 使用GPUNet在NVIDIA GPU上擊敗SOTA推理性能
使用GPUNet在NVIDIA GPU上擊敗SOTA推理性能
GPUNet 由 AI 為 AI 精心打造,是一類卷積神經網絡,旨在使用 NVIDIA TensorRT 最大化 NVIDIA GPU 的性能。
使用新的神經架構搜索( NAS )方法構建, GPUNet 展示了最先進的推理性能,比 EfficientNet-X 和 FBNet-V3 快兩倍。
NAS 方法有助于為廣泛的應用構建 GPUNet ,以便深度學習工程師可以根據相對精度和延遲目標直接部署這些神經網絡。
GPUNet NAS 設計方法
高效的體系結構搜索和部署就緒模型是 NAS 設計方法的關鍵目標。這意味著幾乎不與領域專家進行交互,并且有效地使用集群節點來培訓潛在的架構候選。最重要的是,生成的模型已準備好部署。
人工智能制作
為目標設備尋找性能最佳的架構搜索可能很耗時。 NVIDIA 構建并部署了一種新型的 NAS AI 代理,該代理可以有效地做出構建 GPUNET 所需的艱難設計選擇,使 GPUNET 比當前的 SOTA 模型領先 2 倍。
此 NAS AI 代理在中自動協調數百個 GPU Selene 超級計算機 而不需要領域專家的任何干預。
使用 TensorRT 為 NVIDIA GPU 優化
GPUNet 通過相關的 TensorRT 推理延遲成本,提升 GPU 友好的運算符(例如,較大的篩選器)而不是內存綁定運算符(例如花哨的激活)。它在 ImageNet 上提供了 SOTA GPU 延遲和精度。
部署就緒
GPUNet 報告的延遲包括 TensorRT 發貨版本中可用的所有性能優化,包括融合內核、量化和其他優化路徑。構建的 GPune 已準備好部署。
構建 GPune :端到端 NAS 工作流
在高層次上,神經架構搜索( NAS ) AI 代理分為兩個階段:
根據推理延遲對所有可能的網絡架構進行分類。
使用適合延遲預算的這些網絡的子集,并優化其準確性。
在第一階段,由于搜索空間是高維的,代理使用 Sobol 采樣來更均勻地分布候選。使用延遲查找表,然后將這些候選對象分類到子搜索空間,例如, NVIDIA V100 GPU 上總延遲低于 0.5 毫秒的網絡子集。
此階段中使用的推斷延遲是一個近似成本,通過將延遲查找表中每個層的延遲相加來計算。延遲表使用輸入數據形狀和層配置作為鍵來查找查詢層上的相關延遲。
