 云端AI芯片的市場需求不斷增長
云端AI芯片的市場需求不斷增長
電子發燒友網報道(文/李彎彎)根據應用場景的不同,AI芯片被分為云端AI芯片和邊緣AI芯片。云端AI芯片有些用于訓練,有些用于推理。過去幾年AI芯片的市場需求不斷增加,2017年整體AI芯片市場規模為62.7億美元,預計到2022年將會達到596.2億美元。
而云端AI芯片的市場需求也是增長明顯,根據市場調研機構數據,2017年云端訓練AI芯片市場規模為20.2億美元,云端推理芯片為3.4億美元。預計到2022年,云端訓練AI芯片將達到172.1億美元,云端推理芯片為71.9億美元。
如今在全球云端AI芯片市場領域,可以說是英偉達一家獨大,在云端訓練市場占比達到90%,在云端推理市場占比也高達60%。另外,國外的英特爾、AMD等廠商也在積極布局。
在國內,也有大批企業尋求在云端AI芯片方面不斷突破,包括寒武紀、昆侖芯、燧原科技、天數智芯,以及瀚博半導體、沐曦集成、壁仞科技、摩爾線程、登臨科技等。這里對這些企業及產品進展做了梳理,如下:
寒武紀
寒武紀成立于2016年,專注于人工智能芯片產品的研發與技術創新,致力于打造人工智能領域的核心處理器芯片。產品廣泛應用于服務器廠商和產業公司,面向互聯網、金融、交通、能源、電力和制造等領域的復雜AI應用場景提供充裕算力,推動人工智能賦能產業升級。
寒武紀云端智能芯片產品,大致可以分為云端訓練芯片和云端推理芯片,包括云端推理芯片思元270,主要面向云端訓練的高端產品思元290,以及主要面向中高端訓推場景的思元370。
思元290是寒武紀首顆AI訓練芯片,采用創新性的MLUv02擴展架構,使用臺積電7nm先進制程工藝制造,在一顆芯片上集成了高達460億的晶體管。
思元370基于7nm制程工藝,是寒武紀首款采用chiplet(芯粒)技術的AI芯片,集成了390億個晶體管,最大算力高達256TOPS(INT8),是寒武紀第二代產品思元270算力的2倍。憑借寒武紀最新智能芯片架構MLUarch03,思元370實測性能表現更為優秀。
思元370是國內第一款公開發布支持LPDDR5內存的云端AI芯片,內存帶寬是上一代產品的3倍,訪存能效達GDDR6的1.5倍。搭載MLU-Link多芯互聯技術,在分布式訓練或推理任務中為多顆思元370芯片提供高效協同能力。全新升級的Cambricon NeuWare軟件棧,新增推理加速引擎MagicMind,實現訓推一體,大幅提升了開發部署的效率,降低用戶的學習成本、開發成本和運營成本。
思元370通過不同MLU-Die組合出了三款不同規格、符合不同場景需求的加速卡產品MLU370-S4、MLU370-X4、MLU370-X8。
2021年,寒武紀與阿里巴巴等頭部互聯網企業的多個業務部門進行了深入合作,云端產品思元370芯片及加速卡在視覺、語音、圖文識別等場景的適配性能表現超出客戶預期,部分場景已經進入小批量銷售環節。在金融領域,寒武紀與多家頭部銀行進行了導入和適配。其中,MLU370-X4在招商銀行多個業務場景的實測性能超過競品,能夠大幅提升客戶的效率。
昆侖芯
昆侖芯于2021年4月完成了獨立融資,前身是百度智能芯片及架構部,在實際業務場景中深耕AI加速領域已十余年,是一家在體系結構、芯片實現、軟件系統和場景應用均有深厚積累的AI芯片企業。
昆侖芯1代芯片于2020年量產,昆侖芯2代于2021年8月18日宣布正式量產。2022年09月百度集團執行副總裁沈抖透露,昆侖芯3代將于2024年初量產。
昆侖芯1代芯片采用14nm工藝,256 TOPS@INT8算力,可用于云數據中心和智能邊緣,支持全AI算法,落地超過兩萬片;昆侖芯2代芯片,搭載自研的第二代XPU架構,采用7nm制程,GDDR6高性能顯存,算力256 TOPS@INT8,128 TFLOPS@FP16,相比一代性能提升2-3倍,適用于云、端、邊等多場景,支持硬件虛擬化,芯片間互聯和視頻編解碼。
