") 解決自動語音識別部署難題
解決自動語音識別部署難題
成功部署自動語音識別( ASR )應(yīng)用程序可能是令人沮喪的體驗。例如,考慮到存在許多不同的方言和發(fā)音, ASR 系統(tǒng)很難在保持低延遲的同時正確識別單詞。
無論您使用的是商業(yè)解決方案還是開源解決方案,在構(gòu)建 ASR 應(yīng)用程序時都有許多挑戰(zhàn)需要考慮。
在這篇文章中,我強(qiáng)調(diào)了開發(fā)人員在向應(yīng)用程序添加 ASR 功能時面臨的主要痛點。我以 NVIDIA Riva 語音 AI SDK 為例,分享如何應(yīng)對和克服這些挑戰(zhàn)。
構(gòu)建 ASR 應(yīng)用程序的挑戰(zhàn)
以下是創(chuàng)建任何 ASR 系統(tǒng)時存在的一些挑戰(zhàn):
低延遲
計算資源分配
靈活的部署和可擴(kuò)展性
定制
監(jiān)測和跟蹤
高精度
衡量語音識別準(zhǔn)確性的一個關(guān)鍵指標(biāo)是單詞錯誤率( WER )。 WER 定義為轉(zhuǎn)錄過程中識別的不正確和缺失單詞總數(shù)與標(biāo)記轉(zhuǎn)錄本中出現(xiàn)的單詞總數(shù)之比。
有幾個原因?qū)е?ASR 模型中的轉(zhuǎn)錄錯誤,導(dǎo)致信息的誤解:
訓(xùn)練數(shù)據(jù)集的質(zhì)量
不同的方言和發(fā)音
口音和語音變化
自定義或特定領(lǐng)域的詞和首字母縮略詞
詞的語境關(guān)系
區(qū)分語音相似的句子
由于這些因素,很難建立具有低 WER 分?jǐn)?shù)的穩(wěn)健 ASR 模型。
低延遲
一個對話人工智能 應(yīng)用程序是由語音人工智能和自然語言處理( NLP )組成的端到端管道。
對于任何對話式人工智能應(yīng)用程序,響應(yīng)時間都是進(jìn)行任何自然對話的關(guān)鍵因素。如果客戶在等待 1 分鐘后才收到響應(yīng),則與機(jī)器人對話是不實際的。
據(jù)觀察,任何對話 AI 應(yīng)用程序都應(yīng): 提供小于 300 毫秒的延遲 因此,確保語音 AI 模型等待時間遠(yuǎn)低于 300 毫秒限制,以集成到實時會話 AI 應(yīng)用的端到端流水線中變得至關(guān)重要。
許多因素影響 ASR 模型的總體延遲:
Model size: 大型和復(fù)雜的模型具有更好的精度,但與較小的模型相比,需要大量的計算能力并增加延遲;即推斷成本高。
