") 深度學(xué)習(xí)與圖神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)分享:Transformer
深度學(xué)習(xí)與圖神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)分享:Transformer
在過去的幾年中,神經(jīng)網(wǎng)絡(luò)的興起與應(yīng)用成功推動(dòng)了模式識(shí)別和數(shù)據(jù)挖掘的研究。許多曾經(jīng)嚴(yán)重依賴于手工提取特征的機(jī)器學(xué)習(xí)任務(wù)(如目標(biāo)檢測(cè)、機(jī)器翻譯和語音識(shí)別),如今都已被各種端到端的深度學(xué)習(xí)范式(例如卷積神經(jīng)網(wǎng)絡(luò)(CNN)、長(zhǎng)短期記憶(LSTM)和自動(dòng)編碼器)徹底改變了。曾有學(xué)者將本次人工智能浪潮的興起歸因于三個(gè)條件,分別是:
·計(jì)算資源的快速發(fā)展(如GPU)
·大量訓(xùn)練數(shù)據(jù)的可用性
·深度學(xué)習(xí)從歐氏空間數(shù)據(jù)中提取潛在特征的有效性
盡管傳統(tǒng)的深度學(xué)習(xí)方法被應(yīng)用在提取歐氏空間數(shù)據(jù)的特征方面取得了巨大的成功,但許多實(shí)際應(yīng)用場(chǎng)景中的數(shù)據(jù)是從非歐式空間生成的,傳統(tǒng)的深度學(xué)習(xí)方法在處理非歐式空間數(shù)據(jù)上的表現(xiàn)卻仍難以使人滿意。例如,在電子商務(wù)中,一個(gè)基于圖(Graph)的學(xué)習(xí)系統(tǒng)能夠利用用戶和產(chǎn)品之間的交互來做出非常準(zhǔn)確的推薦,但圖的復(fù)雜性使得現(xiàn)有的深度學(xué)習(xí)算法在處理時(shí)面臨著巨大的挑戰(zhàn)。這是因?yàn)閳D是不規(guī)則的,每個(gè)圖都有一個(gè)大小可變的無序節(jié)點(diǎn),圖中的每個(gè)節(jié)點(diǎn)都有不同數(shù)量的相鄰節(jié)點(diǎn),導(dǎo)致一些重要的操作(例如卷積)在圖像(Image)上很容易計(jì)算,但不再適合直接用于圖。此外,現(xiàn)有深度學(xué)習(xí)算法的一個(gè)核心假設(shè)是數(shù)據(jù)樣本之間彼此獨(dú)立。然而,對(duì)于圖來說,情況并非如此,圖中的每個(gè)數(shù)據(jù)樣本(節(jié)點(diǎn))都會(huì)有邊與圖中其他實(shí)數(shù)據(jù)樣本(節(jié)點(diǎn))相關(guān),這些信息可用于捕獲實(shí)例之間的相互依賴關(guān)系。
近年來,人們對(duì)深度學(xué)習(xí)方法在圖上的擴(kuò)展越來越感興趣。在多方因素的成功推動(dòng)下,研究人員借鑒了卷積網(wǎng)絡(luò)、循環(huán)網(wǎng)絡(luò)和深度自動(dòng)編碼器的思想,定義和設(shè)計(jì)了用于處理圖數(shù)據(jù)的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),由此一個(gè)新的研究熱點(diǎn)——“圖神經(jīng)網(wǎng)絡(luò)(Graph Neural Networks,GNN)”應(yīng)運(yùn)而生
近期看了關(guān)于Transformer的信息
來簡(jiǎn)述一下Transformer結(jié)構(gòu)
Transformer 整體結(jié)構(gòu)
首先介紹 Transformer 的整體結(jié)構(gòu),下圖是 Transformer 用于中英文翻譯的整體結(jié)構(gòu):
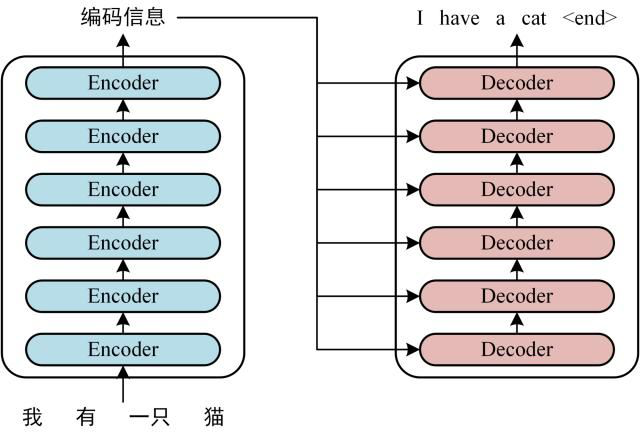
Transformer 的整體結(jié)構(gòu),左圖Encoder和右圖Decoder
