 邏輯復制的概念與原理
邏輯復制的概念與原理
在數字化時代的今天,我們都認同數據會創造價值。為了最大化數據的價值,我們不停的建立著數據遷移的管道,從同構到異構,從關系型到非關系型,從云下到云上,從數倉到數據湖,試圖在各種場景挖掘數據的價值。而在這縱橫交錯的數據網絡中,邏輯復制扮演著極其重要的角色。
讓我們將視角從復雜的網絡拉回其中的一個端點,從PostgreSQL出發,對其邏輯復制的原理進行解密。
概念與原理
邏輯復制,是基于復制標識復制數據及其變化的一種方法。區別于物理復制對頁面操作的描述,邏輯復制是對事務及數據元組的一種描述。
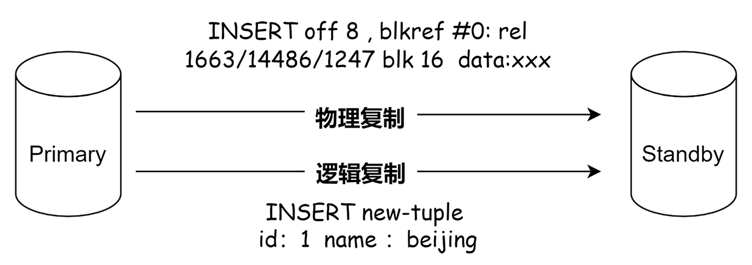
圖-WAL數據流示例
如圖所示,物理復制的數據流是對tablespace/database/filenode文件的塊進行操作,而邏輯復制的內容是對元組進行描述。
接下來我們來看邏輯復制中的幾個概念:
*復制槽
復制槽是記錄復制狀態的一組信息。由于WAL(預寫式日志)文件在數據真正落盤后會刪除,復制槽會防止過早清理邏輯復制解析所需的WAL日志。在邏輯復制中,每個插槽從單個數據庫流式傳輸一系列更改,創建復制槽需要指定其使用的輸出插件,同時創建復制槽時會提供一個快照。
*輸出插件
輸出插件負責將WAL日志解碼為可讀的格式,常用的插件用test_decoding(多用來測試),pgoutput(默認使用),wal2json(輸出為json)。PostgreSQL定義了一系列回調函數,我們除了使用上述插件,可以通過回調函數編寫自己的輸出插件。
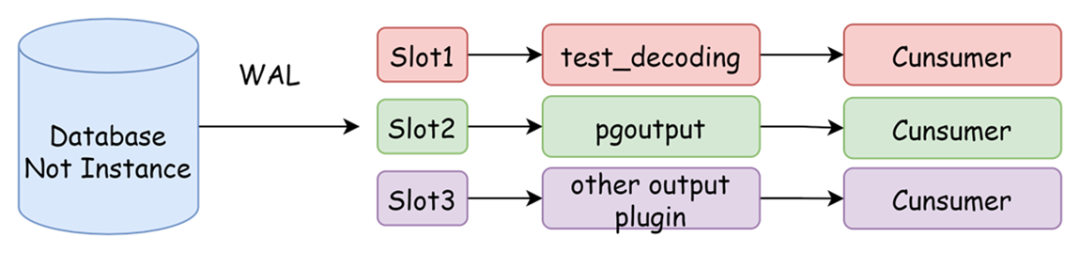
圖-復制槽數據流
*復制協議與消息
