 cache的排布與CPU的典型分布
cache的排布與CPU的典型分布
CACHE 基礎
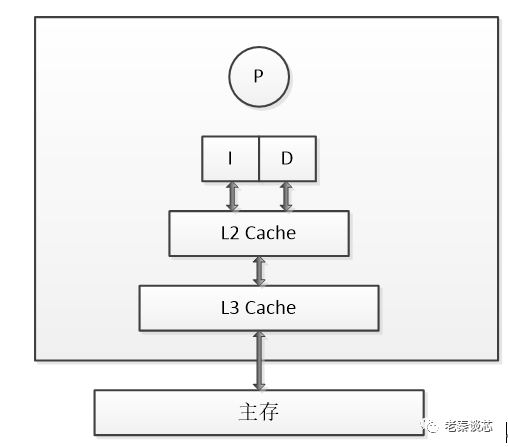
對cache的掌握,對于Linux工程師(其他的非Linux工程師也一樣)寫出高效能代碼,以及優化Linux系統的性能是至關重要的。簡單來說,cache快,內存慢,硬盤更慢。在一個典型的現代CPU中比較接近改進的哈佛結構,cache的排布大概是這樣的:
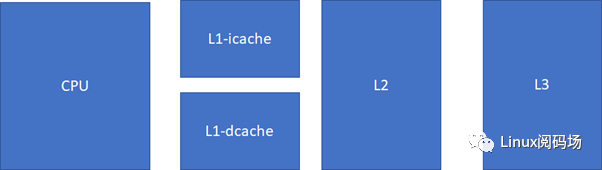
L1速度>L2速度>L3速度>RAM L1容量
現代CPU,通常L1 cache的指令和數據是分離的。
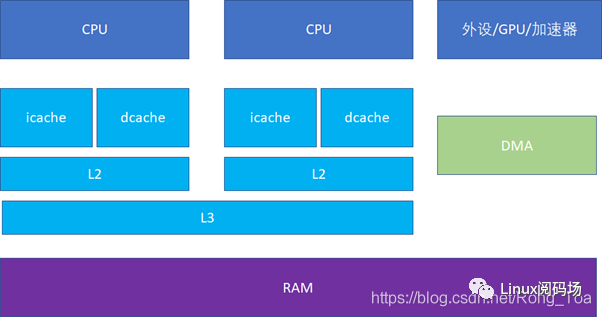
這樣可以實現2條高速公路并行訪問,CPU可以同時load指令和數據。當然,cache也不一定是一個core獨享,現代很多CPU的典型分布是這樣的,比如多個core共享一個L3。比如這臺的Linux里面運行 lstopo 命令:
人們也常常稱呼L2cache為 MLC (MiddleLevel Cache), L3cache為 LLC(LastLevelCache)。
這些Cache究竟有多塊呢?
我們來看看Intel的數據,具體配置:Intel i7-4770 (Haswell), 3.4 GHz (Turbo Boostoff), 22nm. RAM: 32 GB (PC3-12800 cl11 cr2)
訪問延遲:
L1DataCacheLatency=4cyclesforsimpleaccessviapointer L1DataCacheLatency=5cyclesforaccesswithcomplexaddresscalculation(size_tn,*p;n=p[n]). L2CacheLatency=12cycles L3CacheLatency=36cycles(3.4GHzi7-4770) L3CacheLatency=43cycles(1.6GHzE5-2603v3) L3CacheLatency=58cycles(core9)-66cycles(core5)(3.6GHzE5-2699v3-18cores) RAMLatency=36cycles+57ns(3.4GHzi7-4770) RAMLatency=62cycles+100ns(3.6GHzE5-2699v3dual)
數據來源:https://www.7-cpu.com/cpu/Haswell.html
由此我們可以知道,我們應該盡可能追求cache的命中率高,以避免延遲, 最好是低級cache的命中率越高越好。
CACHE 的組織
SET、WAY、TAG、INDEX
現代的cache基本按照這個模式來組織:SET、WAY、TAG、INDEX
,這幾個概念是理解Cache的關鍵。隨便打開一個數據手冊,就可以看到這樣的字眼:
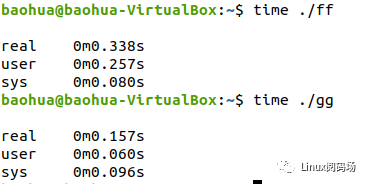
但是它的執行時間,則遠遠不到后者的8倍:
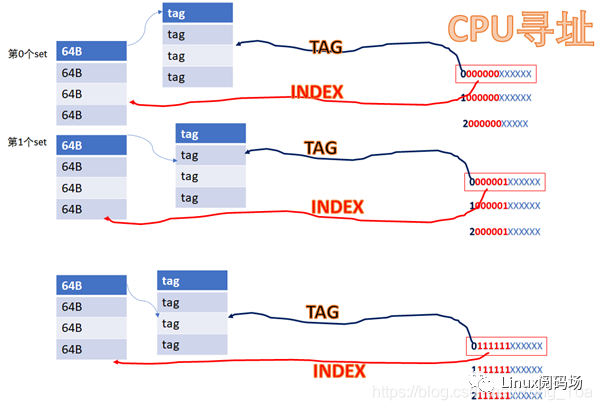
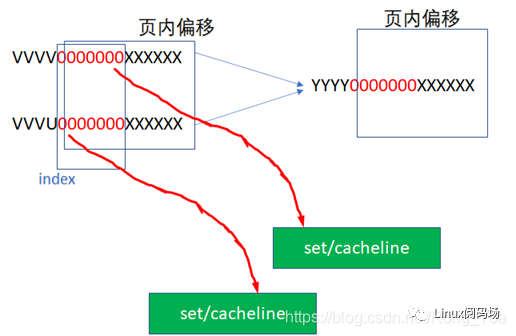
16KB 的cache是 4way 的話,每個set包括 4*64B ,則整個cache分為 16KB/64B/4 =64set
,也即2的6次方。當CPU從cache里面讀數據的時候,它會用地址位的BIT6-BIT11來尋址set,BIT0-BIT5是cacheline內的offset。
比如CPU訪問地址
0 000000 XXXXXX
或者
1 000000 XXXXXX
或者
YYYY 000000 XXXXXX
由于它們紅色的6位都相同,所以他們全部都會找到第0個set的cacheline。第0個set里面有4個way,之后硬件會用地址的高位如0,1,YYYY作為tag,去檢索這4個way的tag是否與地址的高位相同,而且cacheline是否有效,如果tag匹配且cacheline有效,則cache命中。
所以地址YYYYYY000000XXXXXX全部都是找第0個set,YYYYYY000001XXXXXX全部都是找第1個set,YYYYYY111111XXXXXX全部都是找第63個set。每個set中的4個way,都有可能命中。
中間紅色的位就是INDEX,前面YYYY這些位就是TAG。
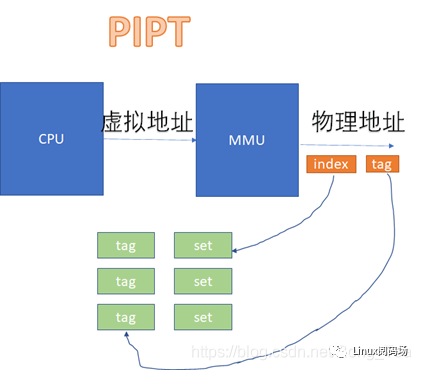
具體的實現可以是用虛擬地址或者物理地址的相應位做TAG或者INDEX。
如果用虛擬地址做TAG,我們叫VT;
如果用物理地址做TAG,我們叫PT;
如果用虛擬地址做INDEX,我們叫VI;
如果用物理地址做INDEX,我們叫PI。
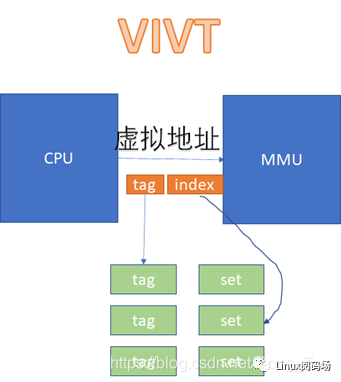
工程中碰到的cache可能有這么些組合:VIVT、VIPT、PIPT。
VIVT、VIPT、PIPT
具體的實現可以是用虛擬地址或者物理地址的相應位做TAG或者INDEX。
如果用虛擬地址做TAG,我們叫VT;
如果用物理地址做TAG,我們叫PT;
如果用虛擬地址做INDEX,我們叫VI;
如果用物理地址做INDEX,我們叫PI。
VIVT的硬件實現開銷最低,但是軟件維護成本高;PIPT的硬件實現開銷最高,但是軟件維護成本最低;VIPT介于二者之間,但是有些硬件是VIPT,但是behave
as PIPT,這樣對軟件而言,維護成本與PIPT一樣。在VIVT的情況下,CPU發出的虛擬地址,不需要經過MMU的轉化,直接就可以去查cache。
而在VIPT和PIPT的場景下,都涉及到虛擬地址轉換為物理地址后,再去比對cache的過程。VIPT如下:
PIPT如下:
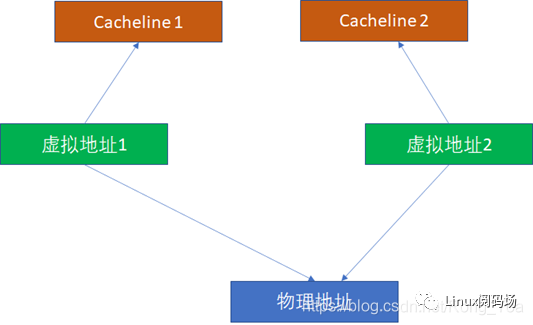
從圖上看起來,VIVT的硬件實現效率很高,不需要經過MMU就可以去查cache了。不過,對軟件來說,這是個災難。因為VIVT有嚴重的歧義和別名問題。
歧義:一個虛擬地址先后指向兩個(或者多個)物理地址
別名:兩個(或者多個)虛擬地址同時指向一個物理地址
