") NVIDIA AI平臺為大型語言模型帶來巨大收益
NVIDIA AI平臺為大型語言模型帶來巨大收益
隨著大型語言模型( LLM )的規(guī)模和復雜性不斷增長, NVIDIA 今天宣布更新 NeMo Megatron 框架,提供高達 30% 的訓練速度。
這些更新包括兩種開拓性技術(shù)和一個超參數(shù)工具,用于優(yōu)化和擴展任何數(shù)量 GPU 上的 LLM 訓練,提供了使用 NVIDIA AI 平臺訓練和部署模型的新功能。
BLOOM ,世界上最大的開放科學、開放獲取多語言模型,具有 1760 億個參數(shù),最近 在 NVIDIA AI 平臺上接受培訓 ,支持 46 種語言和 13 種編程語言的文本生成。 NVIDIA AI 平臺還支持最強大的 transformer 語言模型之一,具有 5300 億個參數(shù), Megatron-Turing NLG 模型 (MT-NLG)。
法學碩士研究進展
LLM 是當今最重要的先進技術(shù)之一,涉及數(shù)萬億個從文本中學習的參數(shù)。然而,開發(fā)它們是一個昂貴、耗時的過程,需要深入的技術(shù)專業(yè)知識、分布式基礎(chǔ)設(shè)施和全堆棧方法。
然而,在推進實時內(nèi)容生成、文本摘要、客戶服務聊天機器人和對話 AI 界面的問答方面,它們的好處是巨大的。
為了推進 LLM ,人工智能社區(qū)正在繼續(xù)創(chuàng)新工具,例如 Microsoft DeepSpeed , 巨大的人工智能 , 擁抱大科學 和 公平比例 –由 NVIDIA AI 平臺提供支持,涉及 Megatron LM , 頂 ,以及其他 GPU 加速庫。
