 基于幾何特征的桿狀物提取方法
基于幾何特征的桿狀物提取方法
摘要
魯棒、精確的定位是移動自主系統的基本要求。交通標志、電線桿、路燈等類似桿子的物體,由于其獨特的局部性和長期的穩定性,在城市環境中經常被用作定位的地標。本文提出了一種新穎、準確、快速的基于幾何特征的桿狀物提取方法,該方法在線運行,計算量小。該方法直接對由3D 激光雷達掃描產生的Range圖像進行計算,避免了對3D 點云的顯式處理,并能快速提取每次掃描的桿狀物。作者進一步利用提取的桿狀物作為偽標簽,訓練一個深度神經網絡用于在線Range圖像的桿狀物分割。作者測試其幾何和學習為基礎的桿狀物提取方法定位在不同的數據集與不同的激光雷達掃描儀,路線和季節變化。實驗結果表明,作者的方法優于其他最先進的方法。此外,借助于從多個數據集中提取的偽桿狀物標注,作者的基于學習的方法可以跨越不同的數據集,比基于幾何的方法獲得更好的定位結果。作者向公眾發布桿狀物數據集,以評估桿狀物提取器的性能,以及作者方法的實現。
簡介
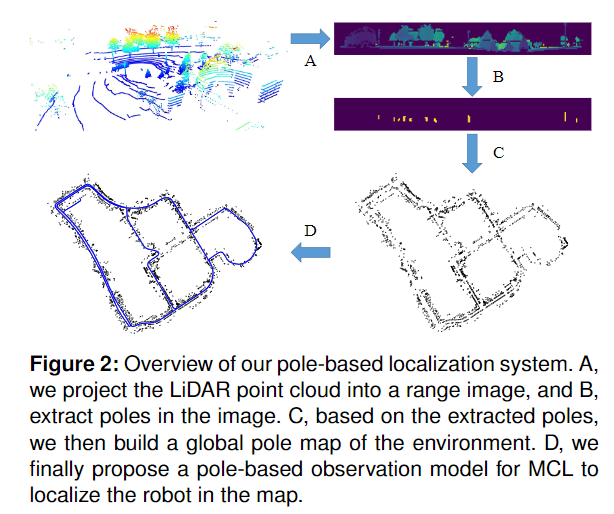
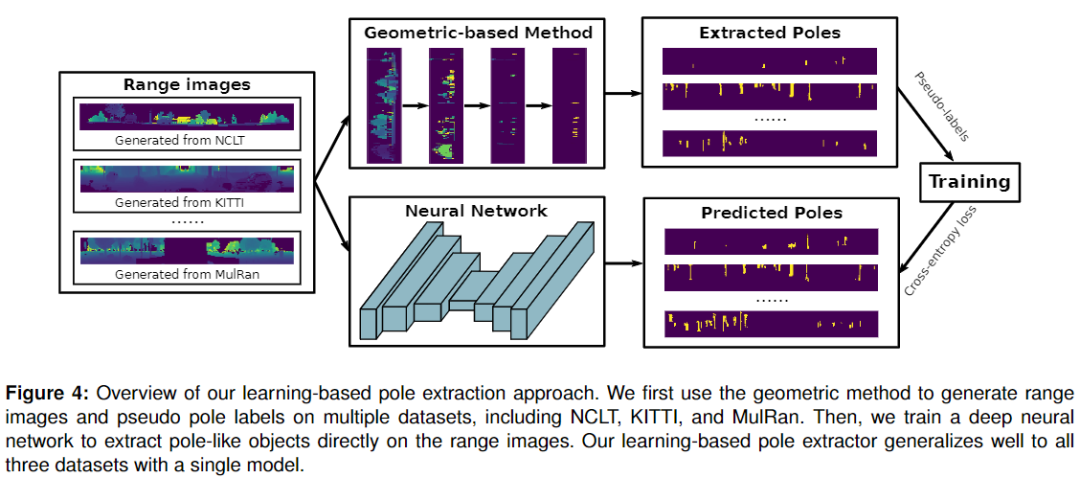
穩健和精確的定位是自主機器人和常用狀態估計任務的關鍵能力。對機器人姿勢的準確估計有助于避免碰撞,以目標導向的方式導航,遵循交通路線,并執行其他任務。這里的可靠性意味著機器人應該適應環境的變化,比如不同的天氣條件[5] ,白天和夜晚 ,或者季節變化。基于GPS的定位系統對環境的外觀變化具有很強的魯棒性。然而,在城市地區,由于建筑物和樹木的阻塞,它們可能受到信號不足的影響。為了移動機器人的精確和可靠的定位,需要額外的、基于地圖的方法。現在已經能使用多種不同類型的傳感器來構建環境地圖,包括光探測和測距(Li-DAR)掃描儀,單目和雙目攝像機。其中,LiDAR 傳感器對光照變化更加穩健,多種基于 LiDAR 的有效和高效建圖方法已經被提出,例如 Behley 和 Stachniss或 Droeschel 和 Behnke。然而,由于地圖表示的原因,這些方法往往需要大量的內存,因此不能很容易地推廣到大規模場景。如果只有特定的特征被用來建立地圖,如交通標志,樹干和其他桿狀結構,地圖的大小可以大大減少。 本文的主要貢獻是提出了一種新的基于Range圖像的桿狀物提取器,可用于自主移動系統的長期定位。作者不再直接使用由三維激光雷達傳感器獲得的原始點云,而是研究如何利用Range圖像進行桿狀物提取。Range圖像是來自旋轉3D 激光雷達(例如 Velodyne 或 Ouster 傳感器)的掃描的光學和自然表示。在Range圖上處理速度相比原始3D激光點云數據也快。此外,一幅Range圖像在其二維結構中隱含了鄰域信息,作者可以利用這些信息進行分割。