Hardware: 這種復(fù)雜模型的邊緣部署進(jìn)一步增加了延遲要求的復(fù)雜性。
Network bandwidth: 流式傳輸音頻內(nèi)容和轉(zhuǎn)錄本需要足夠的帶寬,尤其是在基于云的部署情況下。
計算資源分配
優(yōu)化 ASR 模型及其資源利用適用于所有人工智能模型,而不僅僅是 ASR 模型。然而,這是影響運(yùn)行任何人工智能應(yīng)用程序的總體延遲和計算成本的關(guān)鍵因素。
優(yōu)化模型的全部目的是在計算級別和延遲級別降低推理成本。但是,對于特定架構(gòu),在線可用的所有模型都不是平等創(chuàng)建的,并且不具有相同的代碼質(zhì)量。他們在表現(xiàn)上也有巨大的差異。
此外,并非所有這些方法都以相同的方式響應(yīng)知識提取、修剪、量化和其他優(yōu)化技術(shù),從而在不影響精度結(jié)果的情況下提高推理性能。
靈活的部署和可擴(kuò)展性
創(chuàng)建準(zhǔn)確高效的模型只是任何實時人工智能應(yīng)用程序的一小部分。所需的周邊基礎(chǔ)設(shè)施龐大而復(fù)雜。例如,部署基礎(chǔ)設(shè)施應(yīng)包括:
流式支持
資源管理處
服務(wù)基礎(chǔ)設(shè)施
分析工具支持
監(jiān)測服務(wù)
創(chuàng)建一個定制的端到端優(yōu)化部署管道,以支持任何 ASR 應(yīng)用程序所需的延遲要求,這是一個挑戰(zhàn),因為它需要在每個管道階段進(jìn)行優(yōu)化和加速。
根據(jù)給定實例必須支持的音頻流的數(shù)量,語音識別應(yīng)用程序應(yīng)該能夠自動擴(kuò)展應(yīng)用程序部署,以提供可接受的性能。
定制
讓模型開箱即用始終是我們的目標(biāo)。然而,當(dāng)前可用模型的性能取決于其訓(xùn)練階段使用的數(shù)據(jù)集。模型通常適用于它們已經(jīng)暴露的用例,但一旦在不同的域應(yīng)用程序中部署,同一模型的性能可能會下降。
具體來說,在 ASR 的情況下,模型的性能取決于口音或語言以及語音變化。您應(yīng)該能夠根據(jù)應(yīng)用程序用例定制模型。
例如,在醫(yī)療保健或金融相關(guān)應(yīng)用中部署的語音識別模型需要支持特定領(lǐng)域的詞匯表。該詞匯與 ASR 模型培訓(xùn)期間通常使用的詞匯不同。
為了支持 ASR 的區(qū)域語言,您需要一套完整的培訓(xùn)管道,以便輕松定制模型并有效地處理不同的方言。
監(jiān)測和跟蹤
