 2022語言與智能技術競賽舉辦頒獎典禮
2022語言與智能技術競賽舉辦頒獎典禮
9月18日,由中國中文信息學會(CIPS)和中國計算機學會(CCF)共同發起并聯合主辦的第七屆語言與智能高峰論壇召開。論壇上,2022語言與智能技術競賽賽事組委會為各獲獎團隊舉行了頒獎,賽事各冠軍團隊就參賽技術方案作詳細報告。
語言與智能技術競賽由中國中文信息學會和中國計算機學會聯合主辦,百度、中國中文信息學會評測工作委員會和中國計算機學會自然語言處理專委會承辦。自2018年舉辦以來,憑借面向真實應用場景的任務設計和源自真實場景的數據集,該競賽已成為全球最權威、最熱門的中文NLP賽事之一。2022屆競賽進一步升級,聯合“千言”數據集開源項目,設置了段落檢索、知識對話、情感可解釋、視頻語義理解四大任務,覆蓋了跨模態、知識驅動、可信學習等前沿課題,具有較高的學術和產業價值。
賽題任務的全面升級受到了來自學術界與產業界的廣泛關注。據統計,本屆競賽共計約2500支團隊報名,參賽選手覆蓋全球262所高校和208家企業,提交有效結果超過7000份。其中,高校選手占比約52%,來自清華大學、北京大學、復旦大學、中國人民大學、中國科學院大學、伊利諾伊理工大學、悉尼大學等國內外知名高校;企業選手占比約34%,來自中國移動、聯通、平安保險、華為、騰訊、網易、小米、小鵬汽車、海康威視、施耐德電氣等知名企業,覆蓋了金融、互聯網、傳媒、通信、工程機械、能源、生物等多個行業。
經過激烈的競爭,最終來自中國科學技術大學、香港中文大學、阿里巴巴、騰訊、商湯科技等高校與企業的共計16支團隊獲獎。
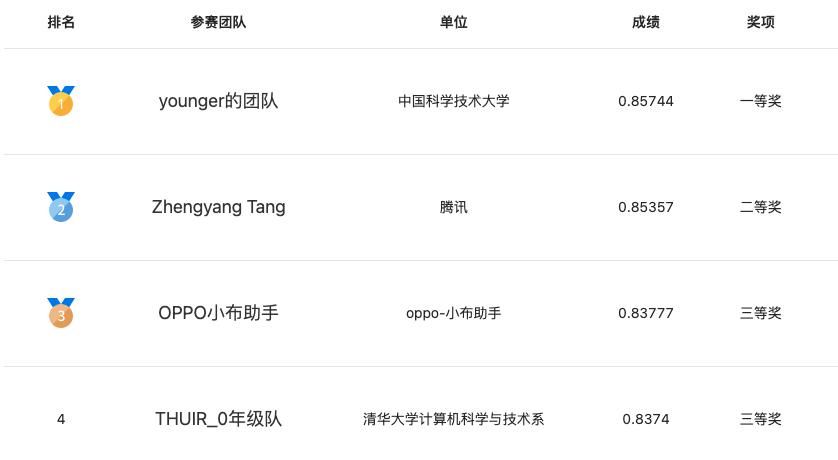
段落檢索賽題獲獎團隊

