 分享微博在特征Embedding建模方向做的一些工作
分享微博在特征Embedding建模方向做的一些工作
導讀:隨著深度學習在推薦系統應用的發展,特征 Embedding 建模的重要性已經成為共識,同時海量特征的稀疏性及參數量過大是必須面對的難題。今天會為大家分享微博在特征 Embedding 建模方向做的一些工作。
今天的介紹會圍繞下面五點展開:
特征建模的必要性
特征建模的三個技術方向
卡門檻:微博在特征重要性方向的工作
擠水分:變長特征 Embedding
補營養:提升特征表達質量
01 特征建模的必要性
1. 三大AI方向的領域特
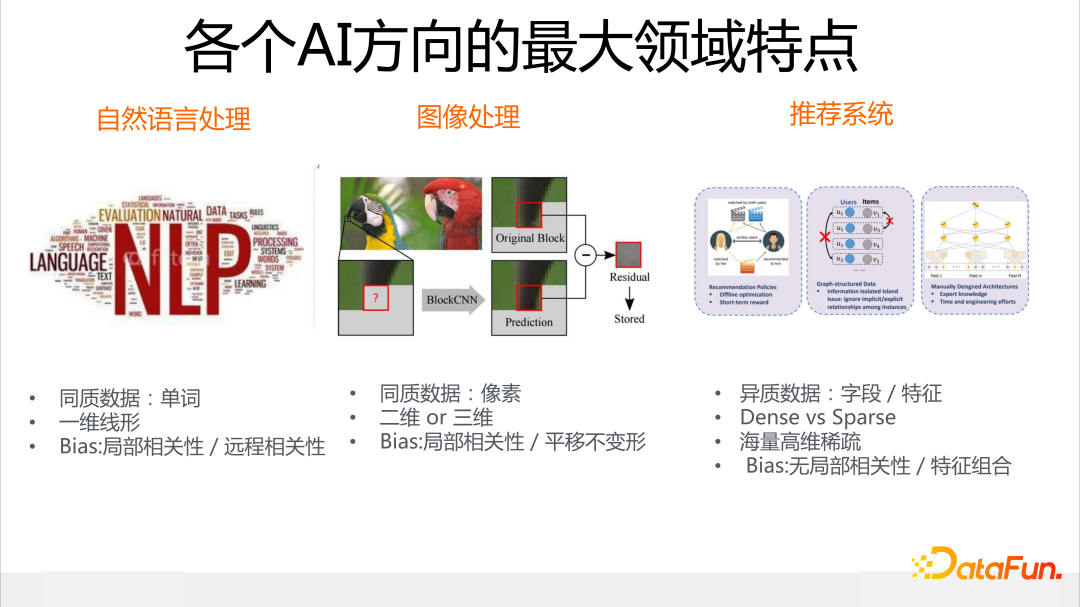
在討論特征建模之前,我們先來對比一下不同 AI 應用領域中數據分布的特點,這里以最常見的自然語言處理、圖像處理和推薦系統為例來說明。
首先我們對比自然語言處理和圖像處理:NLP 最基本的數據元素是單詞,每個單詞有一定的含義,可能指代某個實體;圖像處理最基本元素是像素,因為粒度太細,單個像素并沒有實際含義。所以在輸入信息基本單元粒度上,自然語言處理比圖像處理更抽象,更有具體含義和所指。
在數據的組織結構上看,自然語言處理的語句是一維線性的,同時具備信息的局部相關性和遠程相關性特點:局部相關性指的臨近單詞之間語義相關度高,遠程相關性舉個例子:“雖然“….”但是”是個表達語義轉折關系的結構,但是它們在句中的距離可能很遠,但是這是個重要特征。
而圖像是二維/三維立體結構,數據具有局部相關性和平移不變性等特點:所謂“局部相關性”,就是剛才說的,單個像素無含義,但是相鄰一片區域的像素連在一起就能體現物體特征。平移不變性舉個例子,比如上圖里的鳥頭,不論這個鳥頭出現在圖片哪個位置,你都應該看出來它是個鳥頭,這就是平移不變性的含義,除此外還有旋轉不變性、遮擋不變性等很多特性。
在這些數據的領域特點下,我們回顧這兩個領域模型的發展歷史,你會發現 RNN 結構天然匹配 NLP 數據的一維線形以及局部和遠程相關性等特性,所以這是為何幾年前深度學習進入 NLP 的時候,RNN 快速普及的根本原因。圖像處理里 CNN 則天然適合對局部相關性和各種不變性建模,這也是為何 CNN 快速占領圖像領域的根本原因。
從這里可以看出,我們在設計模型的時候,應該重點考慮領域數據的特性,那些匹配領域數據特性的模型,就容易取得優勢。目前 Transformer 統一了 NLP 和圖像處理領域,那么很自然,我們就可以推論:Transformer 不僅匹配上述兩個領域的數據特點,而且比 RNN 和 CNN 匹配度應該更高。
我們的主題是推薦系統,那么我們再來看推薦領域數據分布有什么獨有的特點。首先,和NLP 及圖像處理不同,推薦領域數據是異質的表格數據,一個實例一般由離散的字段構成,字段可以是數值型的,也可以是離散形態的,字段之間可能有關系,也可能完全無關。
其次,推薦數據輸入特征之間沒有局部相關性,對于平鋪特征類型的任務,并不是兩個特征在輸入里挨得越近,就越有關聯,它們之所以挨在一起,完全是隨機作用(當然,行為序列具有局部相關性)。再者,可能也是推薦數據最大的特點,是特征的海量高維稀疏,關于它的具體含義我們后面會說。
另外,特征組合對于推薦來說是至關重要的數據特點,這個可以理解為遠程相關性。這些都是推薦領域數據獨有的特點。那么,什么樣的模型才匹配推薦領域的數據特點呢?這也是我自己一直在思考的問題,我們做的一些工作可以看作對這個問題的部分回答。
2. 推薦系統數據的稀疏性
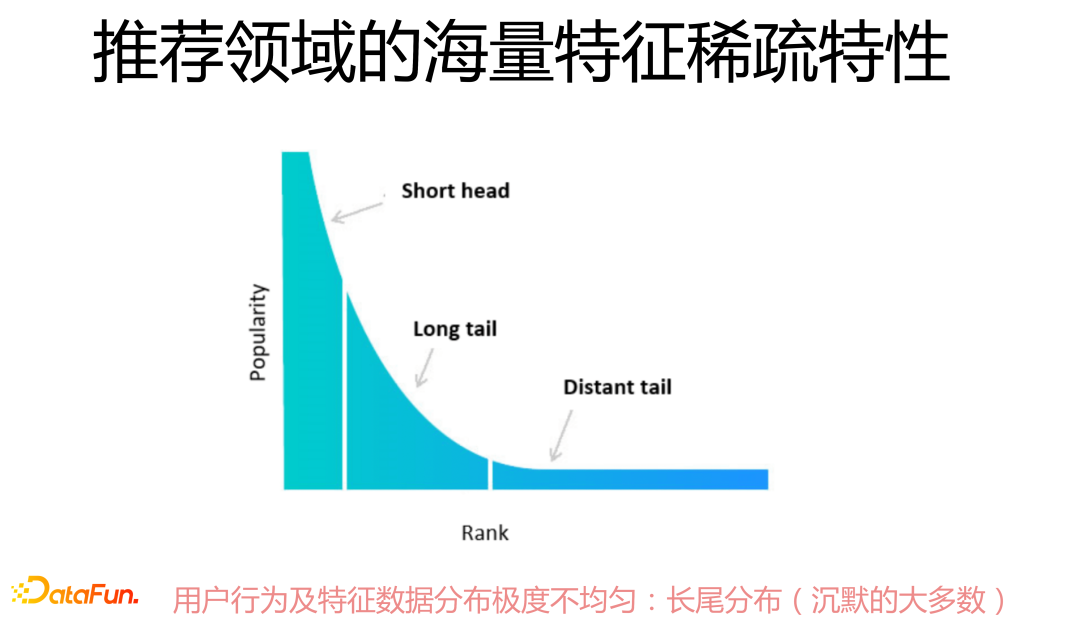
推薦領域特征的海量稀疏性,主要體現在用戶行為及特征數據分布極不均勻,極少量高頻特征在數據總體中占比很高,長尾現象異常嚴重,對于絕大多數行為特征或其它特征來說頻次極低,所以就沒什么信息量,或者包含大量噪音數據,這就給上層模型建模帶來很大難度。
