 ClickHouse與esProc SPL性能對比
ClickHouse與esProc SPL性能對比
開源分析數據庫 ClickHouse 以快著稱,真的如此嗎?我們通過對比測試來驗證一下。
先用 ClickHouse(簡稱 CH)、Oracle 數據庫(簡稱 ORA)一起在相同的軟硬件環境下做對比測試。測試基準使用國際廣泛認可的 TPC-H,針對 8 張表,完成 22 條 SQL 語句定義的計算需求(Q1 到 Q22)。測試采用單機 12 線程,數據總規模 100G。TPC-H 對應的 SQL 都比較長,這里就不詳細列出了。Q1 是簡單的單表遍歷計算分組匯總,對比測試結果如下: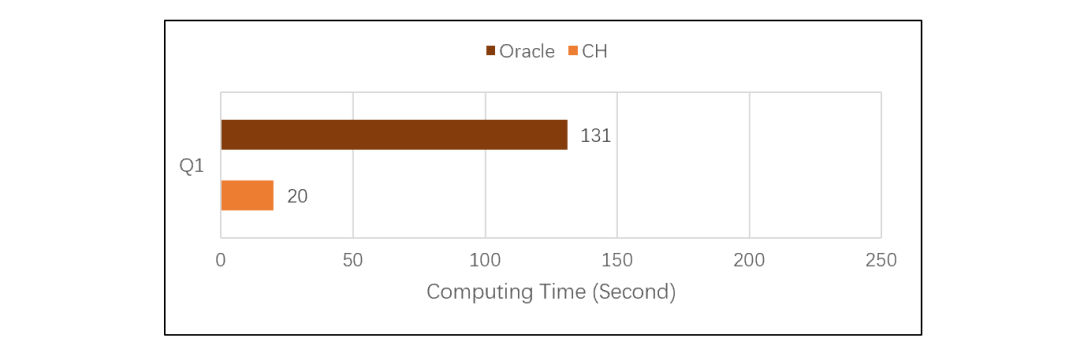 CH 計算 Q1 的表現要好于 ORA,說明 CH 的列式存儲做得不錯,單表遍歷速度很快。而 ORA 主要吃虧在使用了行式存儲,明顯要慢得多了。但是,如果我們加大計算復雜度,CH 的表現怎么樣呢?繼續看 TPC-H 的 Q2、Q3、Q7,測試結果如下:
CH 計算 Q1 的表現要好于 ORA,說明 CH 的列式存儲做得不錯,單表遍歷速度很快。而 ORA 主要吃虧在使用了行式存儲,明顯要慢得多了。但是,如果我們加大計算復雜度,CH 的表現怎么樣呢?繼續看 TPC-H 的 Q2、Q3、Q7,測試結果如下: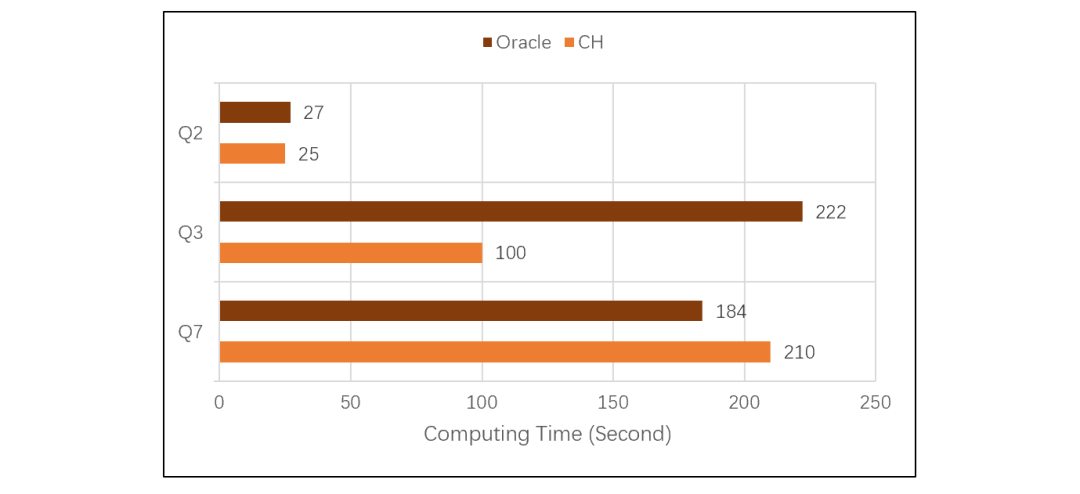 計算變得復雜之后,CH 性能出現了明顯的下降。Q2 涉及數據量較少,列存作用不大,CH 性能和 ORA 幾乎一樣。Q3 數據量較大,CH 占了列存的便宜后超過了 ORA。Q7 數據也較大,但是計算復雜,CH 性能還不如 ORA。做復雜計算快不快,主要看性能優化引擎做的好不好。CH 的列存占據了巨大的存儲優勢,但竟然被 ORA 用行式存儲趕上,這說明 CH 的算法優化能力遠不如 ORA。TPC-H 的 Q8 是更復雜一些的計算,子查詢中有多表連接,CH 跑了 2000 多秒還沒有出結果,應該是卡死了,ORA 跑了 192 秒。Q9 在 Q8 的子查詢中增加了 like,CH 直接報內存不足的錯誤了,ORA 跑了 234 秒。其它還有些復雜運算是 CH 跑不出來的,就沒法做個總體比較了。CH 和 ORA 都基于 SQL 語言,但是 ORA 能優化出來的語句,CH 卻跑不出來,更證明 CH 的優化引擎能力比較差。坊間傳說,CH 只擅長做單表遍歷運算,有關聯運算時甚至跑不過 MySQL,看來并非虛妄胡說。想用 CH 的同學要掂量一下了,這種場景到底能有多大的適應面?