Cache別名問題
這里我們重點看別名問題。比如2個虛擬地址對應同一個物理地址,基于VIVT的邏輯,無論是INDEX還是TAG,2個虛擬地址都是可能不一樣的(盡管他們的物理地址一樣,但是物理地址在cache比對中完全不摻和),這樣它們完全可能在2個cacheline同時命中。
由于2個虛擬地址指向1個物理地址,這樣CPU寫過第一個虛擬地址后,寫入cacheline1。CPU讀第2個虛擬地址,讀到的是過時的cacheline2,這樣就出現了不一致。所以,為了避免這種情況,軟件必須寫完虛擬地址1后,對虛擬地址1對應的cache執行clean,對虛擬地址2對應的cache執行invalidate。
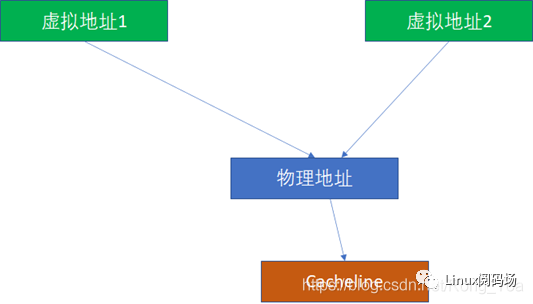
而PIPT完全沒有這樣的問題,因為無論多少虛擬地址對應一個物理地址,由于物理地址一樣,我們是基于物理地址去尋找和比對cache的,所以不可能出現這種別名問題。
那么VIPT有沒有可能出現別名呢?答案是有可能,也有可能不能。 如果VI恰好對于PI,就不可能,這個時候,VIPT對軟件而言就是PIPT了:
VI=PI PT=PT
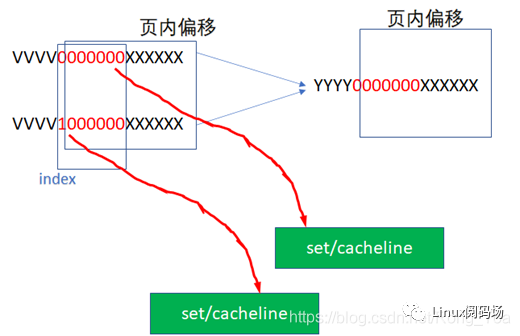
那么什么時候VI會等于PI呢?這個時候我們來回憶下虛擬地址往物理地址的轉換過程,它是以頁為單位的。假設一頁是4K,那么地址的低12位虛擬地址和物理地址是完全一樣的。回憶我們前面的地址:
YYYYY000000XXXXXX
其中紅色的000000是INDEX。在我們的例子中,紅色的6位和后面的XXXXXX(cache內部偏移)加起來正好12位,所以這個000000經過虛實轉換后,其實還是000000的,這個時候
VI=PI ,VIPT沒有別名問題。我們原先假設的cache是:16KB大小的cache,假設是4路組相聯,cacheline的長度是 64字節
,這樣我們正好需要紅色的6位來作為INDEX。但是如果我們把cache的大小增加為32KB,這樣我們需要
32KB/4/64B=128=2^7,也即7位來做INDEX。YYYY0000000XXXXXX
這樣VI就可能不等于PI了,因為紅色的最高位超過了2^12的范圍,完全可能出現如下2個虛擬地址,指向同一個物理地址:
這樣就出現了別名問題,
我們在工程里,可能可以通過一些辦法避免這種別名問題,比如軟件在建立虛實轉換的時候,把虛實轉換往2^13而不是2^12對齊,讓物理地址的低13位而不是低12位與物理地址相同,這樣強行繞開別名問題,下圖中,2個虛擬地址指向了同一個物理地址,但是它們的INDEX是相同的,這樣VI=PI,就繞開了別名問題。這通常是PAGE
COLOURING技術中的一種技巧。
如果這種PAGE
COLOURING的限制對軟件仍然不可接受,而我們又想享受VIPT的INDEX不需要經過MMU虛實轉換的快捷?有沒有什么硬件技術來解決VIPT別名問題呢?確實是存在的,現代CPU很多都是把L1