昆侖芯 AI 芯片除了擁有自研 XPU 架構及多項自主設計,也已與飛騰等多款國產通用處理器、麒麟等多款國產操作系統以及百度自研的飛槳深度學習框架完成了端到端的適配,擁有軟硬一體的全棧國產AI能力。
目前,昆侖芯科技已與智能產業的上下游企業建立了良好的合作生態,通過向不同行業提供以人工智能芯片為基礎的算力產品,輻射互聯網、智慧城市、智算中心、智慧工業、智慧應急、智慧交通、智慧金融等“智慧+”產業,以計算驅動智能,以智能促進發展。
燧原科技
燧原科技成立于2018年3月,專注人工智能領域云端算力產品,致力為人工智能產業發展交付普惠的基礎設施解決方案,提供原始創新、全棧自研、具備完全自主知識產權的通用人工智能訓練和推理產品。憑借其高算力、 高能效比以及靈活編程能力,可廣泛應用于互聯網、金融、交通、能源及新基建等多個行業和場景。
截至目前,燧原科技已經開發了兩個產品線,一個是云端的訓練,包括邃思1.0和邃思2.0,一個是推理芯片,邃思2.5。
邃思1.0基于可編程芯片的設計理念,其計算核心包含32個通用可擴展神經元處理器(SIP),每8個SIP組合成1個可擴展智能計算群(SIC)。SIC之間通過HBM實現高速互聯,通過片上調度算法,數據在搬遷中完成計算,實現SIP利用率最大化。邃思支持CNN、RNN、LSTM、BERT等網絡模型和豐富的數據類型(FP32 / FP16 / BF16 / Int8 / Int16 / Int32等)。
邃思2.0基于GCU-CARA 2.0架構,以TF32為核心提供多數據精度AI算力支持,針對張量、矢量、標量等多計算范式提供領先性能,支持指令驅動、可編程的融合式數據流架構,提供軟件透明、基于任務的智能調度;基于12nm FinFET先進工藝,單芯片包含225億個晶體管,有效提升算力密度;廣泛支持視覺、語音語義、強化學習等各技術方向的模型訓練。
燧原科技創始人趙立東前不久表示,公司去年與浪潮科技,聯合發布了錢塘江智算中心的解決方案,打造了一個液冷的160臺服務器的算力集群,集成了180張燧原科技第一代的訓練卡,現在已部署在之江實驗室上線運行。
天數智芯
天數智芯2018年正式啟動通用并行云端計算芯片設計,公司致力于開發云端服務器級的通用高性能計算芯片,以客戶、市場為導向,瞄準以云計算、人工智能、數字化轉型為代表的數據驅動技術市場,解決核心算力瓶頸問題,為全產業打造高端算力解決方案。
2021年3月,天數智芯正式發布通用GPU“天垓100”芯片及天垓100加速卡。天垓100芯片基于7nm工藝,采用全自研的架構、計算核、指令集及基礎軟件棧,2.5D CoWoS晶圓封裝技術,包括240億個晶體管。
天數智芯堅持自研通用GPU體系思路,天垓100適配x86、ARM、MIPS等架構CPU指令集,業界標準的軟件API(應用程序編程接口)支持垂直類行業應用開發,支持TensorFlow、PyTorch等各種主流深度學習開發框架,以及軟硬件全棧支持等,廣泛應用于互聯網、運營商、生物醫療、教育科研、智算中心等不同行業眾多應用場景。
2022年4月,天數智芯宣布,目前天垓100產品累計訂單金額已經接近2億元,覆蓋新華三等多個頭部企業。而且,天垓100已支撐近百個客戶在人工智能領域進行超過兩百個不同種類模型訓練。另外天數智芯首款7nm通用GPU推理產品智鎧100也在今年5月份成功點亮。
瀚博半導體
瀚博半導體成立于2018年,專注于研發高性能通用加速芯片,為計算機視覺、智能視頻處理、自然語言處理等應用場景,提供低延時、高吞吐的異構計算性能和高效的性能/功耗比,芯片解決方案覆蓋從云端到邊緣的服務器及一體機市場。
