 針對文本生成任務提出一種基于提示的遷移學習方法
針對文本生成任務提出一種基于提示的遷移學習方法
本文將介紹我們已發表在NAACL 2022的兩篇論文,分別關注預訓練語言模型的能力評測與提示遷移學習。預訓練語言模型在廣泛的任務中取得了不錯的效果,但是對于預訓練模型的語言能力仍缺乏系統性的評估與判斷。面對這一難題,我們提出了一個針對預訓練語言模型的通用語言能力測試(ElitePLM),從記憶、理解、推理和創作四個能力維度評估5類10個預訓練模型的語言能力,希望為后續研究提供選擇、應用、解釋和設計預訓練模型的參考指導。另外,目前預訓練語言模型大多采用微調(fine-tuning)范式適應文本生成任務,但這一范式難以應對數據稀疏的場景。因此,我們采用提示學習(prompt-based learning)構建一個通用、統一且可遷移的文本生成模型PTG,在全樣本與少樣本場景下都具有不俗的表現。
一、預訓練語言模型的能力評測
背景
近年來,預訓練語言模型(PLMs)在各種各樣的任務上取得了非常不錯的結果。因此,如何從多個方面系統性地評估預訓練模型的語言能力成為一個非常重要的研究話題,這有助于研究者為特定任務選擇合適的預訓練語言模型。目前相關的研究工作往往聚焦于單個能力的評估,或者只考慮很少部分的任務,缺乏系統的設計與測試。為了解決這一難題,我們針對預訓練語言模型提出了一個通用語言能力測試(ElitePLM),從記憶、理解、推理、創作四個方面評估預訓練模型的語言能力。
通用語言能力測試
評測模型
為了保證測試模型的廣泛性與代表性,我們選擇了五類預訓練模型進行測試:
Bidirectional LMs: BERT, RoBERTa, ALBERT;
Unidirectional LMs: GPT-2;
Hybrid LMs: XLNet, UniLM;
Knowledge-enhanced LMs: ERNIE;
Text-to-Text LMs: BART, T5, ProphetNet;
記憶能力(Memory)
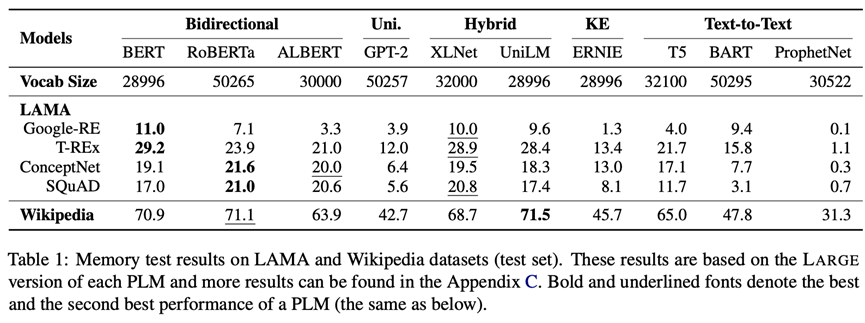