在Range圖像中檢測到的桿狀物可以進一步作為偽桿狀物標注來訓練桿狀物分割神經網絡。通過對不同數據集產生的偽桿狀物標注進行一次訓練,作者的基于學習的方法可以在不同環境下檢測桿狀物,比基于幾何的方法獲得更好的定位性能。為了實現 LiDAR 定位,在建圖階段,作者首先將原始點云投影到一幅Range圖像中,然后從該圖像中提取桿狀物,如下圖所示。

在獲得Range圖像中桿狀物的位置后,作者使用機器人的姿態ground-truth 將它們重新投影到全局坐標系中,以建立一個全局地圖。在定位過程中,作者利用蒙特卡羅定位(MCL) ,通過將在線傳感器數據中檢測到的桿狀物與全局地圖中的桿狀物進行匹配來更新粒子的重要性權重。 總之,作者提出了三個關鍵的主張,即作者的方法能夠(i)相比基線方法,提取更可靠的桿狀物場景,(ii)在不同的環境中,實現更好的在線定位性能,和(iii)相比基于幾何的方法,產生偽桿狀物標簽訓練桿狀物分割網絡,實現更好的定位結果和更快的運行時間。這些主張得到了論文實驗評估的支持。 數據集和代碼地址:https://github.com/PRBonn/pole-localization
方法論
在本文中,作者提出了一種基于Range圖像的桿狀物提取器,用于使用三維激光雷達傳感器進行長期定位。如下圖所示,作者首先將LiDAR點云投影到Range圖像中,然后使用幾何或基于學習的方法從中提取桿狀物。基于所提出的桿狀物提取器,作者構建了環境的全局桿狀物圖。在定位階段,作者使用相同的提取器在線提取桿狀物,并使用新的基于桿狀物的觀測模型進行蒙特卡羅定位。
1 Range圖生成
作者方法的關鍵思想是使用從激光掃描生成的Range圖像進行桿狀物提取。在先前的工作之后,作者利用球形投影來生成Range圖像。每個LIDAR點P=(x,y,z)通過映射π∶?3 ? ?2映射到球形坐標,最后映射到圖像坐標,如下公式所示。
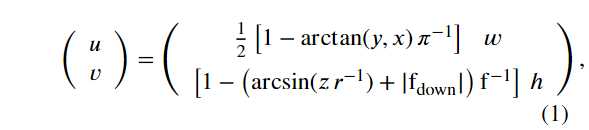

此過程產生的一個列表,列表中包含眾多(u,v)元組,每個(u,v)包含為每個LiDAR點Pi的一對圖像坐標,作者用它來生成代理表示。使用這些索引,作者提取了每個Pi的 range r,x,y,z坐標,并將其存儲在圖像中。
2 基于幾何的桿狀物提取器
根據前一步生成的Range圖像提取桿狀物。通常的桿狀物提取算法的一個先驗直覺是桿狀物的range值通常明顯小于背景。基于這一思想,并按照以下算法流程中的規定。
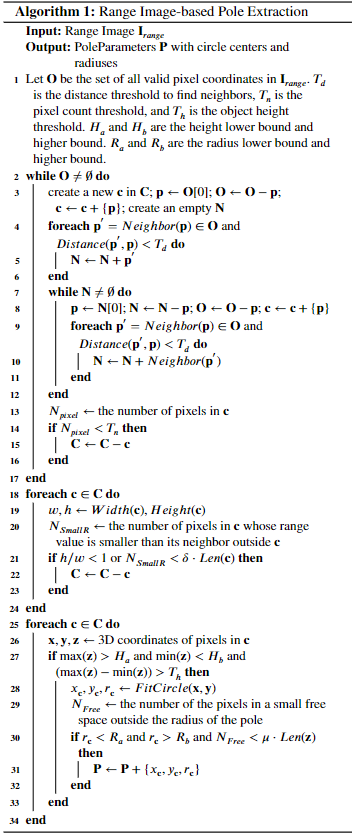
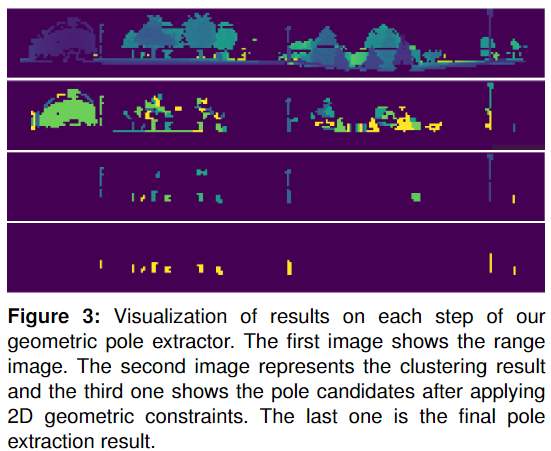