實時監(jiān)控和跟蹤有助于獲得即時洞察、警報和通知,以便您及時采取糾正措施。這有助于根據(jù)傳入流量跟蹤資源消耗,從而可以自動縮放相應(yīng)的應(yīng)用程序。還可以設(shè)置配額限制,以在不影響總體吞吐量的情況下最小化基礎(chǔ)設(shè)施成本。
捕獲所有這些統(tǒng)計數(shù)據(jù)需要集成多個庫,以捕獲 ASR 管道各個階段的性能。
Riva SDK 如何應(yīng)對 ASR 挑戰(zhàn)的示例
高級 SDK 可用于方便地為應(yīng)用程序添加語音接口。在這篇文章中,我演示了如何在構(gòu)建語音識別應(yīng)用程序時使用 GPU 加速 SDK (如 Riva )來解決這些挑戰(zhàn)。
高精度和計算優(yōu)化
您可以在 NGC 中使用預(yù)訓(xùn)練的 Riva 語音模型,該模型可以使用 TAO 工具包在自定義數(shù)據(jù)集上進(jìn)行微調(diào),從而將特定領(lǐng)域的模型開發(fā)進(jìn)一步加速 10 倍。
為 GPU 部署優(yōu)化并加速了所有 NGC 模型,以實現(xiàn)更好的識別精度。 NVIDIA TensorRT 優(yōu)化也完全支持這些模型。 Riva 的高性能推理由 TensorRT 優(yōu)化提供支持,并使用 NVIDIA Triton 推理服務(wù)器來優(yōu)化整體計算需求,進(jìn)而提高服務(wù)器吞吐量
例如,以下是一些 NGC 上的 ASR 模型,它們作為 Riva 管道的一部分進(jìn)一步優(yōu)化,以獲得更好的性能:
Conformer-CTC xLarge
Citrinet 512
從模型、軟件到硬件, Riva 的整個堆棧不斷優(yōu)化,實現(xiàn)了以下目標(biāo): 12 與上一代相比的增益 。
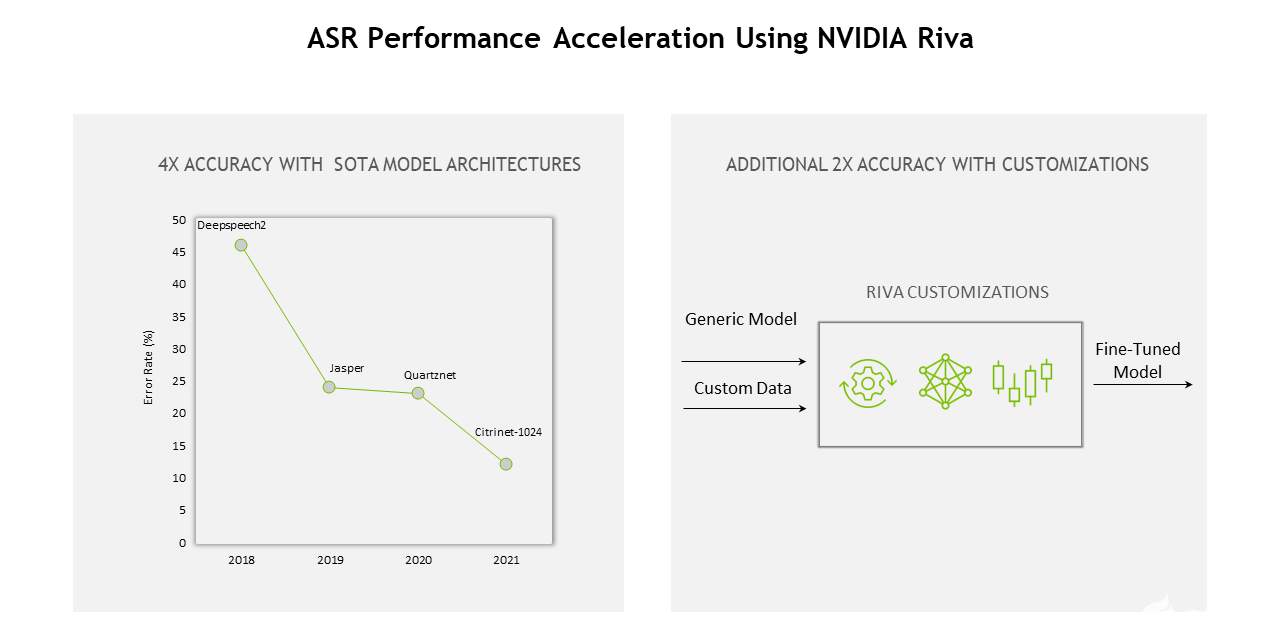
圖 1.使用 NVIDIA Riva 的 ASR 性能加速
低延遲
流式和離線配置的延遲和吞吐量測量報告在 ASR 性能 Riva 文件部分。
在“流式低延遲” Riva ASR 模型部署模式中,大多數(shù)情況下的平均延遲( ms )遠(yuǎn)小于 50 ms 。使用這樣的 ASR 模型,創(chuàng)建實時會話 AI 管道變得更容易,并且仍然達(dá)到《 300 毫秒的延遲要求。
靈活的部署和擴(kuò)展
在任何平臺上輕松部署語音識別應(yīng)用程序都需要全面支持。 Riva SDK 在每一步都提供了靈活性,從對特定領(lǐng)域數(shù)據(jù)集的模型進(jìn)行微調(diào)到定制管道。它還可以部署在云、本地、邊緣和嵌入式設(shè)備中。