記憶是人類最基本的能力。ElitePLM將評估預訓練語言模型在預訓練階段記住的知識與語言模式,因此我們采用LAMA與Wikipedia兩個數據集。LAMA是常用的知識探針數據集,Wikipedia是廣泛使用的預訓練語料,這兩個數據集都將轉化為填空式問題進行測試,評測指標為Precision@1。評測結果如下圖所示(更多結果見原論文和附錄)。可以看出,RoBERTa采用雙向的訓練目標和一些魯棒的訓練策略取得了最好的效果,因此預訓練目標和策略反映了模型記憶信息的方式,深刻影響模型的記憶能力。
理解能力(Comprehension)
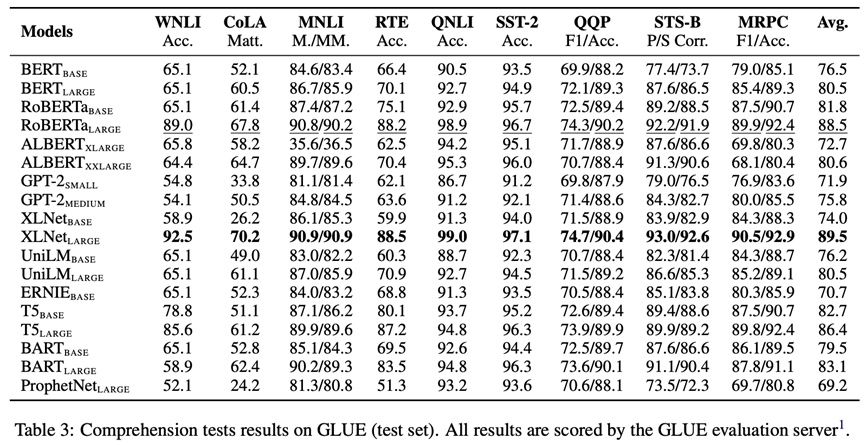
理解是一個復雜且多面的能力,包括對文本詞匯、背景知識、語言結構的理解。因此,我們采用GLUE, SuperGLUE, SQuAD v1.1, SQuAD v2.0和RACE五個數據集對預訓練模型理解詞匯、背景知識和語言結構進行評測。GLUE的評測結果如下圖所示(更多結果見原論文和附錄)。可以看出,在記憶測試上表現良好的模型(如RoBERTa,XLNet)在理解測試上也具有優異的表現,因此記憶能力的改善有助于提升理解能力。
推理能力(Reasoning)
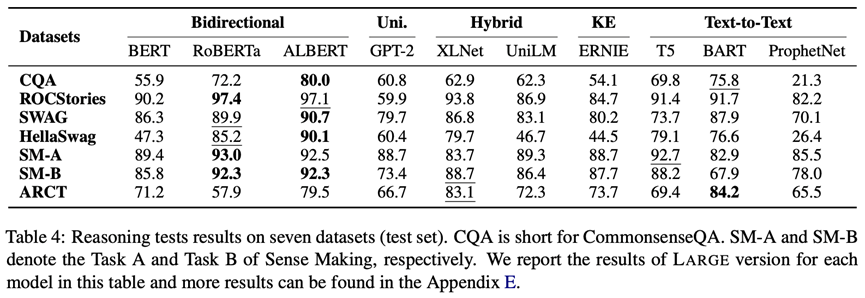
推理是建立在文本理解的基礎上,ElitePLM中主要關注三種推理模式:常識推理、演繹推理和溯因推理。因此,我們采用CommonsenseQA, ROCStories, SWAG, HellaSwag, Sense Making和ARCT六個數據集對上述三種推理進行評測。評測結果如下圖所示(更多結果見原論文和附錄)。可以看出,ALBERT采用inter-sentence coherence預訓練目標在推理測試中取得了不錯的效果,因此句子級推理目標可以提升預訓練模型的推理能力。雖然引入了知識,但是ERNIE在知識相關的數據集CommonsenseQA中表現平平,因此需要設計更加有效的知識融合方式。