3. 特征建模的必要性
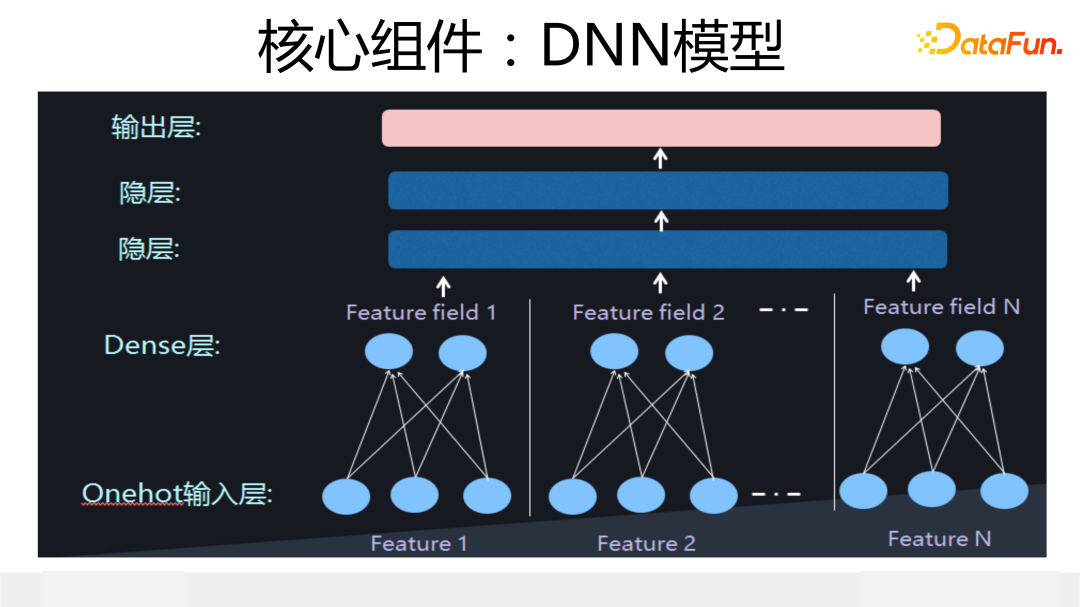
在介紹后續內容前,我們先簡單介紹下 DNN 模型,因為后面很多內容都要以它為基礎。上圖展示了典型的 DNN 模型結構:輸入實例由 n 個特征構成,每個特征由 one-hot 形式轉換成特征 Embedding,這個映射過程需要學習獲得,然后特征 Embedding concat 到一起輸入到上層 DNN 結構,DNN 結構一般由 2 到 3 層 MLP 構成。
DNN 模型是最簡單的深度 CTR 模型,也是大多數其它深度 CTR 模型的關鍵組件,但是如果你愿意好好調試,會發現在推薦領域,它是性能很好的強 baseline 模型,大量所謂新模型,效果未必能打過它。

我們從參數占比來說明為何特征建模是重要的,具體網絡結構配置數據可參考上圖,在這個配置下,你把計算結果列出來一看就明白了:在 DNN 結構中,包含 200 億參數量,特征 Embedding 占總體參數量的 93.3%,上層 MLP 結構參數量只占 6.7%。
也就是說,深度 CTR 模型里,特征 Embedding 占據了參數總量的絕對多數,理論上特征處理好壞對模型整體影響應該比較大。在真實應用場景中,深度 CTR 模型一般都是“過參數化”(over-parameter)的:模型參數的規模遠遠超過訓練數據規模,比如上面 200 億的模型,大概率你沒那么多訓練數據來訓練它。
而深度模型這種天然的“過參數化”傾向導致它天然是個容易引起“過擬合”問題的模型結構,而造成這種現象的,主要原因是占比大的特征 Embedding。當然,你可以調整上層 MLP 大小,比如增加 MLP 的深度和寬度,但是這樣做盡管對模型效果有影響,但是影響很小。所有這些現象或特點,主要原因在于深度模型中包含了海量的特征 Embedding 參數量。
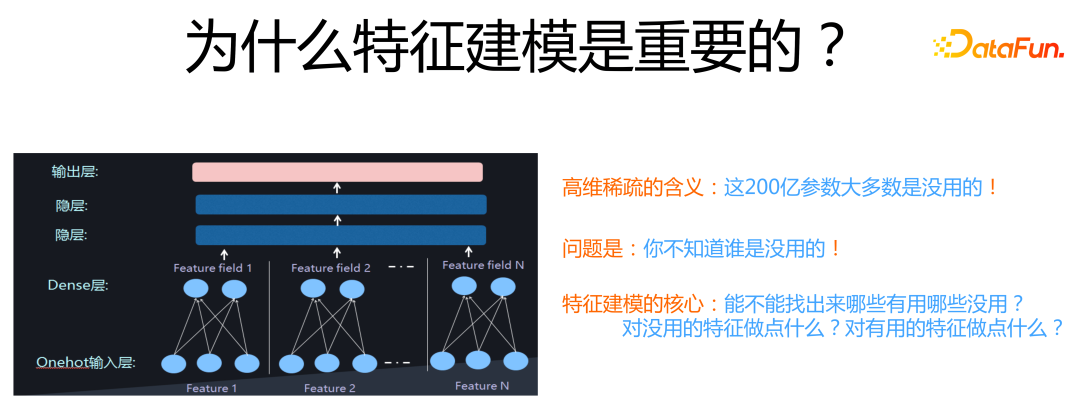
特征參數量雖然看著非常巨大,容易引起過擬合問題,但是,其中大量特征 Embedding其實是沒什么用的。你可以試著逐步拋掉低頻特征,在實驗中可以發現,開始把極低頻特征比如僅僅出現 1 次 2 次的特征拋掉,模型效果會逐漸上升,到了一定數量比如出現 10 次的特征也拋掉,模型效果就開始下降。
這說明對于大量低頻特征,引入它們的副作用要大于正向作用。如果我們能知道哪些特征沒用,把它們拋掉,無疑不僅能提升模型效果,還能大規模減少模型參數,一舉兩得。但是問題的關鍵是:面對如此大量特征,我們并不知道哪些是有用或者無用的。
所以,特征建模的核心問題就是:我們能否通過技術手段,知道哪些特征是有用的?哪些是沒用的?對于模型認為有用的特征我們可以做些什么事情?模型認為沒用的特征,我們又可以做些什么事情?
02
特征建模的三個技術方向
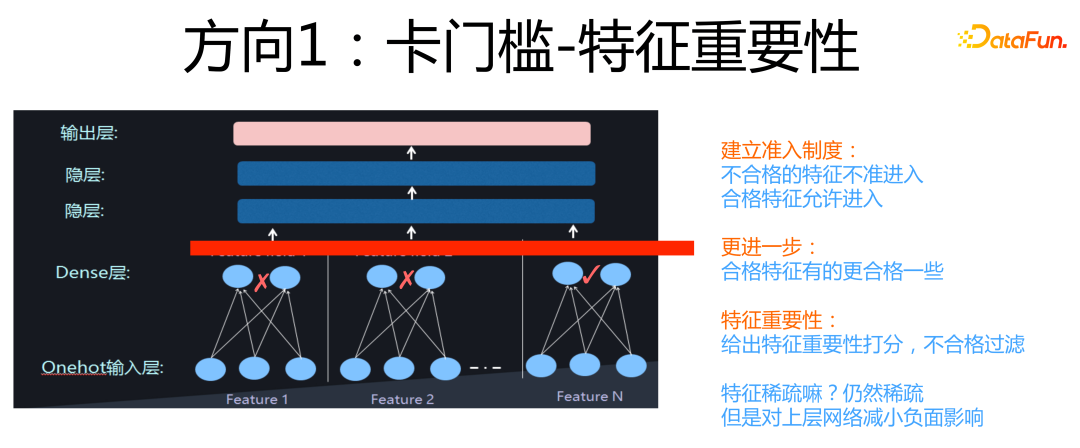
這個部分,會簡單說明下特征建模三個方向的基本思路,我們首先來看“卡門檻”。
所謂“卡門檻”,意思是我們可以在特征 Embedding 層和上面的 DNN 層之間,加一個門控層,這個門控來決定哪些特征可以進入上層的 DNN 部分,哪些特征不能進入后續網絡結構,直接在門控層就被過濾掉。如果進一步思考,其實對于允許通過的特征,這個門控機制還可以區分不同特征的重要性,對于重要特征給予大權重,不那么重要特征給予小的權重。
這就是“卡門檻”的基本思路,它的核心思想是過濾掉對優化目標起負面作用的大部分稀疏特征,同時通過大權重凸顯重要特征的作用。如果用“教育學生學習”來打個比方,類似我們現在的高考制度,劃出統一分數線,只有過線的學生才能通過高考去上大學。