可以看到Transformer 由 Encoder 和 Decoder 兩個(gè)部分組成,Encoder 和 Decoder 都包含 6 個(gè) block。Transformer 的工作流程大體如下:
第一步:獲取輸入句子的每一個(gè)單詞的表示向量X,X由單詞的 Embedding(Embedding就是從原始數(shù)據(jù)提取出來的Feature) 和單詞位置的 Embedding 相加得到。
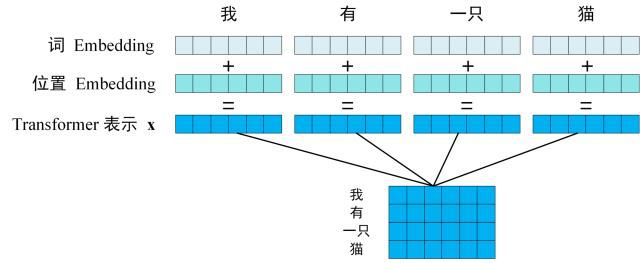
Transformer 的輸入表示
第二步:將得到的單詞表示向量矩陣 (如上圖所示,每一行是一個(gè)單詞的表示x) 傳入 Encoder 中,經(jīng)過 6 個(gè) Encoder block 后可以得到句子所有單詞的編碼信息矩陣C,如下圖。單詞向量矩陣用Xn×d表示, n 是句子中單詞個(gè)數(shù),d 是表示向量的維度 (論文中 d=512)。每一個(gè) Encoder block 輸出的矩陣維度與輸入完全一致。
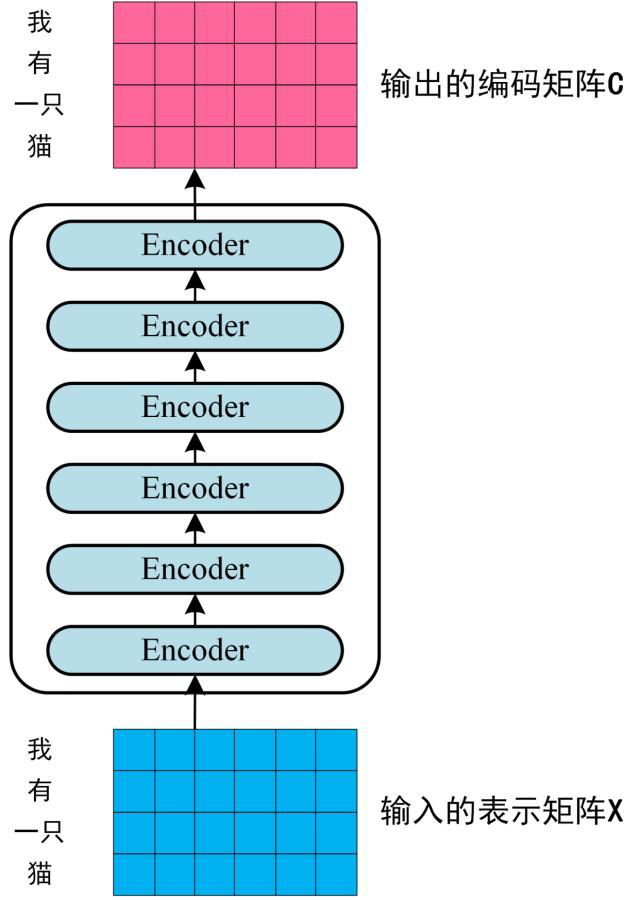
Transformer Encoder 編碼句子信息
第三步:將 Encoder 輸出的編碼信息矩陣C傳遞到 Decoder 中,Decoder 依次會(huì)根據(jù)當(dāng)前翻譯過的單詞 1~ i 翻譯下一個(gè)單詞 i+1,如下圖所示。在使用的過程中,翻譯到單詞 i+1 的時(shí)候需要通過Mask (掩蓋)操作遮蓋住 i+1 之后的單詞。
Transofrmer Decoder 預(yù)測(cè)
上圖 Decoder 接收了 Encoder 的編碼矩陣C,然后首先輸入一個(gè)翻譯開始符 "",預(yù)測(cè)第一個(gè)單詞 "I";然后輸入翻譯開始符 "" 和單詞 "I",預(yù)測(cè)單詞 "have",以此類推。這是 Transformer 使用時(shí)候的大致流程。
審核編輯 黃昊宇
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4762瀏覽量
100535 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120975 -
Transformer
+關(guān)注
關(guān)注
0文章
141瀏覽量
5982
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
深度學(xué)習(xí)中的卷積神經(jīng)網(wǎng)絡(luò)模型
Transformer能代替圖神經(jīng)網(wǎng)絡(luò)嗎
pytorch中有神經(jīng)網(wǎng)絡(luò)模型嗎
簡(jiǎn)單認(rèn)識(shí)深度神經(jīng)網(wǎng)絡(luò)
BP神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)機(jī)制
深度學(xué)習(xí)與nlp的區(qū)別在哪
深度神經(jīng)網(wǎng)絡(luò)與基本神經(jīng)網(wǎng)絡(luò)的區(qū)別
卷積神經(jīng)網(wǎng)絡(luò)與循環(huán)神經(jīng)網(wǎng)絡(luò)的區(qū)別
卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練的是什么
深度學(xué)習(xí)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用
卷積神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)及其功能
深度神經(jīng)網(wǎng)絡(luò)模型cnn的基本概念、結(jié)構(gòu)及原理
深度神經(jīng)網(wǎng)絡(luò)模型有哪些
利用深度循環(huán)神經(jīng)網(wǎng)絡(luò)對(duì)心電圖降噪
詳解深度學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論