在第二階段,代理建立貝葉斯優化損失函數,以在子空間的延遲范圍內找到性能最佳的高精度網絡:

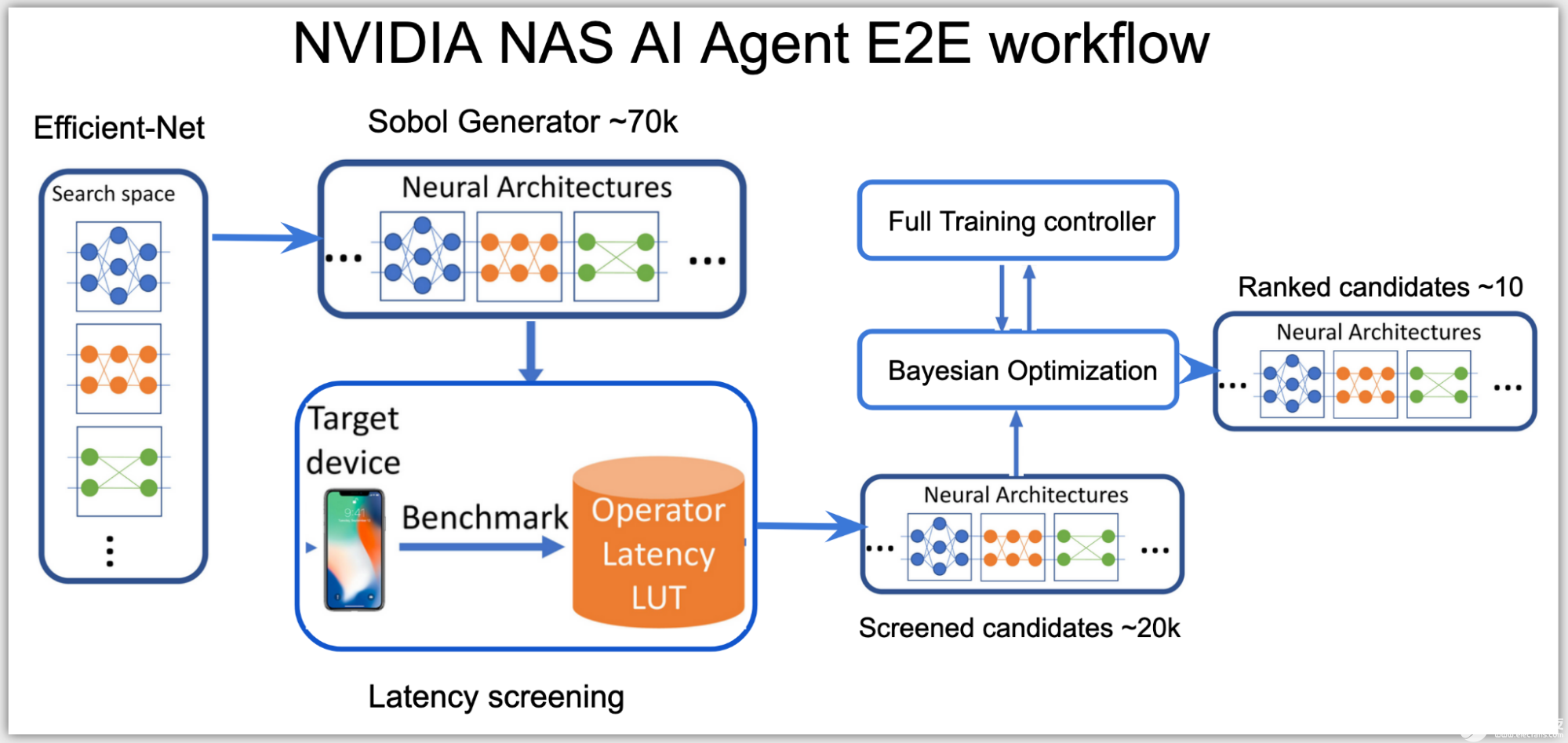
圖 2. NVIDIA NAS AI 代理端到端工作流
AI 代理使用客戶端 – 服務器分布式訓練控制器來跨多個網絡架構同時執行 NAS 。 AI 代理在一個服務器節點上運行,提出并訓練在集群上多個客戶端節點上運行的網絡候選。
根據結果,只有滿足目標硬件的準確度和延遲目標的有前途的網絡體系結構候選者得到排名,從而產生了一些性能最佳的 GPUNET ,可以使用 TensorRT 部署在 NVIDIA GPU 上。
GPUNet 模型體系結構
GPUNet 模型架構是一個八級架構,使用 EfficientNet-V2 作為基線架構。
搜索空間定義包括搜索以下變量:
操作類型
跨步數
內核大小
層數
激活函數
IRB 擴展比
輸出通道濾波器
擠壓激勵( SE )
表 1 顯示了搜索空間中每個變量的值范圍。
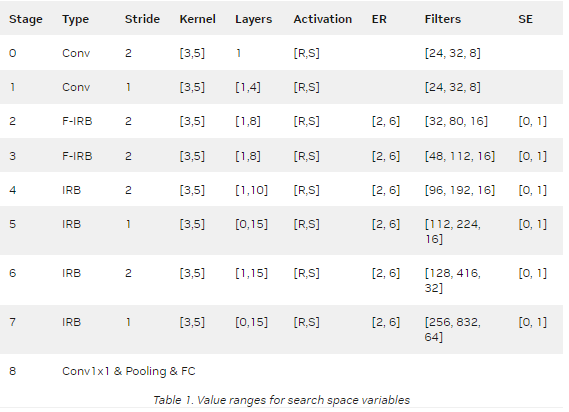
前兩個階段使用卷積搜索磁頭配置。受 EfficientNet-V2 的啟發,第二級和第三級使用融合 IRB 。然而,融合的 IRB 會導致更高的延遲,因此在第 4 至 7 階段,這些被 IRB 取代。
專欄層顯示階段中的層范圍。例如,階段 4 中的[1 , 10]表示該階段可以具有 1 到 10 個 IRB 。專欄過濾器顯示階段中各層的輸出通道濾波器范圍。該搜索空間還調整 IRB /融合 IRB 內部的擴展比( ER )、激活類型、內核大小和壓縮激勵( SE )層。
最后,在步驟 32 ,從 224 到 512 搜索輸入圖像的尺寸。
來自搜索空間的每個 GPUNet 候選構建被編碼為 41 寬的整數向量(表 2 )。
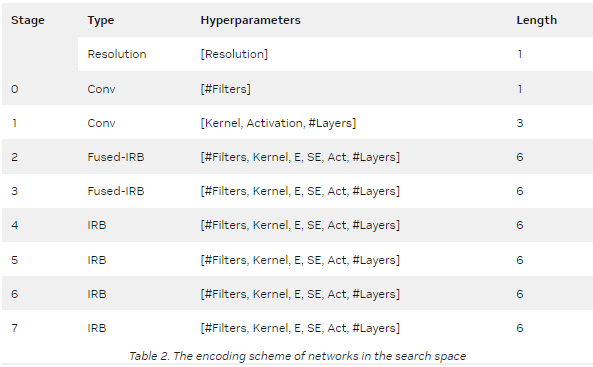
在 NAS 搜索結束時,返回的排序候選是這些性能最佳的編碼的列表,這些編碼又是性能最佳的 GPUNET 。
總結
鼓勵所有 ML 從業人員閱讀 CVPR 2022 GPUNet 研究報告 ,并在 NVIDIA /深度學習示例 GitHub repo ,并在 協作實例 在可用云上 GPU 。 GPUNet 推理也可在 PyTorch hub colab 運行實例使用 NGC 集線器上托管的 GPUNet 檢查點。這些檢查點具有不同的準確性和延遲折衷,可以根據目標應用程序的要求應用。