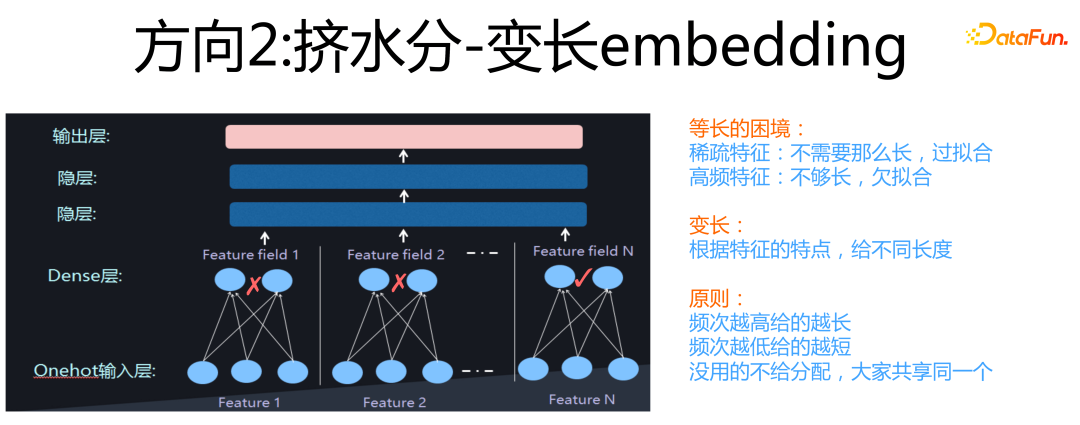
第二個方向是“擠水分”。
它的含義是:通常我們會給所有特征分配相同長度的Embedding size,但是很明顯這么做是不合理的。因為對于大量稀疏特征,因為沒有什么知識可以學習,如果你給它分配的 Embedding size 越大,它越容易出現過擬合的現象;而對于那些高頻特征,你應該給它更長的 Embedding,因為它有很多知識需要編碼,如果分配的太短,則會出現欠擬合問題,就是 Embedding 容量不夠大,放不下那么多要學習的知識。
所以,合理的策略應該是:對于特征采取變長 Embedding,對于中高頻特征,分配長的 Embedding,對于大量低頻特征,分配短的 Embedding。這就是在擠稀疏特征 Embedding 的水分,這是我把它稱為“擠水分”的原因。如果繼續拿上面的學生教育做比喻,那么“擠水分”就類似學校里面給不同學生設置快慢班,學的快的學生進快班,獲得更好的教育資源,學的慢的學生進慢班,因材施教。
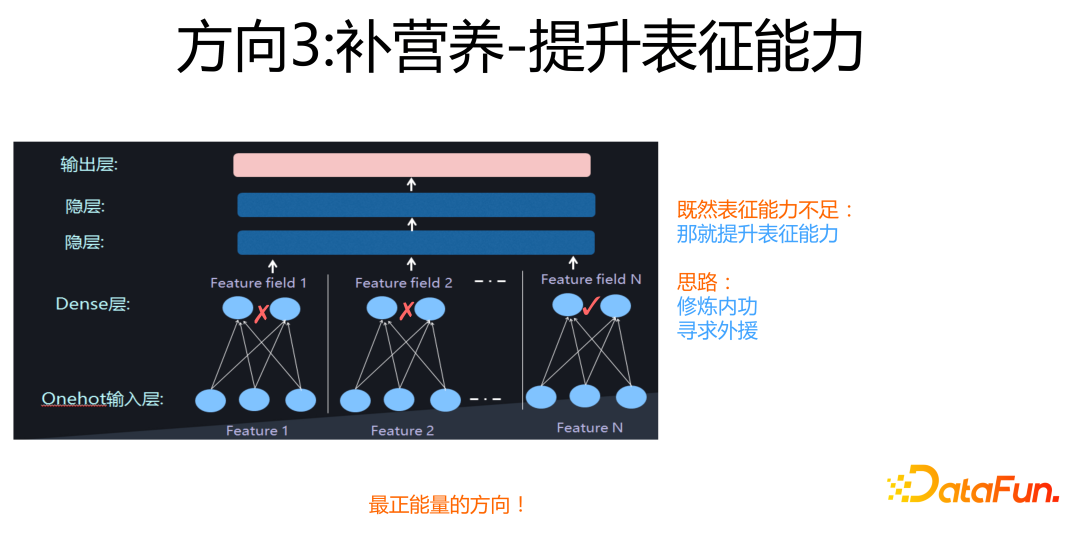
第三個方向是“補營養”。
這是一種最正能量的技術方法,它的意思是:既然很多稀疏特征,它沒太多可學習的內容,導致特征稀疏,表達能力不足,那么我就想點辦法,來提升它的特征表達能力。具體做法又可以細分為“修煉內功”和“尋求外援”,這里暫不展開,后面會用具體例子解釋這兩種做法的思路。如果繼續拿學生教育做類比,那么“補營養”類似學校里面專門給差生進行針對性的補課,來提高他們的學習成績,所以說這是最“正能量”的一種做法。

上述內容是特征建模的主要技術方向,接下來分享一些我個人的想法。
我們最近 4 年來,在排序模型方面,重心放在特征建模方向,尤其是聚焦在“特征重要性”方面,可以說這是我們做 Rank 模型的核心主線。那么,為什么我們在這里投入這么大精力呢?首先,前面介紹過,我們做模型,一定要結合具體領域的業務特性,以及領域內數據的獨有特點。
具體到推薦系統,我個人認為海量高維的稀疏特征以及特征組合,這兩個是推薦領域最主要的領域特點,所以我們把重心放在特征建模這個方向。其次,我認為相比模型結構來說,特征建模更重要。我一直相信的一點是:盡管最近一年來圖像和 NLP 領域已經被 Transformer 統一,推薦系統暫時沒有類似這樣有統治力的模型,但是如果未來某天出現了這種突破性的模型,我覺得應該是在特征建模方向,而不是模型結構的改進和革新。
那為什么我們又聚焦在特征重要性方向上呢?原因是在 2019 年之前,整個行業就沒人做“卡門檻“這個方向,FiBiNet 中的 SENet 模塊應該是第一個做這個事情的 CTR 模型。有些介紹文章把 FiBiNet 里的 SENet 僅看作一種 Attention 具體做法,也有拿 AFM 模型放在一起來說的,我認為這種理解是片面的,這并不能體現引入 SENet 的本質思想,關鍵你要看它用在哪里,目的是什么,具體怎么做其實是次要的,上面介紹的“卡門檻”才是它的本質思想。
03
卡門檻:微博在特征重要性方向的工作
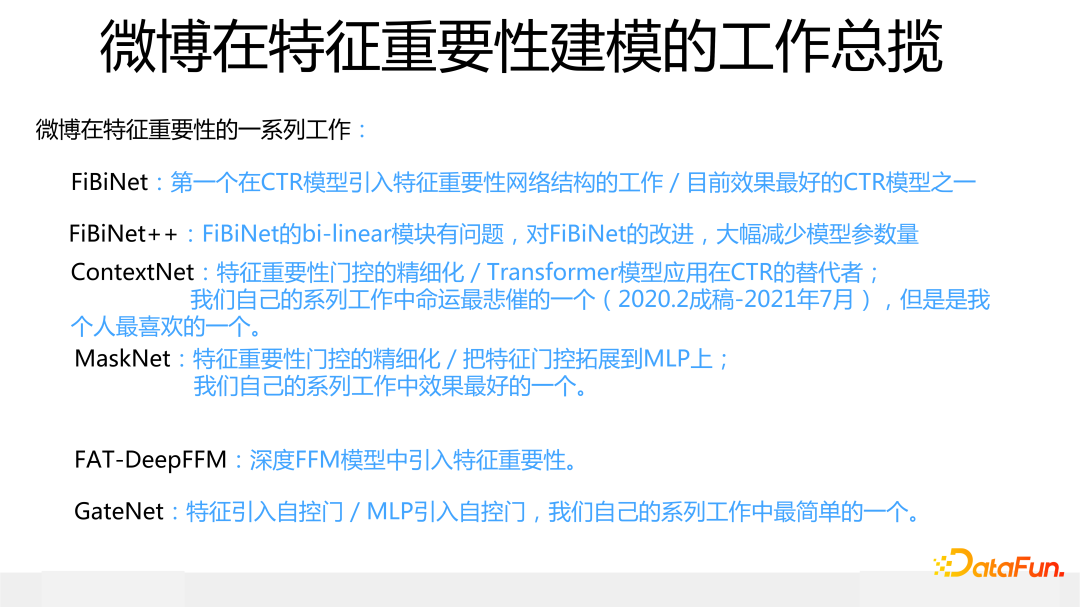
這里對最近幾年我們在特征建模方面做的工作做個概述,節奏大約是一年提出 1 到 2個新模型。最近幾年微博在 Rank 模型方面做的主要工作如下:
FiBiNet 是第一個引入特征重要性子網絡結構的深度 CTR 模型,也是目前效果最好的 CTR 模型之一。
FiBiNet++ 是對 FiBiNet 模型的改進,主要目的在于減少 bi-linear 模塊設計不合理帶來的暴增的參數數量。
ContextNet 是對 Transformer 模型進行改造,將之應用在推薦的改進模型,在特征重要性模塊加入了更精細的特征門控方式,這是我個人比較喜歡的一個模型。