2021年7月7日,瀚博半導體發布首款云端通用AI推理芯片SV100系列及VA1通用推理加速卡。SV100系列,深度學習推理性能指標數倍于現有主流數據中心GPU,超高吞吐量、超低延遲;針對各種深度學習推理負載而優化的通用架構,支持計算機視覺、視頻處理、自然語言處理和搜索推薦等推理應用場景;集成高密度視頻解碼,廣泛適用于云端與邊緣解決方案,單芯片INT8峰值算力超過200TOPS,節省設備投資、降低運營成本。
在2022年世界人工智能大會期間,瀚博半導體又發布了四款新品:瀚博統一計算架構、全新數據中心AI推理卡載天VA10、邊緣AI推理加速卡載天VE1、以及瀚博軟件平臺VastStream擴展版。此外,瀚博還預覽展示國產7nm云端GPU芯片SG100,用于圖像渲染、視頻、元宇宙等領域,不過這款產品目前還未發布。
沐曦集成
沐曦集成成立于2022年9月,公司致力于為異構計算提供安全可靠的高性能GPU芯片及解決方案,可廣泛應用于人工智能、智慧城市、數據中心、云計算、自動駕駛、科學計算、數字孿生、元宇宙等前沿領域,為數字經濟發展提供強大的算力支撐。
2022年1月,沐曦首款采用7nm工藝的異構GPU產品已正式流片,預計很快量產。該產品主要用于AI推理場景,可在人工智能、自動駕駛、工業和制造自動化、智慧城市、自然語言處理、邊緣計算等領域應用。
沐曦第二款用于科學計算、數據中心彈性計算、AI訓練等的旗艦GPU芯片也已進入研發收尾階段,計劃于2024年全面量產。此外,到2025年,沐曦將推出融合了圖形渲染的完整GPU產品,也就是顯示和游戲用途的GPU。
沐曦產品均采用完全自主研發的高性能GPU IP,擁有完全自主的指令集和架構,配以兼容主流GPU生態的完整軟件棧(MACAMACA),具備高性能、高效能和高通用性的天然優勢,能夠為客戶構建軟硬件一體的全面生態解決方案。
壁仞科技
壁仞科技創立于2019年,致力于開發原創性的通用計算體系,建立高效的軟硬件平臺,同時在智能計算領域提供一體化的解決方案。從發展路徑上,壁仞科技將首先聚焦云端通用智能計算,逐步在人工智能訓練和推理、圖形渲染等多個領域趕超現有解決方案。
壁仞科技BR100系列通用GPU芯片,針對人工智能訓練、推理,及科學計算等更廣泛的通用計算場景開發,主要部署在大型數據中心,依托“壁立仞”原創架構,可提供高能效、高通用性的加速計算算力。目前,BR100系列擁有BR100、BR104兩款芯片。
BR100系列采用7nm制程,并創新性應用Chiplet與2.5D CoWoS封裝技術,兼顧高良率與高性能;支持PCIe 5.0接口技術與CXL通信協議,雙向帶寬最高達128 GB/s;原創BLink高速GPU互連技術,單卡互連帶寬最高達448 GB/s,并支持單節點8卡全互連;除原生支持FP32、BF16、FP16、INT8等主流數據精度外,原創定義TF32+數據精度,相較TF32提供更高數據精度與吞吐性能。
摩爾線程
摩爾線程成立于2020年10月,專注于研發設計全功能GPU芯片及相關產品,支持3D高速圖形渲染、AI訓練推理加速、超高清視頻編解碼和高性能科學計算等多種組合工作負載,兼顧算力與算效,能夠為中國科技生態合作伙伴提供強大的計算加速能力。
2022年3月30日,摩爾線程正式推出首款基于其先進架構MUSA統一系統架構(Moore Threads Unified System Architecture)打造的數據中心級多功能GPU產品MTT S2000,內置渲染、音視頻編解碼、人工智能加速和并行計算等硬件模塊,能夠提供圖形圖像渲染、視頻云處理、AI和科學計算在內的全棧功能。
憑借其獨特的渲染、虛擬化等能力和廣泛的生態支持,MTT S2000可以在云桌面、安卓云游戲、視頻云、云渲染和AI推理計算加速等應用場景全面助力綠色數字經濟發展。
