") 使用語音AI開發(fā)下一代擴(kuò)展現(xiàn)實(shí)應(yīng)用程序
使用語音AI開發(fā)下一代擴(kuò)展現(xiàn)實(shí)應(yīng)用程序
由于身臨其境的體驗(yàn),虛擬現(xiàn)實(shí)( VR )、增強(qiáng)現(xiàn)實(shí)( AR )和混合現(xiàn)實(shí)( MR )環(huán)境可以感覺到難以置信的真實(shí)。在擴(kuò)展現(xiàn)實(shí)( XR )應(yīng)用程序中添加基于語音的界面可以使其看起來更真實(shí)。
想象一下,用你的聲音在一個(gè)環(huán)境中導(dǎo)航,或者發(fā)出口頭命令,然后聽到虛擬實(shí)體的回應(yīng)。
在 XR 環(huán)境中利用 speech AI 的可能性非常誘人。語音人工智能技能,如自動(dòng)語音識別( ASR )和文本到語音轉(zhuǎn)換( TTS ),使 XR 應(yīng)用程序變得有趣、易于使用,并使有語音障礙的用戶更容易使用。
本文介紹了如何在 XR 應(yīng)用程序中使用語音識別,也稱為語音到文本( STT ),有哪些 ASR 自定義,以及如何開始在 Windows 應(yīng)用程序中運(yùn)行 ASR 服務(wù)。
為什么要在 XR 應(yīng)用程序中添加語音 AI 服務(wù)?
在當(dāng)今大多數(shù) XR 體驗(yàn)中,用戶無法使用鍵盤或鼠標(biāo)。 VR 游戲控制器通常與虛擬體驗(yàn)交互的方式既笨拙又不直觀,當(dāng)您沉浸在環(huán)境中時(shí),很難通過菜單進(jìn)行導(dǎo)航。
當(dāng)我們沉浸在虛擬世界中時(shí),我們希望我們的體驗(yàn)感覺自然,無論是我們?nèi)绾胃兄€是我們?nèi)绾闻c它互動(dòng)。言語是我們在現(xiàn)實(shí)世界中最常見的交流方式之一。
在 XR 應(yīng)用程序中添加支持語音 AI 的語音命令和響應(yīng),使交互更加自然,并大大簡化了用戶的學(xué)習(xí)曲線。
支持語音 AI 的 XR 應(yīng)用程序示例
如今,有各種各樣的可穿戴技術(shù)設(shè)備,使人們能夠在使用聲音的同時(shí)體驗(yàn)身臨其境的現(xiàn)實(shí):
AR 翻譯眼鏡可以在 AR 中提供實(shí)時(shí)翻譯,或者只在 AR 中轉(zhuǎn)錄語音,以幫助有聽力障礙的人。
品牌化語音是為元宇宙中的數(shù)字化身定制和開發(fā)的,使體驗(yàn)更加可信和真實(shí)。
社交媒體平臺提供語音激活 AR 過濾器,便于搜索和使用。例如, Snapchat 用戶可以使用免提語音掃描功能搜索所需的數(shù)字濾波器。
VR 設(shè)計(jì)審查
虛擬現(xiàn)實(shí)可以幫助企業(yè)通過自動(dòng)化汽車行業(yè)的許多任務(wù)來節(jié)省成本,例如汽車建模、裝配工人培訓(xùn)和駕駛模擬。
添加的語音 AI 組件使免提交互成為可能。例如,用戶可以利用 STT 技能向 VR 應(yīng)用程序發(fā)出命令,應(yīng)用程序可以通過 TTS 以聽起來很人性化的方式響應(yīng)。
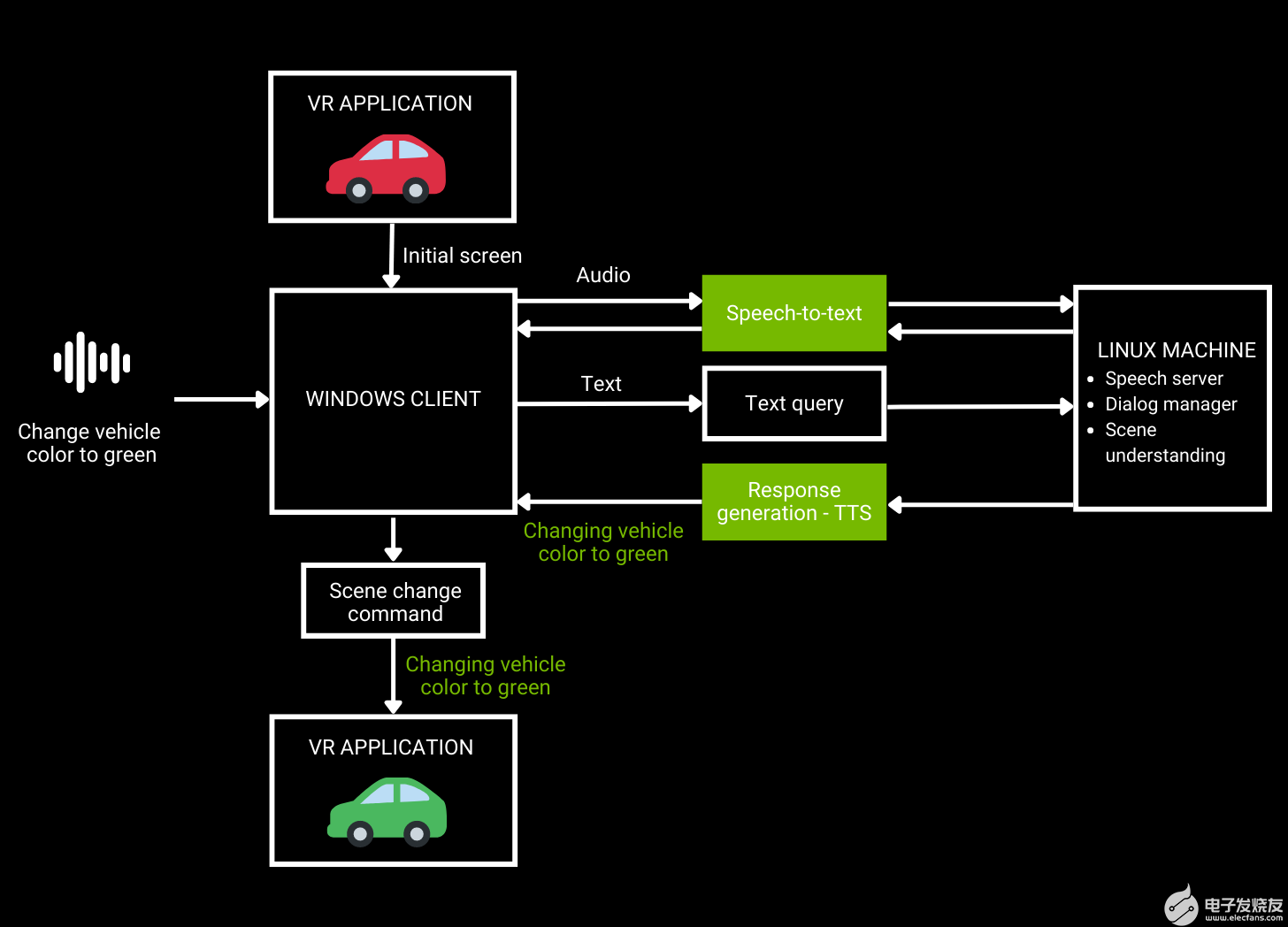
圖 1.VR 汽車設(shè)計(jì)審查工作流架構(gòu)
如圖 1 所示,用戶向 VR 應(yīng)用程序發(fā)送音頻請求,然后使用 ASR 將其轉(zhuǎn)換為文本。自然語言理解將文本作為輸入并生成響應(yīng),然后使用 TTS 將其反饋給用戶。
開發(fā)語音 AI 管道并不像聽起來那么容易。傳統(tǒng)上,在構(gòu)建管道時(shí),總是要在準(zhǔn)確性和實(shí)時(shí)響應(yīng)之間進(jìn)行權(quán)衡。
這篇文章只關(guān)注 ASR ,我們研究了目前 XR 應(yīng)用程序開發(fā)人員可用的一些定制。我們還討論了使用 GPU 加速語音 AI SDK NVIDIA Riva 構(gòu)建針對特定用例定制的應(yīng)用程序,同時(shí)提供實(shí)時(shí)性能。
通過 ASR 定制解決特定領(lǐng)域和語言的挑戰(zhàn)