MaskNet 是 ContextNet 的副產品,將特征門控拓展應用到 MLP 上。這是除了我們今年做的一個還未公開的新模型外,我們自己做的模型里效果最好的。
今天主要介紹上述幾個模型,至于 FAT-DeepFFM 和 GateNet,也是兩個特征門控相關工作,時間原因今天就不介紹了,感興趣的同學可以搜對應論文看看。

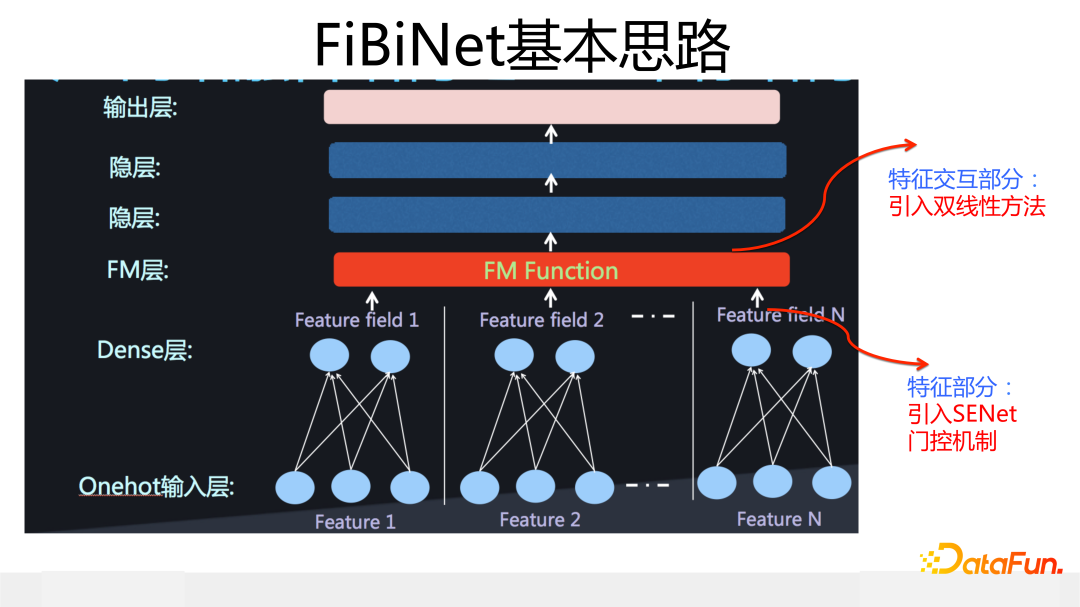
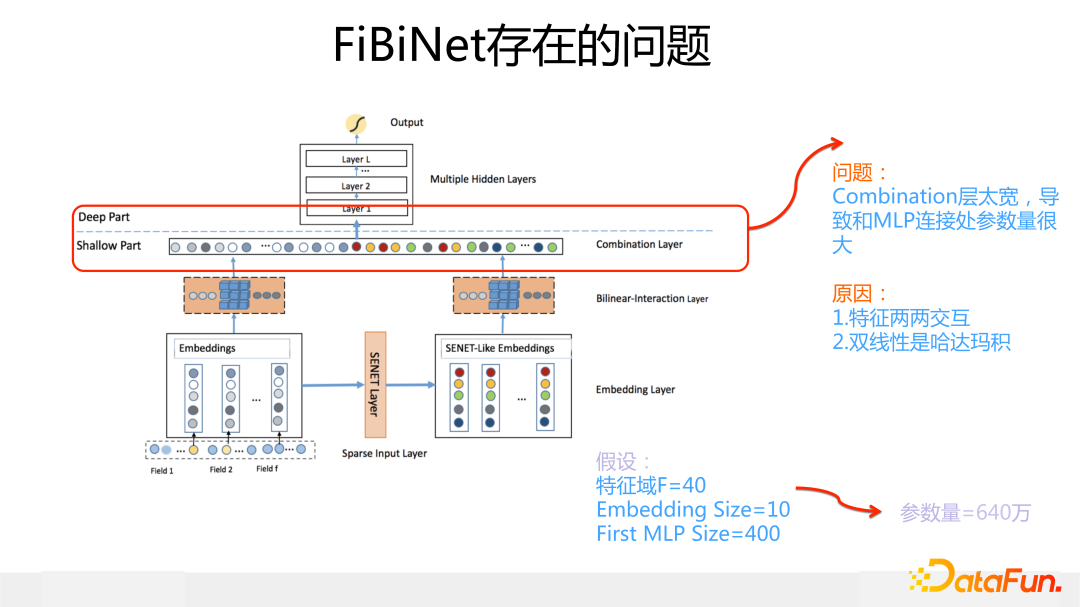
FiBiNet 是我們 2018 年設計、發表在 Recsys2019 的工作。相對其它模型,它的創新點在于引入兩個獨立可插拔的模塊:一個是用 SENet 作為特征重要性門控,二是引入雙線性模塊來改進特征交互方式。這對應下圖網絡模型結構下方兩個分支中標為橙色的三個模塊。
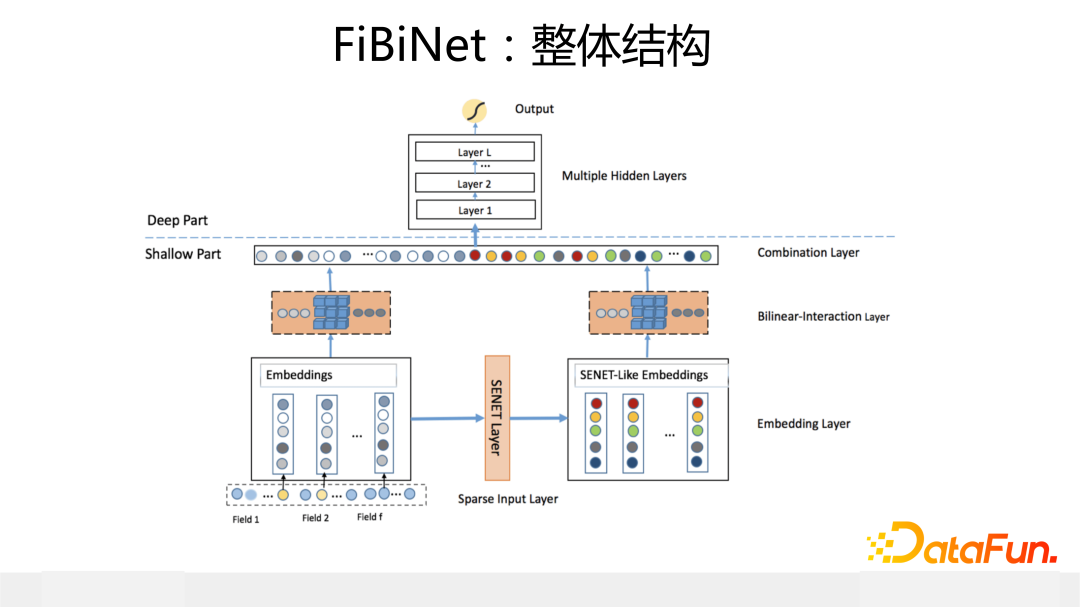
SENet 最早 2018 年在圖像處理中提出的,下面介紹一下它在推薦系統中的應用。
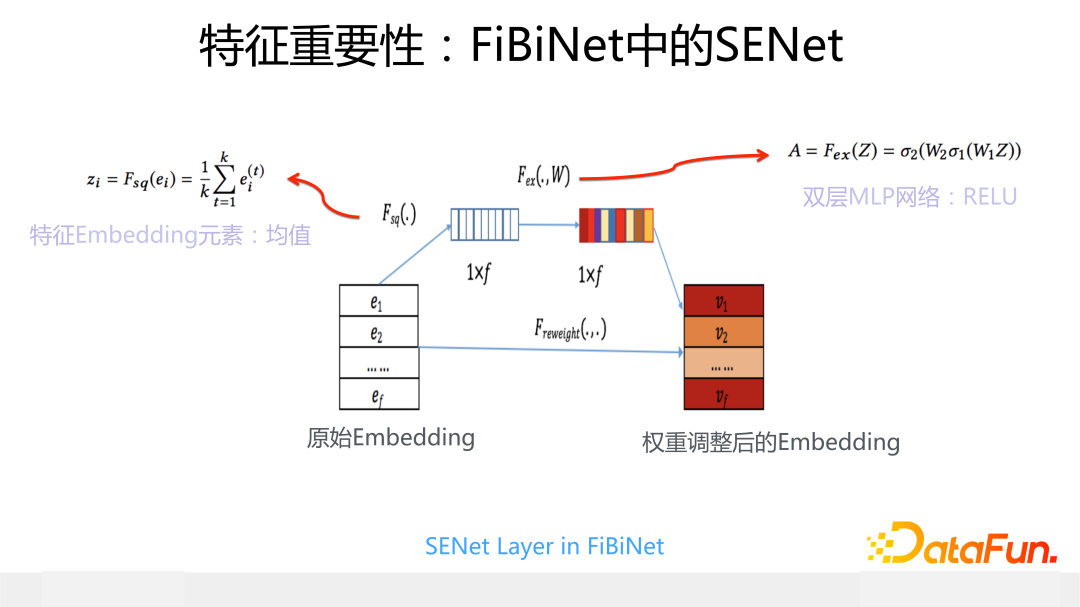
我們在推薦中引入 SENet 的主要目的是希望引入一個特征門控系統,它可以給輸入的每個特征動態打權重,如果是沒什么用的稀疏特征,我們希望這個權重是 0,這等于消除掉了這個特征的負面影響,而如果是重要特征,則希望 SENet 打出一個大權重,強調下這個特征很重要。基本出發點就是之前講過的“卡門檻”的作用。
具體而言,其模型結構參考上圖,對于當前輸入的每個特征 Embedding,取出一個代表 bit 位,這里取 Embedding 中根據每一位求出的均值作為代表位,假設輸入有 f 個 field 或 slot,則有 f 個代表 bit,作為后續雙層 MLP 網絡的輸入。第一層 MLP 是個窄網絡,因為輸入維度 f 一般比較小,實際場景中基本也就是 100 到 200 之間,所以這層 MLP 可以設計的比較窄,就不容易過擬合;第二層 MLP 的輸出結果就是每個特征的重要性得分。我們原始版本的 SENet中,非線性函數都是用的 Relu,你會發現很多特征打出來的權重都是 0 分,這樣就達到了前面說的“卡門檻”的目的。從網絡結構可以看出,SENet 是個輕型網絡,額外引入的參數很少,運算速度也比較快,作為一個可插拔的門控模塊是比較輕巧的。
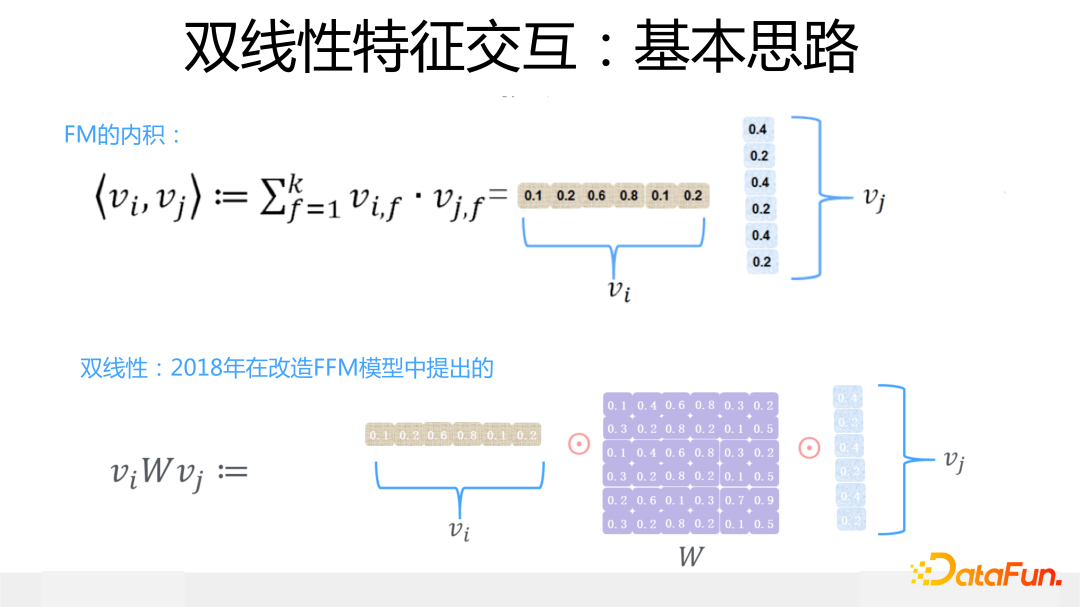
另外一個是雙線性特征交互模塊,這是我們 2018 年在改造 FFM 模型時候想出來的改進模型,是對 FFM 模型的簡化或者是 FM 模型的復雜化,看你站在哪個角度來看了。雙線性交互的核心思想是:在 FM 模型基礎上,當任意兩個特征交互的時候引入一個參數矩陣 W,通過這個參數矩陣來更精細地表征特征交互過程。
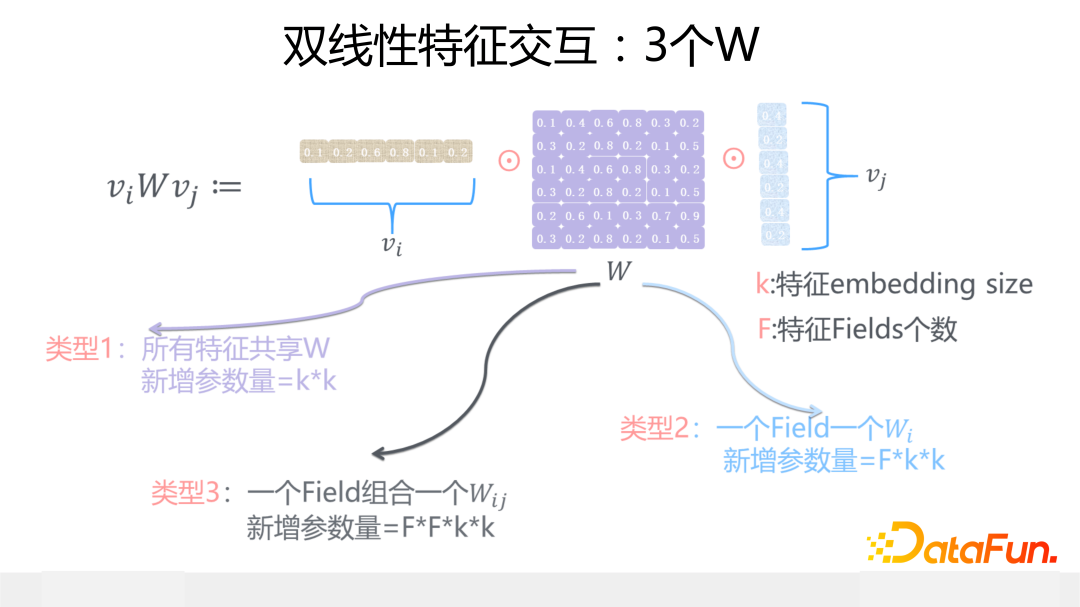
這個參數矩陣 W,有三種做法:一種是所有特征共享同一個 W,這種方式的 W 引入的新參數量是極小的,幾乎可忽略不計;第二種是每一個特征域(Field 或 Slot)內的特征共享同一個 W;第三種最細致,是每種特征域組合,共享一個 W。
這三種不同做法,越來越精細,表達能力越來越強,對應的參數量依次升高,跑起來也會越來越慢,具體用哪個要看具體場景。關于雙線性這里不展開介紹了,對此感興趣的同學,推薦看看小紅書王樹森老師在 B 站的解說視頻(SENet 和 Bilinear 交叉:https://www.bilibili.com/video/BV1SY4y1M7bD/),介紹 FiBiNet 很到位。