關于作者
Satish Salian 是 NVIDIA 的首席系統軟件工程師,為開發人員利用 NVIDIA GPU 的能力構建端到端技術和解決方案。他目前專注于神經架構搜索( NAS )方法,為 NVIDIA GPU 搜索高性能神經架構。
Carl (Izzy) Putterman 最近加入 NVIDIA ,擔任深度學習算法工程師。他畢業于加利福尼亞大學,伯克利在應用數學和計算機科學學士學位。在 NVIDIA ,他目前致力于時間序列建模和圖形神經網絡,重點是推理。
Linnan Wang 是 NVIDIA 的高級深度學習工程師。 2021 ,他在布朗大學獲得博士學位。他的研究主題是神經架構搜索,他的 NAS 相關著作已在 ICML 、 NeurIPS 、 ICLR 、 CVPR 、 TPMAI 和 AAAI 上發表。在 NVIDIA , Lin Nan 繼續進行 NAS 的研發,并將 NAS 優化模型交付給 NVIDIA 核心產品。
審核編輯:郭婷
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100568 -
NVIDIA
+關注
關注
14文章
4949瀏覽量
102828 -
gpu
+關注
關注
28文章
4703瀏覽量
128729
發布評論請先 登錄
相關推薦
英特爾FPGA 助力Microsoft Azure機器學習提供AI推理性能
NVIDIA擴大AI推理性能領先優勢,首次在Arm服務器上取得佳績

NVIDIA打破AI推理性能記錄
NVIDIA 在首個AI推理基準測試中大放異彩
在Ubuntu上使用Nvidia GPU訓練模型
充分利用Arm NN進行GPU推理
求助,為什么將不同的權重應用于模型會影響推理性能?
如何提高YOLOv4模型的推理性能?
利用NVIDIA模型分析儀最大限度地提高深度學習的推理性能
NVIDIA A100 GPU推理性能237倍碾壓CPU
NVIDIA GPU助力提升模型訓練和推理性價比
NVIDIA Triton推理服務器的基本特性及應用案例
在 NGC 上玩轉新一代推理部署工具 FastDeploy,幾行代碼搞定 AI 部署
Nvidia 通過開源庫提升 LLM 推理性能
開箱即用,AISBench測試展示英特爾至強處理器的卓越推理性能






 工商網監
工商網監
評論