創作能力(Composition)
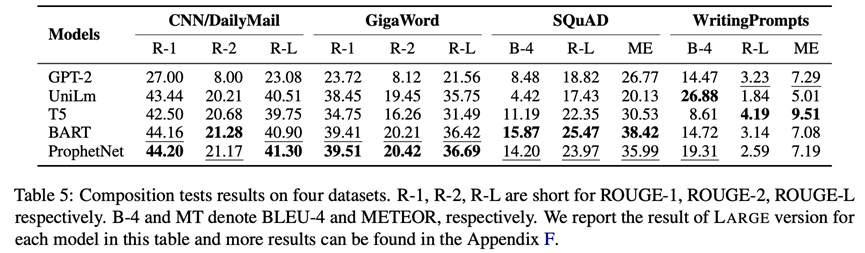
創作也就是從無到有生成新文本,它不僅需要模型對相關內容的理解,還需要推理出合適的上下文。因為,我們采用WritingPrompts——故事生成, CNN/Daily Mail, GigaWord——摘要生成和SQuAD v1.1——問題生成四個數據集對模型的創作能力進行測試,其中故事生成為長文本生成任務,摘要生成與問題生成為短文本生成任務。評測結果如下圖所示(更多結果見原論文和附錄)。可以看出,denoising預訓練目標更有利于短文本生成,left-to-right預訓練目標更有利于長文本生成。
結論
基于對預訓練語言模型的記憶、理解、推理和創作能力的測試,我們發現:(1)使用不同預訓練目標和策略的模型擅長不同的任務,比如基于雙向目標的BERT和使用魯棒訓練策略的RoBERTa能夠很好地記憶預訓練語料,使用permutation language modeling的XLNet在理解任務中可以有效地建模雙向的上下文信息,使用inter-sentence coherence目標的ALBERT在句子級推理任務中更合適;(2)在微調預訓練模型時,他們的表現受到目標領域數據分布的影響比較大;(3)預訓練模型在相似任務中的遷移能力出人意料的良好,特別是推理任務。ElitePLM除了作為預訓練語言模型能力測試的基準,我們還開放了所有數據集的測試結果,基于這些測試結果,研究者可以對預訓練模型在每種能力上的表現進行更加深入的分析。例如,我們在論文中分析了模型在QA任務上的測試結果,發現預訓練模型對于復雜的答案類型仍然有待提高,此外,我們也對模型的創作文本進行了圖靈測試。
總之,ElitePLM希望能夠幫助研究者建立健全的原則,以在實際應用中選擇、應用、解釋和設計預訓練模型。
二、 預訓練語言模型的提示遷移
背景