計算變得復雜之后,CH 性能出現了明顯的下降。Q2 涉及數據量較少,列存作用不大,CH 性能和 ORA 幾乎一樣。Q3 數據量較大,CH 占了列存的便宜后超過了 ORA。Q7 數據也較大,但是計算復雜,CH 性能還不如 ORA。做復雜計算快不快,主要看性能優化引擎做的好不好。CH 的列存占據了巨大的存儲優勢,但竟然被 ORA 用行式存儲趕上,這說明 CH 的算法優化能力遠不如 ORA。TPC-H 的 Q8 是更復雜一些的計算,子查詢中有多表連接,CH 跑了 2000 多秒還沒有出結果,應該是卡死了,ORA 跑了 192 秒。Q9 在 Q8 的子查詢中增加了 like,CH 直接報內存不足的錯誤了,ORA 跑了 234 秒。其它還有些復雜運算是 CH 跑不出來的,就沒法做個總體比較了。CH 和 ORA 都基于 SQL 語言,但是 ORA 能優化出來的語句,CH 卻跑不出來,更證明 CH 的優化引擎能力比較差。坊間傳說,CH 只擅長做單表遍歷運算,有關聯運算時甚至跑不過 MySQL,看來并非虛妄胡說。想用 CH 的同學要掂量一下了,這種場景到底能有多大的適應面?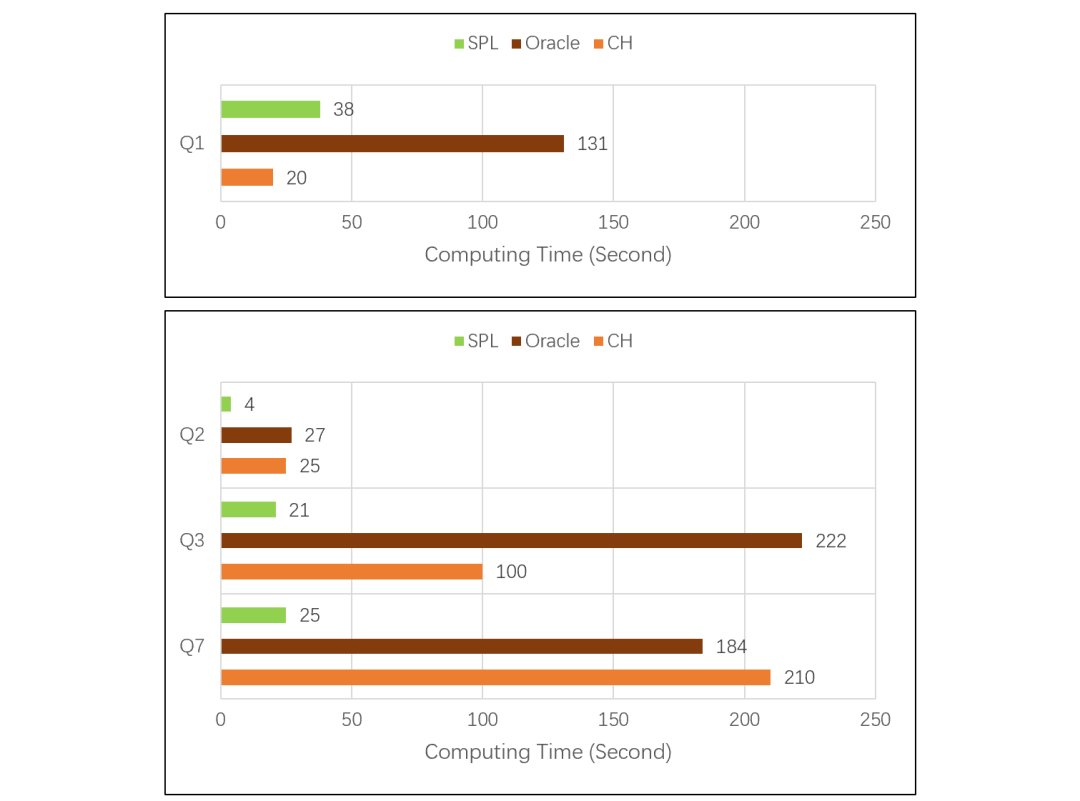 Q2、Q3、Q7 這些較復雜的運算,SPL 比 CH 和 ORA 跑的都快。CH 跑不出結果的 Q8、Q9,SPL 分別跑了 37 秒和 68 秒,也比 ORA 快。原因在于 SPL 可以采用更優的算法,其計算復雜度低于被 ORA 優化過的 SQL,更遠低于 CH 執行的 SQL,再加上列存,最終是用 Java 開發的 SPL 跑贏了 C++ 實現的 CH 和 ORA。大概可以得到結論,esProc SPL 無論做簡單計算,還是復雜計算性能都非常好。不過,Q1 這種簡單運算,CH 比 SPL 還是略勝了一籌。似乎可以進一步證明前面的結論,即 CH 特別擅長簡單遍歷運算。且慢,SPL 還有秘密武器。SPL 的企業版中提供了列式游標機制,我們再來對比測試一下:在 8 億條數據量下,做最簡單的分組匯總計算,對比 SPL(使用列式游標)和 CH 的性能。(采用的機器配置比前面做 TPC-H 測試時略低,因此測出的結果不同,不過這里主要看相對值。)簡單分組匯總對應 CH 的 SQL 語句是:SQL1:
Q2、Q3、Q7 這些較復雜的運算,SPL 比 CH 和 ORA 跑的都快。CH 跑不出結果的 Q8、Q9,SPL 分別跑了 37 秒和 68 秒,也比 ORA 快。原因在于 SPL 可以采用更優的算法,其計算復雜度低于被 ORA 優化過的 SQL,更遠低于 CH 執行的 SQL,再加上列存,最終是用 Java 開發的 SPL 跑贏了 C++ 實現的 CH 和 ORA。大概可以得到結論,esProc SPL 無論做簡單計算,還是復雜計算性能都非常好。不過,Q1 這種簡單運算,CH 比 SPL 還是略勝了一籌。似乎可以進一步證明前面的結論,即 CH 特別擅長簡單遍歷運算。且慢,SPL 還有秘密武器。SPL 的企業版中提供了列式游標機制,我們再來對比測試一下:在 8 億條數據量下,做最簡單的分組匯總計算,對比 SPL(使用列式游標)和 CH 的性能。(采用的機器配置比前面做 TPC-H 測試時略低,因此測出的結果不同,不過這里主要看相對值。)簡單分組匯總對應 CH 的 SQL 語句是:SQL1:
 SPL 使用列式游標機制之后,簡單遍歷分組計算的性能也和 CH 一樣了。如果在 TPC-H 的 Q1 測試中也使用列式游標,SPL 也會達到和 CH 同樣的性能。測試過程中發現,8 億條數據存成文本格式占用磁盤 15G,在 CH 中占用 5.4G,SPL 占用 8G。說明 CH 和 SPL 都采用了壓縮存儲,CH 的壓縮比更高些,也進一步證明 CH 的存儲引擎做得確實不錯。不過,SPL 也可以達到和 CH 同樣的性能,這說明 SPL 存儲引擎和算法優化做得都比較好,高性能計算能力更加均衡。當前版本的 SPL 是用 Java 寫的,Java 讀數后生成用于計算的對象的速度很慢,而用 C++ 開發的 CH 則沒有這個問題。對于復雜的運算,讀數時間占比不高,Java 生成對象慢造成的拖累還不明顯;而對于簡單的遍歷運算,讀數時間占比很高,所以前面測試中 SPL 就會比 CH 更慢。列式游標優化了讀數方案,不再生成一個個小對象,使對象生成次數大幅降低,這時候就能把差距拉回來了。單純從存儲本身看,SPL 和 CH 相比并沒有明顯的優劣之分。接下來再看常規 TopN 的對比測試,CH 的 SQL 是:SQL2:
SPL 使用列式游標機制之后,簡單遍歷分組計算的性能也和 CH 一樣了。如果在 TPC-H 的 Q1 測試中也使用列式游標,SPL 也會達到和 CH 同樣的性能。測試過程中發現,8 億條數據存成文本格式占用磁盤 15G,在 CH 中占用 5.4G,SPL 占用 8G。說明 CH 和 SPL 都采用了壓縮存儲,CH 的壓縮比更高些,也進一步證明 CH 的存儲引擎做得確實不錯。不過,SPL 也可以達到和 CH 同樣的性能,這說明 SPL 存儲引擎和算法優化做得都比較好,高性能計算能力更加均衡。當前版本的 SPL 是用 Java 寫的,Java 讀數后生成用于計算的對象的速度很慢,而用 C++ 開發的 CH 則沒有這個問題。對于復雜的運算,讀數時間占比不高,Java 生成對象慢造成的拖累還不明顯;而對于簡單的遍歷運算,讀數時間占比很高,所以前面測試中 SPL 就會比 CH 更慢。列式游標優化了讀數方案,不再生成一個個小對象,使對象生成次數大幅降低,這時候就能把差距拉回來了。單純從存儲本身看,SPL 和 CH 相比并沒有明顯的優劣之分。接下來再看常規 TopN 的對比測試,CH 的 SQL 是:SQL2: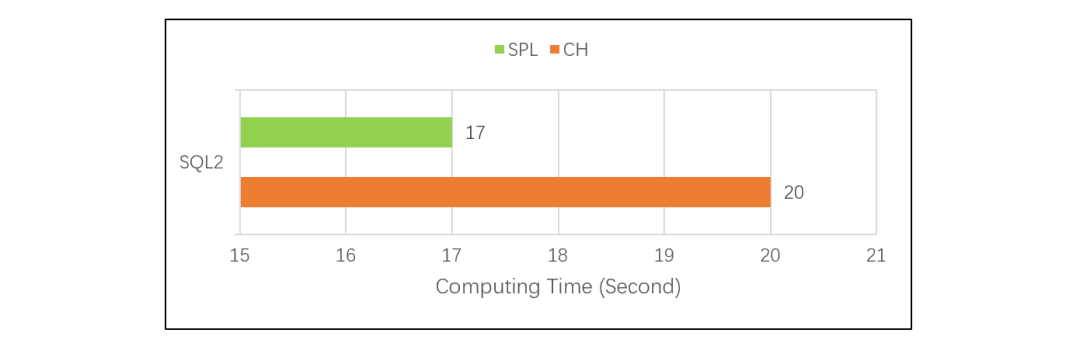 單看 CH 的 SQL2,常規 TopN 的計算方法是全排序后取出前 N 條數據。數據量很大時,如果真地做全排序,性能會非常差。SQL2 的測試結果說明,CH 應該和 SPL 一樣做了優化,沒有全排序,所以兩者性能都很快,SPL 稍快一些。也就是說,無論簡單運算還是復雜運算,esProc SPL 都能更勝一籌。
