") 結(jié)合卷積和注意機制改進(jìn)日語ASR
結(jié)合卷積和注意機制改進(jìn)日語ASR
自動語音識別( ASR )研究通常側(cè)重于高資源語言,如英語,它由數(shù)十萬小時的語音支持。最近的文獻(xiàn)重新關(guān)注更復(fù)雜的語言,如日語。與其他亞洲語言一樣,日語有大量的基本字符集(普通白話中使用了 3000 多個獨特的字符),并提出了獨特的挑戰(zhàn),例如多個詞序。
這篇文章討論了最近提高日語 ASR 準(zhǔn)確性和速度的工作。首先,我們改進(jìn)了 Conformer ,這是一種最先進(jìn)的 ASR 神經(jīng)網(wǎng)絡(luò)架構(gòu),在訓(xùn)練和推理速度方面取得了顯著的改進(jìn),并且沒有精度損失。其次,我們增強了一個具有多頭部自我注意機制的純深度卷積網(wǎng)絡(luò),以豐富輸入語音波形的全局上下文表示的學(xué)習(xí)。
語音識別中的深度稀疏整合器
Conformer 是一種神經(jīng)網(wǎng)絡(luò)體系結(jié)構(gòu),廣泛應(yīng)用于多種語言的 ASR 系統(tǒng)中,并取得了較高的精度。然而, Conformer 在訓(xùn)練和推斷方面都相對較慢,因為它使用了多頭自我注意,對于輸入音頻波的長度,其時間/內(nèi)存復(fù)雜度為 quadratic 。
這妨礙了它對長音頻序列的高效處理,因為在訓(xùn)練和推斷過程中需要相對較高的內(nèi)存占用。這些激勵了稀疏 關(guān)注高效 Conformer 構(gòu)建。此外,由于注意力較少,內(nèi)存成本相對較低,我們能夠構(gòu)建一個更深的網(wǎng)絡(luò),可以處理由大規(guī)模語音數(shù)據(jù)集提供的長序列。
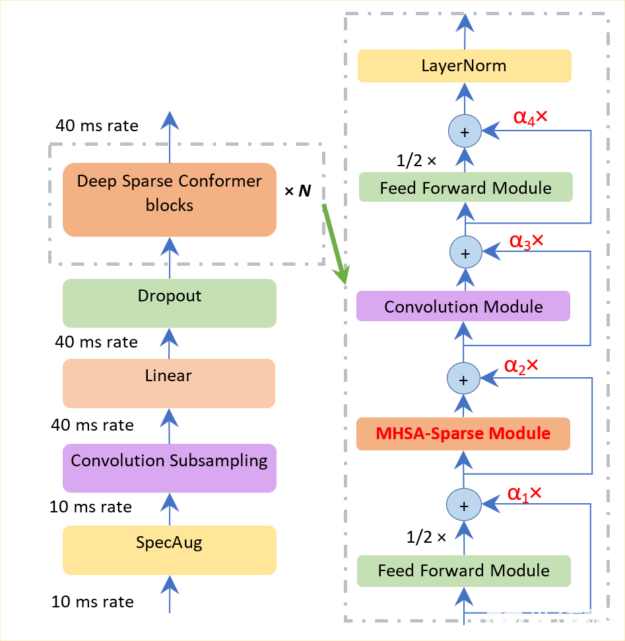
圖 1.深度稀疏 Conformer 的編碼器模型架構(gòu)
如圖 1 所示,我們在兩個方向上改進(jìn)了 Conformer 長序列表示能力:稀疏和深入。我們使用一個排名標(biāo)準(zhǔn),只選擇一小部分占主導(dǎo)地位的查詢,而不是整個查詢集,以節(jié)省計算注意力得分的時間。
在執(zhí)行剩余連接時,使用深度規(guī)范化策略,以確保百級 Conformer 塊的訓(xùn)練。該策略包括使用一個函數(shù)來貼現(xiàn)編碼器和解碼器部分的參數(shù),該函數(shù)分別與編碼器層和解碼器層的數(shù)量相關(guān)。
