") 從代碼角度詳解Seata AT事務模式的流程
從代碼角度詳解Seata AT事務模式的流程
背景
Seata 四種事務模式中,AT 事務模式是阿里體系獨創(chuàng)的事務模式,對業(yè)務無侵入,也是 Seata 用戶最多的一種事務模式,兼具易用性與高性能。
目前,Seata 社區(qū)正大力推進其多語言版本建設,Go、PHP、JS 和 Python 四個語言版本基本完成了 TCC 事務模式的實現。參照 Seata v1.5.2 版本的 AT 模式的實現,并結合 Seata 官方文檔,本文嘗試從代碼角度詳解 Seata AT 事務模式的詳細流程,目的是梳理 Seata Java 版本 AT 模式的實現細節(jié)后,在多語言版本后續(xù)開發(fā)中,優(yōu)先實現 AT 事務模式。
1、什么是 AT 模式?
AT 模式是一種二階段提交的分布式事務模式,它采用了本地 undo log 的方式來數據在修改前后的狀態(tài),并用它來實現回滾。從性能上來說,AT 模式由于有 undo log 的存在,一階段執(zhí)行完可以立即釋放鎖和連接資源,吞吐量比 XA 模式高。用戶在使用 AT 模式的時候,只需要配置好對應的數據源即可,事務提交、回滾的流程都由 Seata 自動完成,對用戶業(yè)務幾乎沒有入侵,使用便利。
2、AT 模式與 ACID 和 CAP
談論數據庫的事務模式,一般都會先談論事務相關的 ACID 特性,但在分布式場景下,還需要考慮其 CAP 性質。
2.1 AT 與 ACID
數據庫事務要滿足原子性、一致性、持久性以及隔離性四個性質,即 ACID 。在分布式事務場景下,一般地,首先保證原子性和持久性,其次保證一致性,隔離性則因為其使用的不同數據庫的鎖、數據 MVCC 機制以及相關事務模式的差異, 具有多種隔離級別,如 MySQL 自身事務就有讀未提交(Read Uncommitted)、讀已提交(Read Committed)、可重復讀(Repeatable Read)、序列化(Serializable)等四種隔離級別。
2.1.1 AT 模式的讀隔離
在數據庫本地事務隔離級別讀已提交(Read Committed)或以上的基礎上,Seata(AT 模式)的默認全局隔離級別是讀未提交(Read Uncommitted)。
如果應用在特定場景下,必須要求全局的讀已提交,目前 Seata 的方式是通過 SELECT FOR UPDATE 語句的代理。
SELECT FOR UPDATE 語句的執(zhí)行會查詢全局鎖,如果全局鎖被其他事務持有,則釋放本地鎖(回滾 SELECT FOR UPDATE 語句的本地執(zhí)行)并重試。這個過程中,查詢是被 block 住的,直到全局鎖拿到,即讀取的相關數據是已提交的,才返回。
出于總體性能上的考慮,Seata 目前的方案并沒有對所有 SELECT 語句都進行代理,僅針對 FOR UPDATE 的 SELECT 語句。
2.1.2 AT 模式的寫隔離
AT 會對寫操作的 SQL 進行攔截,提交本地事務前,會向 TC 獲取全局鎖,未獲取到全局鎖的情況下,不能進行寫,以此來保證不會發(fā)生寫沖突:
-一階段本地事務提交前,需要確保先拿到全局鎖;