這些對 NVIDIA AI 平臺的新優(yōu)化有助于解決整個堆棧中存在的許多難點。 NVIDIA 期待著與人工智能社區(qū)合作,繼續(xù)讓所有人都能使用 LLM 。
更快地構(gòu)建 LLM
NeMo Megatron 的最新更新為訓練 GPT-3 模型提供了 30% 的加速,模型大小從 220 億到一萬億參數(shù)不等。現(xiàn)在,使用 1024 個 NVIDIA A100 GPU 只需 24 天,就可以在 1750 億個參數(shù)模型上完成訓練——在這些新版本發(fā)布之前,將得出結(jié)果的時間減少了 10 天,或約 250000 個小時的 GPU 計算。
NeMo Megatron 是一種快速、高效且易于使用的端到端集裝箱化框架,用于收集數(shù)據(jù)、訓練大規(guī)模模型、根據(jù)行業(yè)標準基準評估模型,以及用于推斷最先進的延遲和吞吐量性能。
它使 LLM 訓練和推理在廣泛的 GPU 簇配置上易于重復。目前,這些功能可供早期訪問客戶使用 DGX 疊加視圖 和 NVIDIA DGX 鑄造廠 以及 Microsoft Azure 云。對其他云平臺的支持將很快提供。
你可以試試這些功能 NVIDIA LaunchPad ,這是一個免費項目,提供對 NVIDIA 加速基礎(chǔ)設(shè)施上的動手實驗室目錄的短期訪問。
NeMo Megatron 是 NeMo 的一部分, NeMo 是一個開源框架,用于為會話人工智能、語音人工智能和生物學構(gòu)建高性能和靈活的應用程序。
加速 LLM 訓練的兩種新技術(shù)