此外,這種深度規(guī)范化策略可確保成功構(gòu)建 10 到 100 層,從而使模型更具表現(xiàn)力。相比之下,與普通 Conformer 相比,深度稀疏 Conformer 的時間和內(nèi)存成本降低了 10% 到 20% 。
用于語音識別的注意力增強型 Citrinet
NVIDIA 研究人員提出的 Citrinet 是一種基于端到端卷積連接時態(tài)分類( CTC )的 ASR 模型。為了捕獲本地和全局上下文信息, Citrinet 使用 1D 時間通道可分離卷積與子字編碼、壓縮和激勵( SE )相結(jié)合,使整個體系結(jié)構(gòu)與基于變壓器的同類產(chǎn)品相比達(dá)到最先進(jìn)的精度。
將 Citrinet 應(yīng)用于日本 ASR 涉及幾個挑戰(zhàn)。具體來說,與類似的深度神經(jīng)網(wǎng)絡(luò)模型相比,它的收斂速度相對較慢,并且更難訓(xùn)練出具有類似精度的模型。考慮到影響 Citrinet 收斂速度的卷積層多達(dá) 235 個,我們旨在通過在 Citrinet 塊的卷積模塊中引入多頭部注意來減少 CNN 層,同時保持 SE 和剩余模塊不變。
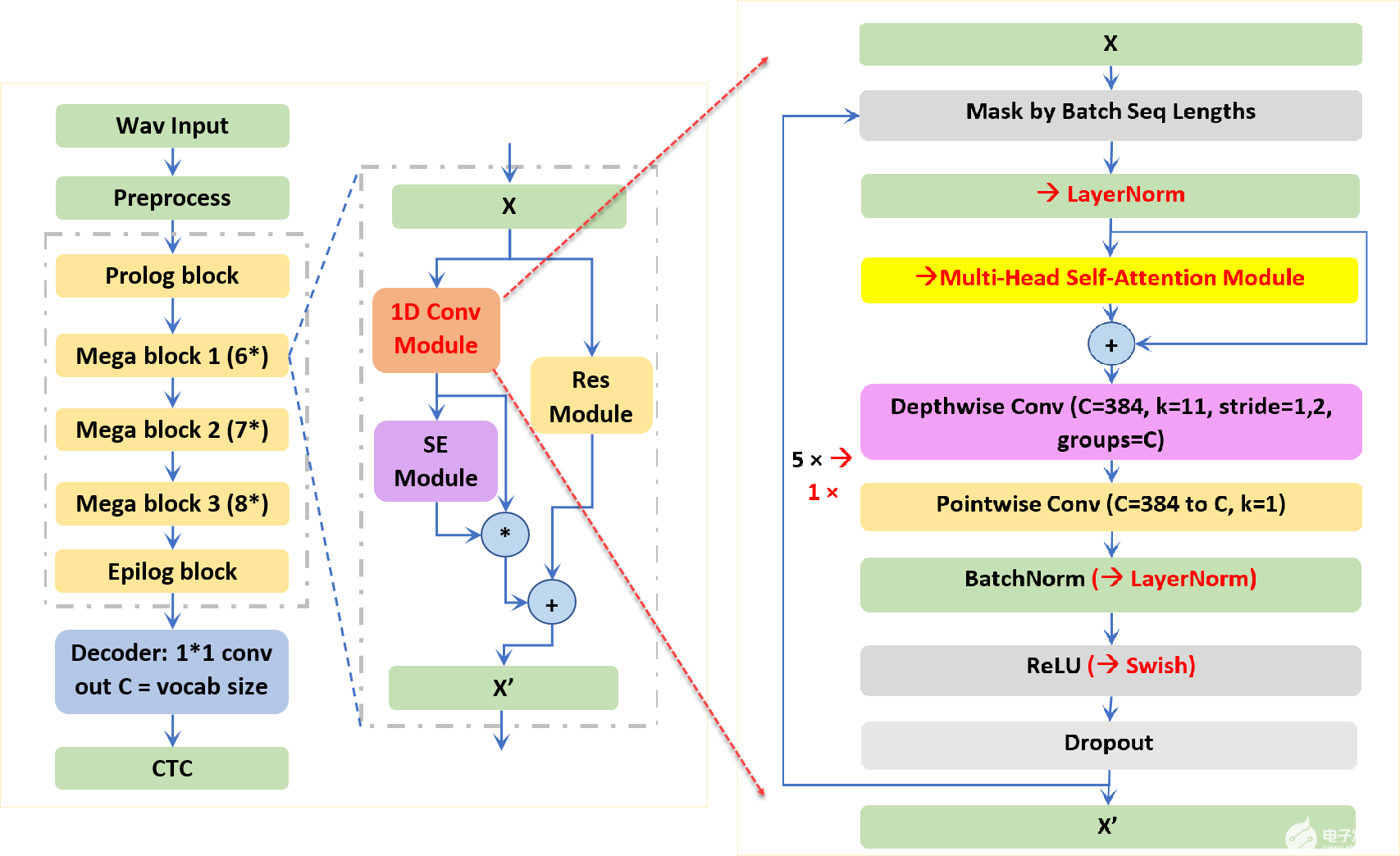
圖 2.Citrinet 端到端架構(gòu)和主要構(gòu)建塊
如圖 2 所示,加快訓(xùn)練時間需要在每個注意力增強的 Citrinet 塊中減少八個卷積層。此外,考慮到自我注意對輸入音頻波的長度具有二次 的時間/記憶復(fù)雜性,我們將原來的 23 個 Jasper 塊縮減為 8 個塊,模型尺寸顯著減小。這種設(shè)計確保了注意力增強的 Citrinet 對于從 20 秒到 100 秒的長語音序列達(dá)到了可比的推理時間。
初步實驗表明,基于注意力的模型收斂于 100 到 200 個時間點,而 Citrinet 收斂到最佳錯誤率需要 500 到 1000 個時間點。在日本 CSJ-500-hour 數(shù)據(jù)集上的實驗表明,與 Citrinet ( 80% 的訓(xùn)練時間)和 Conformer ( 40% 的訓(xùn)練時間和 18.5% 的模型大小)相比, Citrinet 的注意力需要更少的塊層,收斂速度更快,字符錯誤率更低。
總結(jié)