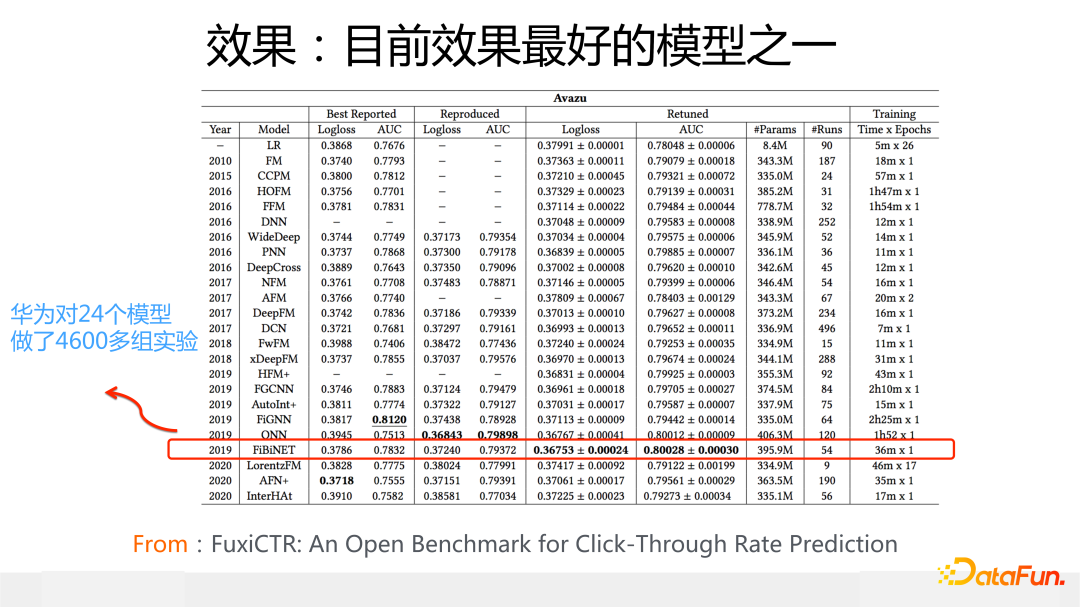
從 2019 年我們提出 FiBiNet,再結合我參考最近兩年的模型發展情況,我的結論是:FiBiNet 是目前效果最好的 CTR 模型之一,尤其是在 Avazu 數據集上,大概率 FiBiNet 到目前這個時間點就是 2022 年,盡管有一些新模型出現,我判斷它在 Avazu 上很可能仍然是效果最好的 CTR 模型(有個公平對比的前提條件:Avazu 數據集上,特征 Embedding size 要放到 40 或者 50,這是絕大多數 CTR 模型在 Avazu 上效果最好時候的 Embedding size,而不是像很多工作實驗部分報道的,強制把 Avazu 數據集上的 Embedding size 設置成 10,這并非一個合理設置。Criteo 數據集最合理的 Embedding size 應該在 10 到 20 之間)。
上面這張圖是得出判斷的依據之一,這是華為 FuxiCTR 的工作,它做了 4600 多組實驗來公平對比從 2010 到 2020 年這 10 年間比較知名的 24 個 CTR 模型的效果,結果顯示在 Avazu 上 FiBiNet 效果最好。當然這只是我得出上述結論的依據之一,還有其它依據,包括我們內部也對新模型做過大量實驗對比,我個人覺得上述結論基本成立。
不過話說回來,最近 2 年我的一個明顯感覺是:CTR 模型的效果和數據集關系比較大,目前應該不存在一個模型,它在各種數據集都能占據統治地位,這和 NLP 以及圖像處理領域表現完全不同,這兩個領域基本都有統治性的模型,這也一定程度上說明了,推薦模型整體缺乏突破進展,才會造成在不同數據集上最佳模型不同,類似軍閥割據的這種外在表現。而在某個數據集上表現最好的 CTR 模型,很可能是因為它的某個網絡結構設計,正好匹配了這個數據集合的數據分布特性。
這里順便再說下數據集的問題,如果你要測試 CTR 模型且以論文的方式呈現出來,很明顯實驗部分的測試數據應該帶上 Criteo 和 Avazu,因為這兩個數據集規模比較大,都在 4500 萬左右。盡管這兩個數據集也有一些問題,但是貌似除此外我們也沒有更好的選擇,這也是沒辦法的辦法。
而如果一個論文里的 CTR 模型,實驗部分都用的是小規模數據,很明顯這個工作就沒太多實用價值,因為小數據上有效的技術改進,大概率換個規模大的數據就會失效。即使在 Criteo 和 Avazu 證明有效的模型,上線未必會有效,因為你面臨比 4500 萬更大規模的數據,技術失效也不意外,但是如果一個新模型在實驗部分連這兩個數據都不帶,都是小規模數據,那只能說明模型作者對自己的模型效果不夠自信。所以如果你的出發點是真正想提出有效的改進模型而不僅僅是水一篇論文,那我建議一定要用大規模數據來驗證。
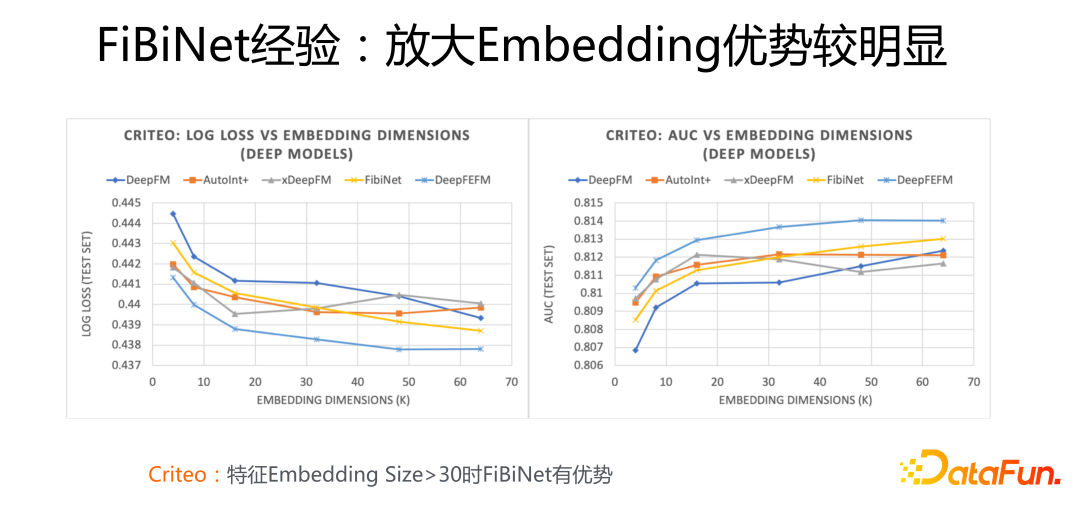
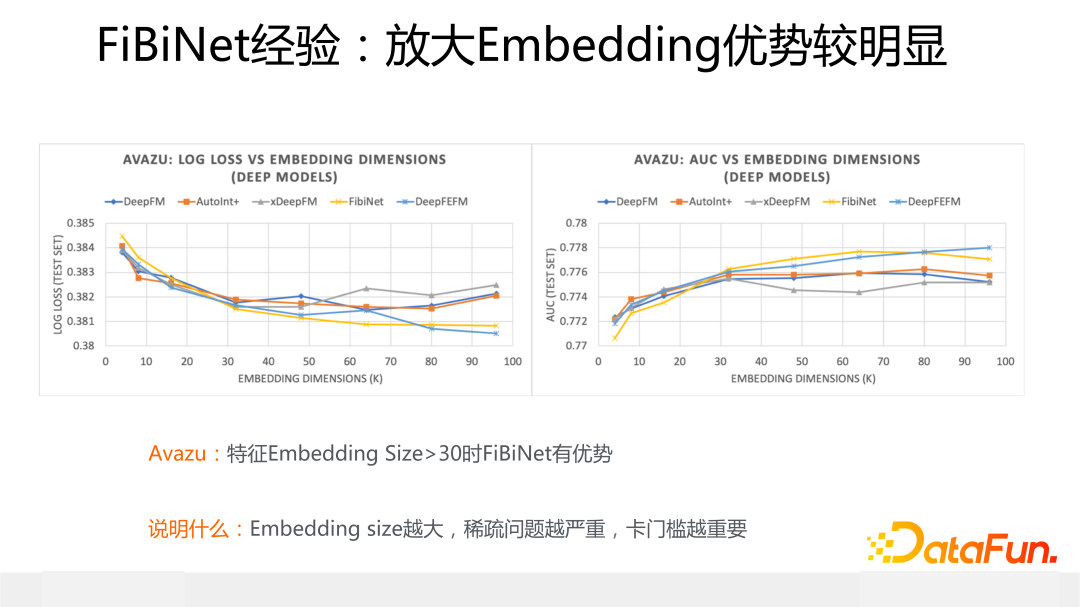
這里介紹下使用 FiBiNet 的一個經驗:上面兩張圖片展示了不同模型在 Criteo 和Avazu 數據集上的效果對比,坐標橫軸是不同大小的特征 Embedding size,縱軸是 Logloss 和 AUC 效果指標,圖中的黃色曲線代表了 FiBiNet 的效果表現。
從中可以看出,無論是 Criteo 還是 Avazu 數據集合,當逐漸放大特征 Embedding size,尤其當大小超過 30 的時候,FiBiNet 相對其它模型(DeepFM/xDeepFM/AutoInt+)的效果優勢逐步擴大,而其它模型的效果要么開始往下掉,要么開始波動,只有 FiBiNet 隨著 Embedding size 的繼續放大,性能穩步提升。也就是說如果應用中 Embedding size 設置的比較大的時候,明顯使用 FiBiNet 效果更好。