作者的第一步是根據Range值將Range圖像的像素聚類到不同的小區域中。首先遍歷Range圖像中的所有像素,從上到下,從左到右。作者將所有具有有效Range數據的像素放在一個開放集O中。對于每個有效像素p,檢查其鄰居,包括左側、右側和下方。如果存在一個具有有效值的鄰居,并且當前像素與其鄰居之間的Range差小于閾值 Td,作者將當前像素添加到一個簇集c中,并將其從開放集 O中移除。作者對鄰居進行迭代檢查,直到沒有鄰居像素滿足上述標準,然后得到一個像素簇。檢查O中的所有像素后,作者將得到一個包含多個簇的集合C,每個簇代表一個目標。如果一個簇中的像素數小于閾值Tn,作者將其視為異常值并忽略它。 下一步是使用 2D 幾何約束從這些目標中提取桿狀物。為此,作者利用每個像素的Range信息和 3D 坐標(x,y,z)。作者首先檢查每個集群的縱橫比。由于只對高度通常大于寬度的桿狀物體感興趣,因此作者丟棄縱橫比(h/w) < 1 的簇。作者使用的另一個啟發式方法是桿通常獨立存在并且具有與背景物體的顯著距離。N(smallR)是集群c中Range值小于其在c外鄰居的點的數量,如果 N(smallR)小于delta乘以集群中所有點的數量,作者將丟棄該集群。 為了利用每個像素的 3D 坐標 (x,y,z),作者計算每個簇的 max(z) - min(z),如果 max(z)-min(z) > T?,則作為候選桿狀物。此外,作者只對高度高于閾值Ha的桿感興趣。根據經驗,作者還為桿狀物的最低位置設置了一個閾值Hb,以過濾異常值。對于每個候選桿狀物,作者使用集群中所有點的 x 和 y 坐標來擬合一個圓,得到該桿狀物的中心和半徑。作者通過檢查周圍的可用空間來過濾掉半徑過小或過大的候選目標以及連接到其他目標的候選目標。經過上述步驟,作者最終提取了桿狀物的位置和半徑。例如下圖,可視化了幾何桿狀物提取器每一步的中間結果。
3 利用偽標簽訓練基于學習的桿狀物分割方法
如 [11] 所示,幾何信息可用于自動生成標簽,用于訓練基于 LiDAR 的運動物體分割網絡,并在各種環境中取得良好的性能。這種自動標注方法能夠以自監督的方式進行網絡學習,從而節省了大量的手動標注工作,并提高了基于學習的方法的泛化能力。受此啟發,作者使用基于幾何的桿狀物提取器檢測到的桿狀物來生成偽標簽來訓練在線桿狀物分割網絡。 作者使用基于幾何的方法從 NCLT [5]、SemanticKITTI [2] 和 Mul-Ran [20] 數據集生成偽桿狀物標簽。在這項工作中,作者沒有設計新的網絡架構,而是重用過去已成功應用于基于 LiDAR 的語義分割的網絡。作者采用并評估 SalsaNext [14],這是一種編碼器-解碼器架構,在語義分割任務上具有可靠的性能。SalsaNext [14] 在所有基于Range圖像的語義分割網絡中的 SemanticKITTI 數據集上實現了SOTA性能。