通過復制協議,我們可以從源端獲取WAL數據流。例如通過PSQL工具建議復制連接
psql "dbname=postgres replication=database"
開啟流式傳輸WAL
START_REPLICATION[ SLOT slot_name] [ PHYSICAL] XXX/XXX[ TIMELINE tli]
無論是物理復制,還是邏輯復制,使用PostgreSQL的發布訂閱或者pg_basebackup搭建流復制,都是通過復制協議與定義的消息進行交互(物理復制和邏輯復制數據流內容不同)

圖- WAL數據流消息類型
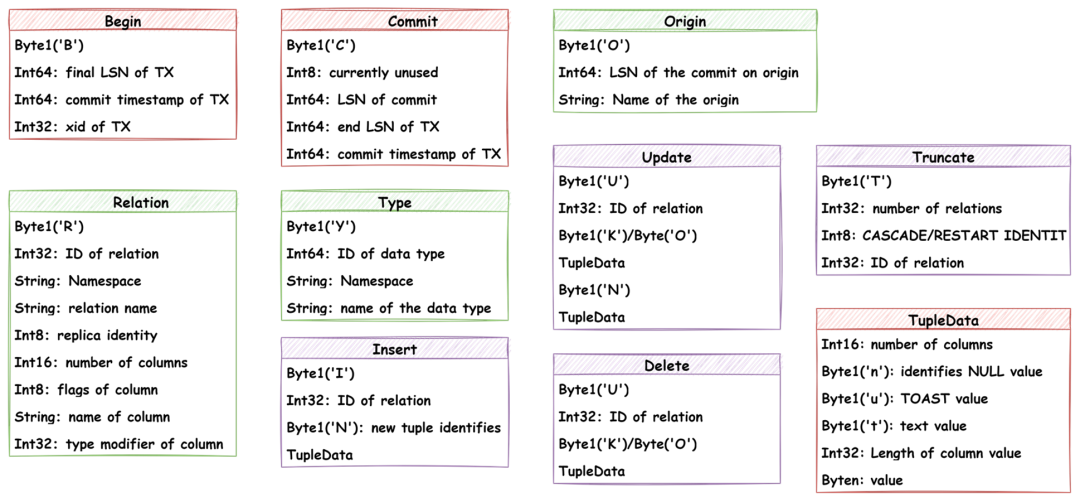
圖-邏輯復制中的XLogData消息
*工作流程
當我們了解了概念之后,來看一下整個解析的工作流程。由于WAL文件里一個事務的內容并不一定是連續的,所以需要通過Reorder后放在buffer中,根據事務ID組織成一條消息,COMMIT后發送給輸出插件,輸出插件解析后將消息流發送給目標端。
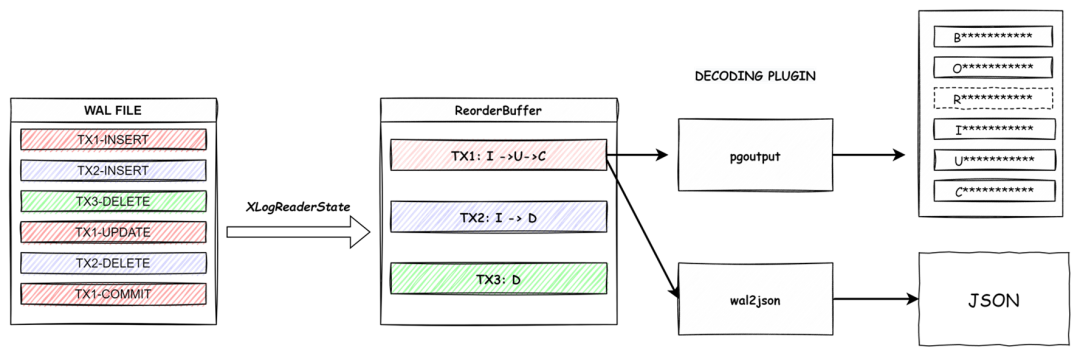
圖-邏輯解析工作流程
問題與演進
當我們掌握了邏輯復制的原理,計劃使用其構建我們的數據遷移應用之前,我們還有一些問題并沒有解決。讓我們來一起看看是什么亟待解決的問題,以及我們如何進行處理。
*問題一:Failover slot
為了高可用性,數據庫至少會存在一主一備的架構,當主庫故障進行高可用切換時,備庫卻沒有相應的復制槽信息,也就是缺少failover slot。這是由于保存slot信息的物理文件,未同步至備庫。那么我們如何手動創建一個faliover slot呢?