通常,我們提出兩種新的架構(gòu)來構(gòu)建端到端的日本 ASR 模型。在一個方向上,我們改進(jìn)了基于變壓器的 Conformer 訓(xùn)練和推斷速度,并保持了其準(zhǔn)確性。我們成功地構(gòu)建了更稀疏和更深入的 Conformer 模型。我們還通過引入多頭部自我注意機制和修剪 80% 的 CNN 層,提高了基于 CNN 的 Citrinet 收斂速度和準(zhǔn)確性。這些建議是通用的,適用于其他亞洲語言。
關(guān)于作者
吳顯超博士是 NVIDIA 的高級解決方案架構(gòu)師。他專注于語音處理和自然語言處理的研究領(lǐng)域。他支持客戶在 NVIDIA SDK (如威震天 LM 、 NeMo 和 Riva )下構(gòu)建大規(guī)模預(yù)處理模型和對話人工智能平臺。
Somshubra Majumdar 是 NVIDIA NeMo 工具包的資深研究科學(xué)家。他于 2016 年獲得孟買大學(xué)計算機工程學(xué)士學(xué)位, 2018 年獲得芝加哥伊利諾伊大學(xué)計算機科學(xué)碩士學(xué)位。他的研究興趣包括自動語音識別、語音分類、時間序列分類和深度學(xué)習(xí)的實際應(yīng)用。
審核編輯:郭婷
-
編碼器
+關(guān)注
關(guān)注
45文章
3601瀏覽量
134205 -
語音識別
+關(guān)注
關(guān)注
38文章
1725瀏覽量
112567 -
ASR
+關(guān)注
關(guān)注
2文章
42瀏覽量
18701
發(fā)布評論請先 登錄
相關(guān)推薦
卷積神經(jīng)網(wǎng)絡(luò)模型發(fā)展及應(yīng)用
μC/OS-II 任務(wù)調(diào)度機制的改進(jìn)
Snort匹配機制的改進(jìn)
維納濾波反卷積算法的改進(jìn)
卷積神經(jīng)網(wǎng)絡(luò)的權(quán)值反向傳播機制和MATLAB的實現(xiàn)方法
結(jié)合改進(jìn)Fisher判別準(zhǔn)則與GRV模塊的卷積神經(jīng)網(wǎng)絡(luò)

基于通道注意力機制的SSD目標(biāo)檢測算法
結(jié)合注意力機制的改進(jìn)深度學(xué)習(xí)光流網(wǎng)絡(luò)

基于循環(huán)卷積注意力模型的文本情感分類方法
結(jié)合注意力機制的跨域服裝檢索方法
改進(jìn)膠囊網(wǎng)絡(luò)優(yōu)化分成卷積的亞健康識別
計算機視覺中的注意力機制

一種基于因果路徑的層次圖卷積注意力網(wǎng)絡(luò)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論