單看 CH 的 SQL2,常規 TopN 的計算方法是全排序后取出前 N 條數據。數據量很大時,如果真地做全排序,性能會非常差。SQL2 的測試結果說明,CH 應該和 SPL 一樣做了優化,沒有全排序,所以兩者性能都很快,SPL 稍快一些。也就是說,無論簡單運算還是復雜運算,esProc SPL 都能更勝一籌。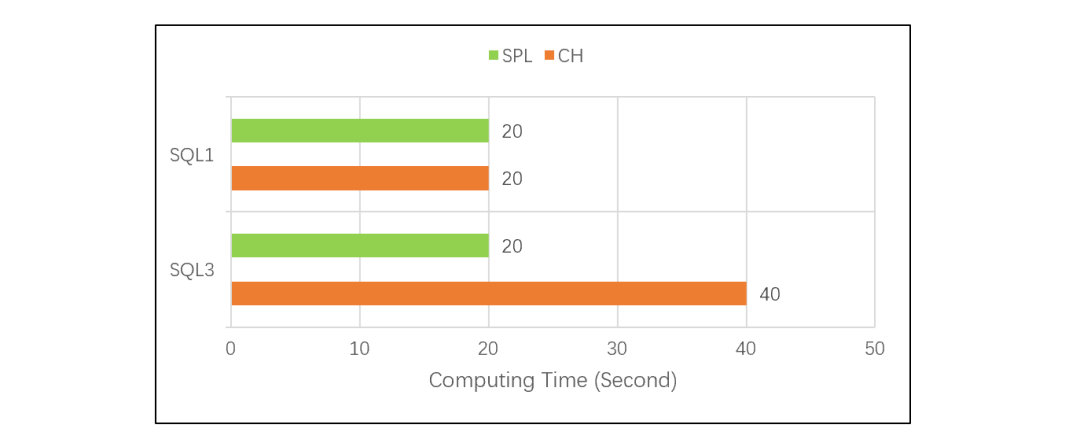 這是因為 SPL 不僅使用了列式游標,還使用了遍歷復用機制,能在一次遍歷過程中計算出多種分組結果,可以減少很多硬盤訪問量。CH 使用的 SQL 無法寫出這樣的運算,只能靠 CH 自身的優化能力了。而 CH 算法優化能力又很差,其優化引擎在這個測試中沒有起作用,只能遍歷兩次,所以性能下降了一倍。SPL 實現遍歷復用的代碼很簡單,大致是這樣:
這是因為 SPL 不僅使用了列式游標,還使用了遍歷復用機制,能在一次遍歷過程中計算出多種分組結果,可以減少很多硬盤訪問量。CH 使用的 SQL 無法寫出這樣的運算,只能靠 CH 自身的優化能力了。而 CH 算法優化能力又很差,其優化引擎在這個測試中沒有起作用,只能遍歷兩次,所以性能下降了一倍。SPL 實現遍歷復用的代碼很簡單,大致是這樣:
 CH 做分組 TopN 計算比常規 TopN 慢了 42 倍,說明 CH 在這種情況下很可能做了排序動作。也就是說,情況復雜化之后,CH 的優化引擎又不起作用了。與 SQL 不同,SPL 把 TopN 看成是一種聚合運算,和 sum、count 這類運算的計算邏輯是一樣的,都只需要對原數據遍歷一次。這樣,分組求組內 TopN 就和分組求和、計數一樣了,可以避免排序計算。因此,SPL 計算分組 TopN 比 CH 快了 22 倍。而且,SPL 計算分組 TopN 的代碼也不復雜:
CH 做分組 TopN 計算比常規 TopN 慢了 42 倍,說明 CH 在這種情況下很可能做了排序動作。也就是說,情況復雜化之后,CH 的優化引擎又不起作用了。與 SQL 不同,SPL 把 TopN 看成是一種聚合運算,和 sum、count 這類運算的計算邏輯是一樣的,都只需要對原數據遍歷一次。這樣,分組求組內 TopN 就和分組求和、計數一樣了,可以避免排序計算。因此,SPL 計算分組 TopN 比 CH 快了 22 倍。而且,SPL 計算分組 TopN 的代碼也不復雜:
審核編輯:湯梓紅 CH 計算 Q1 的表現要好于 ORA,說明 CH 的列式存儲做得不錯,單表遍歷速度很快。而 ORA 主要吃虧在使用了行式存儲,明顯要慢得多了。但是,如果我們加大計算復雜度,CH 的表現怎么樣呢?繼續看 TPC-H 的 Q2、Q3、Q7,測試結果如下:計算變得復雜之后,CH 性能出現了明顯的下降。Q2 涉及數據量較少,列存作用不大,CH 性能和 ORA 幾乎一樣。Q3 數據量較大,CH 占了列存的便宜后超過了 ORA。Q7 數據也較大,但是計算復雜,CH 性能還不如 ORA。做復雜計算快不快,主要看性能優化引擎做的好不好。CH 的列存占據了巨大的存儲優勢,但竟然被 ORA 用行式存儲趕上,這說明 CH 的算法優化能力遠不如 ORA。TPC-H 的 Q8 是更復雜一些的計算,子查詢中有多表連接,CH 跑了 2000 多秒還沒有出結果,應該是卡死了,ORA 跑了 192 秒。Q9 在 Q8 的子查詢中增加了 like,CH 直接報內存不足的錯誤了,ORA 跑了 234 秒。其它還有些復雜運算是 CH 跑不出來的,就沒法做個總體比較了。CH 和 ORA 都基于 SQL 語言,但是 ORA 能優化出來的語句,CH 卻跑不出來,更證明 CH 的優化引擎能力比較差。坊間傳說,CH 只擅長做單表遍歷運算,有關聯運算時甚至跑不過 MySQL,看來并非虛妄胡說。想用 CH 的同學要掂量一下了,這種場景到底能有多大的適應面?esProc SPL 登場
