 會議系統設計組成及功能
會議系統設計組成及功能
01. 設計概述 1.1 設計目的
隨著疫情的出現,線上會議的應用越來越廣泛,相關的技術也越來越成熟,但當前的線上會議系統大都基于電腦和手機,便于個人使用,但由于其攝像頭拍攝方向固定,當會議一端有多人參與時,就需要每人都單獨開一個窗口才能有較好的效果,較為不便。基于此,我們設計了一個新的會議系統,以更好地適應多人會議的需求。
本系統以 Xilinx PYNQ-Z2 FPGA 為控制核心,將聲源定位與圖像識別相結 合。通過對環境聲音的實時檢測,實現對聲源目標的定位,并基于特征提取和模式匹配的方法對目標進行圖像識別,根據提前訓練的數據模型,在顯示屏上框出 目標并顯示目標的個人信息。同時,也可以通過 socket 通信將識別后的圖像信息 直接發送至客戶端(PC 機等)顯示,從而實現遠程會議的效果。
1.2 應用領域
本系統理念較為新穎,將聲源定位與圖像識別相結合,并在 FPGA 上實現, 使得系統整體體積與功耗都較小,可以在各種線上會議中使用,在疫情防控常態 化的當下,應用前景十分廣泛。例如,該系統可以用于在企業之間進行的大型會 議,聲源定位功能可以使攝像頭實時跟蹤講話人,并對其進行識別,顯示人員信 息,這就使得只使用一個客戶端就可以較好地實現多人會議,節省資源;另外, 該系統在多方參與的學術會議或國際會議中也都比較適用。
1.3 主要技術特點
(1)采用四麥克風陣列采集聲音信息,并通過硬件電路將麥克風陣列輸出 PDM 信號直接轉換為 I2S 信號送入 FPGA 中處理。 (2)使用 python 編寫的 TDOA 算法進行聲源定位,即先通過 GCC-PHAT 算法 得出不同麥克風芯片接收到聲音的時延,再通過幾何關系計算出聲源所在的角度。 (3)采用 Haar 特征提取算法檢測人臉區域,速度快,識別率較高;采用 LBPH 特征識別算法對數據集中的圖片進行訓練,訓練完成后,建立標簽與真實人員姓 名的直接映射表,從而實現身份識別。 (4)基于 socket 通信,使用 UDP 通信協議,將圖像從 FPGA 中實時傳輸到客戶 端 (PC 機等)中顯示,從而實現遠程會議的功能。 1.4 關鍵性能指標
(1)聲源定位速度與準確率 本系統在環境噪聲較小的情況下可在 1 秒之內完成聲源定位,準確率幾乎為 100%;在環境噪聲較大的情況下定位時間會稍長,在 2 秒左右也基本可以完成 定位,準確度在 90%以上。 (2)人臉檢測與身份識別速度與準確率 本系統人臉檢測速度較快,當人臉進入攝像頭中部區域后就可立即框出 人臉,在攝像頭中部區域人臉檢測準確率幾乎為 100%;身份識別速度較人臉檢 測稍慢,但識別時間都在 0.5s 左右,當人員處于拍攝區域中部時識別準確率較 高,在 90%以上,當人員處于拍攝區域邊緣時準確度較低,但也基本都在 80%以 上。 (3)數據無線傳輸速率與延時 本系統無線數據傳輸時,客戶端(PC)接收到圖像信息的延時在 1s 左右,延時 較低;其傳輸速率也較快,顯示的圖像基本都在 3 幀/秒以上。 1.5 主要創新點
(1)采用了數字麥克風芯片,抗干擾能力較強,且在使用時外圍電路簡單;使 用四芯片麥克風陣列采集聲音信號,使得其在 360°平面內對聲源方向角度的分 辨率大大提高。 (2)采用 AC108 芯片將 PDM 信號轉換為 I2S 信號,再送入 FPGA 中處理。 (3)采用 TDOA 算法,并在高速、并行的 FPGA 中實現,使得聲源定位的速度 較快,延遲較低。 (4)使用舵機搭建了水平 360°云臺,使攝像頭可以更方便地跟蹤聲源。 (5)系統支持現場錄入人員并學習,且識別率較高。 (6)基于 socket 通信,實現將圖像信息從 FPGA 中實時傳輸到客戶端(PC 機等) 顯示的功能。 (7)該會議系統功耗低、體積小、易安裝并且可供多人在同一客戶端使用。
02. 系統組成及功能部分
2.1 整體介紹
本系統由麥克風陣列模塊、FPGA 處理器模塊、攝像頭模塊、遠程數據傳輸 模塊和顯示模塊共同組成。麥克風陣列模塊在檢測聲音信號后,將轉換后的 PCM 碼送入 FPGA 處理器模塊處理,實現對聲源目標的定位;攝像頭模塊在接收到 FPGA 處理器模塊發出的位置信號后,控制攝像頭轉向聲源方向,并將攝像頭拍 攝到的圖像信息傳入 FPGA 處理器模塊進行處理,識別其是否為檢測目標,若為 檢測目標則顯示檢測到的人員信息;若沒有檢測到相關目標,則重新進行聲源定 位。圖 2.1 為系統整體框圖。