CACHE做成VIPT,但是表現地(behave as)像PIPT。這是怎么做到的呢?這要求VIPT的cache,硬件上具備alias detection的能力。比如,硬件知道YYYY 0000000 XXXXXX既有可能出現在第
0000000 ,又可能出現在 1000000
這2個set,然后硬件自動去比對這2個set里面是否出現映射到相同物理地址的cacheline,并從硬件上解決好別名同步,那么軟件就完全不用操心了。下面我們記住一個簡單的規則:
對于VIPT,如果cache的size除以WAY數,小于等于1個page的大小,則天然VI=PI,無別名問題;
對于VIPT,如果cache的size除以WAY數,大于1個page的大小,則天然VI≠PI,有別名問題;這個時候又分成2種情況:
硬件不具備alias detection能力,軟件需要pagecolouring;
硬件具備alias detection能力,軟件把cache當成PIPT用。
比如cache大小64KB,4WAY,PAGE SIZE是4K,顯然有別名問題;這個時候,如果cache改為16WAY,或者PAGE
SIZE改為16K,不再有別名問題。為什么?感覺小學數學知識也能算得清CACHE 的一致性
Cache的一致性有這么幾個層面
2.多個CPU各自的cache同步問題
3.CPU與設備(其實也可能是個異構處理器,不過在Linux運行的CPU眼里,都是設備,都是 DMA )的cache同步問題
cache中的映射
1. 直接映射
一個內存地址能被映射到的Cache line是固定的。就如每個人的停車位是固定分配好的,可以直接找到。缺點是:因為人多車位少,很可能幾個人爭用同一個車位,導致Cache淘汰換出頻繁,需要頻繁的從主存讀取數據到Cache,這個代價也較高。
2. 全相聯映射
主存中的一個地址可被映射進任意cache line,問題是:當尋找一個地址是否已經被cache時,需要遍歷每一個cache line來尋找,這個代價很高。就像停車位可以大家隨便停一樣,停的時候簡單,找車的時候需要一個一個停車位的找了。
主存中任何一塊都可以映射到Cache中的任何一塊位置上。
全相聯映射方式比較靈活,主存的各塊可以映射到Cache的任一塊中,Cache的利用率高,塊沖突概率低,只要淘汰Cache中的某一塊,即可調入主存的任一塊。但是,由于Cache比較電路的設計和實現比較困難,這種方式只適合于小容量Cache采用。3. 組相聯映射
組相聯映射實際上是直接映射和全相聯映射的折中方案,其組織結構如圖(3)所示。
主存和Cache都分組,主存中一個組內的塊數與Cache中的分組數相同,組間采用直接映射,組內采用全相聯映射。也就是說,將Cache分成2^u組,每組包含2^v塊,主存塊存放到哪個組是固定的,至于存到該組哪一塊則是靈活的。即主存的某塊只能映射到Cache的特定組中的任意一塊。主存的某塊b與Cache的組k之間滿足以下關系:k=b%(2^u).icache、dcache同步 - 指令流( icache )和數據流( dcache )
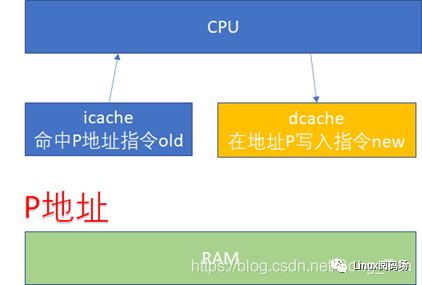