因此,作者選擇它作為基于學習的方法的基礎網絡架構。在作者的例子中,只是將桿狀物與其他物體區分開來,而不是將環境分割成多個類別,如地面、結構、車輛和人類。在分割之后,應用幾何方法中使用的類似過濾步驟來去除異常值。SalsaNext 網絡相對輕量級,并且可以實現實時操作,即運行速度比所采用的 LiDAR 傳感器的常用幀速率(Ouster 和 Velodyne 掃描儀的 10Hz)更快。有關網絡的更多詳細信息,作者參考原始論文 [14]。 為了訓練分割網絡,作者直接向它們提供Range圖像以及從基于幾何的桿狀物提取器生成的偽桿狀物標簽。作者使用與原始分割方法相同的損失函數,同時將所有類映射到兩類,桿狀物和非桿狀物。作者重新訓練網絡并使用作者的桿狀物數據集和定位任務評估桿狀物提取性能。如下圖顯示了作者提出的基于學習的桿狀物分割方法的訓練流程。請注意,作者使用從不同數據集生成的偽桿狀物標簽來訓練網絡,然后使用相同的模型來提取不同環境中的桿狀物。
4 基于桿狀物的建圖
為了構建用于定位的全局建圖,作者遵循 Schaefer 等人介紹的相同設置。將軌跡ground-truth分成等長的較短段,分別提取這些段中的桿狀物,最后合并成一個全局桿狀物圖。由于提供的姿態對于建圖不是很精確[30] ,所以作者只使用每個部分的中間 LiDAR 掃描來提取桿狀物,而不是聚合一個有噪聲的子圖。通過對多個重疊桿狀物檢測的中心和半徑進行平均,合并多個重疊桿狀物檢測,并應用計數模型對動態目標進行濾波。只有那些在連續剖面中出現多次的候選桿狀物被添加到地圖中。
5 蒙特卡羅定位
蒙特卡羅定位(MCL)通常使用粒子濾波器實現[16]。MCL 實現了一種估計概率密度的遞推貝葉斯濾波器。具體的公式見下圖:

在作者的例子中,每個粒子表示機器人在時間 t 時的二維姿態 xt = (x,y,delta) t 的一個假設。當機器人移動時,每個粒子的姿態都是基于一個運動模型和控制輸入 u 或里程測量更新的。對于觀測模型,基于期望觀測值與實際觀測值的差異更新粒子的權重。觀測結果是桿狀物的位置。作者使用 k-d 樹通過最近鄰搜索將在線觀測的桿狀物與地圖中的桿狀物進行匹配。第j個粒子的最大似然使用高斯分布進行近似:

作者使用桿狀物位置之間的歐氏距離度量來測量這種差異。公式中的常數考慮了檢測到的桿狀物不是地圖一部分的可能性。當存在許多異常值時,這個常數對于定位的魯棒性是至關重要的。如果有效粒子的數量低于閾值[19] ,則觸發重采樣過程,并根據粒子的權重對其進行采樣。
實驗