-拿不到全局鎖,不能提交本地事務;
-拿全局鎖的嘗試被限制在一定范圍內,超出范圍將放棄,并回滾本地事務,釋放本地鎖。
2.2 AT 與 CAP
Seata 所有的事務模式在一般情況下,是需要保證 CP,即一致性和分區(qū)容錯性,因為分布式事務的核心就是要保證數據的一致性(包括弱一致性)。比如,在一些交易場景下,涉及到多個系統的金額的變化,保證一致性可以避免系統產生資損。
分布式系統不可避免地會出現服務不可用的情況,如 Seata 的 TC 出現不可用時,用戶可能希望通過服務降級,優(yōu)先保證整個服務的可用性,此時 Seata 需要從 CP 系統轉換為一個保證 AP 的系統。
比如,有一個服務是給用戶端提供用戶修改信息的功能,假如此時 TC 服務出現問題,為了不影響用戶的使用體驗,我們希望服務仍然可用,只不過所有的 SQL 的執(zhí)行降級為不走全局事務,而是當做本地事務執(zhí)行。
AT 模式默認優(yōu)先保證 CP,但提供了配置通道讓用戶在 CP 和 AP 兩種模式下進行切換:
-配置文件的 tm.degrade-check 參數,其值為 true 則分支事務保證 AP,反之保證 CP;
-手動修改配置中心的 service.disableGlobalTransaction 屬性為 true,則關閉全局事務實現 AP。
3、AT 數據源代理
在 AT 模式中,用戶只需要配置好 AT 的代理數據源即可, AT 的所有流程都在代理數據源中完成,對用戶無感知。
AT 數據源代理的整體類結構如下圖:
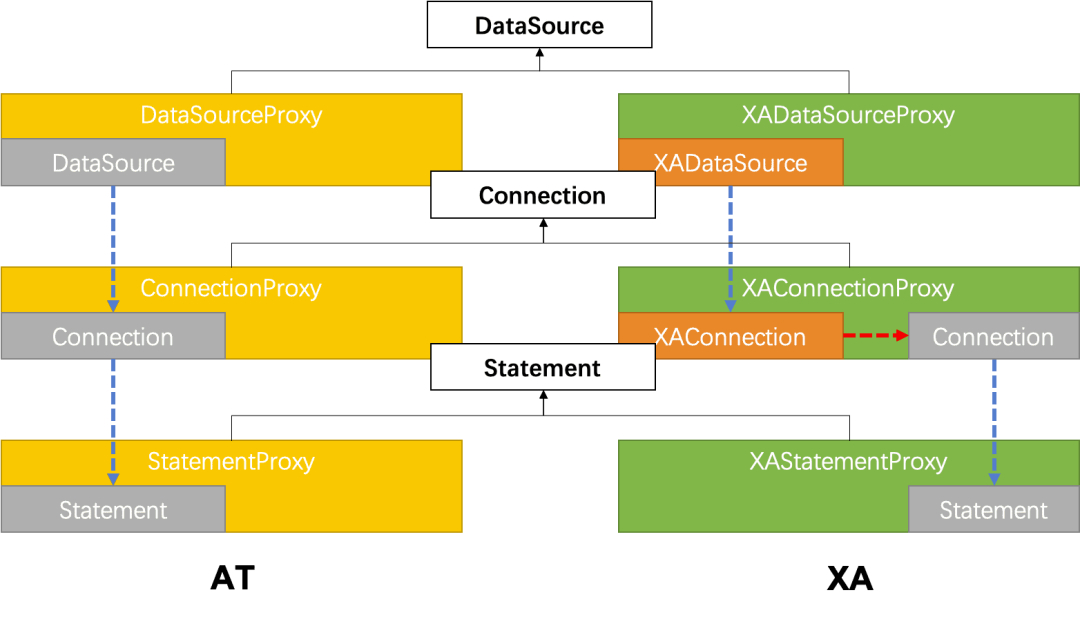
AT 事務數據源代理類結構圖
AT 的數據源代理中,分別對目標數據庫的 DataSource 、 Connection 和 Statement 進行了代理,在執(zhí)行目標 SQL 動作之前,完成了 RM 資源注冊、 undo log 生成、分支事務注冊、分支事務提交 / 回滾等操作,而這些操作對用戶并無感知。
下面的時序圖中,展示了 AT 模式在執(zhí)行過程中,這幾個代理類的動作細節(jié):
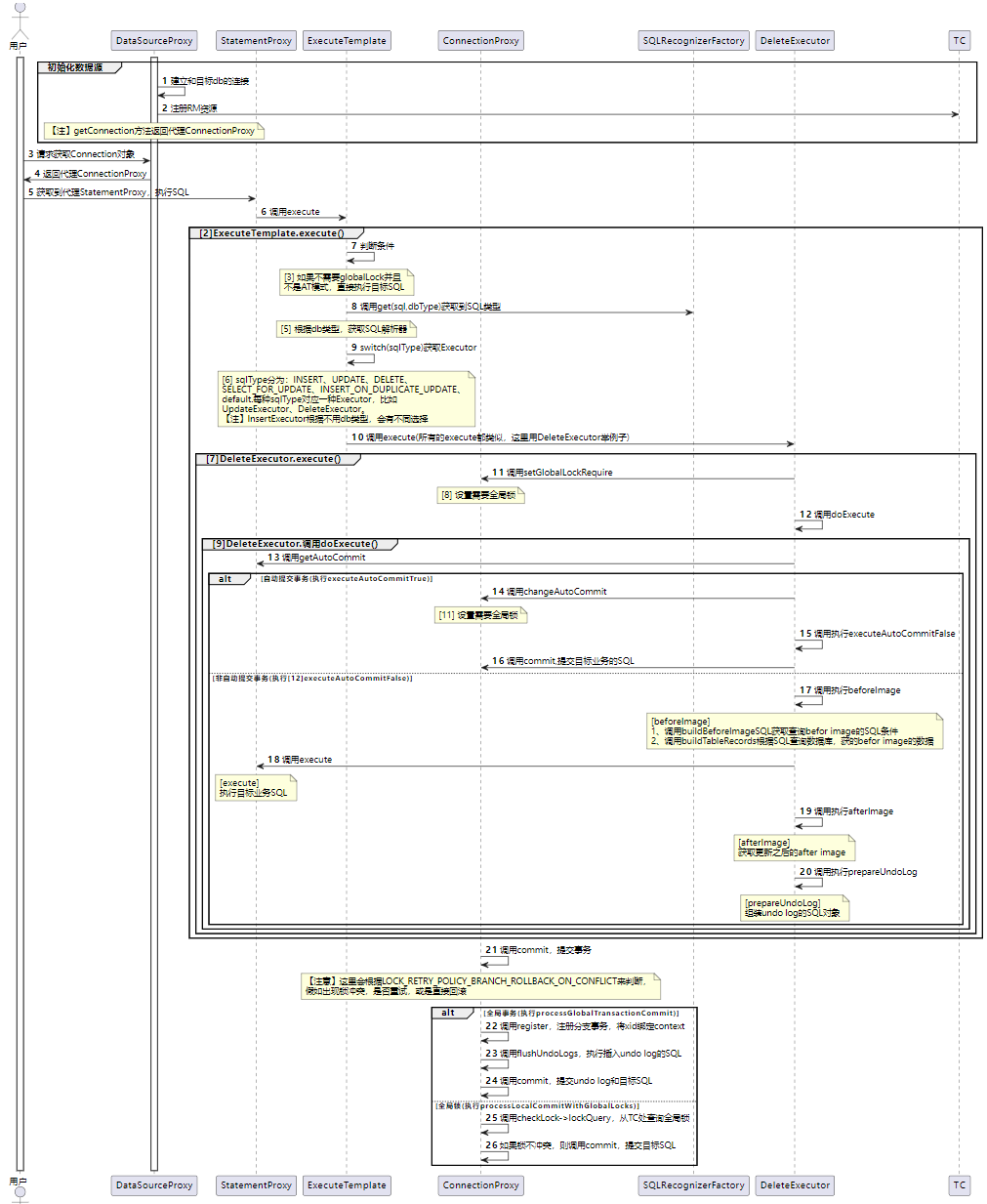
注:圖片建議在 PC 端查看
4、AT 模式流程
以下是 AT 模式的整體流程,從這里可以看到分布式事務各個關鍵動作的執(zhí)行時機,每個動作細節(jié),我們后面來討論:
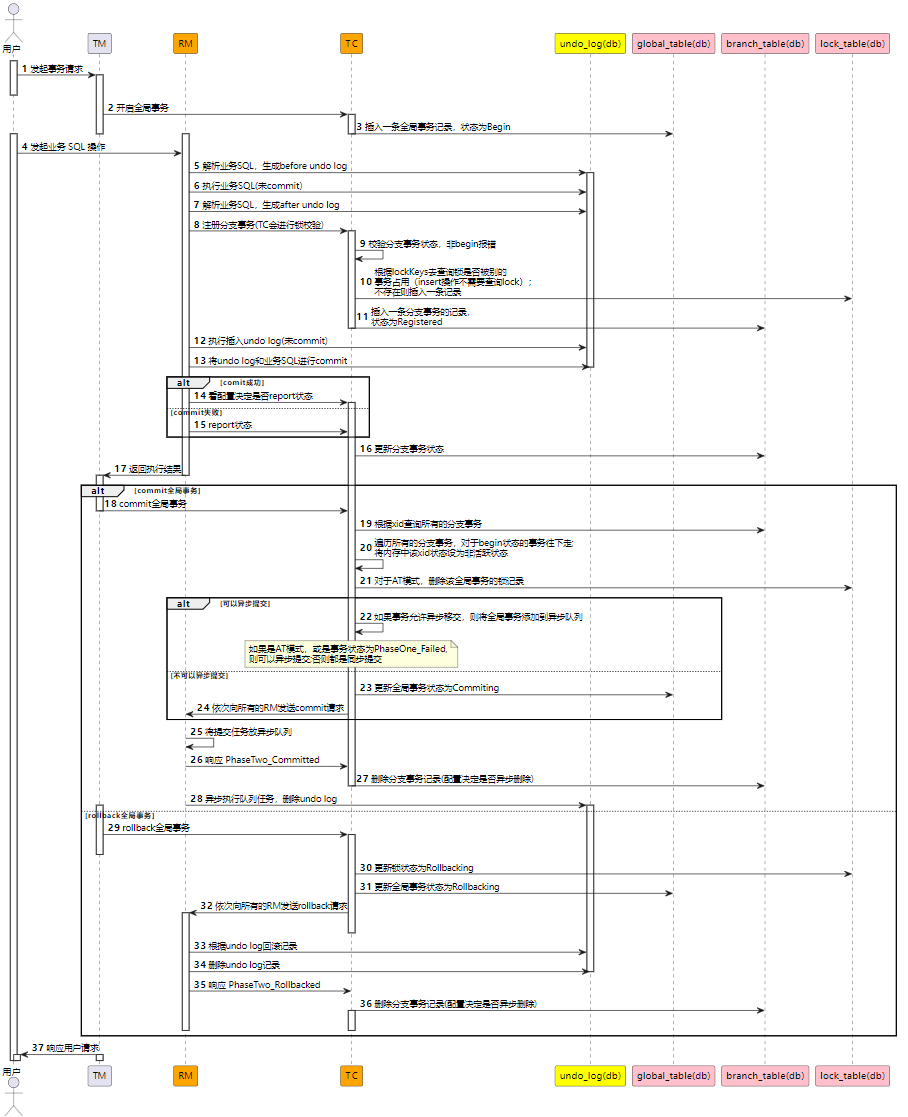
注:圖片建議在 PC 端查看
4.1 一階段
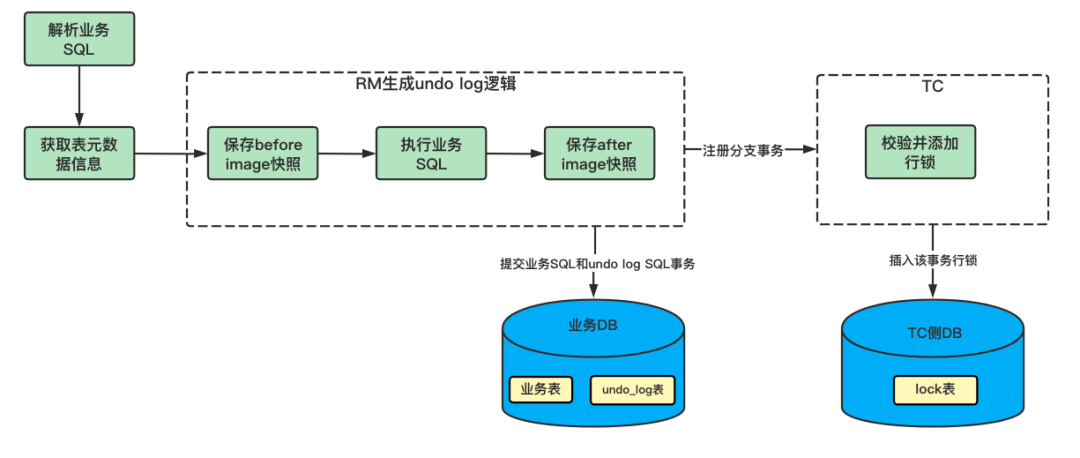
在 AT 模式的第一階段, Seata 會通過代理數據源,攔截用戶執(zhí)行的業(yè)務 SQL ,假如用戶沒有開啟事務,會自動開啟一個新事務。如果業(yè)務 SQL 是寫操作(增、刪、改操作)類型,會解析業(yè)務 SQL 的語法,生成 SELECT SQL 語句,把要被修改的記錄查出來,保存為 “before image” 。然后執(zhí)行業(yè)務 SQL ,執(zhí)行完后用同樣的原理,將已經被修改的記錄查出來,保存為 “after image” ,至此一個 undo log 記錄就完整了。