目前大部分預訓練語言模型都采用微調(fine-tuning)的方式來適應文本生成任務。但是,在現實中,我們常常遇到只有少量標注數據、難以進行微調的場景。我們知道,大部分文本生成任務都采用相似的學習機制例如Seq2Seq,預訓練語言模型如GPT也展現了構建通用且可遷移框架的重要性。基于上述目標,我們采用提示學習(prompt-based learning)構建一個通用、統一且可遷移的文本生成模型PTG,特別是對于數據稀疏的場景。
形式化定義
給定輸入文本與輸出文本,文本生成任務的目標是最大化條件生成概率。本文采用連續提示,其中為提示向量數目,最終的訓練目標為。在遷移學習下,我們有一系列源任務,其中第個源任務 包含條輸入文本與輸出文本,遷移學習的目標是利用在源任務中學習到的知識解決目標任務。在本文中,我們考慮一種基于提示學習的新型遷移學習框架:針對每個源任務,我們學習獨立的source prompt , 然后將這些已學習的prompt遷移到目標任務。
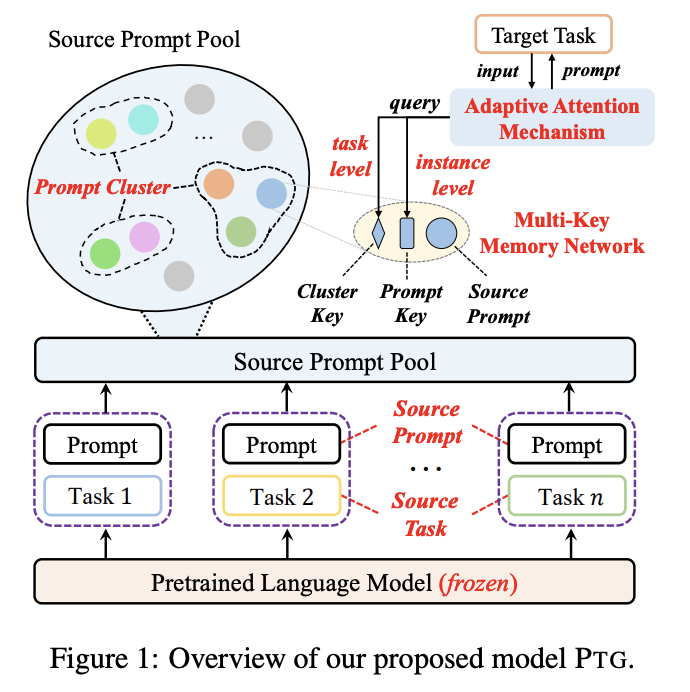
模型
在這一過程,我們需要解決兩個核心挑戰:(1)已有研究表明prompt是高度任務特定的,因此對于新任務來說需要有效的遷移及重用prompt機制;(2)對于單個任務而言,一個prompt顯然不足以應對大量不同的數據樣本,因此有必要在prompt遷移過程中考慮任務于樣本的雙重特征。
學習可遷移的Source Prompts
對于每個源任務,基于共享的一個凍結PLM,使用訓練數據和訓練目標學習source prompt ,這些prompt將存儲在一個source prompt pool中,記為。構建提示池的目的是為了將提示共享給所有目標任務,同時在遷移時考慮任務間的相似性。
如何衡量任務間的相似性?我們通過譜聚類的方式將source prompts進行聚簇,每個prompt將被看作是有權無向圖上的一個節點,然后采用min-max cut策略進行分割,最后得到所有簇,每個prompt屬于其中某個簇,簇中的prompt認為具有任務間的相似性。
有了上述結構,我們將構建一個multi-key記憶網絡,對于簇中的一個source prompt ,它與一個可學習的cluster key 和一個可學習的prompt key 進行聯結,即:
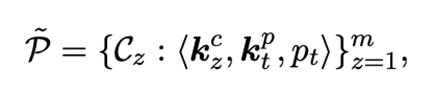
遷移Instance Adaptive Prompts
在遷移prompt過程中,我們需要考慮任務特征與樣本特征,因此我們設計了一個自適應的注意力機制,高效地學習target prompt來解決目標任務。
對于目標任務中的一個樣本,我們使用task query和instance query從提示池中選擇合適的source prompts來學習新的target prompt以解決目標任務的樣本。Task query被定義為一個任務特定的可學習向量,instance query則需要考慮樣本輸入的特征,我們使用一個凍結的BERT計算,即,對BERT頂層每個單詞的表示采用平均池化操作。對于提示池中的prompt ,我們使用task query和instance query計算匹配分數:
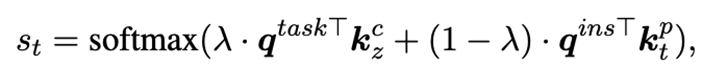
最終,對于目標任務中的樣本,我們學習到的target prompt為。基于此,我們在目標任務上的訓練目標為:
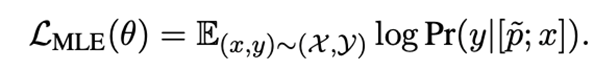
實驗結果
在實驗中,我們選擇三類生成任務的14個數據集:compression(包括摘要生成和問題生成)、transduction(包括風格遷移和文本復述)以及creation(包括對話和故事生成)。數據集統計如下表所示。
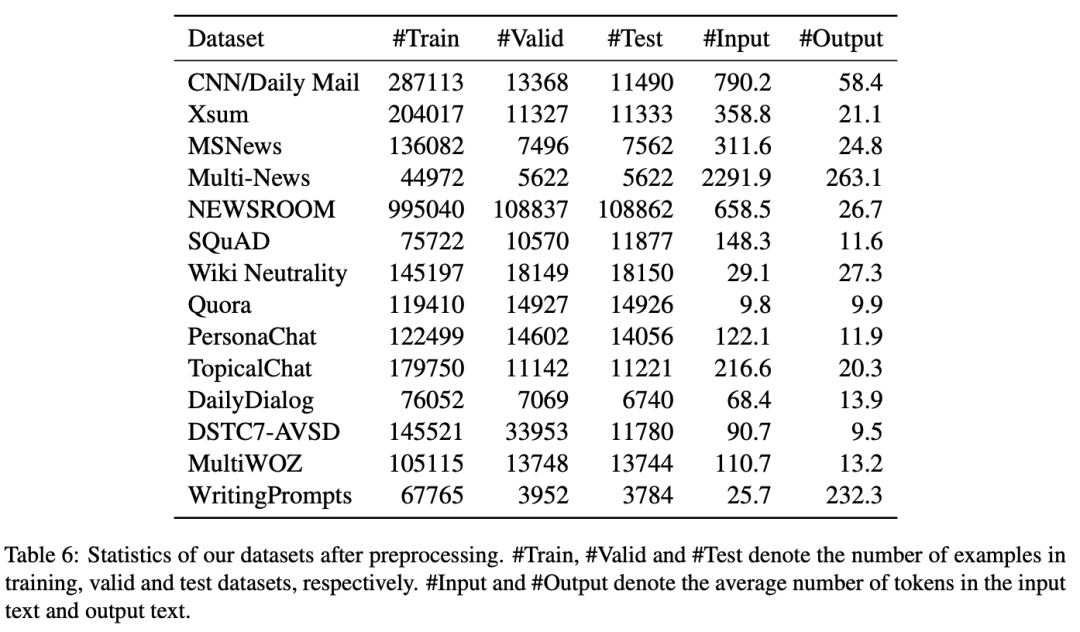
基準模型方面,我們選擇了預訓練語言模型(GPT-2, BART和T5)、Prefix-Tuning、SPoT和Multi-task Tuning,并分別在全樣本與少樣本兩種場景下進行任務間遷移與數據集間遷移的測試。
全樣本場景
對于任務間遷移實驗,我們考慮兩種情況:(1)目標任務和數據集為摘要生成(CNN/Daily Mail),其他五種任務為源任務;(2)目標任務和數據集為對話(PersonaChat),其他五種任務為源任務。