先看一下 ICACHE 和 DCACHE 同步問題。由于程序的運行而言, 指令流的都流過icache ,而指令中涉及到的數據流經過dcache 。所以對于自修改的代碼(Self-Modifying Code)而言,比如我們修改了內存p這個位置的代碼(典型多見于JIT
compiler),這個時候我們是通過store的方式去寫的p,所以新的指令會進入dcache。但是我們接下來去執行p位置的指令的時候,icache里面可能命中的是修改之前的指令。
所以這個時候軟件需要把dcache的東西clean出去,然后讓icache invalidate,這個開銷顯然還是比較大的。
但是,比如ARM64的N1處理器,它支持硬件的icache同步,詳見文檔:The Arm Neoverse N1 Platform: BuildingBlocks for the Next-Gen Cloud-to-Edge InfrastructureSoC
特別注意畫紅色的幾行。軟件維護的成本實際很高,還涉及到icache的invalidation向所有核廣播的動作。
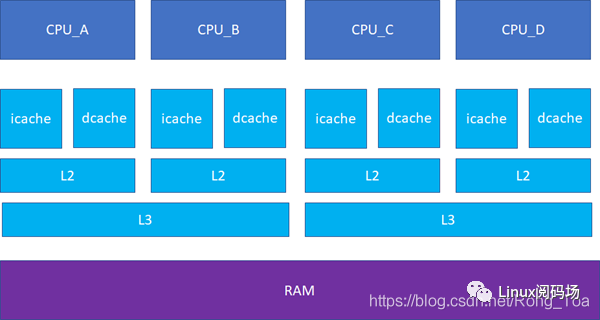
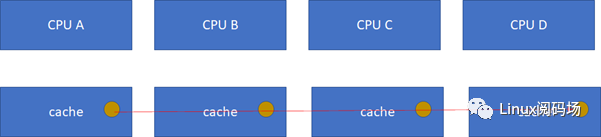
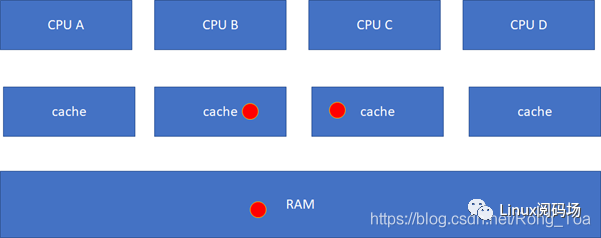
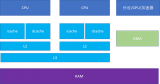
接下來的一個問題就是多個核之間的cache同步。下面是一個簡化版的處理器,CPU_A和B共享了一個L3,CPU_C和CPU_D共享了一個L3。實際的硬件架構由于涉及到NUMA,會比這個更加復雜,但是這個圖反映層級關系是足夠了。
比如CPU_A讀了一個地址p的變量?CPU_B、C、D又讀,難道B,C,D又必須從RAM里面經過L3,L2,L1再讀一遍嗎?這個顯然是沒有必要的,在硬件上,cache的snooping控制單元,可以協助直接把CPU_A的p地址cache拷貝到CPU_B、C和D的cache
這樣A-B-C-D都得到了相同的p地址的棕色小球。
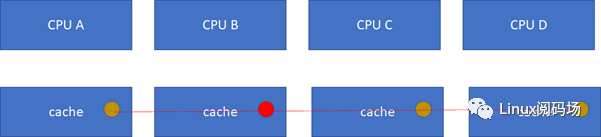
假設CPU B這個時候,把棕色小球寫成紅色,而其他CPU里面還是棕色,這樣就會不一致了:
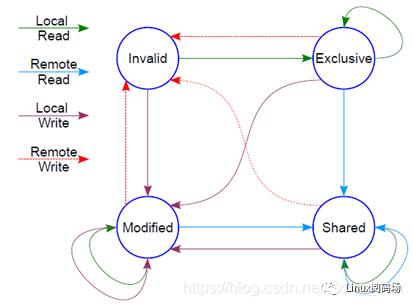
這個時候怎么辦?這里面顯然需要一個協議,典型的多核cache同步協議有MESI和MOESI。MOESI相對MESI有些細微的差異,不影響對全局的理解。下面我們重點看MESI協議。
MESI 協議
MESI協議定義了4種狀態:
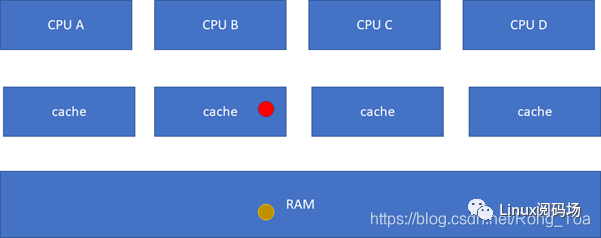
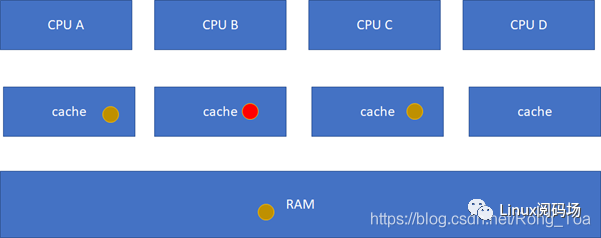
M(Modified) :
當前cache的內容有效,數據已被修改而且與內存中的數據不一致,數據只在當前cache里存在;類似RAM里面是棕色球,B里面是紅色球(CACHE與RAM不一致),A、C、D都沒有球。
