練后從生成器中抽取的樣本示例,其中,最右邊的列顯示了鄰近樣本的最近訓(xùn)練示例,以證明模型沒有記憶訓(xùn)練集。樣本是公平隨機(jī)抽取,而不是精心挑選。圖2中,a)表示GAN網(wǎng)絡(luò)在MNIST數(shù)據(jù)集上的生成效果,b)表示GAN網(wǎng)絡(luò)在TFD數(shù)據(jù)集上的生成效果。c)和d)均表示GAN網(wǎng)絡(luò)在CIFAR-10數(shù)據(jù)集上的生成效果,只是c)中GAN網(wǎng)絡(luò)采取全連接模型,而d)中是卷積判別器和反卷積生成器。在使用GAN進(jìn)行圖像生成任務(wù)時(shí),比較典型的網(wǎng)絡(luò)結(jié)構(gòu)有DCGAN網(wǎng)絡(luò)和基于先驗(yàn)知識(shí)的StackGAN網(wǎng)絡(luò)。DCGAN將CNN與GAN進(jìn)行了融合,利用CNN強(qiáng)大的特征提取能力來提高GAN的學(xué)習(xí)效果。DCGAN主要是在網(wǎng)絡(luò)結(jié)構(gòu)上對(duì) GAN 進(jìn)行了改進(jìn)。生成器相當(dāng)于反卷積網(wǎng)絡(luò),而判別器相當(dāng)于卷積網(wǎng)絡(luò)。DCGAN的生成器網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示。
圖3 DCGAN生成器網(wǎng)絡(luò)結(jié)構(gòu)
DCGAN網(wǎng)絡(luò)最先采用CNN結(jié)構(gòu)實(shí)現(xiàn)GAN模型,介紹了如何使用卷積層,并給出一些額外的結(jié)構(gòu)上的指導(dǎo)建議來實(shí)現(xiàn)。另外,它還討論如何可視化GAN的特征、隱空間的插值、利用判別器特征訓(xùn)練分類器以及評(píng)估結(jié)果。關(guān)于DCGAN的應(yīng)用主要集中在圖像處理方面,可以說這個(gè)模型是最典型、應(yīng)用最廣泛的GAN變種模型。StackGAN是一種新的堆疊生成對(duì)抗網(wǎng)絡(luò),用于從文本描述合成照片真實(shí)感圖像,其網(wǎng)絡(luò)結(jié)構(gòu)如圖4。StackGAN首次從文本描述生成256×256分辨率的圖像,且生成的圖像具有照片般逼真的細(xì)節(jié)。StackGAN網(wǎng)絡(luò)結(jié)構(gòu)分為兩個(gè)部分:Stage-ⅠGAN和Stage-ⅡGAN。 Stage-ⅠGAN:根據(jù)給定的文本描述,繪制對(duì)象的原始形狀和原始顏色,并根據(jù)隨機(jī)噪聲向量繪制背景布局,生成低分辨率圖像。生成器G0:首先是經(jīng)過一個(gè)CA(調(diào)節(jié)增強(qiáng)技術(shù))模塊,對(duì)文本嵌入進(jìn)行降維。StackGAN沒有直接將降維后的文本嵌入作為condition,而是將它接了一個(gè)全連接層,并從得到的獨(dú)立的高斯分布中隨機(jī)采樣得到高斯條件變量。接著,將高斯條件變量與噪聲向量經(jīng)過級(jí)聯(lián)得到的一組向量輸入到生成器中,然后,經(jīng)過上采樣之后生成一張64*64的圖像。判別器D0:首先,文本嵌入經(jīng)過一個(gè)全連接層被壓縮到128維,然后經(jīng)過空間復(fù)制將其擴(kuò)成一個(gè)4×4×128的張量。同時(shí),圖像會(huì)經(jīng)過一系列的下采樣到4×4。然后,圖像過濾映射會(huì)連接圖像和文本張量的通道。隨后,張量會(huì)經(jīng)過一個(gè)1×1的卷積層去連接跨文本和圖像學(xué)到的特征。最后,會(huì)通過只有一個(gè)節(jié)點(diǎn)的全連接層去產(chǎn)生圖像真假的概率。
圖4 StackGAN網(wǎng)絡(luò)結(jié)構(gòu)
Stage-Ⅱ GAN:
修正第一階段低分辨率圖像的缺陷,通過再次文本描述來完成對(duì)象的細(xì)節(jié),生成了高分辨率的真實(shí)感圖像。與通常的GAN不同,本階段不使用隨機(jī)噪聲。
生成器G:將第二階段生成器設(shè)計(jì)為一個(gè)具有殘差塊的編解碼網(wǎng)絡(luò)。Stage-Ⅰ GAN生成的64×64的圖片,加上對(duì)文本嵌入進(jìn)行CA操作得到的高斯條件變量,與前一階段相似,高斯條件變量被擴(kuò)成一個(gè)16×16×128的張量(綠色部分)。同時(shí),由前一個(gè)GAN生成的64×64的圖像,會(huì)經(jīng)過下采樣變成16×16(紫色部分)。連接圖像特征和文本特征后,經(jīng)過殘差塊,再上采樣,生成圖片。判別器D:對(duì)于判別器,其結(jié)構(gòu)類似于第一階段判別器,僅具有額外的下采樣塊。另外,為了明確地強(qiáng)制GAN更好地學(xué)習(xí)圖像和條件文本之間的對(duì)齊,我們在兩個(gè)階段都采用了匹配感知判別器。StackGAN訓(xùn)練用到的數(shù)據(jù)集:CUB,Oxford-102和MS COCO數(shù)據(jù)集。圖5中a),b)和c)分別展示了基于這三個(gè)數(shù)據(jù)集的測試集,StackGAN網(wǎng)絡(luò)生成的圖像示例。總體來說,StackGAN生成的高分辨率的圖像,細(xì)節(jié)信息較豐富,且能較好地反映相應(yīng)的文本描述。
圖5 StackGAN網(wǎng)絡(luò)生成的圖像示例
五、 GAN的實(shí)際應(yīng)用示例圖
(1)生成人臉:
圖6 基于GAN方法生成人臉
(2)語義圖像-圖片轉(zhuǎn)化:
圖7基于GAN方法將語義圖像轉(zhuǎn)化成圖片
(3)生成動(dòng)漫人物形象:
圖8基于GAN方法生成動(dòng)漫人物
(4)路況預(yù)測:圖9中,奇數(shù)列顯示解碼圖像,偶數(shù)列顯示目標(biāo)圖像:
圖9基于GAN方法的路況預(yù)測結(jié)果
(5)人臉圖像修復(fù):圖10中,依次顯示真實(shí)圖像,缺失圖像,修復(fù)圖像:
圖10基于GAN方法修復(fù)人臉圖像
審核編輯 黃昊宇
-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120975
發(fā)布評(píng)論請先 登錄
相關(guān)推薦
生成式AI工具作用
GaN有體二極管嗎?了解GaN的第三象限運(yùn)行

三行代碼完成生成式AI部署
生成對(duì)抗網(wǎng)絡(luò)(GANs)的原理與應(yīng)用案例
生成式AI與神經(jīng)網(wǎng)絡(luò)模型的區(qū)別和聯(lián)系
原來這才是【生成式AI】!!

深度學(xué)習(xí)生成對(duì)抗網(wǎng)絡(luò)(GAN)全解析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論