1. 主庫創建復制槽,檢查備庫wal文件是否連續
2. 復制包含slot信息的物理文件至備庫,在pg_repslot目錄下
3. 備庫重啟,重啟后才可以看到復制槽信息,原因是讀取slot物理文件的函數StartupReplicationSlots只會在postmaster進程啟動時調用。
4. 定期查詢主庫slot狀態,使用pg_replication_slot_advance函數推進備庫復制槽
自此,我們在備庫上也有了相應的信息,手動實現了failover slot。PostgreSQL生態中著名的高可用軟件Patroni也是以這種方式進行了實現,區別只是在Patroni查詢主庫slot狀態時將信息寫入了DCS中,備庫拿到DCS中的位點信息進行推進。
*問題二:DDL同步
原生的邏輯復制不支持解析DDL語句,我們可以使用事件觸發器來進行處理。
1. 使用事件觸發器感知表結構變更,記錄到DDL_RECORD表中,并將該表通過邏輯復制進行發布。
2. 接收端獲取到該表的數據變更,即可處理為相應DDL語句進行執行。
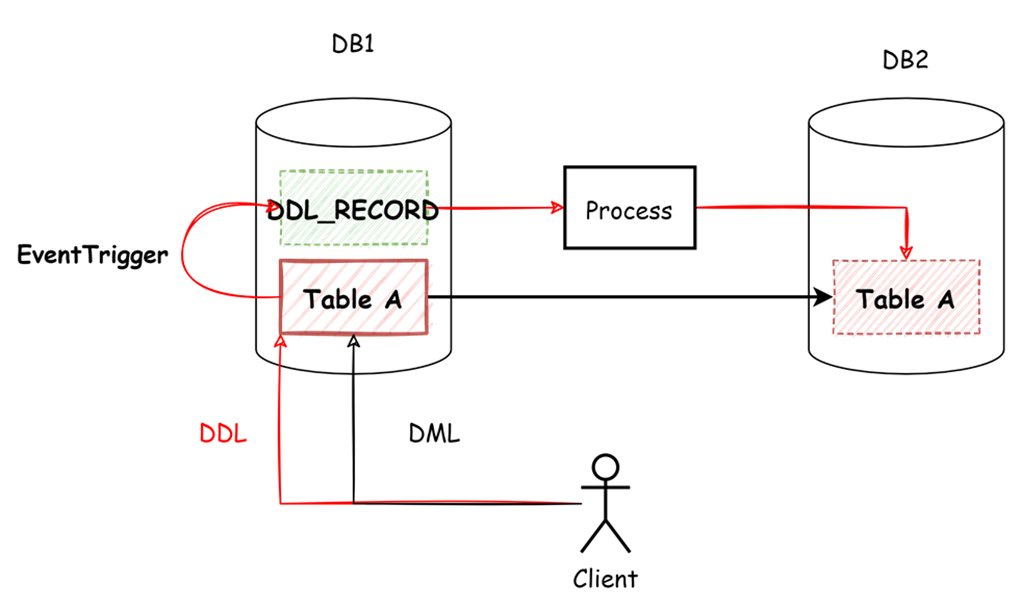
圖-事件觸發器實現DDL同步
*問題三:雙向同步
當數據遷移涉及雙向同步的管道時,例如想實現雙主雙寫,對數據庫同一對象進行操作,就會出現WAL循環。

圖-相同表雙向同步導致數據循環
部分DTS應用為了解決這個問題會創建輔助表,在事務中先對輔助表進行操作,通過解析到對輔助表的操作而得知該記錄是有DTS應用插入,從而過濾該事務,不再循環解析。PostgreSQL對事務提供了Origin記錄,無須輔助表,通過pg_replication_origin_session_setup函數或者發布訂閱中的replorigin_create即可指定Origin ID。