知識對話賽題獲獎團隊
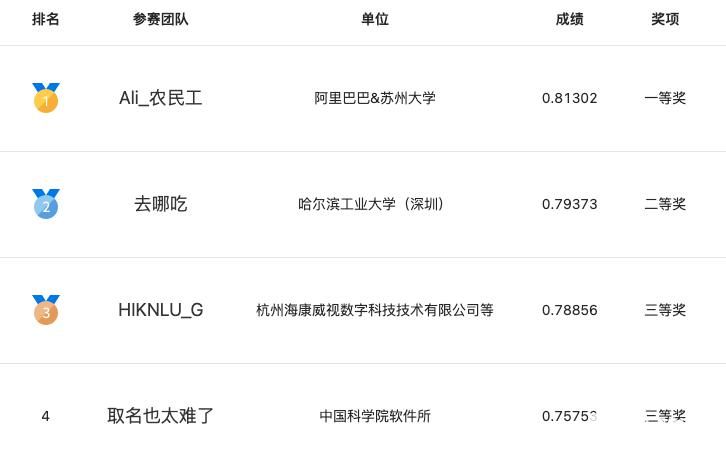
情感可解釋賽題獲獎團隊

視頻語義理解賽題獲獎團隊
賽事優勝團隊在參賽方案中均使用了預訓練語言模型,也提出了很多創新思路和方案,并取得了大幅的效果提升。相較于賽事官方的基線成績,段落檢索任務提升了15.40%,知識對話任務提升了142.86%,情感可解釋任務提升了77.12%,視頻語義理解任務提升了50%,各團隊的技術方案有力地推動了相關任務的技術探索。在論壇的評測報告環節,四大任務的冠軍團隊對各自的參賽方案做了分享。
在段落檢索任務中,來自中國科學技術大學的“young的團隊”提出了一種基于弱監督數據預訓練的開放問答段落檢索方法,該方法可以有效提升檢索準確率。在知識對話賽題中,來自騰訊的“拿件T恤就溜”團隊,設計了一個基于實時知識搜索API的知識對話系統,實驗表明該方案可以顯著提升對話整體的連貫性和吸引力。在情感可解釋任務中,阿里巴巴的“Ali_農民工團隊” 提出了一個基于通用信息抽取統一框架 UIE的情感可解釋分析方法,該方法根據情感可解釋任務的特點,使用few-shot、文本聚類等方法,提高了模型的合理性、忠誠性。在視頻語義理解任務中,來自商湯科技&香港科技大學的“商湯NLP×LaVi的團隊”針對分類標簽預測任務和語義標簽預測任務,分別設計了對應方案,提出了基于多模態學習的視頻語義理解模型,并通過數據增強、數據加權和多模型集成進一步提升方案性能,最終脫穎而出。
針對此次競賽,百度自然語言處理部主任架構師劉璟進行了總結,他表示:“四大任務的優勝方案相對基線均大幅提升。各優勝隊伍均基于預訓練模型進行了一系列的創新,如采用prompting技術、面向任務的預訓練等,有效地推動了技術的進步。目前來看,知識融合、可信學習、跨模態等技術在應用落地中還存在很多挑戰,未來需要更大地突破。”
值得一提的是,本次競賽數據集均來自于千言中文開源數據集項目。千言是面向自然語言處理的中文開源數據共建項目,由中國計算機學會、中國中文信息學會和百度聯合發起,目前已有近20家單位的數據集作者參與共建,已有覆蓋文本生成、情感分析、閱讀理解等15個任務方向的近60個中文NLP開源數據集入駐。
2022語言與智能競賽發布了首個來自搜索引擎的大規模中文段落檢索數據集DuReader_retrieval、首個服務信息增強對話數據集DuSinc、首個細粒度中文情感可解釋評測數據集DuExplain、視頻語義理解數據集DuVideoTag。賽后,開發者可繼續在千言數據集官網下載使用以上數據集,并參與相應的榜單評測,不斷提升技術水平,實現創新發展。
語言是人類信息傳遞最重要的媒介,近年來自然語言處理領域獲得了產學研各界的持續關注。語言與智能技術競賽將繼續提供面向真實應用場景的數據集和富有挑戰性的任務設定,引領學術研究面向真實應用,提升語言理解與人機交互智能水平,為推動語言與智能領域技術發展和應用貢獻力量。
審核編輯 黃昊宇
-
智能技術
+關注
關注
0文章
296瀏覽量
12818 -
自然語言處理
+關注
關注
1文章
614瀏覽量
13508
發布評論請先 登錄
相關推薦
MPS榮獲2024全球電子成就獎之年度電源管理/電壓轉換器產品獎
西安郵電大學“中科億海微獎學金”頒獎典禮圓滿舉行

2024年度“瑞薩杯”信息科技前沿專題賽頒獎典禮圓滿落幕
第八屆集創賽“芯海杯”總決賽頒獎典禮圓滿落幕

集創西南 共育棟梁|第八屆集創賽“芯海杯”西南賽區決賽頒獎典禮圓滿落幕

光庫科技自研的諧振腔組件再度榮膺“榮格技術創新獎”

首屆“Imagine Wi-Fi 7”中東和中亞創新應用大賽頒獎典禮隆重舉行

鼎陽科技受邀參加大灣區戰略新興產業領航企業頒獎典禮

北京大學高性能計算綜合能力競賽圓滿結束







 工商網監
工商網監
評論