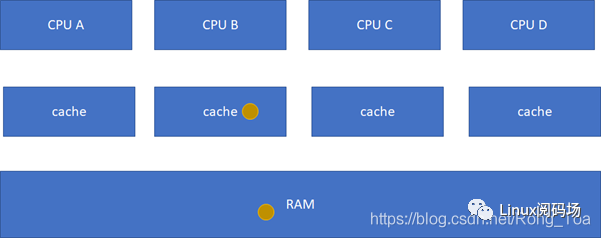
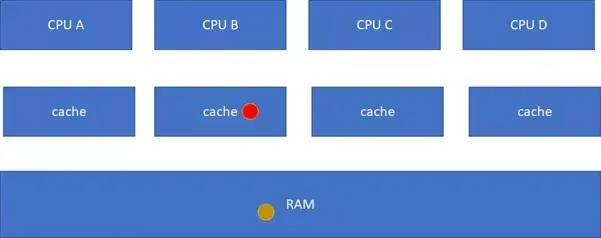
E(Exclusive 獨有的 )
:當前cache的內容有效,數據與內存中的數據一致,數據只在當前cache里存在;類似RAM里面是棕色球,B里面是棕色球(RAM和CACHE一致),A、C、D都沒有球。
S(Shared) :當前cache的內容有效,數據與內存中的數據一致,數據在多個cache里存在。類似如下圖,在CPU A-B-C里面cache的棕色球都與RAM一致。
I(Invalid) :當前cache無效。前面三幅圖里面cache沒有球的那些都是屬于這個情況。
然后它有個狀態機
這個狀態機比較難記,死記硬背是記不住的,也沒必要記,它講的cache原先的狀態,經過一個硬件在本cache或者其他cache的讀寫操作后,各個cache的狀態會如何變遷。所以,硬件上不僅僅是監控本CPU的cache讀寫行為,還會監控其他CPU的。只需要記住一點:這個狀態機是為了保證多核之間cache的一致性,比如一個干凈的數據,可以在
多個CPU的cache share ,這個沒有一致性問題;但是,假設其中一個CPU寫過了,比如A-B-C本來是這樣:
然后B被寫過了:
這樣A、C的cache實際是過時的數據,這是不允許的。這個時候,硬件會自動把A、C的cache
invalidate掉,不需要軟件的干預,A、C其實變地相當于不命中這個球了:
這個時候,你可能會繼續問,如果C要讀這個球呢?它目前的狀態在B里面是modified的,而且與RAM不一致,這個時候,硬件會把紅球clean,然后B、C、RAM變地一致,B、C的狀態都變化為S(Shared):
這一系列的動作雖然由硬件完成,但是對軟件而言不是免費的,因為它耗費了時間。如果編程的時候不注意,引起了硬件的大量cache同步行為,則程序的效率可能會急劇下降。
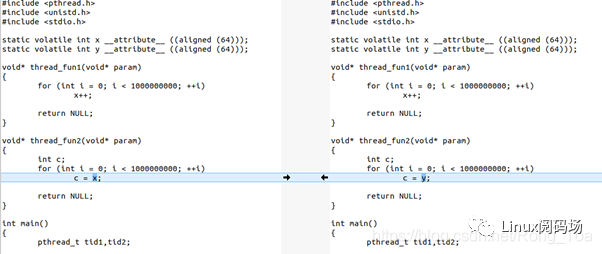
為了讓大家直觀感受到這個cache同步的開銷,下面我們寫一個程序,這個程序有2個線程,一個寫變量,一個讀變量:
這個程序里,x和y都是cacheline對齊的,這個程序的thread1的寫,會不停地與thread2的讀,進行cache同步。
它的執行時間為:
$time./a.out real0m3.614s user0m7.021s sys0m0.004s
它在2個CPU上的userspace共運行了7.021秒,累計這個程序從開始到結束的對應真實世界的時間是3.614秒(就是從命令開始到命令結束的時間)。
如果我們把程序改一句話,把thread2里面的c = x改為c =
y,這樣2個線程在2個CPU運行的時候,讀寫的是不同的cacheline,就沒有這個硬件的cache同步開銷了:
它的運行時間:
$time./b.out real0m1.820s user0m3.606s sys0m0.008s
現在只需要1.8秒,幾乎減小了一半。
感覺前面那個a.out,雙核的幫助甚至都不大。如果我們改為單核跑呢?