這項工作的主要重點是為長期LiDAR定位獲得一個準確和高效的桿狀物提取器。作者展示實驗,以顯示作者的方法的效果。實驗進一步支持了作者的關鍵主張,作者的方法能夠: (i)比基線方法提取更可靠的桿狀物,因此,(ii)在不同的環境中實現更好的在線定位性能,和(iii)相比幾何方法,產生偽桿狀物標簽訓練桿狀物分割網絡實現更好的定位結果和更快的運行時間。
1 桿狀物提取和LiDAR定位數據集
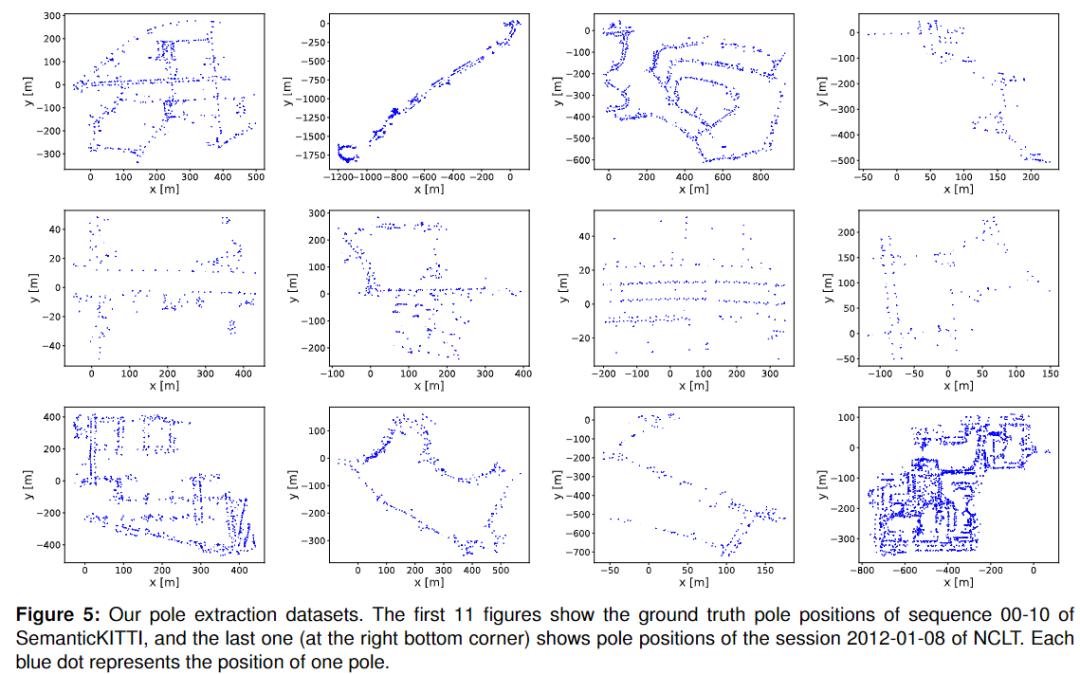
很少有公共數據集可用于評估桿狀物提取性能。為此,作者手工標注了2012-01-08會議的 NCLT 數據集中的桿狀物,并將其發布用于公共研究。由于原始的 NCLT 姿態ground-truth是不準確的[30] ,聚合的點云有點模糊。因此,為了創建環境的桿狀物ground-truth圖,作者將軌跡ground-truth劃分為等長的較短段。對于每個片段,作者將點云聚合在一起,并使用 Open3D [46]來渲染和標注桿狀物位置。作者只給這些桿狀物貼上高度確定的標簽,而忽略那些模糊的。除了作者自己的標注數據之外,作者還通過提取交通標志,桿子和樹干等桿狀物目標來重組 SemanticKITTI [2]數據集序列00-10,然后聚類點云以生成桿狀物實例ground-truth。 為了評估作者方法的定位可靠性和準確性,作者使用 NCLT 數據集[5]和 MulRan 數據集[20]。這兩個數據集是在不同的環境(美國,韓國)和不同的激光雷達傳感器(Velodyne HDL-32E,Ouster OS1-64)中收集的。在這兩個數據集中,機器人多次通過具有月級時間間隔的同一地點,因此是測試長期定位性能的理想選擇。將作者的方法與 Schaefer 等[30]提出的基于桿狀物的方法和 Chen 等[13]提出的基于Range圖像的方法進行了比較。作者使用公共可用代碼重現他們的結果。對于 SemanticKITTI 數據集,不同序列之間沒有用于評估長期定位的重疊區域。因此,作者只使用從 SemanticKITTI 數據集中提取的桿狀物標簽來訓練作者的網絡。下圖顯示了作者提出的桿狀物數據集的例子。
2 桿狀物提取性能
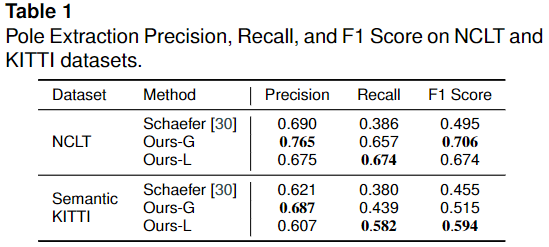
第一個實驗評估了該方法的桿狀物提取性能,并支持了基于Range圖像的桿狀物提取方法優于基線方法的結論。作者評估了基于幾何的桿狀物提取器,命名為ours-G,和作者的基于學習的桿狀物分割方法,命名為ours-L。為了訓練桿狀物分割網絡,作者使用來自多個數據集的數據,包括 NCLT 數據集中的2012-01-08會話,MulRan 數據集中的序列 KAIST 02和 Se-manticKITTI 數據集中的序列00-02,05-09。為了驗證,作者在 SemanticKITTI 數據集中使用序列03和04,在測試中使用序列10。