隨后 RM 會向 TC 注冊分支事務, TC 側會新加鎖記錄,鎖可以保證 AT 模式的讀、寫隔離。RM 再將 undo log 和業(yè)務 SQL 的本地事務提交,保證業(yè)務 SQL 和保存 undo log 記錄 SQL 的原子性。
4.2 二階段提交
AT 模式的二階段提交,TC 側會將該事務的鎖刪除,然后通知 RM 異步刪除 undo log 記錄即可。
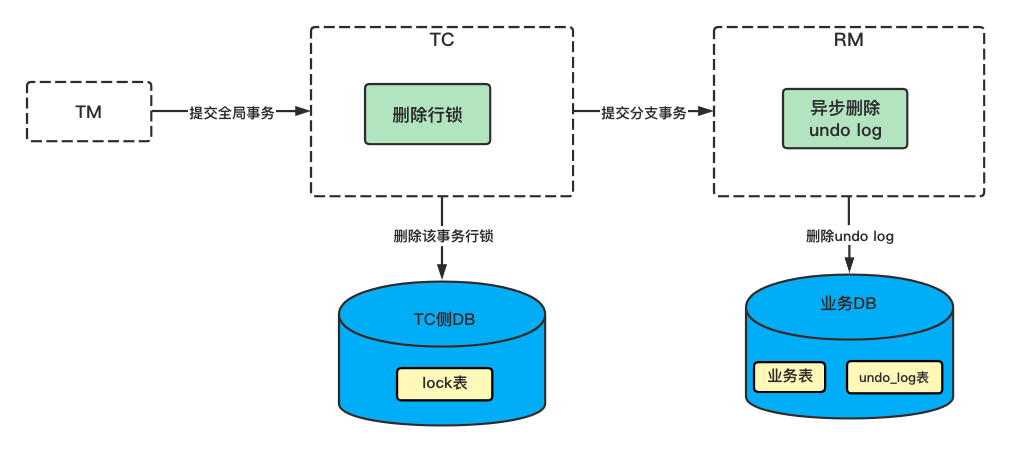
4.3 二階段回滾
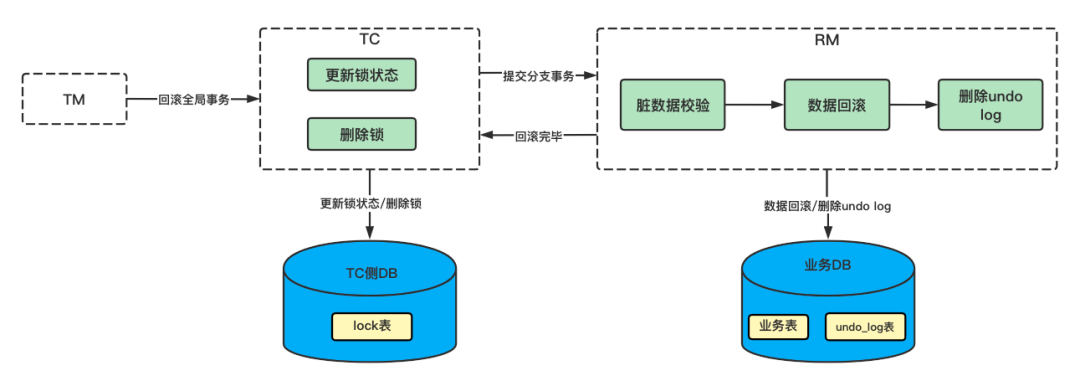
如果 AT 模式的二階段是回滾,那么 RM 側需要根據一階段保存的 undo log 數據中的 before image 記錄,通過逆向 SQL 的方式,對在一階段修改過的業(yè)務數據進行還原即可。
但是在還原數據之前,需要進行臟數據校驗。因為在一階段提交后,到現在進行回滾的中間這段時間,該記錄有可能被別的業(yè)務改動過。校驗的方式,就是用 undo log 的 after image 和現在數據庫的數據做比較,假如數據一致,說明沒有臟數據;不一致則說明有臟數據,出現臟數據就需要人工進行處理了。
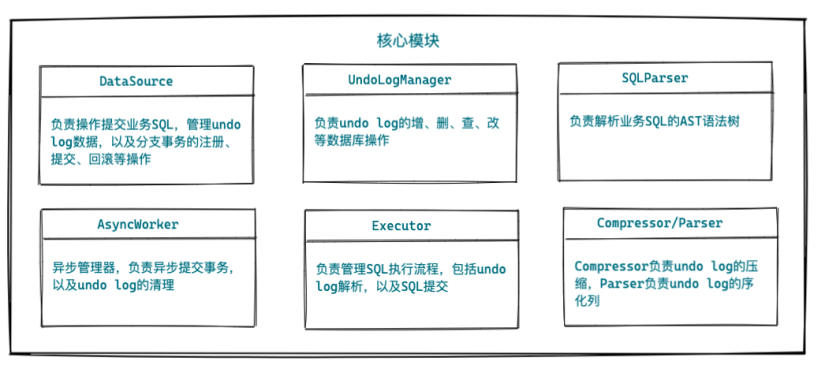
5、關鍵代碼模塊
如下是 AT 模式整個流程的主要模塊,我們從中可以了解開發(fā) AT 模式需要做哪些事情:
5.1 Undo log 數據格式
undo log 存在表 undo_log 表中,undo_log 表的表結構如下:

rollback_info 存放了業(yè)務數據修改前后的內容,數據表存放的是經過壓縮后的格式,他的明文格式如下:
{
"branchId":2828558179596595558,
"sqlUndoLogs":[
{
"afterImage":{
"rows":[
{
"fields":[
{
"keyType":"PRIMARY_KEY",
"name":"id",
"type":4,
"value":3
},
{
"keyType":"NULL",
"name":"count",
"type":4,
"value":70
}
]
}
],
"tableName":"stock_tbl"
},
"beforeImage":{
"rows":[
{
"fields":[
{
"keyType":"PRIMARY_KEY",
"name":"id",
"type":4,
"value":3
},
{
"keyType":"NULL",
"name":"count",
"type":4,
"value":100
}
]
}
],
"tableName":"stock_tbl"
},
"sqlType":"UPDATE",
"tableName":"stock_tbl"
}
],
"xid":"192.168.51.1022828558179596595550"
}
5.2 UndoLogManager
UndoLogManager 負責 undo log 的新加、刪除、回滾操作,不同的數據庫有不同的實現(不同數據庫的 SQL 語法會不同),公共邏輯放在了 AbstractUndoLogManager 抽象類中,整體的類繼承關系如下圖:
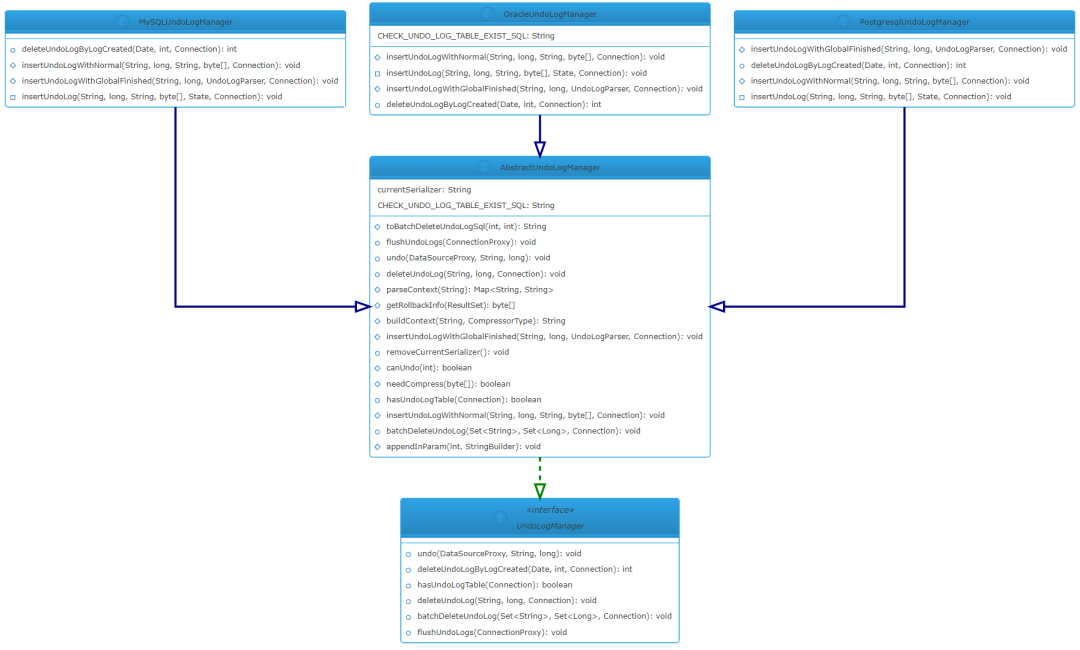
注:圖片建議在 PC 端查看
插入和刪除 undo log 的邏輯都比較簡單,直接操作數據表就行。這里重點看下回滾 undo log 的邏輯:

源碼分析如下:
@Override
public void undo(DataSourceProxy dataSourceProxy, String xid, long branchId) throws TransactionException {
Connection conn = null;b
ResultSet rs = null;
PreparedStatement selectPST = null;
boolean originalAutoCommit = true;
for (; ; ) {
try {
conn = dataSourceProxy.getPlainConnection();
// The entire undo process should run in a local transaction.
// 開啟本地事務,確保刪除undo log和恢復業(yè)務數據的SQL在一個事務中commit
if (originalAutoCommit = conn.getAutoCommit()) {
conn.setAutoCommit(false);
}
// Find UNDO LOG
selectPST = conn.prepareStatement(SELECT_UNDO_LOG_SQL);
selectPST.setLong(1, branchId);
selectPST.setString(2, xid);
// 查出branchId的所有undo log記錄,用來恢復業(yè)務數據
rs = selectPST.executeQuery();
boolean exists = false;
while (rs.next()) {
exists = true;
// It is possible that the server repeatedly sends a rollback request to roll back
// the same branch transaction to multiple processes,
// ensuring that only the undo_log in the normal state is processed.
int state = rs.getInt(ClientTableColumnsName.UNDO_LOG_LOG_STATUS);
// 如果state=1,說明可以回滾;state=1說明不能回滾
if (!canUndo(state)) {
if (LOGGER.isInfoEnabled()) {
LOGGER.info("xid {} branch {}, ignore {} undo_log", xid, branchId, state);
}
return;
}
String contextString = rs.getString(ClientTableColumnsName.UNDO_LOG_CONTEXT);