一個(gè) ASR 管道包括一個(gè)特征抽取器、聲學(xué)模型、解碼器或語言模型以及標(biāo)點(diǎn)符號和大寫模型(圖 2 )。
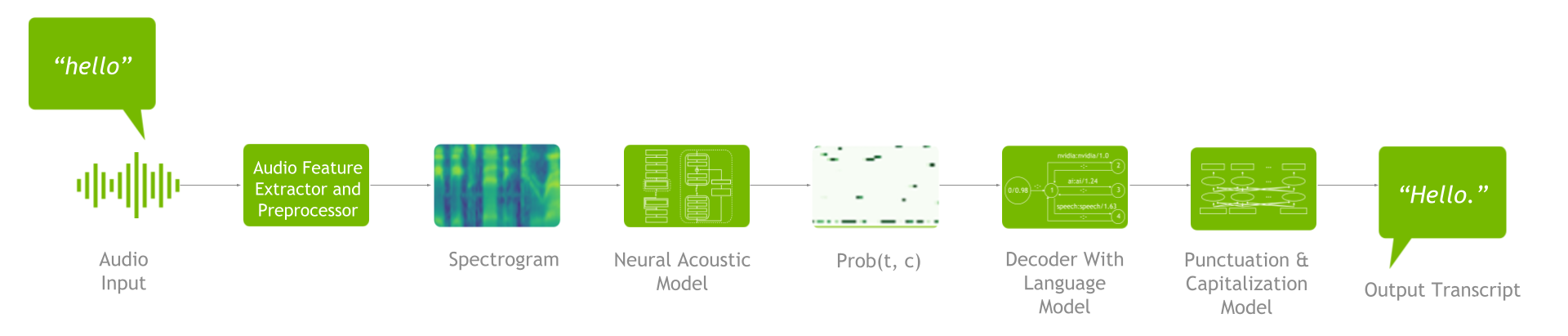
圖 2.ASR 管道
要了解可用的 ASR 定制,掌握端到端流程很重要。首先,進(jìn)行特征提取,將原始音頻波形轉(zhuǎn)換為頻譜圖/梅爾頻譜圖。然后將這些頻譜圖輸入聲學(xué)模型,該模型生成一個(gè)矩陣,其中包含每個(gè)時(shí)間步長的所有字符的概率。
接下來,解碼器與語言模型一起使用該矩陣作為輸入來生成文本。然后,您可以通過標(biāo)點(diǎn)符號和大寫模型運(yùn)行生成的文本,以提高可讀性。
高級語音 AI SDK 和工作流(如 Riva )支持語音識別管道定制。自定義可幫助您解決一些特定于語言的挑戰(zhàn),例如了解以下一項(xiàng)或多項(xiàng):
多重口音
單詞語境化
領(lǐng)域?qū)S眯g(shù)語
多種方言
多種語言
噪音環(huán)境中的用戶
Riva 中的定制可以應(yīng)用于訓(xùn)練和推理階段。從培訓(xùn)級別定制開始,您可以微調(diào)聲學(xué)模型、解碼器/語言模型以及標(biāo)點(diǎn)符號和大寫模型。這可以確保您的管道能夠理解不同的語言、方言、口音和行業(yè)特定的行話,并且對噪音具有魯棒性。
當(dāng)涉及到推理級自定義時(shí),可以使用 word boosting 。通過單詞增強(qiáng),在解碼聲學(xué)模型的輸出時(shí), ASR 管道更可能通過給某些感興趣的單詞更高的分?jǐn)?shù)來識別它們。
開始使用 NVIDIA Riva 為 XR 開發(fā)集成 ASR 服務(wù)
Riva 作為客戶機(jī) – 服務(wù)器模型運(yùn)行。要運(yùn)行 Riva ,您需要訪問帶有 NVIDIA GPU 的 Linux 服務(wù)器,在那里您可以安裝和運(yùn)行 Riva 服務(wù)器(本文提供了詳細(xì)信息和說明)。
Riva 客戶端 API 集成到 Windows 應(yīng)用程序中。在運(yùn)行時(shí), Windows 客戶端通過網(wǎng)絡(luò)向 Riva 服務(wù)器發(fā)送 Riva 請求,而[ZDK0 :服務(wù)器則發(fā)送回復(fù)。單個(gè) Riva 服務(wù)器可以同時(shí)支持多個(gè) Riva 客戶端。
ASR 服務(wù)可以在兩種不同的模式下運(yùn)行:
Offline mode: 捕獲完整的語音段,完成后發(fā)送到 Riva 以轉(zhuǎn)換為文本。
Streaming mode: 語音片段正在實(shí)時(shí)流式傳輸?shù)?Riva 服務(wù)器,文本結(jié)果正在實(shí)時(shí)流回。流模式有點(diǎn)復(fù)雜,因?yàn)樗枰鄠€(gè)線程。
本文稍后將提供兩種模式的示例。
在本節(jié)中,您將學(xué)習(xí)幾種將 Riva 集成到 Windows 應(yīng)用程序中的方法:
Python ASR 離線客戶端
Python 流式 ASR 客戶端
使用 Docker 的 C ++脫機(jī)客戶端
C ++流媒體客戶端
首先,這里介紹了如何設(shè)置和運(yùn)行 Riva 服務(wù)器。
先決條件
訪問 NGC 。有關(guān)分步說明,請參閱 NGC Getting Started Guide
執(zhí)行所有步驟,以便能夠從命令行界面( CLI )運(yùn)行ngc命令。
訪問 NVIDIA Volta 、 NVIDIA -Turing 或基于 A100 GPU 的 NVIDIA 安培架構(gòu)。帶有 NVIDIA GPU 的 Linux 服務(wù)器也可從主要 CSP 獲得。有關(guān)更多信息,請參閱 support matrix 。
Docker 安裝,支持 NVIDIA GPU 。
按照說明安裝 NVIDIA Container Toolkit ,然后安裝nvidia-docker軟件包。
服務(wù)器設(shè)置
通過運(yùn)行以下命令從 NGC 下載腳本:
ngc registry resource download-version nvidia/riva/riva_quickstart:2.4.0
初始化 Riva 服務(wù)器:
bash riva_init.sh
啟動(dòng) Riva 服務(wù)器:
bash riva_start.sh
運(yùn)行 Python ASR 脫機(jī)客戶端
首先,運(yùn)行以下命令來安裝riva客戶端軟件包。確保您使用的是 Python 版本 3.7 。
pip install nvidia-riva-client
以下代碼示例以脫機(jī)模式運(yùn)行 ASR 轉(zhuǎn)錄。您必須更改服務(wù)器地址,給出要轉(zhuǎn)錄的音頻文件的路徑,并選擇語言代碼。目前, Riva 支持英語、西班牙語、德語、俄語和普通話。
import io import IPython.display as ipd import grpc import riva.client auth = riva.client.Auth(uri='server address:port number') riva_asr = riva.client.ASRService(auth) # Supports .wav file in LINEAR_PCM encoding, including .alaw, .mulaw, and .flac formats with single channel # read in an audio file from local disk path = "audio file path" with io.open(path, 'rb') as fh: content = fh.read() ipd.Audio(path) # Set up an offline/batch recognition request config = riva.client.RecognitionConfig() #req.config.encoding = ra.AudioEncoding.LINEAR_PCM # Audio encoding can be detected from wav #req.config.sample_rate_hertz = 0 # Sample rate can be detected from wav and resampled if needed config.language_code = "en-US" # Language code of the audio clip config.max_alternatives = 1 # How many top-N hypotheses to return config.enable_automatic_punctuation = True # Add punctuation when end of VAD detected config.audio_channel_count = 1 # Mono channel response = riva_asr.offline_recognize(content, config) asr_best_transcript = response.results[0].alternatives[0].transcript print("ASR Transcript:", asr_best_transcript) print("\n\nFull Response Message:") print(response)
運(yùn)行 Python 流式 ASR 客戶端
要運(yùn)行 ASR 流客戶端,請克隆riva python-clients存儲(chǔ)庫并運(yùn)行存儲(chǔ)庫附帶的文件。
要使 ASR 流式處理客戶端在 Windows 上運(yùn)行,請運(yùn)行以下命令克隆存儲(chǔ)庫:
git clone https://github.com/nvidia-riva/python-clients.git
從python-clients/scripts/asr文件夾運(yùn)行以下命令:
python transcribe_mic.py --server=server address:port number
下面是 transcibe_mic.py :