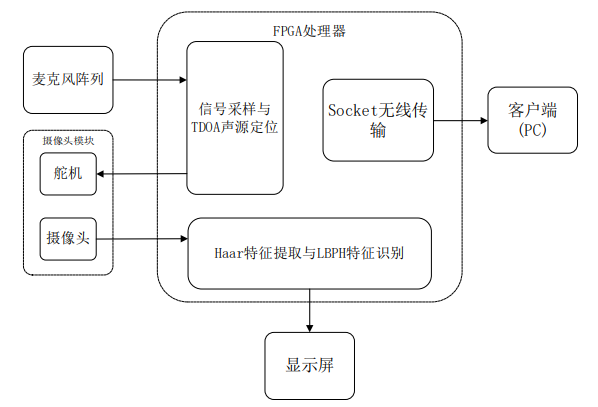
▲圖2.1系統整體框圖
2.2 各模塊介紹
2.2.1 麥克風陣列模塊
系統采用由 KNOWLES 公司制造的性能優良的 MEMS 數字麥克風芯片 SPU0414HR5H,可識別頻率在 100Hz~10kHz 范圍內的聲音信號。選用四芯片麥 克風陣列采集聲音信號,輸出四路 PDM 信號到 AC108 芯片中進行解調,輸出 PCM 信號送入 FPGA 中進行處理。其實物圖如下圖所示:

▲圖2.2.1麥克風陣列
2.2.2 FPGA 處理器模塊
處理器模塊主要采用 Xilinx PYNQ-Z2 開發板,其由 650MHz 雙核 Coryex-A9 處理器與 FPGA 組成。PYNQ-Z2 開發板支持 Python 語言開發,也支持使用傳統 的 Xilinx Vivado 開發工具流程平臺開發編寫 Verilog 來開發嵌入式系統應用。同 時,PYNQ-Z2 開發板也具有極其豐富的外設接口,如千兆以太網口、USB 接口、 UART 接口、HDMI 輸出/輸出接口等常用接口,還提供了兼容 Ardunio、RPi、 Pmod 的擴展接口。
聲源定位算法和圖像識別的算法均在處理器模塊中實現。
(1)TDOA 聲源定位算法
TDOA 定位算法是一種利用時間差進行定位的方法,通過測量信號到達的時 間,可以確定信號源的距離,利用信號源到各個信號接受點的距離,就能確定信 號的位置。采用 GCC-PHAT 算法,先對輸入 FPGA 中的 PCM 信號通過 I2S 協議 采樣,得到四路數字信號,以兩個信號為一組,采用廣義互相關的方法求出時延, 即求兩路信號的互頻譜,得出其頻譜峰值索引,即為聲音到這兩路信號采集點的 時延。得到時延后,根據幾何關系,即可求出聲源與兩對角信號采集點連線的角 度,進而得到攝像頭需要旋轉的角度信息。
(2)Haar 特征提取算法
系統使用 Haar 特征提取的識別算法進行人臉檢測。Haar 特征提取過程是將 一副圖像中所有黑色矩形框和白色矩形框中所包含的全部像素進行差值運算,得到該圖像的 Haar 特征值,但由于一副圖像中包含的 Haar 特征的個數較多,對于其中矩形特征的特征值的提取相對比較復雜,因此采用積分圖像的轉換來縮減其計算量,以提高運算速度。
在提取出 Haar 特征后,將其分別轉化為弱分類器,然后根據弱分類器處理樣本數據,根據其正確分類樣本的情況來改變其權值大小,進而產生多個強分類器,然后將這些訓練產生的強分類器繼續迭代,最終獲得一個識別率較高的最終強分類器,從而實現對人臉區域的準確識別。
(3)LBPH 特征識別算法
系統采用了基于 LBP(局部二值模式)特征的 Adaboost(級聯分類器)進行人臉 識別。LBP 是典型的二值描述算子,其更多的是整數計算,可以通過各種邏輯操 作對運算過程進行優化,因此效率較高。此外,通常光照對圖像中物體的影響是 全局的,即圖像中物體的明暗程度通常是往同一個方向改變的,只是改變的幅度 會因距離光源的遠近而有所不同,故圖像中局部相鄰的像素間受光照影響后的相 對大小不會改變,LBP 特征也因此對光照具有比較好的魯棒性。Adaboost 是一種 迭代算法,其核心思想是針對同一個訓練集訓練不同的弱分類器,然后把這些弱 分類器集合起來,構成一個更強的最終分類器。Adaboost 算法系統具有較高的 檢測速率,且不易出現過適應現象。
2.2.3 攝像頭模塊
采用 GUCEE 攝像頭,1200 萬像素,動態分辨率支持 1920*1080,其機身小 巧,易于安裝,適合在各種環境下使用。同時,系統搭建了一個攝像頭云臺,使 用一個舵機來控制云臺上攝像頭的轉向,使其能在水平 360°范圍內跟蹤聲源方位。
2.2.4 遠程數據傳輸模塊
系統基于 socket 通信,編寫 python 創建 UDP 服務端程序,在同一局域網下 可以將圖像信息直接從 FPGA 中發送到任一客戶端(PC 機等)中,客戶端只需打 開使用 python 編寫好的上位機程序,即可接收到信息并同步顯示。其無線傳輸延遲較小,傳輸速度較快且輸出圖像較為清晰。2.2.5 顯示模塊 采用 Creatblock7 寸 iPS 高清顯示屏,使用 FPGA 中的顯示模塊將識別后的 圖像直接顯示在顯示屏上。
03.