這是為什么呢?我覺得這個現象說明了一個問題:正是 FiBiNet 中的 SENet 模塊導致這個現象的發生。因為當特征 Embedding size 越大的時候,稀疏問題就會越嚴重,而此時使用特征門控就越重要,因為此時 SENet 有更大可能將無效特征過濾掉,避免了大量特征稀疏的負面影響。
據我了解,目前 FiBiNet 里的 SENet 模塊或者它的改進變體在很多一線二線互聯網公司的線上推薦系統或廣告系統都在應用,也取得了不錯的收益,但是在現實場景中雙線性模塊用的就比較少,這是為什么呢?我認為主要原因是 FiBiNet 模型中,雙線性模塊本身以及它和上層 DNN 連接處設計思路有問題:
因為 FiBiNe 下層有兩路,每路各有一個雙線性模塊,而雙線性模塊里用了哈達瑪積,這就導致在雙線性模塊做完特征交叉之后,這層非常寬,它和 DNN 的第一層 MLP 這個連接處參數量會急劇增加。如果應用中包含的特征域(Fields或Slot)比較多,模型跑起來非常慢,這就是它的主要問題所在。
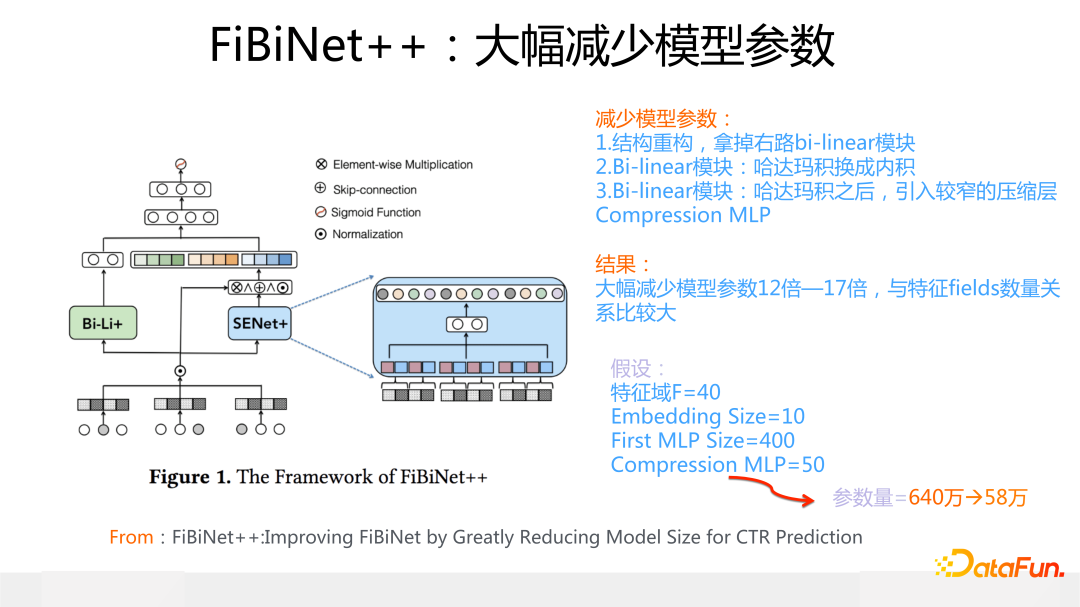
為了解決 FiBiNet 雙線性模塊設計的問題,我們改造出了新版本的 FibiNet++(細節信息可以參考論文:FiBiNet++:Improving FiBiNet by Greatly Reducing Model Size for CTR Prediction,https://arxiv.org/pdf/2209.05016.pdf),主要目的是在盡量不降低模型效果,甚至進一步提升模型效果的前提條件下,大幅減少模型參數量。
關于減少模型參數的改進措施,包含幾個要點:首先,更改模型結構,去掉 FiBiNet 下層右路 SENet 之上的 bi-linear 模塊,拿掉基本無影響;其次,雙線性模塊計算中的哈達瑪積變成內積,這個改變很小,但能大幅減少模型參數;再次,在左路 bilinear 特征交叉后,加入一個窄的 MLP 層,用于對特征交互結果進行維度的進一步壓縮。經過上述改進,模型大小縮小了 10 幾倍(不考慮特征 Embedding 的情況)。
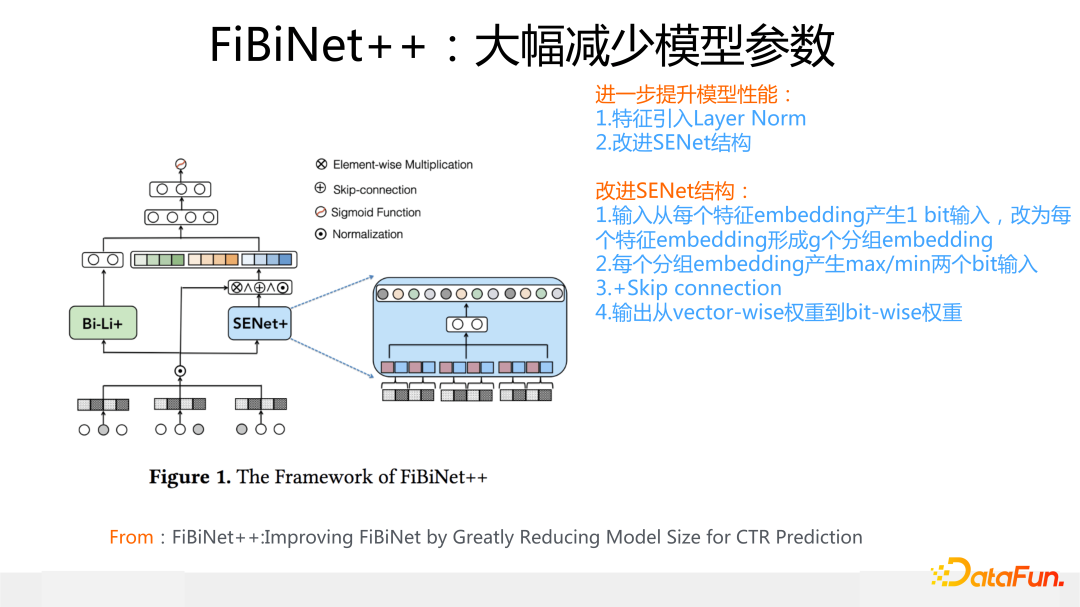
與此同時,我們對 SENet 模塊做了一些改進,來進一步提升模型效果。
主要措施包括:
首先,SENet 的輸入信息,從每個特征 Embedding 產生 1 bit代表位,改為將每個特征的 Embedding 劃分成 g 個分組 Embedding ,每個分組 Embedding 產生兩個代表位:一個均值 bit,一個 max bit,這兩個 bit 作為分組代表信息。
其次,增加 Skip connection,原始 Embedding 和加權的 embedding 進行求和,等于保留了原始 Embedding 信息。
最后,輸出的特征權重,從 vector-wise 權重到 bit-wise 權重,就是說原先是每個特征學習一個權重,現在是每個特征的每個 bit 都給予一個權重。
經過這些改造,FiBiNet++ 的效果相比 FiBiNet 有進一步的提升。
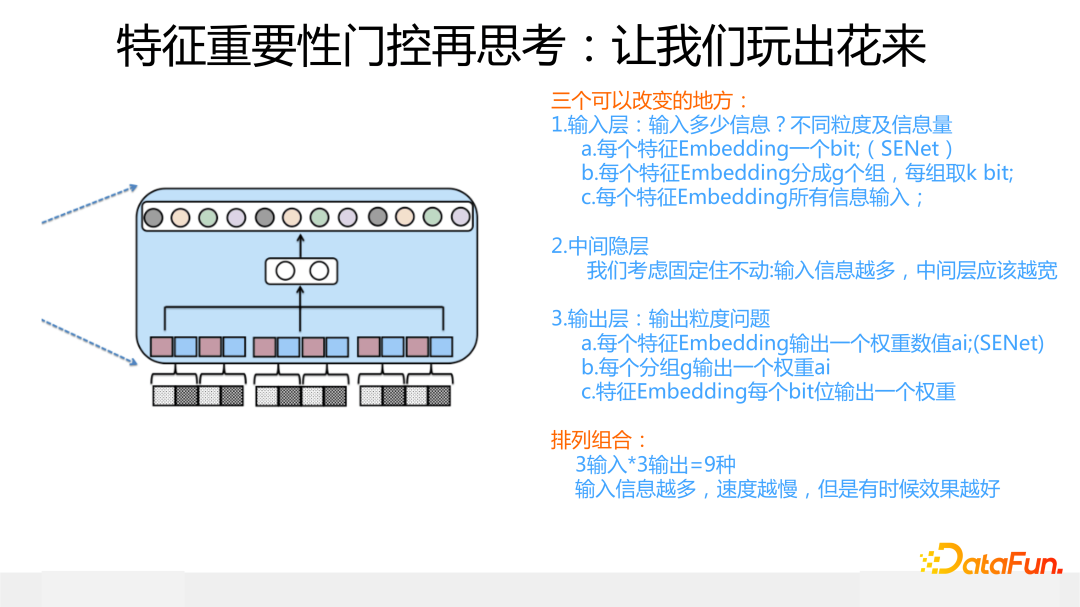
如果我們把特征門控抽象一下,你會發現各種新型的變體結構。
首先,門控的輸入層,根據輸入信息由粗到細,可以有三種做法:每個特征 Embedding 出一個 bit 代表位/每個特征分組,每組出 1 個或者 2 個代表位/每個特征 Embedding 的所有信息都作為門控的輸入。
其次,為了簡化問題,關于中間 MLP 隱層,我們假設結構不動(但是這層的寬度應該根據輸入信息多少進行相應調整,總的原則是輸入信息越多,這層 MLP 應該越寬,否則會存在表達不足問題)。