import argparse import riva.client from riva.client.argparse_utils import add_asr_config_argparse_parameters, add_connection_argparse_parameters import riva.client.audio_io def parse_args() -> argparse.Namespace: default_device_info = riva.client.audio_io.get_default_input_device_info() default_device_index = None if default_device_info is None else default_device_info['index'] parser = argparse.ArgumentParser( description="Streaming transcription from microphone via Riva AI Services", formatter_class=argparse.ArgumentDefaultsHelpFormatter, ) parser.add_argument("--input-device", type=int, default=default_device_index, help="An input audio device to use.") parser.add_argument("--list-devices", action="store_true", help="List input audio device indices.") parser = add_asr_config_argparse_parameters(parser, profanity_filter=True) parser = add_connection_argparse_parameters(parser) parser.add_argument( "--sample-rate-hz", type=int, help="A number of frames per second in audio streamed from a microphone.", default=16000, ) parser.add_argument( "--file-streaming-chunk", type=int, default=1600, help="A maximum number of frames in a audio chunk sent to server.", ) args = parser.parse_args() return args def main() -> None: args = parse_args() if args.list_devices: riva.client.audio_io.list_input_devices() return auth = riva.client.Auth(args.ssl_cert, args.use_ssl, args.server) asr_service = riva.client.ASRService(auth) config = riva.client.StreamingRecognitionConfig( config=riva.client.RecognitionConfig( encoding=riva.client.AudioEncoding.LINEAR_PCM, language_code=args.language_code, max_alternatives=1, profanity_filter=args.profanity_filter, enable_automatic_punctuation=args.automatic_punctuation, verbatim_transcripts=not args.no_verbatim_transcripts, sample_rate_hertz=args.sample_rate_hz, audio_channel_count=1, ), interim_results=True, ) riva.client.add_word_boosting_to_config(config, args.boosted_lm_words, args.boosted_lm_score) with