開源 esProc SPL 也是以高性能作為宣傳點,那么我們再來比較一下。仍然是跑 TPC-H 來看 :Q2、Q3、Q7 這些較復雜的運算,SPL 比 CH 和 ORA 跑的都快。CH 跑不出結果的 Q8、Q9,SPL 分別跑了 37 秒和 68 秒,也比 ORA 快。原因在于 SPL 可以采用更優的算法,其計算復雜度低于被 ORA 優化過的 SQL,更遠低于 CH 執行的 SQL,再加上列存,最終是用 Java 開發的 SPL 跑贏了 C++ 實現的 CH 和 ORA。大概可以得到結論,esProc SPL 無論做簡單計算,還是復雜計算性能都非常好。不過,Q1 這種簡單運算,CH 比 SPL 還是略勝了一籌。似乎可以進一步證明前面的結論,即 CH 特別擅長簡單遍歷運算。且慢,SPL 還有秘密武器。SPL 的企業版中提供了列式游標機制,我們再來對比測試一下:在 8 億條數據量下,做最簡單的分組匯總計算,對比 SPL(使用列式游標)和 CH 的性能。(采用的機器配置比前面做 TPC-H 測試時略低,因此測出的結果不同,不過這里主要看相對值。)簡單分組匯總對應 CH 的 SQL 語句是:SQL1:
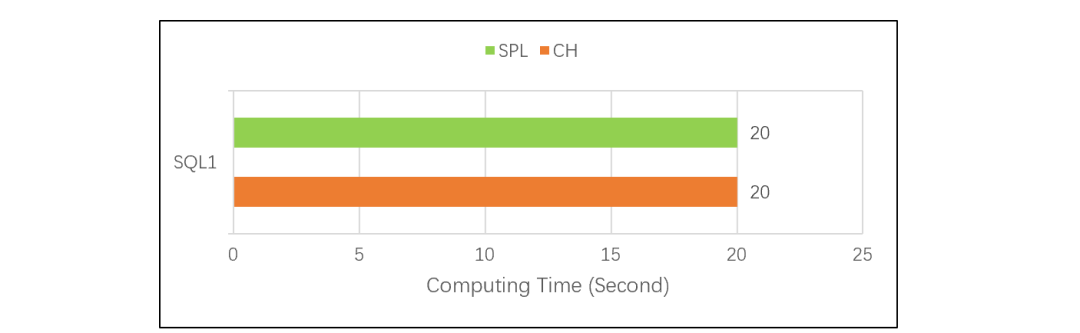
這個測試的結果是下圖這樣:SELECT mod(id, 100) AS Aid, max(amount) AS AmaxFROM test.tGROUP BY mod(id, 100)
SPL 使用列式游標機制之后,簡單遍歷分組計算的性能也和 CH 一樣了。如果在 TPC-H 的 Q1 測試中也使用列式游標,SPL 也會達到和 CH 同樣的性能。測試過程中發現,8 億條數據存成文本格式占用磁盤 15G,在 CH 中占用 5.4G,SPL 占用 8G。說明 CH 和 SPL 都采用了壓縮存儲,CH 的壓縮比更高些,也進一步證明 CH 的存儲引擎做得確實不錯。不過,SPL 也可以達到和 CH 同樣的性能,這說明 SPL 存儲引擎和算法優化做得都比較好,高性能計算能力更加均衡。當前版本的 SPL 是用 Java 寫的,Java 讀數后生成用于計算的對象的速度很慢,而用 C++ 開發的 CH 則沒有這個問題。對于復雜的運算,讀數時間占比不高,Java 生成對象慢造成的拖累還不明顯;而對于簡單的遍歷運算,讀數時間占比很高,所以前面測試中 SPL 就會比 CH 更慢。列式游標優化了讀數方案,不再生成一個個小對象,使對象生成次數大幅降低,這時候就能把差距拉回來了。單純從存儲本身看,SPL 和 CH 相比并沒有明顯的優劣之分。接下來再看常規 TopN 的對比測試,CH 的 SQL 是:SQL2:
SELECT * FROM test.t ORDER BY amount DESC LIMIT 100
對比測試結果是這樣的:單看 CH 的 SQL2,常規 TopN 的計算方法是全排序后取出前 N 條數據。數據量很大時,如果真地做全排序,性能會非常差。SQL2 的測試結果說明,CH 應該和 SPL 一樣做了優化,沒有全排序,所以兩者性能都很快,SPL 稍快一些。也就是說,無論簡單運算還是復雜運算,esProc SPL 都能更勝一籌。進一步的差距