優(yōu)化和擴展 LLM 訓練的更新中包括兩種新技術(shù),即序列并行( SP )和選擇性激活重新計算( SAR )。
序列并行性擴展了張量級模型并行性,注意到之前未并行的 transformer 層的區(qū)域沿序列維度是獨立的。
沿著序列維度拆分這些層可以實現(xiàn)計算的分布,最重要的是,這些區(qū)域的激活內(nèi)存可以跨張量并行設(shè)備分布。由于激活是分布式的,因此可以為向后傳遞保存更多激活,而不是重新計算它們。
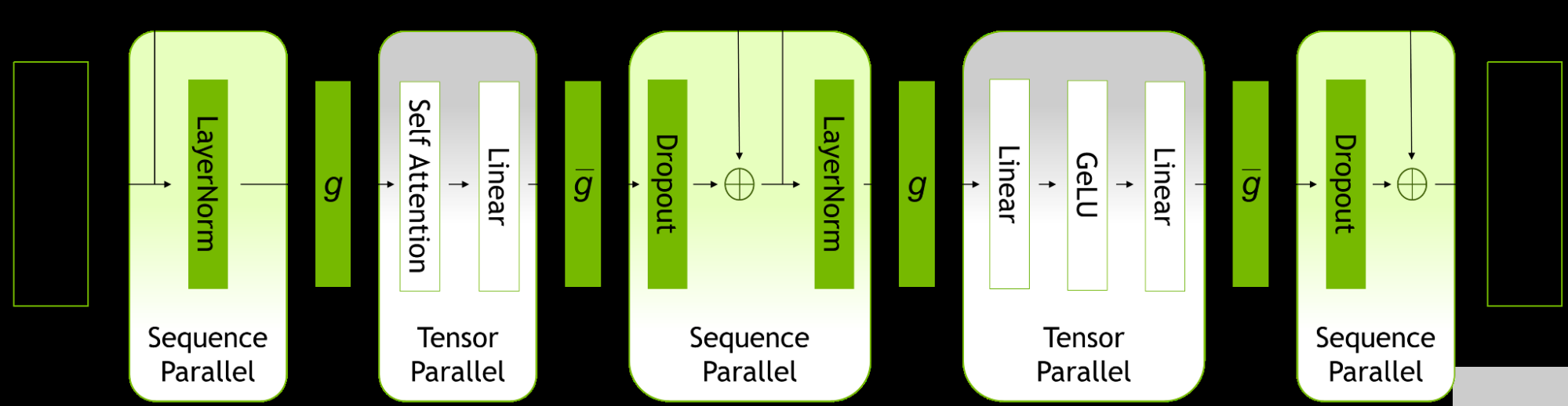
圖 1.ZFK8 層內(nèi)的并行模式。
選擇性激活重新計算通過注意到不同的激活需要不同數(shù)量的操作來重新計算,從而改善了內(nèi)存約束強制重新計算部分(但不是全部)激活的情況。
與檢查點和重新計算整個 transformer 層不同,可以只檢查和重新計算每個 transformer 層中占用大量內(nèi)存但重新計算計算成本不高的部分。
有關(guān)更多信息,請參閱 減少大型 transformer 模型中的激活重新計算 。
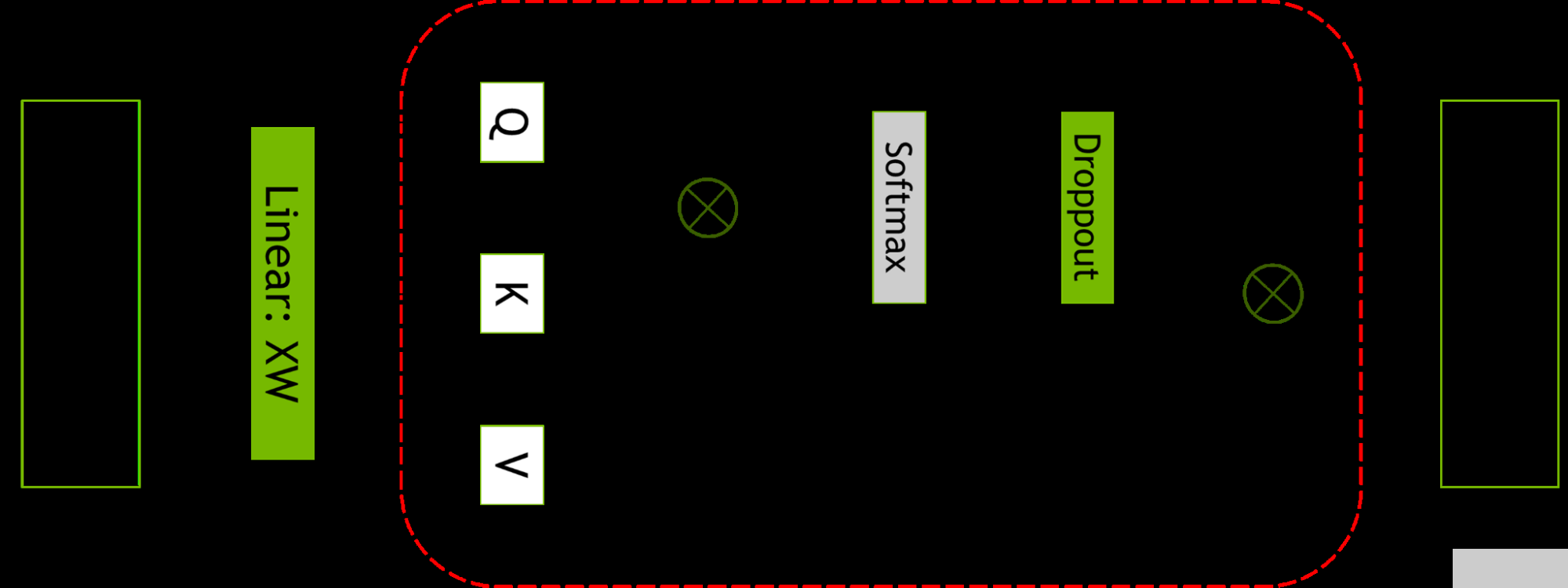
圖 2.自注意力塊。紅色虛線顯示了應用選擇性激活重新計算的區(qū)域。
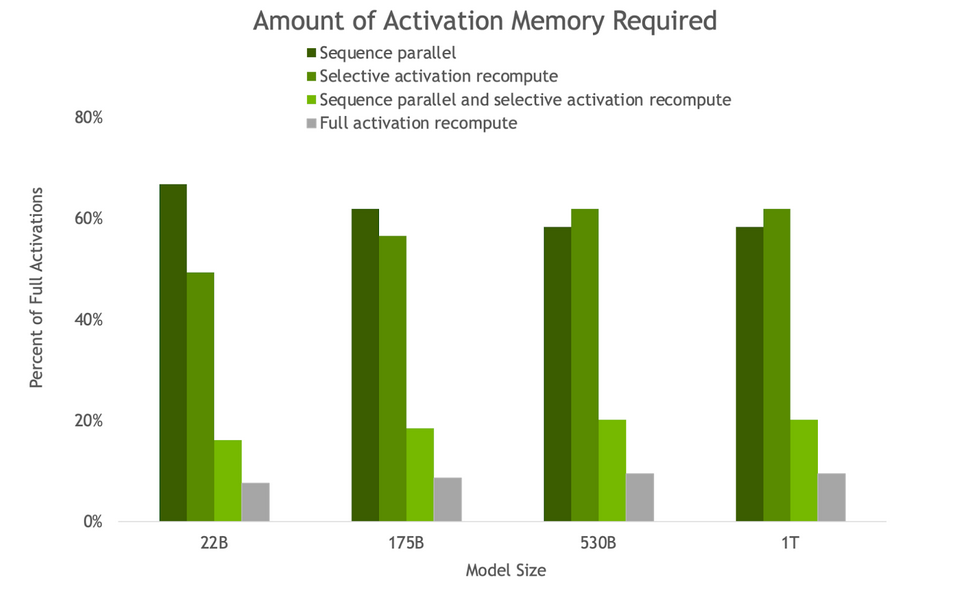
圖 3.由于 SP 和 SAR ,反向傳遞所需的激活內(nèi)存量。隨著模型尺寸的增加, SP 和 SAR 的內(nèi)存節(jié)省量相似,所需內(nèi)存減少了約 5 倍。
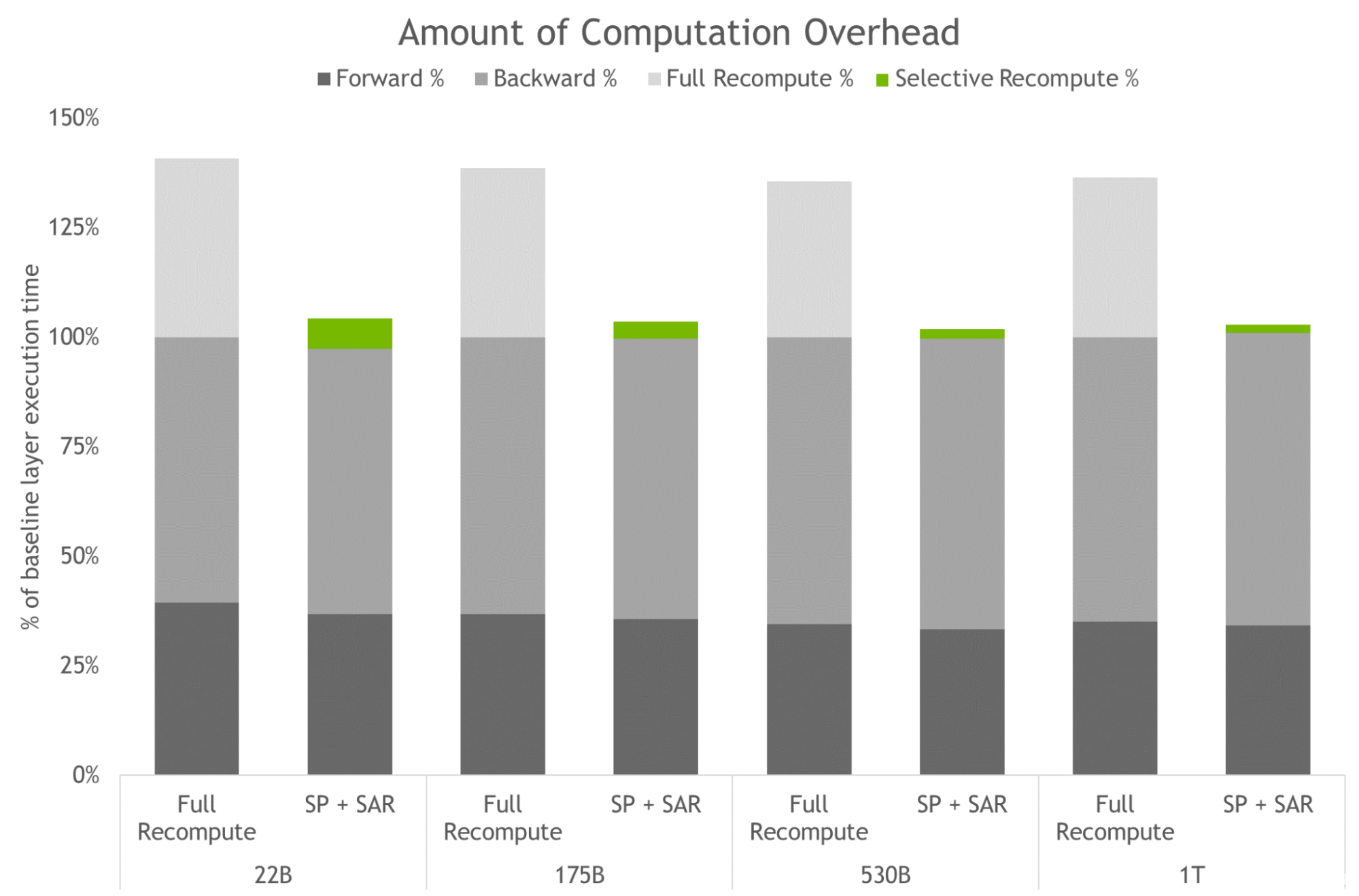