Map context = parseContext(contextString);
byte[] rollbackInfo = getRollbackInfo(rs);
String serializer = context == null ? null : context.get(UndoLogConstants.SERIALIZER_KEY);
// 根據serializer獲取序列化工具類
UndoLogParser parser = serializer == null ? UndoLogParserFactory.getInstance()
: UndoLogParserFactory.getInstance(serializer);
// 反序列化undo log,得到業(yè)務記錄修改前后的明文
BranchUndoLog branchUndoLog = parser.decode(rollbackInfo);
try {
// put serializer name to local
setCurrentSerializer(parser.getName());
List sqlUndoLogs = branchUndoLog.getSqlUndoLogs();
if (sqlUndoLogs.size() > 1) {
Collections.reverse(sqlUndoLogs);
}
for (SQLUndoLog sqlUndoLog : sqlUndoLogs) {
TableMeta tableMeta = TableMetaCacheFactory.getTableMetaCache(dataSourceProxy.getDbType()).getTableMeta(
conn, sqlUndoLog.getTableName(), dataSourceProxy.getResourceId());
sqlUndoLog.setTableMeta(tableMeta);
AbstractUndoExecutor undoExecutor = UndoExecutorFactory.getUndoExecutor(
dataSourceProxy.getDbType(), sqlUndoLog);
undoExecutor.executeOn(conn);
}
} finally {
// remove serializer name
removeCurrentSerializer();
}
}
// If undo_log exists, it means that the branch transaction has completed the first phase,
// we can directly roll back and clean the undo_log
// Otherwise, it indicates that there is an exception in the branch transaction,
// causing undo_log not to be written to the database.