$timetaskset-c0./a.out real0m3.299s user0m3.297s sys0m0.000s
它單核跑,居然只需要3.299秒跑完,而雙核跑,需要3.614s跑完。單核跑完這個程序,甚至比雙核還快,有沒有驚掉下巴?!!!因為單核里面沒有cache同步的開銷。
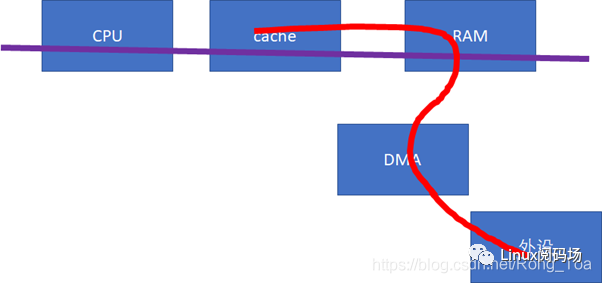
下一個cache同步的重大問題,就是設備與CPU之間。如果設備感知不到CPU的cache的話(下圖中的紅色數據流向不經過cache),這樣,做DMA前后,CPU就需要進行相關的cacheclean和invalidate的動作,軟件的開銷會比較大。
這些軟件的動作,若我們在Linux編程的時候,使用的是 streaming DMA APIs 的話,都會被類似這樣的API自動搞定:
dma_map_single() dma_unmap_single() dma_sync_single_for_cpu() dma_sync_single_for_device() dma_sync_sg_for_cpu() dma_sync_sg_for_device()
如果是使用的 dma_alloc_coherent ()API呢,則設備和CPU之間的buffer是cache一致的,不需要每次DMA進行同步。對于不支持硬件cache一致性的設備而言,很可能dma_alloc_coherent()會把CPU對那段DMA
buffer的訪問設置為uncachable的。這些API把底層的硬件差異封裝掉了,如果硬件不支持CPU和設備的cache同步的話,延時還是比較大的。那么,對于底層硬件而言,更好的實現方式,應該仍然是硬件幫我們來搞定。比如我們需要修改總線協議,延伸紅線的觸角:
當設備訪問RAM的時候,可以去snoop CPU的cache:
如果做內存到外設的DMA,則直接從CPU的cache取modified的數據;
如果做外設到內存的DMA,則直接把CPU的cache invalidate掉。
這樣,就實現硬件意義上的cache同步。當然,硬件的cache同步,還有一些其他方法,原理上是類似的。注意,這種同步仍然不是免費的,它仍然會消耗bus
cycles的。實際上,cache的同步開銷還與距離相關,可以說距離越遠,同步開銷越大,比如下圖中A、B的同步開銷比A、C小。
對于一個NUMA服務器而言,跨NUMA的cache同步開銷顯然是要比NUMA內的同步開銷大。
意識到 CACHE 的編程
通過上一節的代碼,讀者應該意識到了cache的問題不處理好,程序的運行性能會急劇下降。所以意識到cache的編程,對程序員是至關重要的。
7-zip LZMA 基準
https://www.7-cpu.com/
LZMA基準說明
LZMA基準測試顯示了MIPS等級(每秒百萬條指令)。額定值是根據測得的速度計算得出的,并通過關閉多線程選項的Intel Core 2CPU的結果進行了標準化。因此,如果您擁有Intel或AMD的現代CPU,則單線程模式下的額定值必須接近實際CPU頻率。
該測試中用于壓縮的測試數據是使用特殊算法生成的,該算法創建的數據流具有真實數據的某些屬性,例如文本或執行代碼。請注意,用于實際數據的LZMA的速度可能會略有不同。
壓縮速度 很大程度上取決于內存(RAM)延遲,數據高速緩存大小/速度和TLB。CPU的無序執行功能對該測試也很重要。
解壓縮速度在
很大程度上取決于CPU整數運算。該測試最重要的事情是:分支錯誤預測損失(流水線的長度)和32位指令的延遲(“乘”,“移位”,“加”和其他)。減壓測試具有大量不可預測的分支。請注意,某些CPU體系結構(例如32位ARM)支持可以有條件執行的指令。因此,在LZMA解壓縮代碼中的許多情況下,此類CPU可以在沒有分支的情況下工作(也無需管道沖洗)。與不支持復雜的有條件執行的其他體系結構相比,此類CPU具有一些速度優勢。亂序執行功能對于LZMA減壓并不那么重要。測試代碼不使用FPU和SSE。大多數代碼是32位整數代碼。壓縮代碼中只有一小部分也使用64位整數。RAM和緩存帶寬對于這些測試而言并不那么重要。延遲要重要得多。