圖 4.完全激活重新計算和 SP 加 SAR 的計算開銷量。條形圖表示向前、向后和重新計算時間的每層分解。基線是指沒有重新計算和序列并行性的情況。這些技術(shù)可以有效地減少重新計算而不是保存所有激活時產(chǎn)生的開銷。對于最大型號,開銷從 36% 降至 2% 。
訪問 LLM 的功能還需要高度優(yōu)化的推理策略。用戶可以輕松地使用經(jīng)過訓練的模型進行推理,并使用 p- 調(diào)優(yōu)和即時調(diào)優(yōu)功能針對不同的用例進行優(yōu)化。
這些功能是微調(diào)的參數(shù)有效替代方案,并允許 LLM 適應新的用例,而無需對完全預訓練模型進行嚴格的微調(diào)。在這種技術(shù)中,原始模型的參數(shù)不會改變。因此,避免了與微調(diào)模型相關(guān)的災難性“遺忘”問題。
用于訓練和推理的新超參數(shù)工具
跨分布式基礎(chǔ)設(shè)施查找 LLM 的模型配置是一個耗時的過程。 NeMo Megatron 引入了一種超參數(shù)工具,可以自動找到最佳的訓練和推理配置,無需更改代碼。這使得 LLM 能夠從第一天開始訓練收斂以進行推理,從而消除了搜索有效模型配置所浪費的時間。
它跨不同參數(shù)使用啟發(fā)式和經(jīng)驗網(wǎng)格搜索,以找到具有最佳吞吐量的配置:數(shù)據(jù)并行性、張量并行性、管道并行性、序列并行性、微批量大小和激活檢查點層的數(shù)量(包括選擇性激活重新計算)。