差距還不止于此。正如前面所說,CH 和 ORA 使用 SQL 語言,都是基于關系模型的,所以都面臨 SQL 優化的問題。TPC-H 測試證明,ORA 能優化的一些場景 CH 卻優化不了,甚至跑不出結果。那么,如果面對一些 ORA 也不會優化的計算,CH 就更不會優化了。比如說我們將 SQL1 的簡單分組匯總,改為兩種分組匯總結果再連接,CH 的 SQL 寫出來大致是這樣:SQL3:SELECT *FROM (SELECT mod(id, 100) AS Aid, max(amount) AS AmaxFROM test.tGROUP BY mod(id, 100)) AJOIN(SELECTfloor(id/200000)ASBid,min(amount)ASBminFROMtest.tGROUPBYfloor(id/200000))BONA.Aid=B.Bid
這種情況下,對比測試的結果是 CH 的計算時間翻倍,SPL 則不變:
這是因為 SPL 不僅使用了列式游標,還使用了遍歷復用機制,能在一次遍歷過程中計算出多種分組結果,可以減少很多硬盤訪問量。CH 使用的 SQL 無法寫出這樣的運算,只能靠 CH 自身的優化能力了。而 CH 算法優化能力又很差,其優化引擎在這個測試中沒有起作用,只能遍歷兩次,所以性能下降了一倍。SPL 實現遍歷復用的代碼很簡單,大致是這樣:| A | B | |
| 1 | =file("topn.ctx").open().cursor@mv(id,amount) | |
| 2 | cursor A1 | =A2.groups(id%100:Aid;max(amount):Amax) |
| 3 | cursor | =A3.groups(id200000:Bid;min(amount):Bmin) |
| 4 | =A2.join@i(Aid,A3:Bid,Bid,Bmin) | |
再將 SQL2 常規 TopN 計算,調整為分組后求組內 TopN。對應 SQL 是:
SQL4:SELECTgid,groupArray(100)(amount)ASamountFROM(SELECTmod(id, 10) AS gid,amountFROMtest.topnORDERBYgid ASC,amount DESC)ASaGROUPBYgid
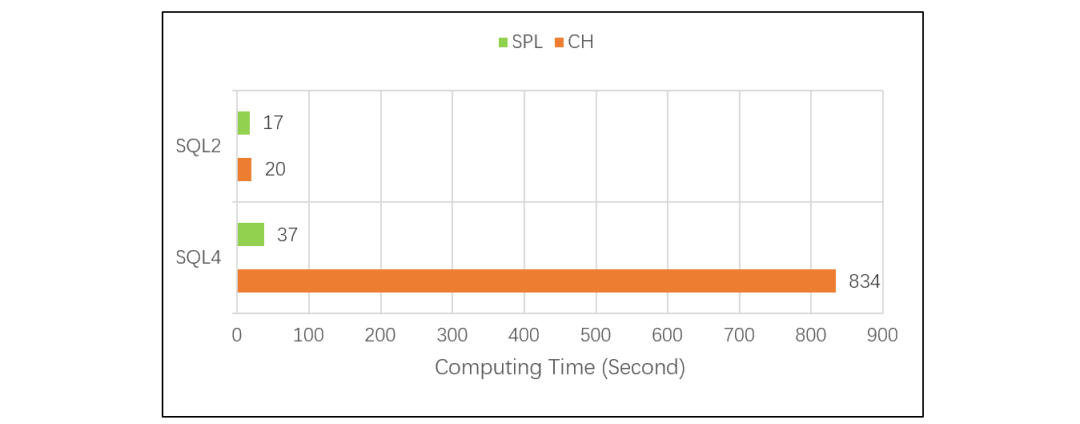
這個分組 TopN 測試的對比結果是下面這樣的:
CH 做分組 TopN 計算比常規 TopN 慢了 42 倍,說明 CH 在這種情況下很可能做了排序動作。也就是說,情況復雜化之后,CH 的優化引擎又不起作用了。與 SQL 不同,SPL 把 TopN 看成是一種聚合運算,和 sum、count 這類運算的計算邏輯是一樣的,都只需要對原數據遍歷一次。這樣,分組求組內 TopN 就和分組求和、計數一樣了,可以避免排序計算。因此,SPL 計算分組 TopN 比 CH 快了 22 倍。而且,SPL 計算分組 TopN 的代碼也不復雜:| A | |
| 1 | =file("topn.ctx").open().cursor@mv(id,amount) |