對于這些測試,CPU的IPC(每個周期的指令)速率不是很高。對于現代CPU,測試IPC的估計值為1(每個周期一條指令)。壓縮測試具有對RAM和數據緩存的大量隨機訪問。執行時間中很大一部分,CPU等待數據緩存或RAM中的數據。在分支預測錯誤之后,減壓測試會進行大量的管道沖洗。如此低的IPC意味著有一些未使用的CPU資源。但是具有超線程功能的CPU可以使用兩個線程來加載這些CPU資源。因此,超線程在這些測試中提供了很大的改進。
多線程模式下的LZMA
當您指定(N *2)個線程進行測試時,程序將創建N份LZMA編碼器副本,并且每個LZMA編碼器實例都會壓縮單獨的測試數據塊。每個LZMA編碼器實例都會創建3個非對稱執行線程:兩個大線程和一個小線程。這3個線程的總CPU負載可以在140%到200%之間變化。為了在壓縮過程中提供更好的CPU負載,我們還測試了基準線程數大于硬件線程數的模式。
每個處于多線程模式的LZMA編碼器實例將壓縮任務分為3個不同的任務,其中每個任務在單獨的線程中執行。這些任務中的每一個都比原始任務簡單,并且使用更少的內存。因此,每個線程在多線程模式下都會更有效地使用數據緩存和TLB。LZMA編碼器在“多線程”模式下將“速度”的值除以“
CPU使用率”會更有效。請注意,LZMA編碼器的3個線程之間存在一些數據通信。因此,通過CPU線程之間的內存進行數據交換的帶寬也很重要,尤其是在具有大量內核或CPU的多核系統中。
所有LZMA解碼器線程都是對稱且獨立的。因此,如果使用了硬件線程數,則解壓縮測試將使用所有硬件線程。
LZMA成績
我們將基準測試結果用于32 MB詞典(控制臺版本的結果中的“ 25:”行)。如果沒有32
MB的字典結果,則將結果用于較小的字典。大多數x86測試都是在Windows
7官方二進制文件上進行的。一些測試是在64位模式下執行的。其他平臺上的大多數測試都是使用GCC編譯的p7zip進行速度優化的。新版本的7-Zip提供了改進的性能。例如,最新版本的x64平臺的7-Zip使用以匯編器編寫的用于解壓縮的優化代碼,因此評級結果可以是以前版本的7-Zip的1.7倍。但是表中的大多數結果表示在進行這些優化之前,使用舊版本的7-Zip執行的度量。如果某些CPU已通過7-Zip的新版本進行了測試,則會在7-Zip的版本號上打上標記。
審核編輯:彭靜






-
cpu
+關注
關注
68文章
10825瀏覽量
211146 -
數據
+關注
關注
8文章
6892瀏覽量
88827 -
Cache
+關注
關注
0文章
129瀏覽量
28298 -
代碼
+關注
關注
30文章
4748瀏覽量
68349
原文標題:深入理解CPU cache:組織、一致性(同步)、編程
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
cpu與cache內存交互的過程
CPU Cache是如何保證緩存一致性的?
嵌入式CPU指令Cache的設計與實現
什么是緩存Cache
什么是Cache/SIMD?
什么是Instructions Cache/IMM/ID
高速緩存(Cache),高速緩存(Cache)原理是什么?
Buffer和Cache之間區別是什么?
cache對寫好代碼真的有那么重要嗎

宋寶華:深入理解cache對寫好代碼至關重要
CPU Cache偽共享問題
CPU設計之Cache存儲器
多個CPU各自的cache同步問題





 工商網監
工商網監
評論