作者使用初始學習率為0.01的隨機梯度下降對網絡進行150個epoch的訓練,學習率衰減為0.01。批量大小為12,空間dropout概率為0.2。Range圖像的尺寸為32 × 256,有效Range值在0 ~ 1之間進行歸一化處理。為了防止過擬合,作者增加了數據應用隨機旋轉或平移,隨機翻轉周圍的 y 軸的概率為0.5。在匹配階段,作者使用一個1m Range范圍的 k-d 樹通過最近鄰搜索找到匹配。下表總結了作者的方法和 Schaefer 等[30]關于 NCLT 數據集和 Se-manticKITTI 數據集的桿狀物groundtruth圖的精確度,召回率和 F1評分。可以看到,與基線方法相比,作者的方法在兩種環境下都獲得了更好的性能和更多的桿狀物提取。
與作者的基于幾何的桿狀物提取器相比,基于學習的方法發現更多的桿狀物,同時引入更多的假陽性,這降低了精度。這也可以在下圖中看到,它顯示了作者的幾何和基于學習的桿狀物提取器桿狀物提取的例子。請注意,作者只訓練一次桿狀物分割網絡,使用不同數據集生成的偽桿狀物標簽,但在多個不同的數據集評估它。如下圖,不同數據集的環境差異很大,而作者的基于學習的方法仍然可以很好地提取桿狀物而不需要進行微調,這表明作者的方法具有很好的泛化能力。
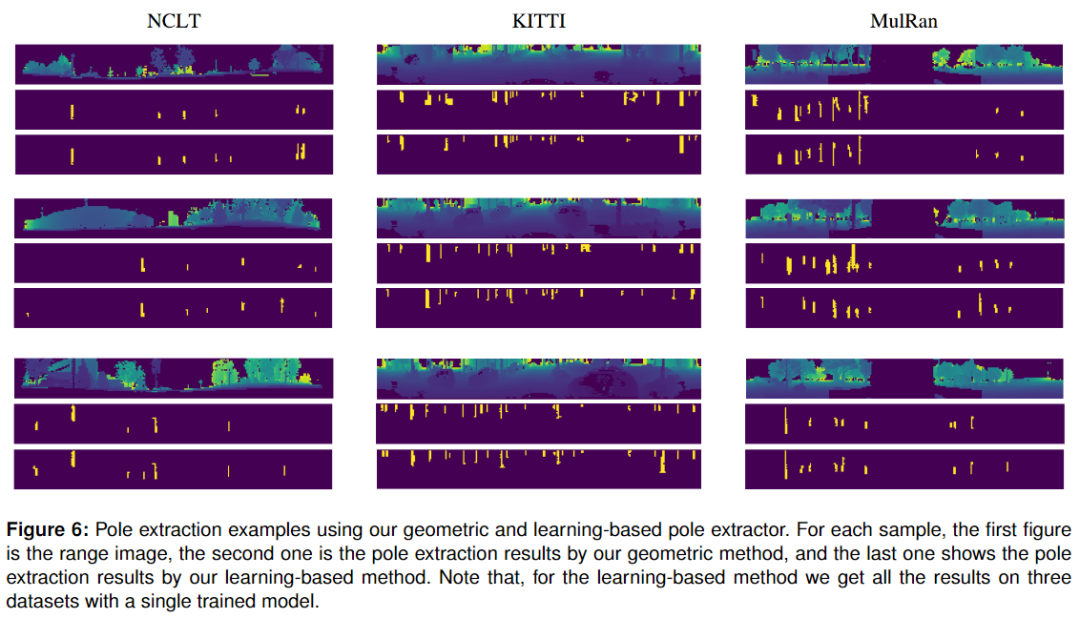
這可能是因為桿狀物的Range值通常與背景有顯著的不同,這使得桿狀物與眾不同,并且很容易在Range圖像上被檢測到。與多類分割相比,神經網絡更容易學習一個更一般的模型來檢測基于Range圖像的桿狀物[10]。此外,基于學習的方法比基于幾何的方法具有更高的召回率,但精度較低,這意味著基于學習的方法檢測出更多的真陽性,但也有更多的假陽性。作者將檢測到的桿狀物作為 MCL 的標志,這是一個非常健壯的概率定位系統。因此,定位性能不會受到少量誤報的影響,而是受益于更高的召回率和更多的地標。
3 定位性能
第二個實驗是為了支持作者的方法在不同環境中實現了更高的定位精度這一說法。對于所有實驗,作者使用與基線相同的設置,并報告原始工作的結果。
NCLT數據集上的定位
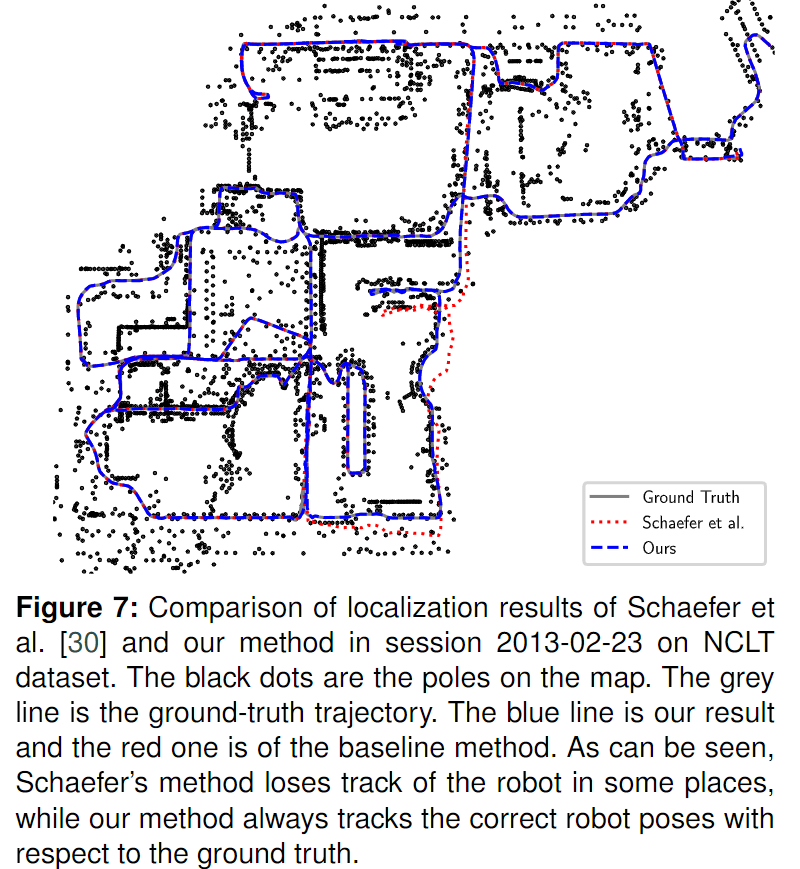
NCLT 數據集包含27個會話,平均長度為5.5公里,平均持續時間為1.3小時,持續時間為15個月。這些數據記錄在一年中不同的時間,不同的天氣和季節,包括室內和室外環境,還有大量的動態目標。不同會話的軌跡有很大的重疊。因此,它是在城市環境中測試長期定位的理想數據集。作者首先根據 Schaefer 等[30]介紹的設置構建地圖,該設置使用第一次會話的激光掃描和姿態ground-truth。