再者,在門控輸出層,我們跟輸入層一樣,也有由粗到細的三種做法。
這樣,三種輸入搭配三種輸出,一共有 3*3=9 種模型組合,這還不算中間隱層的變化。而原始版本的 SENet,取了其中輸入信息、輸出信息最少的一種組合搭配,它的特點是模型參數少,速度快,比較輕巧,但是有信息損失。
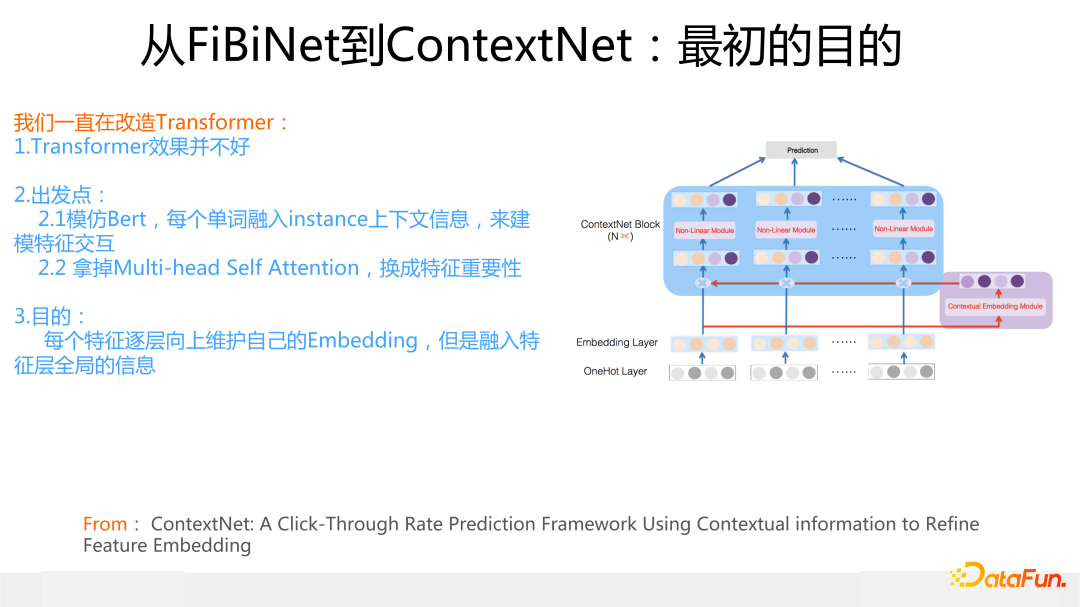
在此基礎上,我們來介紹 ContextNet 模型,這是 2019 年在 FiBiNet 發表后的關于特征重要性的進一步改進工作,論文形成于 2020 年 2 月份左右,把論文扔出來是 2021 年年中的事情了。當然,我們最初設計 ContextNet 的初衷,并不是因為推斷出上面的門控 9 組合,然后換一種組合來做這個事情。
起因是自從 Bert 出來后,從 2018 年年底開始,我覺得 Transformer 會統一 NLP 領域,所以從那時候就想改造一個推薦版本的 Transformer 結構,當時我們用原始版本 Transformer 試過,跟 DNN 模型比,效果其實并不好,所以 ContextNet 其實是我們摸索覺得比較適合用于推薦領域的 Transformer 改造版本。
它的結構和出發點參考上圖,說白了就是模仿 Bert,在 Bert 里,每個單詞維護自己的 Embedding 一直往上層結構走,根據其它單詞 Embedding 來修正自己的 Embedding,達到根據上下文消除單詞多義詞的問題。ContextNet 思路類似,每個特征維護自己的 Embedding,不斷往上層結構走,根據同一個輸入里的其它特征的原始 Embedding,經過一個特征門控系統,來不斷修正自己的 Embedding 內容,這個門控起到的作用其實是尋找有效特征組合。在門控起作用后,上接一個局部 MLP 來非線性整合新的特征 Embedding 內容,這點和 Transformer 沒有太大不同。你可以簡化理解為把 Transformer 的 Multi-head self attention 用特征門控系統給替換掉了,就是 ContextNet。
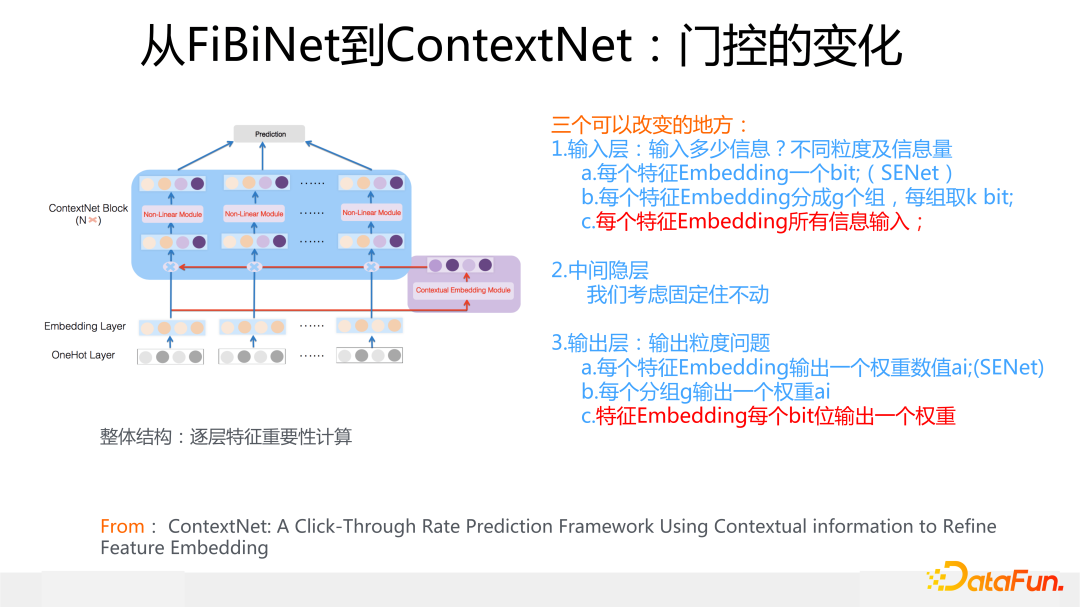
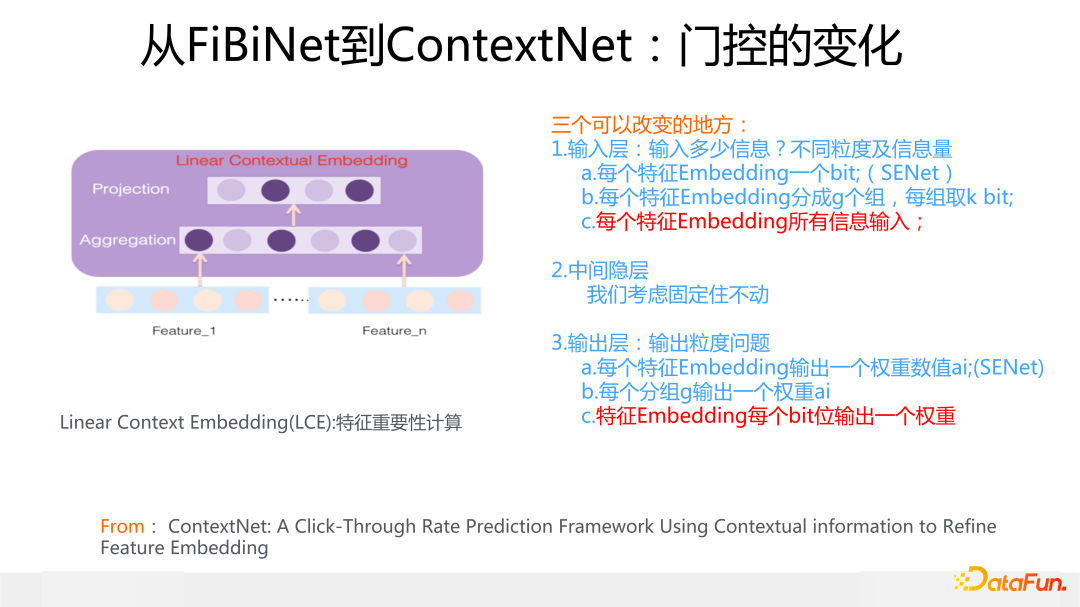
于是,繞了一圈,我們又回到了特征門控這里來了,這個特征門控就是上面說的門控 9組合里輸入輸出最豐富的另外一個極端情況:特征 Embedding 所有信息作為門控輸入,輸出則是 Bit-wise 的,就是說給特征 Embedding 每個 Bit 都打上一個權重。
這里有兩點需要注意:首先,不論特征 Embedding 走到哪一層,它對應的門控的輸入都是所有最原始的特征 Embedding,實驗結果證明這種原始特征的輸入效果最好;其次,門控中間的隱層要比較寬,2 倍于輸入信息是效果最好的,這是因為輸入信息比較多,中間層就需要較多神經元來擬合信息。所以它和 SENet 特性正好相反,它比較重,參數多,速度慢,但是效果要更好。
另外,如果在最上層加上一個 MLP 用于整合各個特征 Embedding 的信息,ContextNet 效果會進一步提升,應該和 MaskNet 效果接近,但是當時我覺得這種“戴帽子”的混合結構看上去太丑陋,就沒同意加這個帽子,于是 ContextNet 就是目前這種樣子。
我認為如果 CTR 模型里需要 Transformer 模型,那它應該就是長得類似 ContextNet 這樣的,因為這些年來我們嘗試改造過非常多不同的 Transformer 變體結構,目前看這種結構效果是最好的,當然,在用的時候,這里建議最上層可以帶上個 MLP 的帽子,畢竟效果要好,長相難看就難看點吧,聰明更重要,為此我已放棄模型審美了。