對于數據集間遷移實驗,我們同樣也考慮兩種情況:(1)在摘要生成任務下,目標數據集為CNN/Daily Mail或者XSUM,其他摘要數據集為源數據集;(2)在對話任務下,目標數據集為PersonaChat或者DailyDialog,其他對話數據集為源數據集。
實驗結果如下表所示。可以看到,通過將prompt從源任務遷移到目標任務,PTG超越了GPT-2, BART, T5和Prefix-Tuning,這表明提示遷移提供了一種非常有效的預訓練語言模型微調方式。其次,PTG也超越了同樣基于提示遷移的方法SPoT,這是因為SPoT在遷移時僅僅使用source prompt初始化target prompt。最后,PTG與Multi-task Tuning表現相當甚至超越其表現。這表明簡單地混合所有任務進行微調并不足以應對文本生成任務的復雜性。
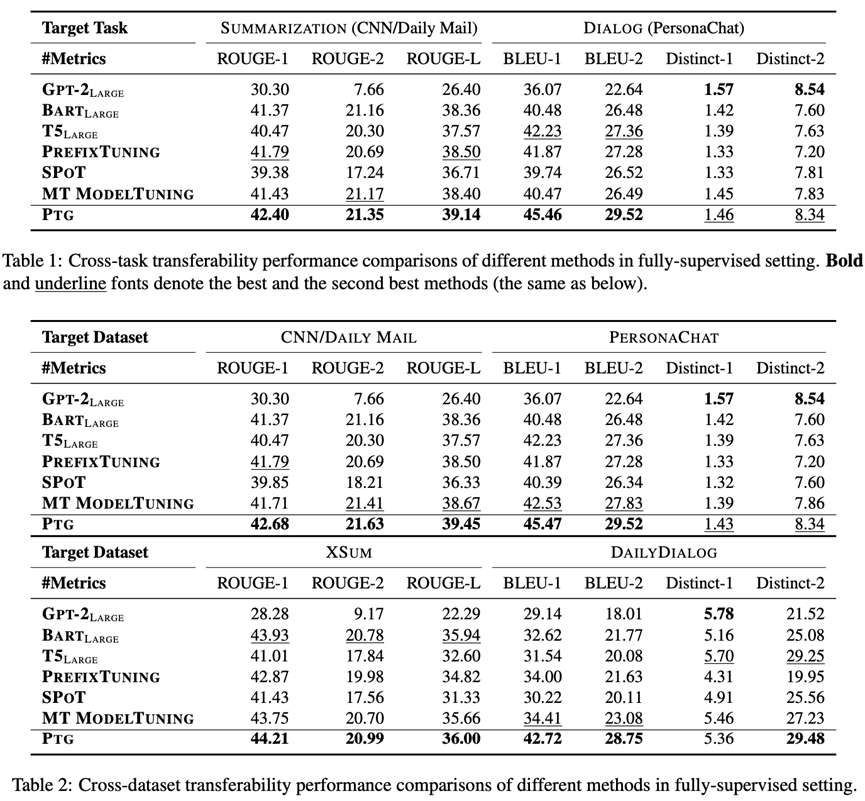
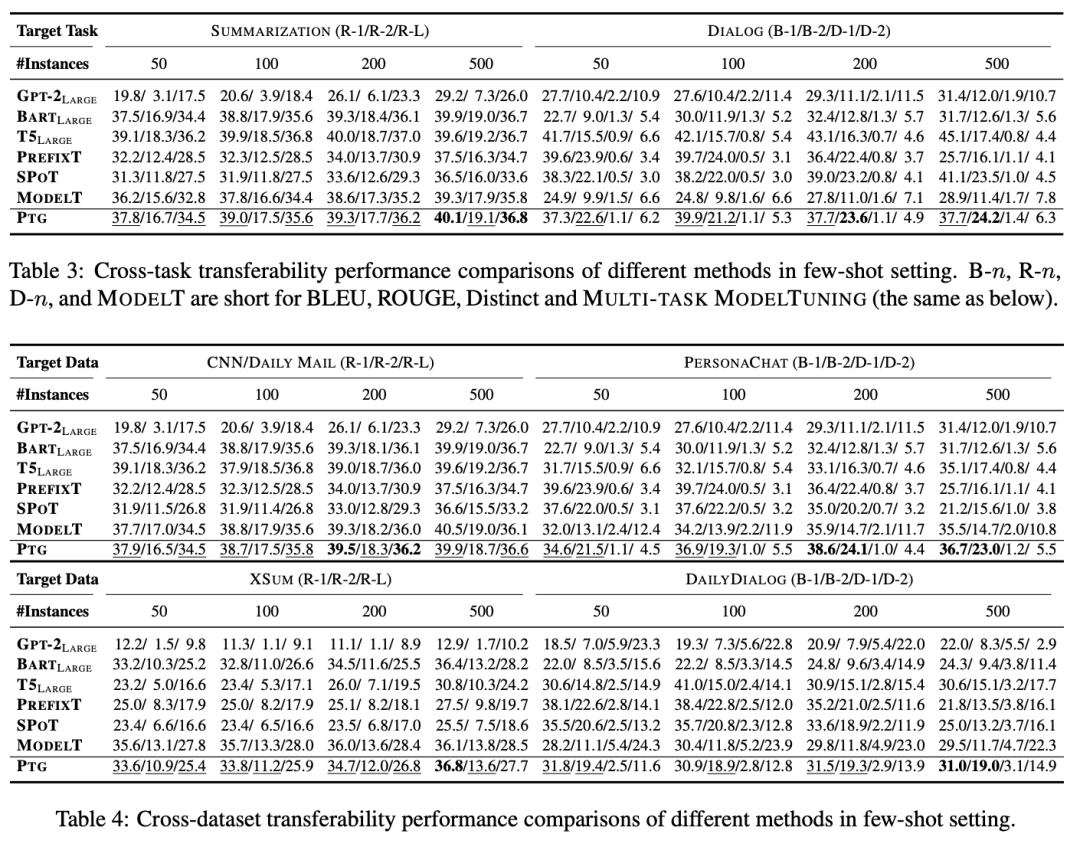
少樣本場景
少樣本實驗下的任務間遷移與數據集間遷移設置與全樣本場景一致。除此以外,我們減少目標任務與數據集的訓練樣本數目為{50, 100, 200, 500}。對于每個數目,我們在2中隨機種子下分別進行5次實驗,最終結果為10次實驗的平均結果。
實驗結果如下表所示。可以看到,少樣本場景下PTG取得了與最強基準模型Multi-task Tuning相當的表現,甚至超越其表現,這也進一步說明了我們方法的有效性。
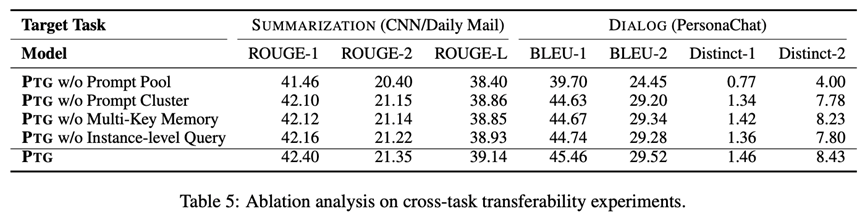
消融實驗
此外,我們還設置了消融實驗,探究不同模塊對模型表現的影響,包括提示池(prompt pool)、提示聚簇(prompt cluster)、multi-key記憶網絡(multi-key memory network)和樣本級特征(instance-level query)。實驗結果如下表所示。