由于在以后的會話中,機器人有時會在第一個會話中移動到看不見的地方,因此作者也使用那些位置與之前訪問過的所有姿勢相距10米的掃描來構建地圖。在定位過程中,作者使用了1000個粒子,并使用與 Schaefer 等人相同的初始化方法[30] ,通過在2.5米圓周內圍繞第一個姿態ground-truth的均勻采樣位置。取向是從 -5度到5度均勻取樣的。當有效粒子數小于50% 時,重新采樣粒子。為了獲取姿態估計,作者使用了最好的10%粒子的平均姿態。 下表顯示每個會話的位置和方向誤差。作者進行了10次定位,計算了軌跡ground-truth的平均均值和均方根誤差。結果表明,作者的幾何學和基于學習的方法在幾乎所有會話上都超過了 Schaefer 等[30] ,平均誤差分別為0.174米和0.164米。此外,在2013-02-23會話中,基線方法未能定位,導致誤差為2.470米,而作者的方法從未丟失機器人位置的軌跡(下圖)。這是因為作者的桿狀物提取器能夠在桿狀物較少的環境中也能夠強有力地提取桿狀物。Schaefer 等[31]在2013-02-23會議上分析了他們的定位失敗,原因是建筑區域的油桶在后面的會話中被移動到右邊幾米。由于這些桶通過其方法被檢測為桿狀物,因此它們被構建在地圖中,并導致錯誤的桿狀物與該區域的地圖匹配。在作者的桿狀物提取算法中,丟棄那些半徑過大的極點。因此,這些桶不是作者地圖的一部分,定位不會受到這些桶移動的影響。有趣的是,在大多數會話中,作者基于學習的方法比基于幾何的方法更能提高定位結果。這可能是由于使用不同環境生成的偽標簽訓練的更一般的桿狀物分割模型引起的。
MulRan數據集 上的定位
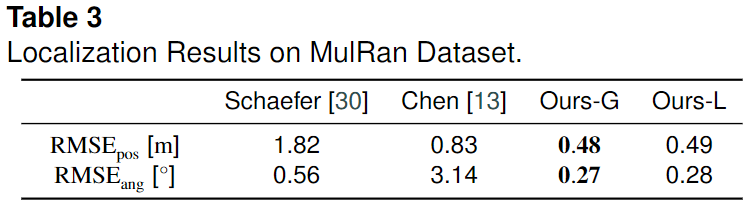
為了進一步顯示作者方法的泛化能力,測試了基于幾何和基于學習的方法在MulRan數據集上的效果。這些數據來自于不同環境下的不同類型的激光雷達傳感器。作者使用 MulRan 數據集 KAIST 02序列(2019-08-23收集)來構建全局地圖,并使用 KAIST 01序列(2019-06-20收集)進行定位。下表顯示了 MulRan 數據集的定位和偏航角 RMSE 誤差。可以看出,作者的幾何和基于學習的方法始終比基線方法獲得更好的性能[30,13]。請注意,作者只訓練桿狀物分割一次,并且在應用到新環境時沒有進行任何微調。
4 運行時間
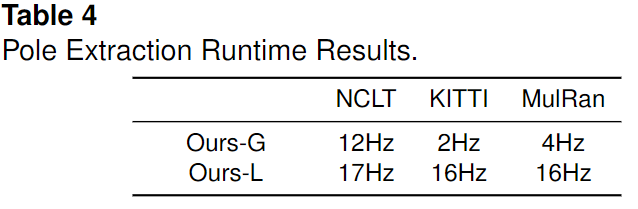