| 2 | =A1.groups(id%10:gid;top(10;-amount)).news(#2;gid,~.amount) |
不只是跑得快
再來看看電商系統中常見的漏斗運算。SPL 的代碼依然很簡潔:| A | B | |
| 1 | =["etype1","etype2","etype3"] | =file("event.ctx").open() |
| 2 |
=B1.cursor(id,etime,etype;etime>=date("2021-01-10") && etime |
|
| 3 | =A2.group(id).(~.sort(etime)) | =A3.new(~.select@1(etype==A1(1)):first,~:all).select(first) |
| 4 |
=B3.(A1.(t=if(#==1,t1=first.etime,if(t,all.select@1(etype==A1.~ && etime>t && etime |
|
| 5 | =A4.groups(;count(~(1)):STEP1,count(~(2)):STEP2,count(~(3)):STEP3) | |
CH 的 SQL 無法實現這樣的計算,我們以 ORA 為例看看三步漏斗的 SQL 寫法:
ORA 的 SQL 寫出來要三十多行,理解起來有相當的難度。而且這段代碼和漏斗的步驟數量相關,每增加一步數就要再增加一段子查詢。相比之下,SPL 就簡單得多,處理任意步驟數都是這段代碼。這種復雜的 SQL,寫出來都很費勁,性能優化更無從談起。而 CH 的 SQL 還遠不如 ORA,基本上寫不出這么復雜的邏輯,只能在外部寫 C++ 代碼實現。也就是說,這種情況下只能利用 CH 的存儲引擎。雖然用 C++ 在外部計算有可能獲得很好的性能,但開發成本非常高。類似的例子還有很多,CH 都無法直接實現。with e1 as (select gid,1 as step1,min(etime) as t1from Twhere etime>= to_date('2021-01-10', 'yyyy-MM-dd') and etime<to_date('2021-01-25', 'yyyy-MM-dd')and eventtype='eventtype1' and …group by 1),with e2 as (select gid,1 as step2,min(e1.t1) as t1,min(e2.etime) as t2from T as e2inner join e1 on e2.gid = e1.gidwhere e2.etime>= to_date('2021-01-10', 'yyyy-MM-dd') and e2.etime<to_date('2021-01-25', 'yyyy-MM-dd')and e2.etime > t1and e2.etime < t1 + 7and eventtype='eventtype2' and …group by 1),with e3 as (select gid,1 as step3,min(e2.t1) as t1,min(e3.etime) as t3from T as e3inner join e2 on