 AI引擎內核編程設計進程
AI引擎內核編程設計進程
Versal AI Core 系列可借助 AI 引擎提供突破性的人工智能( AI )推斷加速。此系列應用范圍廣泛,包括用于云端動態工作負載以及超高帶寬網絡,同時還可提供高級安全性功能。AI 和數據科學家以及軟硬件開發者均可充分利用高計算密度的優勢來加速提升任何應用的性能。鑒于 AI 引擎所具備的高級信號處理計算能力,它十分適合用于高度優化的無線應用,例如射頻、5G、回程( backhaul )和其它高性能 DSP 應用。
本文檔聚焦 AI 引擎內核編程,除單內核編程外,還涵蓋了多方面的內容,如內核之間的數據通信,這些方面的內容都是將應用分區為多個內核以達成整體系統性能所必不可少的概念。本文檔涵蓋了以下設計進程:
? AI 引擎開發:創建 AI 引擎 Graph 及內核、庫用法、仿真調試與剖析以及算法開發。還包含 PL 與 AI 引擎內核的集成。
AI 引擎架構概述
AI 引擎陣列由二維 AI 引擎拼塊 (tile) 陣列構成,其中每個 AI 引擎拼塊均包含一個 AI 引擎、存儲器模塊和拼塊互連模 塊。AI 引擎拼塊二維陣列概覽如下圖所示。
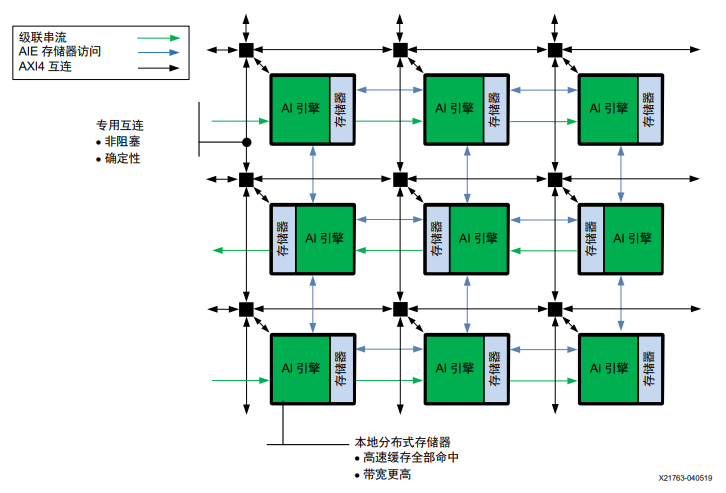
圖:AI引擎陣列
根據陣列中拼塊的位置,存儲器模塊在其東西南北四向的相鄰 AI 引擎之間共享。AI 引擎可訪問其東西南北各存儲器模塊及其自己本身的存儲器模塊。AI 引擎通過專用存儲器訪問接口來訪問這些相鄰存儲器模塊,并且每次訪問最大位寬為 256 位。AI 引擎與相鄰 AI 引擎之間還可發送或接收級聯串流數據。級聯串流是水平方向從左到右或從右到左的單向串流,它通過卷繞方式移至下一行。AXI4 互連模塊可提供 AI 引擎拼塊之間的串流連接,并在串流接口與存儲器模塊之間提供串流到存儲器 (S2MM) 或存儲器到串流 (MM2S) 連接。此外,互連模塊還可連接到相鄰互連模塊,以便以類似網格的方式提供靈活的布線功能。
下圖顯示了單個 AI 引擎拼塊的架構。
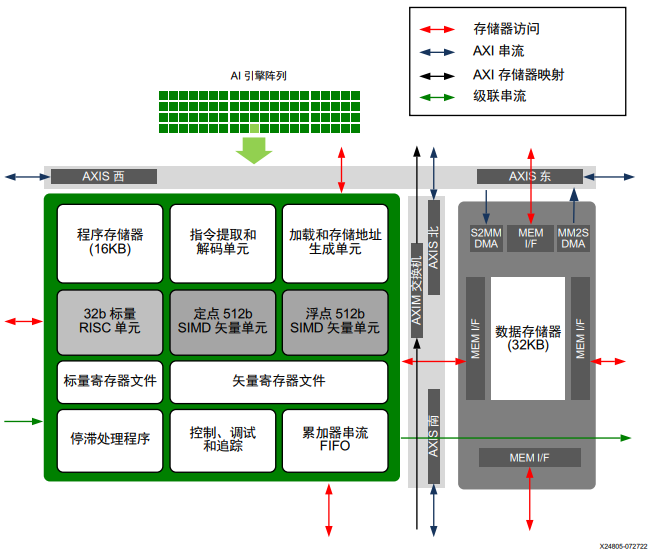
圖:AI引擎拼塊詳情信息
每個 AI 引擎拼塊都有一個 AXI4-Stream 交換機,它屬于完全可編程的 32 位 AXI4-Stream 交叉開關矩陣。它支持含有反壓的電路切換和包切換串流。通過 MM2S DMA 和 S2MM DMA,AXI4-Stream 交換機可提供往來 AI 引擎數據存儲器的串流訪問。此交換機還包含 2 個深度為 16 且位寬為 33 位(32 位數據 + 1 位 TLAST)的 FIFO,這兩個 FIFO 可鏈接在一起構成深度為 32 的 FIFO,方法是通過電路切換將其中一個 FIFO 的輸出鏈接到另一個 FIFO 的輸入。
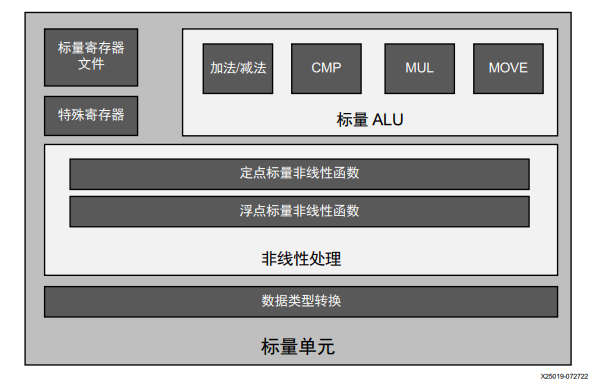
圖:標量處理單元
-
AI
+關注
關注
87文章
30172瀏覽量
268435 -
人工智能
+關注
關注
1791文章
46872瀏覽量
237600 -
編程設計
+關注
關注
0文章
9瀏覽量
6442
原文標題:AI 引擎內核編碼最佳實踐指南
文章出處:【微信號:賽靈思,微信公眾號:Xilinx賽靈思官微】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
單片機的ISP在線編程設計


對Linux的進程內核棧的認識
鴻蒙內核源碼:進程是內核的資源管理單元






 工商網監
工商網監
評論