任務間相似性分析
我們針對源任務上學習到的source prompts做了源任務間的相似性分析,下圖展示了prompt之間余弦相似度的熱力圖。可以看出,6個任務14個數據集大致可以分為3類,這與我們選擇數據集的類別基本吻合。
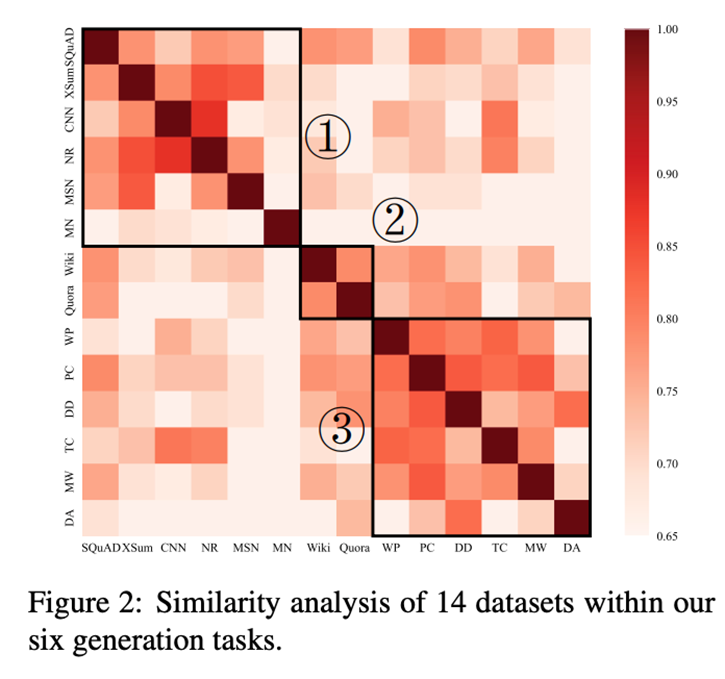
結論
本文針對文本生成任務提出一種基于提示的遷移學習方法。通過在源任務學習一系列的源提示,模型將這些提示遷移到目標任務以解決下游任務。在模型中,我們設計了一種自適應注意力機制,在提示遷移時考慮任務特征和樣本特征。在大量實驗上的結果表明,我們的方法要優于基準辦法。
審核編輯 :李倩
-
語言模型
+關注
關注
0文章
508瀏覽量
10247 -
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
遷移學習
+關注
關注
0文章
74瀏覽量
5558
原文標題:NAACL'22 | 預訓練模型哪家強?提示遷移學習為文本生成提供新思路
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何使用 Llama 3 進行文本生成
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
Whatsapp正在開發一種新的生成人工智能功能
深度學習中的無監督學習方法綜述
生成式AI的基本原理和應用領域
如何手擼一個自有知識庫的RAG系統
谷歌提出大規模ICL方法
一種利用光電容積描記(PPG)信號和深度學習模型對高血壓分類的新方法
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
檢索增強生成(RAG)如何助力企業為各種企業用例創建高質量的內容?
OpenVINO?協同Semantic Kernel:優化大模型應用性能新路徑
高級檢索增強生成技術(RAG)全面指南
探索高效的大型語言模型!大型語言模型的高效學習方法





 工商網監
工商網監
評論