這個實驗是為了支持作者的方法以傳感器幀速率在線運行的說法而進行的。如下表所示。作者的方法與 Schaefer 等[30]在三個不同數據集上提出的基線方法進行比較,包括 NCLT (會議2012-01-08) ,KITTI (序列09)和 MulRan (KAIST 02)數據集。正如他們的論文所報道的,在 NCLT 數據集上,使用 GPU 在 PC 上進行桿狀物提取的基線方法平均需要1.33秒。作者在沒有使用 GPU 的情況下測試了的基于幾何的方法,此方法只需要0.09 s 的桿狀物提取,所有 MCL 步驟都小于0.1 s,比通常使用的10Hz 的 LiDAR 幀速率產生更快的運行時間。 Schaefer 和作者的基于幾何的桿狀物提取器的性能都受到輸入數據大小的影響,這是定位精度和定位速度之間的權衡。為了獲得良好的幾何定位效果,作者對 NCLT 采用了32 × 256的Range像素尺寸,對 KITTI 和 MulRan 采用了64 × 500的Range圖像尺寸,這導致了運行性能的下降。然而,作者的基于學習的方法不受輸入數據大小的影響。作者將網絡輸入的大小定為32 × 256,并且作者的網絡始終在一個單一的 GPU 上具有良好的定位性能,這顯示了作者提出的基于學習的方法的明顯優勢。
總結
本文提出了一種新的基于距離像的幾何特征桿狀物提取方法,用于激光雷達在線長期定位。作者的方法利用激光雷達掃描產生的Range圖像。這允許作者的方法快速處理點云數據并在線運行。進一步利用幾何桿狀物提取器檢測到的桿狀物作為偽標注,訓練深層神經網絡進行在線桿狀物分割。作者的基于學習的桿狀物提取器可以在不進行微調的情況下推廣到不同類型的數據集,盡管不同數據集的環境變化很大。作者在多個不同的數據集上實現并評估了作者的方法,并提供了與其他現有技術的比較,支持本文中提出的所有主張。實驗結果表明,與基線方法相比,基于幾何和基于學習的方法能夠準確地提取環境中更多的桿狀物,在長期定位任務中取得更好的性能。此外,作者發布了作者的實現和桿狀物數據集,以供其他研究人員評估他們的算法。在未來,作者計劃探討其他特征如道路標記,路緣和交叉口特征的使用,以提高作者的方法的魯棒性。 審核編輯:郭婷
-
傳感器
+關注
關注
2548文章
50664瀏覽量
751947 -
機器人
+關注
關注
210文章
28191瀏覽量
206506 -
LIDAR
+關注
關注
10文章
323瀏覽量
29358
原文標題:又快又準!用于LiDAR長期定位的Range圖在線桿狀物提取方法
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于卷積神經網絡的雙重特征提取方法
基于局域判別基的音頻信號特征提取方法
模擬電路故障診斷中的特征提取方法
基于Fisher的Gabor特征提取方法
油管桿狀磨損缺陷的建模與定量檢測
SISAR功率譜特征提取方法
基于小波分析的車輛噪聲特征提取方法
故障特征提取的方法研究

一種對野值魯棒的紋理特征提取方法
一種去冗余的SIFT特征提取方法





 工商網監
工商網監
評論