指定Origin ID后,我們除了可以解析后通過DTS應用進行過濾,還也可以通過解析插件中的FilterByOriginCB回調函數在解析過程中過濾,這種方式減少了數據傳輸,效率更高。
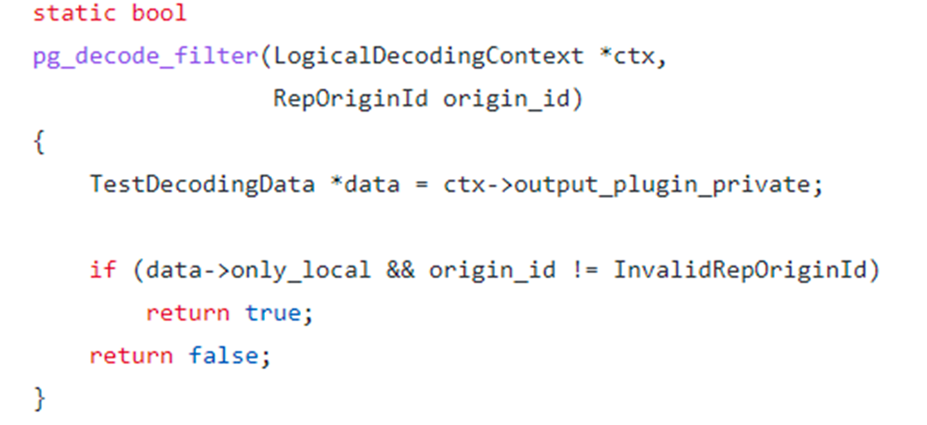
圖-test_decoding中OriginFilter函數DEMO
*其他問題
除了以上三個問題,還有一些使用的問題或限制。這里列出了一些,不再展開,僅簡要說明。
Toast處理:對于toast值(消息格式中可以判斷),我們在處理時一般使用占位符進行處理,接收端接收到占位符就不對這一列進行處理,雖然有些麻煩,但這也是在和傳輸toast值的方案中權衡的結果。
心跳表:由于復制槽記錄的XMIN是全局的,當我們發布的表一直沒有更新時,XMIN沒有推進導致WAL積壓,我們可以創建一張心跳表,周期性寫入數據并發布,使XMIN進行推進。
大事務延遲:根據前文提到的工作流程我們可以知道默認事務在COMMIT后才會進行解析,這對于大事務來說勢必會導致延遲,PG14版本提供了streamin模式進行解析,即事務進行中進行解析并發送至接收端。
應用與實踐
前兩節我們從原理及問題的角度對PostgreSQL進行了解密,接下來我們看如何通過我們掌握的邏輯復制原理,進行數據遷移的應用與實踐。
*全量與增量同步
在真實的數據遷移場景中,大部分都是全量和增量都要同步的場景,并且我們打通了數據傳輸的通道后,也對這條通道的安全,效率,以及功能的擴展,例如清洗,脫敏等ETL能力提出了新的要求。我們先來看一下如何實現全量與增量的同步。
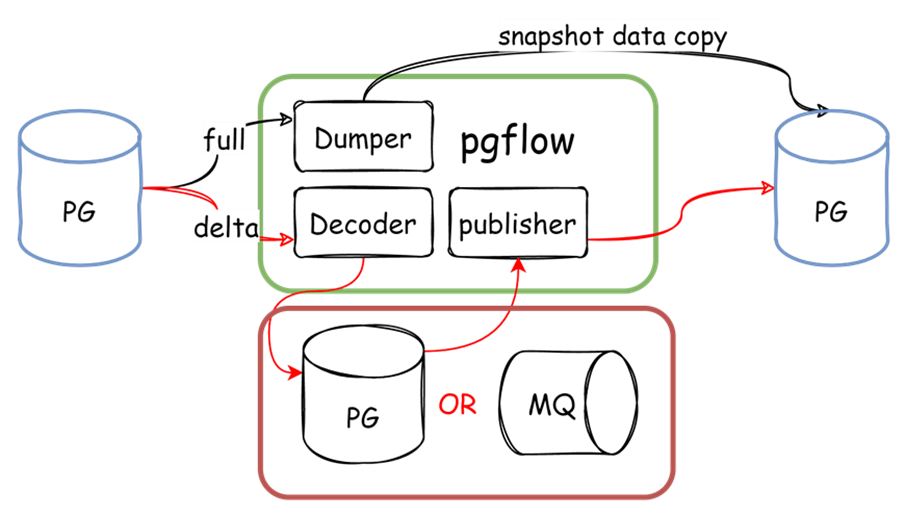
圖-數據流向示意圖
主要流程包括:
1. 創建復制槽并導出快照