為了支持?jǐn)U展, Riva 是完全容器化的,可以擴(kuò)展到成百上千個并行流。 Riva 也包含在 NGC Helm 倉庫 ,這是一個設(shè)計用于自動按下按鈕的圖表 部署到 Kubernetes 集群 。
定制
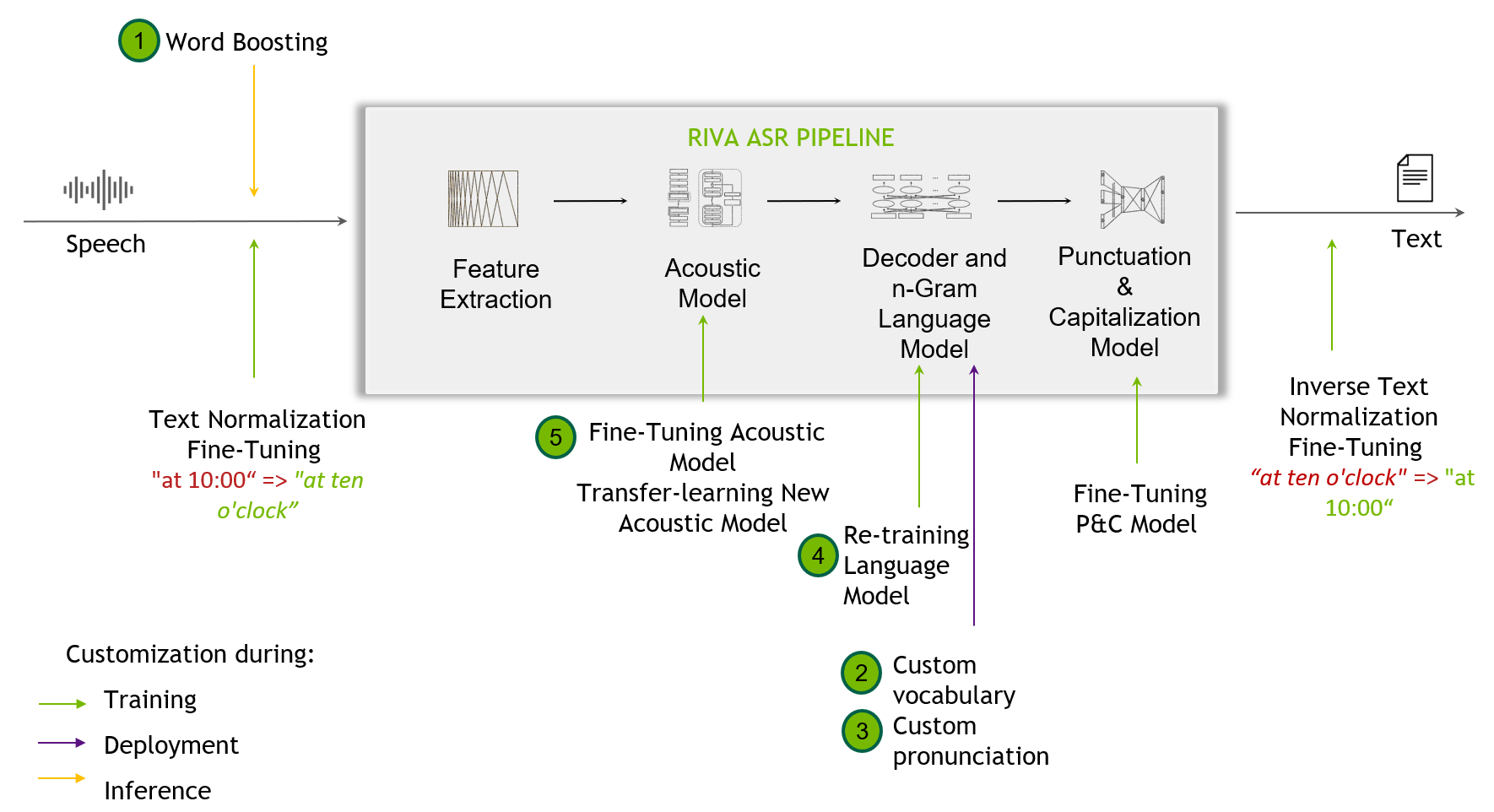
Figure 2. 定制技術(shù)包括從單詞提升到微調(diào)標(biāo)點和大寫模型
定制技術(shù) 當(dāng)開箱即用 Riva 模型無法處理訓(xùn)練數(shù)據(jù)中未出現(xiàn)的挑戰(zhàn)性場景時,這是有用的。這可能包括識別窄域術(shù)語、新口音或嘈雜環(huán)境。
類似 Riva 的 SDK 支持 定制 ,從單詞增強(qiáng)級別開始,并為最終用戶提供定制訓(xùn)練其聲學(xué)模型。
Riva 語音技能還提供了跨多種語言的高質(zhì)量、預(yù)訓(xùn)練模型。有關(guān)支持的語言的所有模型的更多信息,請參閱 語言支持 部分。
監(jiān)測和跟蹤
在 Riva,基礎(chǔ) Triton 推理服務(wù)器度量 基于自定義和儀表板創(chuàng)建,可供最終用戶使用。這些指標(biāo)僅通過訪問端點可用。
NVIDIA Triton 提供普羅米修斯指標(biāo),以及指示 GPU 和請求統(tǒng)計。這有助于監(jiān)控和跟蹤生產(chǎn)部署設(shè)置。
關(guān)鍵要點
這篇文章為您提供了開發(fā)具有 ASR 功能的 AI 應(yīng)用程序時出現(xiàn)的常見痛點的高級概述。了解影響 ASR 應(yīng)用程序整體性能的因素有助于簡化和改進(jìn)端到端開發(fā)過程。
Sunil Kumar Jang Bahadur 是 NVIDIA Inception 團(tuán)隊的高級解決方案架構(gòu)師,專注于印度的人工智能初創(chuàng)企業(yè)。他在各種工業(yè)部門的軟件開發(fā)和技術(shù)解決方案方面擁有 12 年以上的經(jīng)驗。他喜歡教機(jī)器,讓它們更人性化。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4935瀏覽量
102811 -
語音識別
+關(guān)注
關(guān)注
38文章
1721瀏覽量
112541
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論