使用超參數(shù)工具和 NVIDIA 對 NGC 上的容器進行測試,我們在 24 小時內(nèi)獲得了 175B GPT-3 模型的最佳訓練配置(見圖 5 )。與使用完全激活重新計算的常見配置相比,我們實現(xiàn)了 20%-30% 的吞吐量加速。使用最新技術(shù),對于參數(shù)超過 20B 的模型,我們實現(xiàn)了額外 10%-20% 的吞吐量加速。
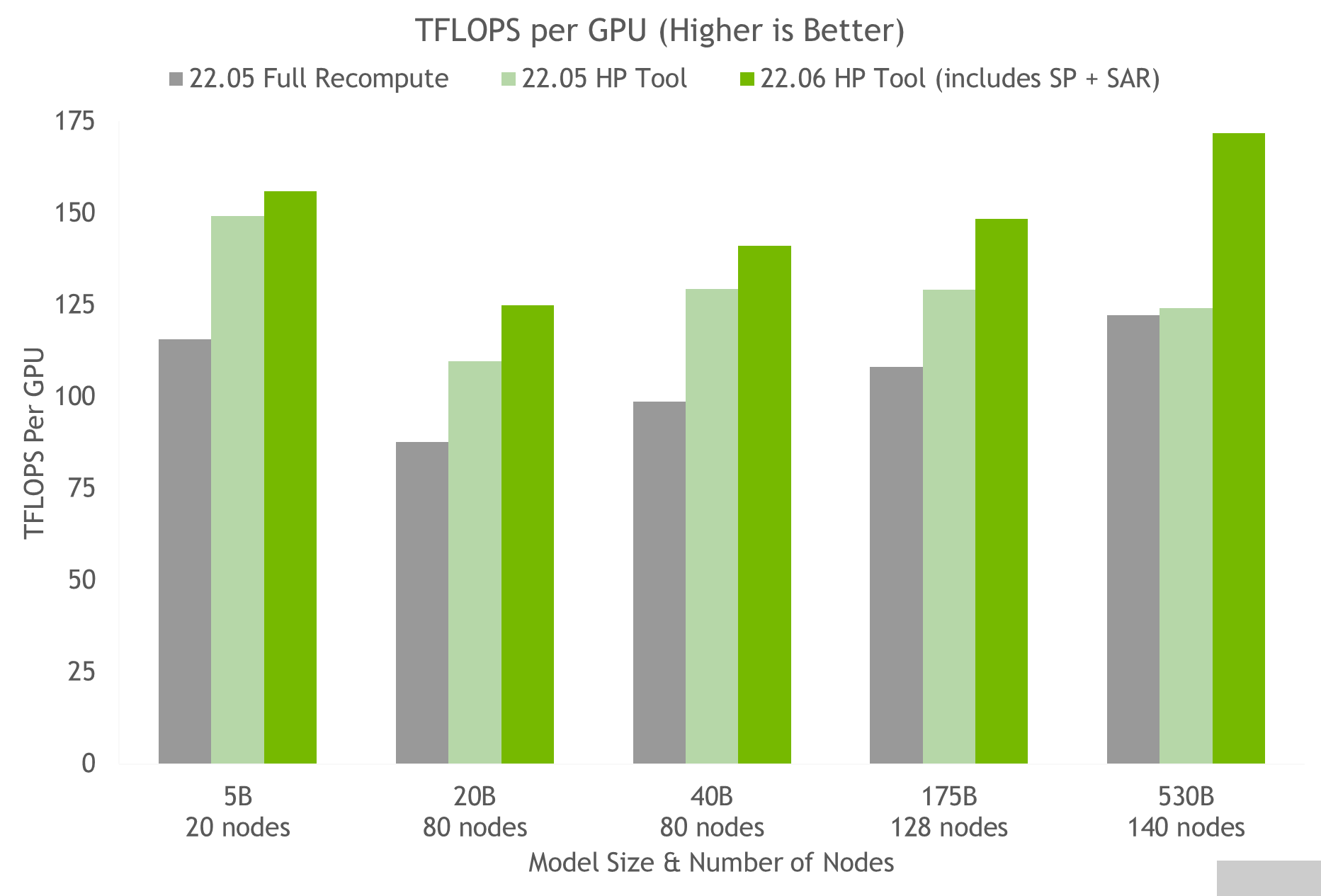
圖 5.HP 工具在多個容器上的結(jié)果,表明序列并行和選擇性激活重新計算的速度加快,其中每個節(jié)點是一個 NVIDIA DGX A100 。
hyperparameter 工具還允許查找在推理過程中實現(xiàn)最高吞吐量或最低延遲的模型配置。可以提供延遲和吞吐量約束來為模型服務,該工具將推薦合適的配置。
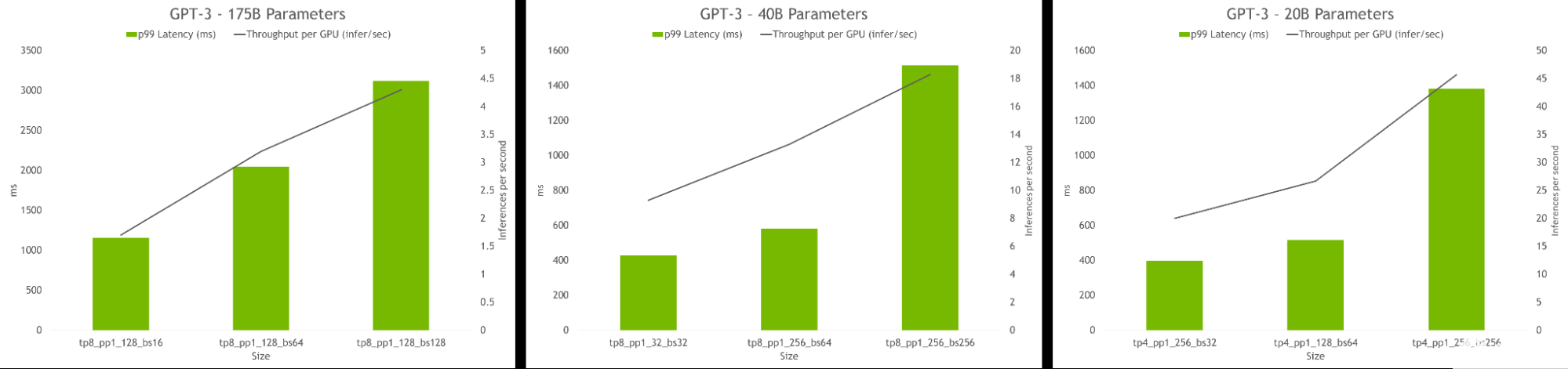
圖 6.HP 工具推斷結(jié)果,顯示了每 GPU 的吞吐量和不同配置的延遲。最佳配置包括高吞吐量和低延遲。
關(guān)于作者
Markel Ausin 是 NVIDIA 的深度學習算法工程師。在目前的角色中,他致力于構(gòu)建和部署大型語言模型,作為 NeMo- Megatron 框架的一部分。
Vinh Nguyen 是一位深度學習的工程師和數(shù)據(jù)科學家,發(fā)表了 50 多篇科學文章,引文超過 2500 篇。
Annamalai Chockalingam 是 NVIDIA 的 NeMo Megatron 和 NeMo NLP 產(chǎn)品的產(chǎn)品營銷經(jīng)理。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4940瀏覽量