// For example, the business processing timeout, the global transaction is the initiator rolls back.
// To ensure data consistency, we can insert an undo_log with GlobalFinished state
// to prevent the local transaction of the first phase of other programs from being correctly submitted.
// See https://github.com/seata/seata/issues/489
if (exists) {
deleteUndoLog(xid, branchId, conn);
conn.commit();
if (LOGGER.isInfoEnabled()) {
LOGGER.info("xid {} branch {}, undo_log deleted with {}", xid, branchId,
State.GlobalFinished.name());
}
} else {
// 如果不存在undo log,可能是因為分支事務還未執(zhí)行完成(比如,分支事務執(zhí)行超時),TM發(fā)起了回滾全局事務的請求。
// 這個時候,往undo_log表插入一條記錄,可以使分支事務提交的時候失敗(undo log)
insertUndoLogWithGlobalFinished(xid, branchId, UndoLogParserFactory.getInstance(), conn);
conn.commit();
if (LOGGER.isInfoEnabled()) {
LOGGER.info("xid {} branch {}, undo_log added with {}", xid, branchId,
State.GlobalFinished.name());
}
}
return;
} catch (SQLIntegrityConstraintViolationException e) {
// Possible undo_log has been inserted into the database by other processes, retrying rollback undo_log
if (LOGGER.isInfoEnabled()) {
LOGGER.info("xid {} branch {}, undo_log inserted, retry rollback", xid, branchId);
}
} catch (Throwable e) {
if (conn != null) {
try {
conn.rollback();
} catch (SQLException rollbackEx) {
LOGGER.warn("Failed to close JDBC resource while undo ... ", rollbackEx);
}
}
throw new BranchTransactionException(BranchRollbackFailed_Retriable, String
.format("Branch session rollback failed and try again later xid = %s branchId = %s %s", xid,
branchId, e.getMessage()), e);
} finally {
try {
if (rs != null) {
rs.close();
}
if (selectPST != null) {
selectPST.close();
}
if (conn != null) {
if (originalAutoCommit) {
conn.setAutoCommit(true);
}
conn.close();
}
} catch (SQLException closeEx) {
LOGGER.warn("Failed to close JDBC resource while undo ... ", closeEx);