摩爾線程MTT S2000兼容X86、ARM等CPU架構以及主流Linux操作系統發行版,并已著手與多家服務器合作伙伴開展合作,包括浪潮、新華三、聯想、清華同方、長城超云、思騰合力等OEM廠商多款通用服務器及GPU服務器型號,可以在眾多硬件和應用環境中完成部署。
得益于豐富的模型庫支持和先進硬件設計,MTT S2000能夠滿足計算機視覺、自然語言處理等多種智能應用場景的模型訓練和推理應用,并對包括DBNet、CRNN、FastRCNN、Yolo V2/V3/V5、PSENet、Mask RCNN、Resnet 50/101、Inception、Vgg、Alexnet、Densenet、Unet等在內的眾多主流深度學習算法提供支持。
同時,MTT S2000也支持用戶使用PyTorch、TensorFlow、PaddlePaddle等深度學習框架進行算法開發及應用搭建。此外,用戶也可通過應用更廣泛的OpenCL及CUDA環境進行開發,大幅降低了新硬件的學習及應用門檻,提升開發速度。
登臨科技
登臨科技成立于2017年,專注于高性能通用計算平臺的芯片研發與技術創新,致力于打造云邊端一體、軟硬件協同、訓練推理融合的前沿芯片產品和平臺化基礎系統軟件。
公司自主創新的GPU+,在兼容CUDA/OpenCL在內的編程模型和軟件生態的基礎上,通過架構創新,完美解決了通用性和高效率的雙重難題。大量客戶產品實測證明,針對AI計算,GPU+相比傳統GPU在性能尤其是能效上有顯著提升。
2022年9月,登臨科技創始人李建文在某會議上表示,登臨科技首款系列產品基于GPU+的創新AI加速器Goldwasser已在智慧城市、交通、金融、能源、電力、教育、無人駕駛、互聯網等眾多行業實現商業化落地,目標年內客戶訂單達數萬片,并且已實現批量量產交付。登臨第二代產品將于明年上半年進入市場,其能效比將是第一代產品的2倍。
另外,登臨科技還發布了完整的翰銘(Hamming)軟件工具鏈,該工具鏈支持國內外主流AI框架、操作系統、CPU、容器與虛擬機、以及推理服務器,可幫助客戶盡快把算法部署到實際業務上,并幫助云端與數據中心的客戶更好地利用硬件資源。
小結
總結來看,寒武紀、昆侖芯的云端AI芯片已經有一定量出貨,燧原科技的產品也已經智算中心中部署運行,天數智芯表示其天垓100產品累計已拿下接近2億元的訂單金額,登臨科技的產品也已經實現批量交付。其他各家的產品在研發和推進應用方面,都有不同程度的進展。整體而言,各家廠商都在積極尋求創新,尋求突破。
-
互聯網
+關注
關注
54文章
11105瀏覽量
103009 -
人工智慧
+關注
關注
0文章
12瀏覽量
2052 -
AI芯片
+關注
關注
17文章
1859瀏覽量
34908
原文標題:?云端AI芯片市場需求不斷增長,國內廠商進展如何?
文章出處:【微信號:elecfans,微信公眾號:電子發燒友網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
智能面膜或成印刷電子技術市場化的主要增長產品

RISC-V擁有巨大市場潛力的原因
半導體市場迎高增長,AI與存儲芯片成主要驅動力
RISC-V在中國的發展機遇有哪些場景?
日月光投控迎來先進封裝技術的強勁市場需求
英偉達AI芯片需求激增,封測廠訂單量或翻倍
振華風光提前研發以應對市場需求增長
工業富聯預估今年AI在云端項目營收占比40%
隨著AI算力需求不斷增強,800G光模塊的需求不斷增大
半導體市場需求日益旺盛 連續三個月正增長
MCU芯片和功率半導體價格攀升,市場需求復蘇信號不明
英偉達如何應對AI芯片市場需求的轉變
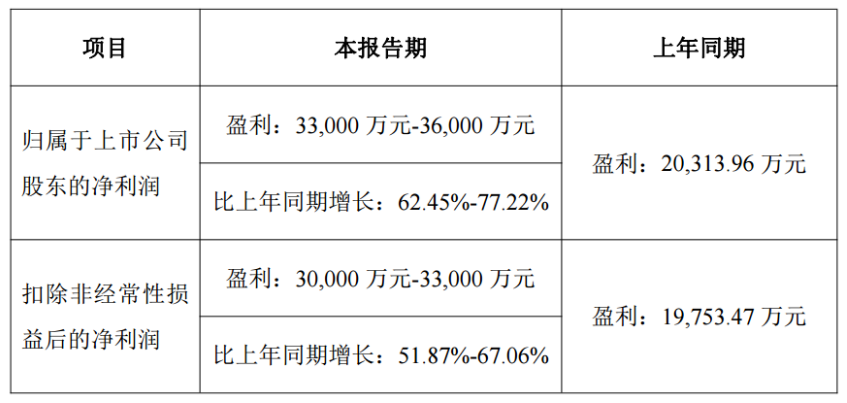
曼恩斯特預計2023年凈利潤增長62%-77%,受益于新能源市場需求增加





 工商網監
工商網監
評論