2. 根據快照進行全量數據遷移
3. 根據復制槽進行增量數據的遷移
我們使用了PG數據庫或者消息隊列MQ作為數據代理,全量與增量解析可以同時進行,當全量數據處理完畢后,狀態機通知增量處理程序進行增量發布。而對于代理中的數據,可以在解析后進行預處理。
*自建實例遷移上云實踐
最后和大家分享一個自建實例遷移上云的實踐,該案例是將自建的PG10版本實例遷移至京東云上的RDS PG 11版本,通過對增量數據的回流以及數據校驗保證了數據安全與業務平穩切換。
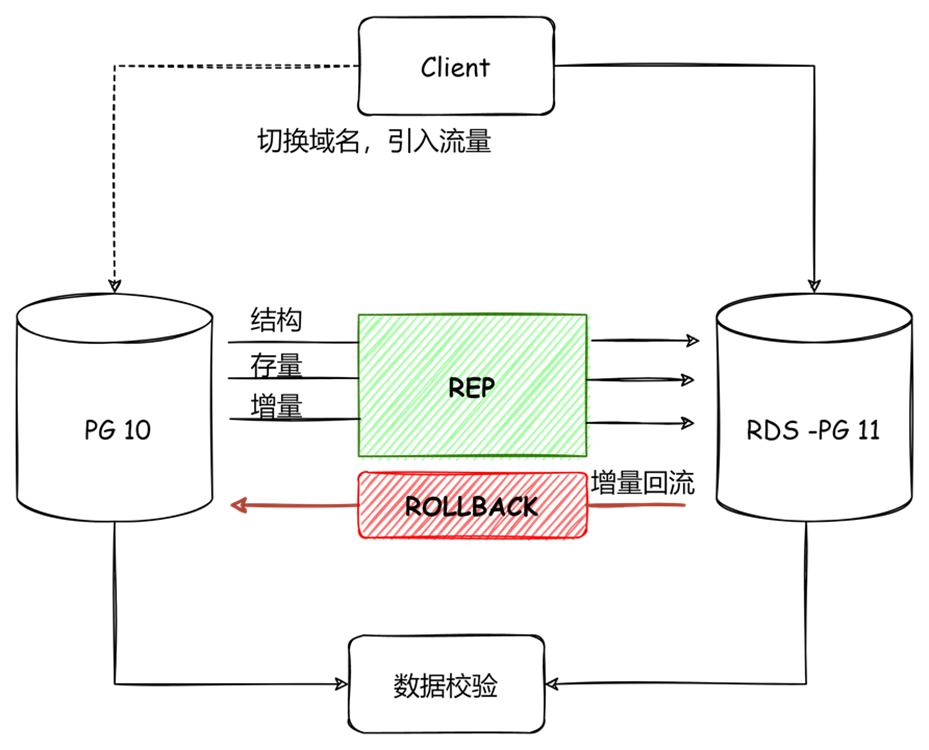
圖-數據遷移上云
DTS應用主要分為如下幾個階段:
1. 數據檢查階段:檢查主鍵,權限,配置
2. 數據遷移階段:結構,存量,增量數據遷移,監控遷移狀態
3. 應用遷移階段:切換域名,引入流量
4. 回滾階段:增量數據回流,若出現問題可快速回滾。
-
數據流
+關注
關注
0文章
117瀏覽量
14272 -
DDL
+關注
關注
0文章
12瀏覽量
6309 -
數據遷移
+關注
關注
0文章
66瀏覽量
6929
原文標題:PostgreSQL邏輯復制解密
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
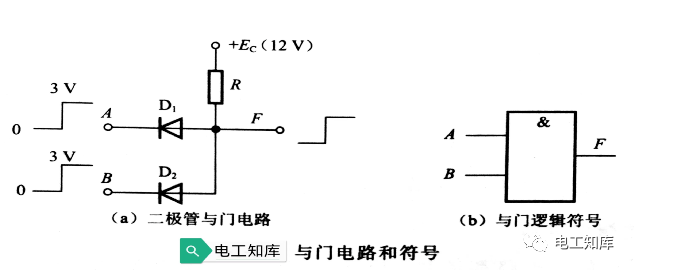
邏輯門電路基本概念介紹
FPGA實戰演練邏輯篇46:邏輯復制與資源共享
解釋一下有關邏輯電平的一些概念
線與邏輯、鎖存器、緩沖器、建立時間、緩沖時間的基本概念

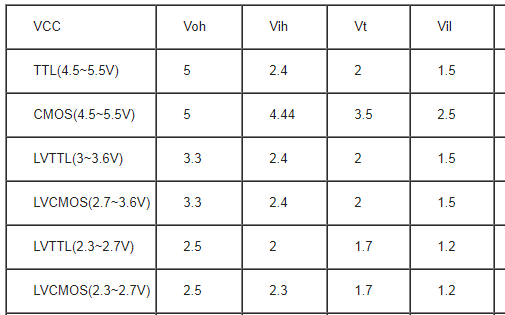
常見邏輯電平介紹和基本概念
邏輯電平的一些基本概念詳細說明

邏輯門電路相關概念





 工商網監
工商網監
評論