}
}
}
}
備注:需要特別注意下,當回滾的時候,發(fā)現 undo log 不存在,需要往 undo_log 表新加一條記錄,避免因為 RM 在 TM 發(fā)出回滾請求后,又成功提交分支事務的場景。
5.3 Compressor 壓縮算法
Compressor 接口定義了壓縮算法的規(guī)范,用來壓縮文本,節(jié)省存儲空間:
public interface Compressor {
/**
* compress byte[] to byte[].
* @param bytes the bytes
* @return the byte[]
*/
byte[] compress(byte[] bytes);
/**
* decompress byte[] to byte[].
* @param bytes the bytes
* @return the byte[]
*/
byte[] decompress(byte[] bytes);
}
目前已經實現的壓縮算法有如下這些:

5.4 UndoLogParser 序列化算法
Serializer 接口定義了序列化算法的規(guī)范,用來序列化代碼:
public interface UndoLogParser {
/**
* Get the name of parser;
*
* @return the name of parser
*/
String getName();
/**
* Get default context of this parser
*
* @return the default content if undo log is empty
*/
byte[] getDefaultContent();
/**
* Encode branch undo log to byte array.
*
* @param branchUndoLog the branch undo log
* @return the byte array
*/
byte[] encode(BranchUndoLog branchUndoLog);
/**
* Decode byte array to branch undo log.
*
* @param bytes the byte array
* @return the branch undo log
*/
BranchUndoLog decode(byte[] bytes);
}
目前已經實現的序列化算法有如下這些:
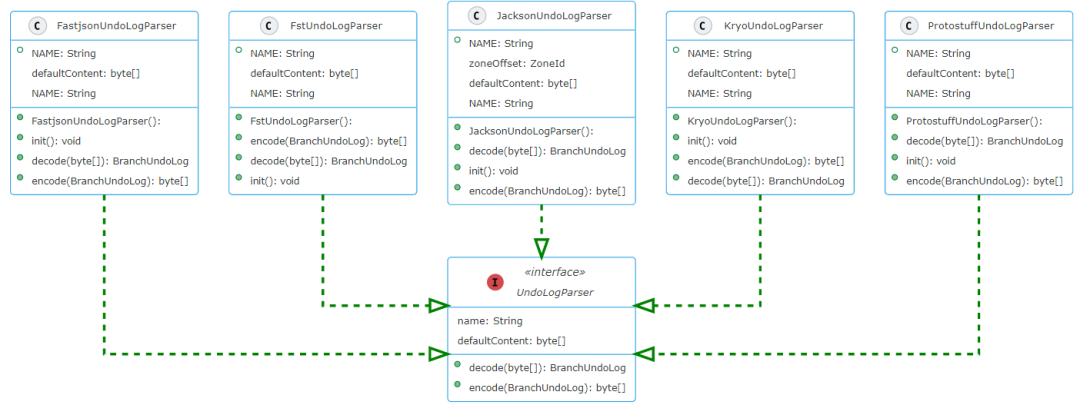
5.5 Executor 執(zhí)行器
Executor 是 SQL 執(zhí)行的入口類, AT 在執(zhí)行 SQL 前后,需要管理 undo log 的 image 記錄,主要是構建 undo log ,包括根據不同的業(yè)務 SQL ,來組裝查詢 undo log 的 SQL 語句;執(zhí)行查詢 undo log 的 SQL ,獲取到鏡像記錄數據;執(zhí)行插入 undo log 的邏輯(未提交事務)。
public interface Executor{ /** * Execute t. * * @param args the args * @return the t * @throws Throwable the throwable */ T execute(Object... args) throws Throwable;}
針對不同的業(yè)務 SQL ,有不同的 Executor 實現,主要是因為不同操作 / 不同數據庫類型的業(yè)務 SQL ,生成 undo log 的 SQL 的邏輯不同,所以都分別重寫了 beforeImage () 和 afterImage () 方法。整體的繼承關系如下圖所示:
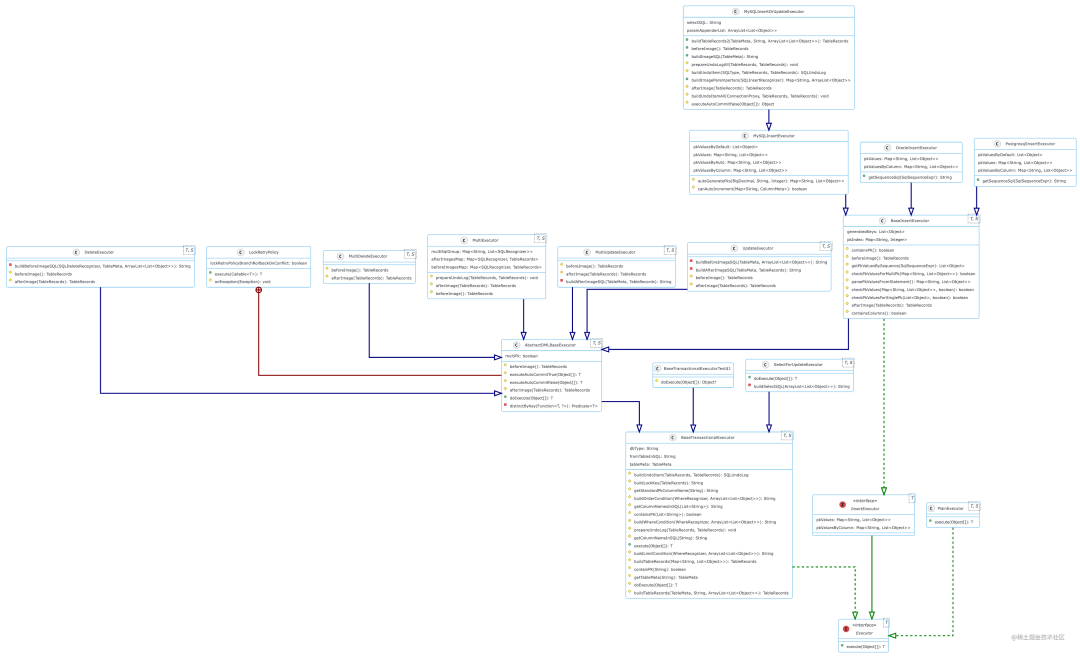
注:圖片建議在 PC 端查看
為了直觀地看到不同類型的 SQL 生成的 before image SQL 和 after iamge SQL ,這里做個梳理。假如目標數據表的結構如下:
public interface Executor{ /** * Execute t. * * @param args the args * @return the t * @throws Throwable the throwable */ T execute(Object... args) throws Throwable; }
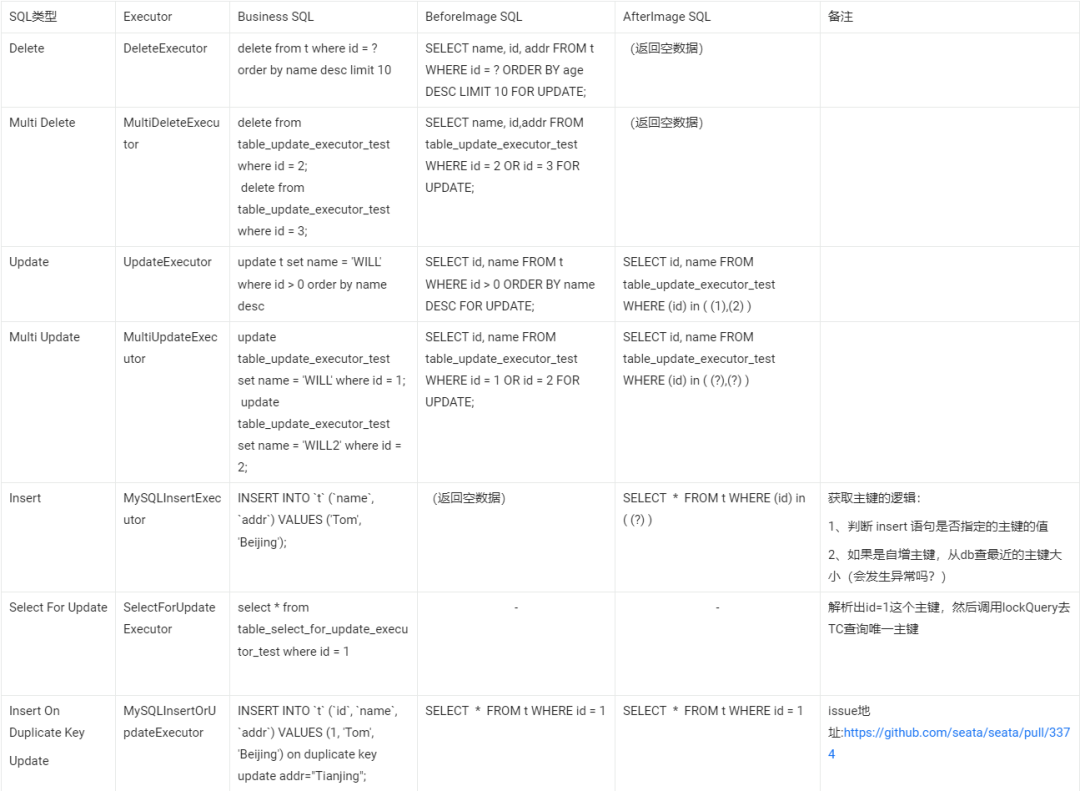
注:圖片建議在 PC 端查看
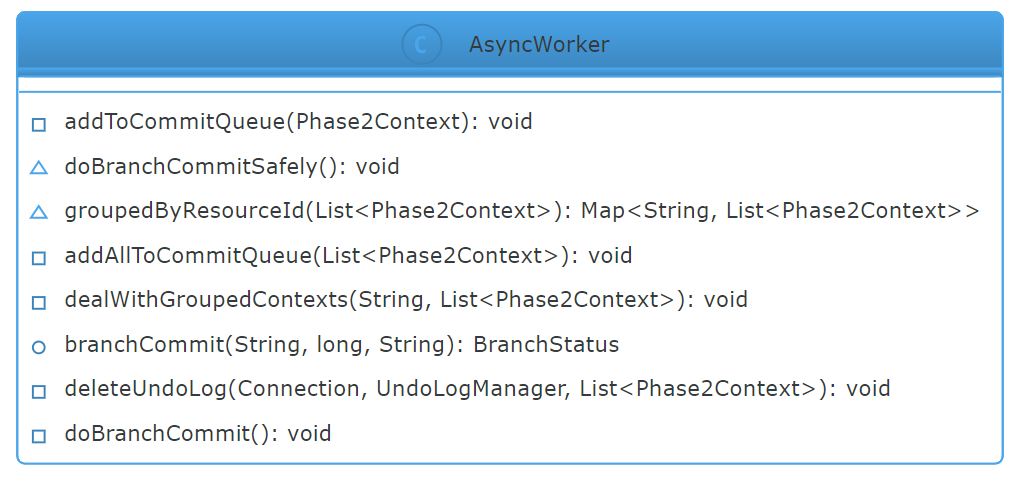
5.6 AsyncWorker
AsyncWorker 是用來做異步執(zhí)行的,用來做分支事務提交和 undo log 記錄刪除等操作。
6、關于性能
并不存在某一種完美的分布式事務機制可以適應所有場景,完美滿足所有需求。無論 AT 模式、TCC 模式還是 Saga 模式,本質上都是對 XA 規(guī)范在各種場景下安全性或者性能的不足的改進。Seata 不同的事務模式是在一致性、可靠性、易用性、性能四個特性之間進行不同的取舍。
近期 Seata 社區(qū)發(fā)現有同行,在未詳細分析 Java 版本 AT 模式的代碼的詳細實現的情況下,僅對某個早期的 Go 版本的 Seata 進行短鏈接壓測后,質疑 AT 模型的性能及其數據安全性,請具有一定思辨能力的用戶朋友們在接受這個結論前仔細查閱其測試方法與測試對象,區(qū)分好 “李鬼” 與 “李逵”。
實際上,這個早期的 Go 版本實現僅參照了 Seata v1.4.0,且未嚴格把 Seata AT 模式的所有功能都予以實現。話說回來,即便其推崇的 Seata XA 模式,其也依賴于單 DB 的 XA 模式。而當下最新版本的 MySQL XA 事務模式的 BUG 依然很多,這個地基并沒有其想象中的那樣百分百穩(wěn)固。
由阿里與螞蟻集團共建的 Seata,是我們多年內部分布式事務工程實踐與技術經驗的結晶,開源出來后得到了多達 150+ 以上行業(yè)同行生產環(huán)境的驗證。開源大道既長且寬,這個道路上可以有機動車道也有非機動車道,還可以有人行道,大家攜手把道路拓寬延長,而非站在人行道上宣傳機動車道危險性高且車速慢。
7、總結
Seata AT 模式依賴于各個 DB 廠商的不同版本的 DB Driver(數據庫驅動),每種數據庫發(fā)布新版本后,其 SQL 語義及其使用模式都可能發(fā)生改變。隨著近年 Seata 被其用戶們廣泛應用于多種業(yè)務場景,在開發(fā)者們的努力下,Seata AT 模式保持了編程接口與其 XA 模式幾乎一致,適配了幾乎所有的主流數據庫,并覆蓋了這些數據庫的主要流行版本的 Driver:真正做到了把分布式系統的 “復雜性” 留在了框架層面,把易用性和高性能交給了用戶。
當然,Seata Java 版本的 XA 和 AT 模式還有許多需要完善與改進的地方,遑論其它多語言版本的實現。歡迎對 Seata 及其多語言版本建設感興趣的同行參與到 Seata 的建設中來,共同努力把 Seata 打造成一個標準化分布式事務平臺。
審核編輯:劉清
-
PHP
+關注
關注
0文章
452瀏覽量
26650 -
JAVA語言
+關注
關注
0文章
138瀏覽量
20076 -
python
+關注
關注
56文章
4782瀏覽量
84456 -
CAP
+關注
關注
0文章
16瀏覽量
2077
原文標題:Seata AT模式代碼級詳解
文章出處:【微信號:OSC開源社區(qū),微信公眾號:OSC開源社區(qū)】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
Spring事務實現原理
EEPROM讀寫程序詳解

如何從服務器角度對ESP設備執(zhí)行ping操作?
ZM8258系列國產藍牙模組詳解① — 多主多從工作模式

AMD FPGA中MicroBlaze的固化流程詳解

如何在AMD Vivado? Design Tool中用工程模式使用DFX流程?
SMT來料加工模式加工流程
阿里二面:了解MySQL事務底層原理嗎
PCB設計流程詳解
騰訊科技獲區(qū)塊鏈網絡事務處理專利
詳解從均值濾波到非局部均值濾波算法的原理及實現方式
Spring事務失效的十種常見場景
什么是CI/CD?基本的gitlab CI/CD流程詳解





 工商網監(jiān)
工商網監(jiān)
評論