完成情況及性能參數
3.1 聲源定位
系統可較好實現 360°聲源定位,在環境噪聲較小的情況下,識別很精準, 誤差不超過 5°,在有一定噪聲干擾的情況下,其識別度也能穩定在一定水平, 識別誤差不超過 15%。下表為聲源定位測試結果:
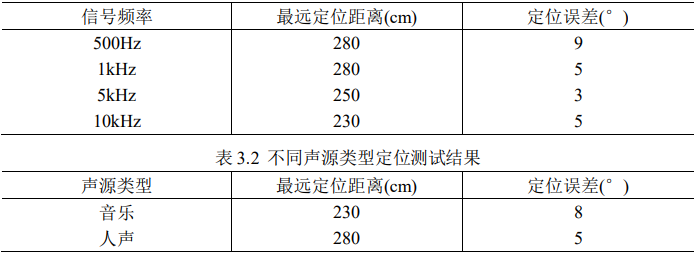
▲表3.1 單頻聲源定位測試結果
3.2 身份識別與顯示
系統能夠很好地實現人臉檢測與身份識別功能,且運算速度較快,在識別到 人臉后能夠迅速框出人臉,并將其人臉特征與數據庫中錄入特征進行匹配,若匹 配到相應的人臉信息則直接在方框上方顯示當前人員信息,若未匹配到相應人臉 信息,則只框出人臉。人臉檢測識別率很高,識別速度較快;身份識別速度較快, 在單人識別時成功率較高,達到 90%以上,當同時有多人在識別范圍內時識別準 確度會受到影響,但也基本在 80%以上。識別后的圖像可以清晰地在顯示屏上顯 示,并且顯示延遲較小。下圖為人臉檢測與身份識別顯示畫面:

3.3 無線數據傳輸
系統通過 socket 通信,可以將圖像信息直接通過局域網傳輸到客戶端中,這 里使用 PC 機作為客戶端,在運行上位機程序后即可接收到從 FPGA 中實時傳輸的圖像。通過 FPGA 上的撥碼開關可以控制傳輸圖像的模式,即實時顯示模式和 身份識別模式。下圖為 PC 機接收到的圖像:

04.
完成情況及性能參數
4.1 可擴展之處
(1)當前系統聲源定位在特定位置處定位誤差會略大,同時,在環境噪音較大 的情況下,也會對聲源定位造成一定影響。可通過增加麥克風數量,改變麥克風陣列結構或改進聲源定位算法等進一步提高系統聲源定位的精度與抗干擾性。
(2)拓展圖像處理功能,將攝像頭拍到的圖像降噪,并根據圖像的具體情況自 動將圖像的亮度和對比度等特性調節到合適的值。
(3)當前系統無線數據傳輸功能只能將FPGA拍攝到的圖像數據發送到和FPGA 連接在同一局域網內的客戶端中,可以進一步完善無線傳輸功能,使得 FPGA可以直接將圖像數據發送到外網的客戶端中,增加系統的實用性。
(4)優化圖像處理算法,進一步提高人臉識別算法的準確度與魯棒性。
-
Xilinx
+關注
關注
71文章
2163瀏覽量
121001 -
圖像識別
+關注
關注
9文章
519瀏覽量
38233 -
會議系統
+關注
關注
1文章
44瀏覽量
11700
原文標題:基于 FPGA 的會議系統設計
文章出處:【微信號:HXSLH1010101010,微信公眾號:FPGA技術江湖】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論