102816 -
AI
+關(guān)注
關(guān)注
87文章
30146瀏覽量
268417 -
深度學習
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120977
發(fā)布評論請先 登錄
相關(guān)推薦
使用NVIDIA AI平臺確保醫(yī)療數(shù)據(jù)安全
賴耶科技通過NVIDIA AI Enterprise平臺打造超級AI工廠
如何利用大型語言模型驅(qū)動的搜索為公司創(chuàng)造價值

NVIDIA NIM助力企業(yè)高效部署生成式AI模型
NVIDIA NIM微服務帶來巨大優(yōu)勢
Mistral AI與NVIDIA推出全新語言模型Mistral NeMo 12B
NVIDIA AI Foundry 為全球企業(yè)打造自定義 Llama 3.1 生成式 AI 模型

基于CPU的大型語言模型推理實驗

LLM之外的性價比之選,小語言模型
【大語言模型:原理與工程實踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
NVIDIA 為部分大型亞馬遜 Titan 基礎(chǔ)模型提供訓練支持

NVIDIA 通過企業(yè)級生成式 AI 微服務為聊天機器人、AI 助手和摘要工具帶來商業(yè)智能
NVIDIA 通過企業(yè)級生成式 AI 微服務 為聊天機器人、AI 助手和摘要工具帶來商業(yè)智能






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論