riva.client.audio_io.MicrophoneStream( args.sample_rate_hz, args.file_streaming_chunk, device=args.input_device, ) as audio_chunk_iterator: riva.client.print_streaming( responses=asr_service.streaming_response_generator( audio_chunks=audio_chunk_iterator, streaming_config=config, ), show_intermediate=True, ) if __name__ == '__main__': main()
使用 Docker 運(yùn)行 C ++ ASR 脫機(jī)客戶端
下面是如何在 C ++中使用 Docker 運(yùn)行 Riva ASR 脫機(jī)客戶端。
通過運(yùn)行以下命令克隆/ cpp 客戶端 GitHub 存儲(chǔ)庫:
git clone https://github.com/nvidia-riva/cpp-clients.git
構(gòu)建 Docker 映像:
DOCKER_BUILDKIT=1 docker build . –tag riva-client
運(yùn)行 Docker 映像:
docker run -it --net=host riva-client
啟動(dòng) Riva 語音識別客戶端:
Riva_asr_client –riva_url server address:port number –audio_file audio_sample
運(yùn)行 C ++ ASR 流式處理客戶端
要在 C ++中運(yùn)行 ASR 流式客戶端riva_asr,必須首先編譯 cpp sample 。在滿足以下依賴項(xiàng)之后,使用 CMake 很簡單:
gflags
glog
grpc
rtaudio
rapidjson
protobuf
grpc_cpp_plugin
在根源文件夾中創(chuàng)建文件夾/build。在終端上,鍵入cmake 。.,然后鍵入make。有關(guān)詳細(xì)信息,請參閱存儲(chǔ)庫中包含的自述文件。
編譯樣本后,輸入以下命令運(yùn)行它:
riva_asr.exe --riva_uri={riva server url}:{riva server port} --audio_device={Input device name, e.g. "plughw:PCH,0"}
-
riva_uri:riva服務(wù)器的address:port值。默認(rèn)情況下,riva服務(wù)器偵聽端口 50051 。 -
audio_device:要使用的輸入設(shè)備(麥克風(fēng))。
該示例實(shí)際上實(shí)現(xiàn)了四個(gè)步驟。這篇文章中只展示了幾個(gè)簡短的例子。有關(guān)詳細(xì)信息,請參閱文件streaming_recognize_client.cc。
使用命令行中指定的輸入(麥克風(fēng))設(shè)備打開輸入流。在這種情況下,您使用的是每秒 16K 采樣和 16 位采樣的一個(gè)通道。
int StreamingRecognizeClient::DoStreamingFromMicrophone(const std::string& audio_device, bool& request_exit)
{
nr::AudioEncoding encoding = nr::LINEAR_PCM;
adc.setErrorCallback(rtErrorCallback);
RtAudio::StreamParameters parameters;
parameters.nChannels = 1;
parameters.firstChannel = 0;
unsigned int sampleRate = 16000;
unsigned int bufferFrames = 1600; // (0.1 sec of rec) sample frames