e3.gid = e2.gidwhere e3.etime>= to_date('2021-01-10', 'yyyy-MM-dd') and e3.etime<to_date('2021-01-25', 'yyyy-MM-dd')and e3.etime > t2and e3.etime < t1 + 7and eventtype='eventtype3' and …group by 1)selectsum(step1) as step1,sum(step2) as step2,sum(step3) as step3frome1left join e2 on e1.gid = e2.gidleft join e3 on e2.gid = e3.gid
總結一下:CH 計算某些簡單場景(比如單表遍歷)確實很快,和 SPL 的性能差不多。但是,高性能計算不能只看簡單情況快不快,還要權衡各種場景。對于復雜運算而言,SPL 不僅性能遠超 CH,代碼編寫也簡單很多。SPL 能覆蓋高性能數據計算的全場景,可以說是完勝 CH。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
SQL
+關注
關注
1文章
760瀏覽量
44082 -
數據庫
+關注
關注
7文章
3767瀏覽量
64280 -
開源
+關注
關注
3文章
3256瀏覽量
42420
原文標題:ClickHouse 挺快,esProc SPL 更快
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Linux下AWTK與Qt的性能對比
為了比較直觀的看到AWTK的基本性能,我們對產品開發者比較關心GUI的一些參數做了測試,如界面刷新幀數、啟動時間等。讓我們從參數上直觀了解Linux下AWTK與Qt的性能對比。
發表于 10-29 08:26
談談ST的單片機分類及性能對比
,轉載請注明.文章目錄前言一、ST的單片機分類二、ST性能對比總結前言最近,由于新項目即將開始,我在選型的時候,突然想到早些年的一個面試。當時面試的時候,我說了兩個項目。兩個用到了不同的MCU
發表于 12-09 06:10
arduino和stm32性能對比究竟誰更厲害?
一些DIY和各種小項目?arduino和stm32性能對比究竟誰更厲害呢?我們一起來討論一下。比較兩者之前首先我們來了解下arduino和stm32的特點:Arduino:Arduino UNO-DFRobot商城1. Arduino更傾向于創意,它弱化了具體的硬件的操作,它的函數...
發表于 01-24 07:14
高頻型直流充電機性能對比檢驗試驗總結報告
高頻型直流充電機性能對比檢驗試驗總結報告(開關電源技術課程設計)-高頻型直流充電機性能對比檢驗試驗總結報告? ? ? ? ? ?
發表于 08-31 19:55
?19次下載

ClickHouse和Elasticsearch壓測對比
ClickHouse 是一個真正的列式數據庫管理系統(MS)。在 ClickHouse 中,數據始終是列存儲的,包括向量(對或列塊)的執行過程。只要有可能,操作都是基于向量進行分派的,而不是實現的價值,這被稱為?它有查詢實際的數據處理?。





 工商網監
工商網監
評論