RtAudio::StreamOptions streamOptions;
streamOptions.flags = RTAUDIO_MINIMIZE_LATENCY;
…
RtAudioErrorType error = adc.openStream( nullptr, ¶meters, RTAUDIO_SINT16, sampleRate, &bufferFrames, &MicrophoneCallbackMain, static_cast(&uData), &streamOptions);
使用.proto 文件指定的協(xié)議 api 接口(在文件夾riva/proto的源中)打開與 Riva 服務(wù)器的grpc通信通道:
int StreamingRecognizeClient::DoStreamingFromMicrophone(const std::string& audio_device, bool& request_exit)
{
…
std::shared_ptr call = std::make_shared(1, word_time_offsets_);
call->streamer = stub_->StreamingRecognize(&call->context);
// Send first request
nr_asr::StreamingRecognizeRequest request;
auto streaming_config = request.mutable_streaming_config();
streaming_config->set_interim_results(interim_results_);
auto config = streaming_config->mutable_config();
config->set_sample_rate_hertz(sampleRate);
config->set_language_code(language_code_);
config->set_encoding(encoding);
config->set_max_alternatives(max_alternatives_);
config->set_audio_channel_count(parameters.nChannels);
config->set_enable_word_time_offsets(word_time_offsets_);
config->set_enable_automatic_punctuation(automatic_punctuation_);
config->set_enable_separate_recognition_per_channel(separate_recognition_per_channel_);
config->set_verbatim_transcripts(verbatim_transcripts_);
if (model_name_ != "") {
config->set_model(model_name_);
}
call->streamer->Write(request);
開始發(fā)送麥克風(fēng)通過grpc消息接收到的音頻數(shù)據(jù)到riva:
static int MicrophoneCallbackMain( void *outputBuffer, void *inputBuffer, unsigned int nBufferFrames, double streamTime, RtAudioStreamStatus status, void *userData )
通過服務(wù)器的grpc應(yīng)答接收轉(zhuǎn)錄的音頻:
void StreamingRecognizeClient::ReceiveResponses(std::shared_ptrcall, bool audio_device) { … while (call->streamer->Read(&call->response)) { // Returns false when no m ore to read. call->recv_times.push_back(std::chrono::steady_clock::now()); // Reset the partial transcript call->latest_result_.partial_transcript = ""; call->latest_result_.partial_time_stamps.clear(); bool is_final = false; for (int r = 0; r < call->response.results_size(); ++r) { const auto& result = call->response.results(r); if (result.is_final()) { is_final = true; } … call->latest_result_.audio_processed = result.audio_processed(); if (print_transcripts_) { call->AppendResult(result); } } if (call->response.results_size() && interim_results_ && print_transcripts_) { std::cout << call->latest_result_.final_transcripts[0] + call->latest_result_.partial_transcript << std::endl; } call->recv_final_flags.push_back(is_final); }
開發(fā)語音 AI 應(yīng)用程序的資源
通過識別你的聲音或執(zhí)行命令,語音人工智能正在從在聯(lián)絡(luò)中心授權(quán)實(shí)際人類擴(kuò)展到在元宇宙授權(quán)數(shù)字人類。
關(guān)于作者
Sirisha Rella 是 NVIDIA 的技術(shù)產(chǎn)品營銷經(jīng)理,專注于計(jì)算機(jī)視覺、語音和基于語言的深度學(xué)習(xí)應(yīng)用。 Sirisha 獲得了密蘇里大學(xué)堪薩斯城分校的計(jì)算機(jī)科學(xué)碩士學(xué)位,是國家科學(xué)基金會(huì)大學(xué)習(xí)中心的研究生助理。
Davide Onofrio 是 NVIDIA 的高級深度學(xué)習(xí)軟件技術(shù)營銷工程師。他在 NVIDIA 專注于深度學(xué)習(xí)技術(shù)開發(fā)人員關(guān)注內(nèi)容的開發(fā)和演示。戴維德在生物特征識別、虛擬現(xiàn)實(shí)和汽車行業(yè)擔(dān)任計(jì)算機(jī)視覺和機(jī)器學(xué)習(xí)工程師已有多年經(jīng)驗(yàn)。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4939瀏覽量
102815 -
AI
+關(guān)注
關(guān)注
87文章
30137瀏覽量
268411 -
vr
+關(guān)注
關(guān)注
34文章
9633瀏覽量
150058
發(fā)布評論請先 登錄
相關(guān)推薦
傳蘋果正開發(fā)下一代無線充電技術(shù)
用Java開發(fā)下一代嵌入式產(chǎn)品
S2C與Japan Circuit合作,共同開發(fā)下一代超高速
用CompactRIO和LabVIEW開發(fā)下一代機(jī)器人控制系
安森美開發(fā)下一代GaN-on-Si功率器件
三星電子與丹麥頂級音響公司合作,共同開發(fā)下一代顯示器
蘋果將開發(fā)顯示屏 將大舉開發(fā)下一代MicroLED
英飛凌與Aaware達(dá)成戰(zhàn)略合作,開發(fā)下一代語音開發(fā)平臺

IBM宣布在紐約投資20億美元建立一個(gè)新的IBMAI硬件中心 旨在開發(fā)下一代AI硬件
電裝將與高通共同開發(fā)下一代座艙系統(tǒng)
擴(kuò)展現(xiàn)實(shí)或?qū)⒊蔀?b class='flag-5'>下一代生產(chǎn)力工具
KYOCERA AVX和VisIC Technologies合作開發(fā)下一代電車應(yīng)用GaN技術(shù)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論