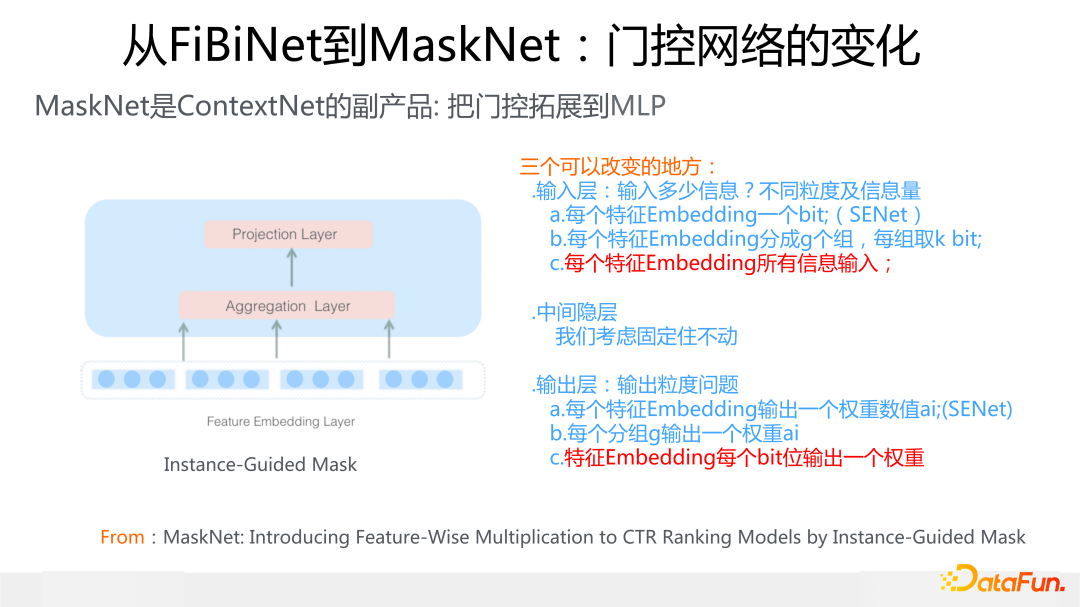
最后介紹下 MaskNet,這是我們目前探索的所有模型中效果最好的(Avazu 數據除外,Avazu 上仍然是 FiBiNet 或者 FiBiNet++ 效果更好)。MaskNet 是 ContextNet 的副產品,在做 ContextNet 有了效果的同時,我問自己這么一個問題:特征門控肯定是有效的組件,但是除了用在特征 Embedding 上,如果我們把它用在 DNN 模型的 MLP 結構上,會是什么效果呢?是否可以根據原始特征輸入,通過門控調整 MLP 的輸出,使得 MLP 更好地在原始特征輸入里捕捉特征組合呢?為了回答這個問題,就做實驗試了一下,發現在幾個數據集合上效果都是最好的。
本來我覺得既然有了 ContextNet,這個改動不值得形成一篇文獻,但是考慮到效果確實比較好,就也寫了論文,成文時間與 ContextNet 基本同時期,大約在 2020 年 3 月份,2021 年年初我看外界有類似的思路出來,就把文章扔出去了。
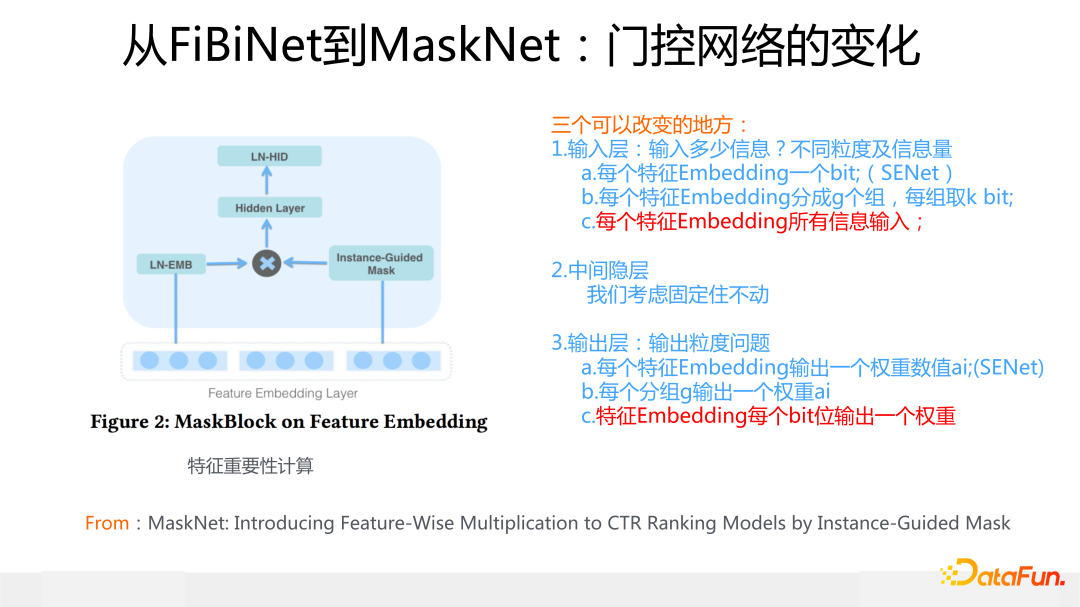
下面簡單介紹一下 MaskNet 的具體做法。這里采用的門控和 ContextNet 是完全一樣的,沒有任何區別,作用在特征 Embedding 上的機制和 ContextNet 也一樣,不同的地方是上面加了一個全局的 MLP 結構對信息進行融合,這是 MaskBlock on Feature Embedding。
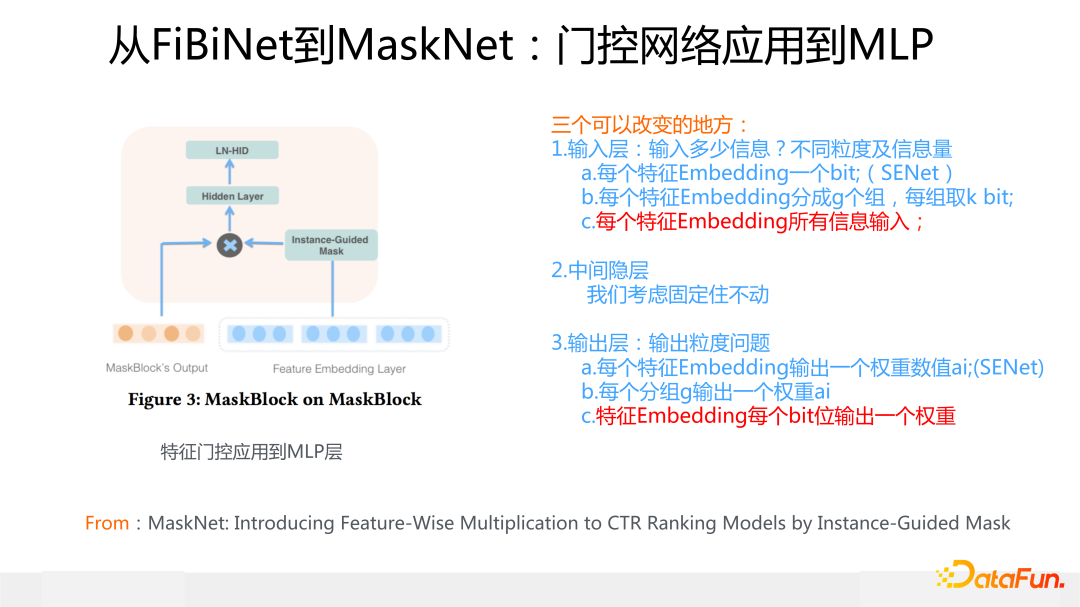
類似的,對于某個 MaskBlock 的輸出結果,也就是上面說的 MLP,我們也可以產生對應的一個特征門控,然后作用到 MLP 上,之后用一個新的全局 MLP 對信息進行融合,這就是 MaskBlock on MaskBlock。
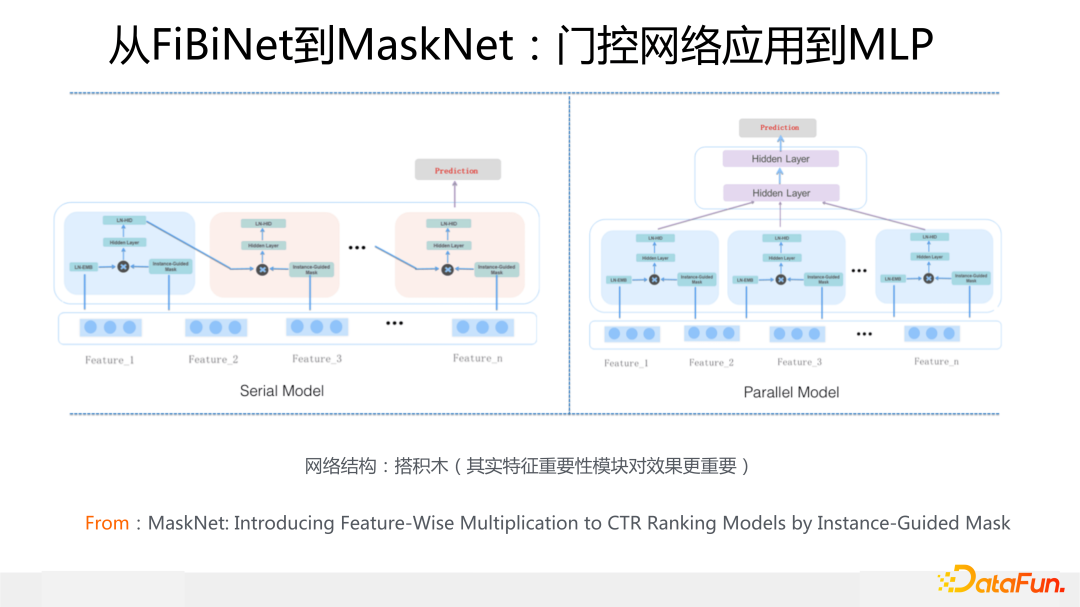
把針對特征的 MaskBlock 和針對 MLP 的 MaskBlock 進行疊加,有兩種方式,一種是串行方式,因為不同 Block 特征門控的輸入都是來自原始特征 Embedding,這個結構看起來就類似 RNN 的結構了;另外一種是多個針對特征的 MaskBlock 并行,上面接上標準 MLP,這種類似 MMOE 多專家的結構。

上面是微博在特征建模的主要工作介紹,這里打個廣告:今年我們在特征建模方向做了一個新工作,我個人認為是一種全新的范式和方向,目前在幾個大規模公開數據集上離線測試效果有大幅提升,過兩個月如果有機會的話,和大家分享下思路和具體做法。
04
擠水分:變長特征 Embedding
接下來用具體例子,簡單說明下“擠水分”可以怎么做。這里再強調下,一個理想的分配特征 Embedding Size 的原則是:中高頻特征的 Embedding 應該較長,低頻特征的 Embedding 應該較短。在這個原則指導下,目前常見的做法可以細分為兩種 。
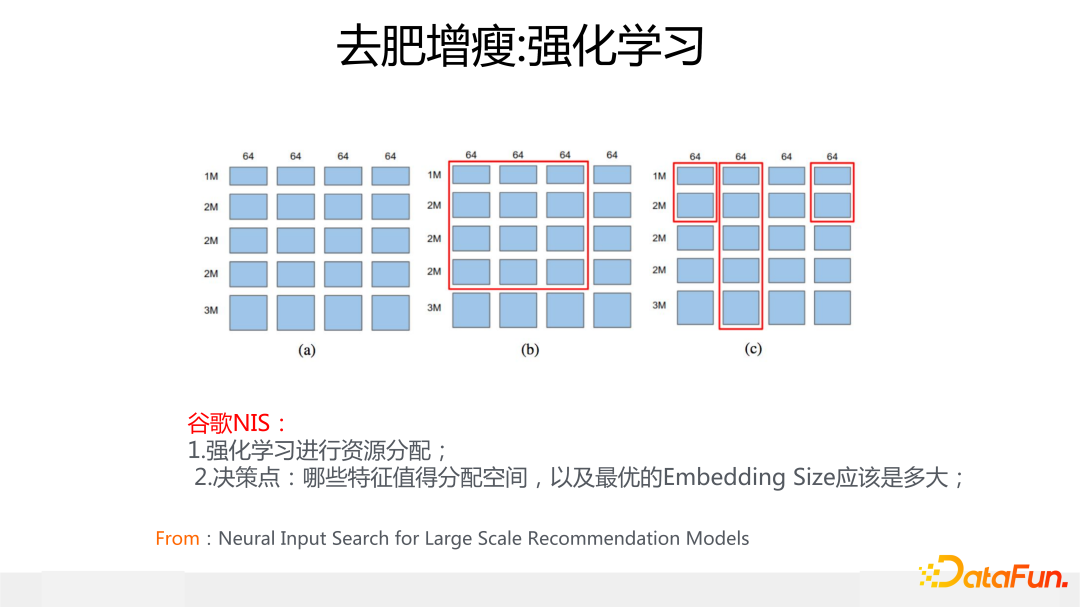
第一種做法是用強化學習來自主學習應該給每個特征分配多大的 Embedding size,代表模型是谷歌的 NIS 模型,它的核心思想是把可分配空間劃成 64bit 一個 block,不斷迭代嘗試,看看每個特征分配多少個 block 效果最好,強化學習的 reward 就是驗證集合上的 AUC 指標。這里不展開講了,具體思路大家可以看上圖列出的參考文獻。這是一類方法,在 NIS 之后有不少采取強化學習思路來做變長 Embedding 的工作。
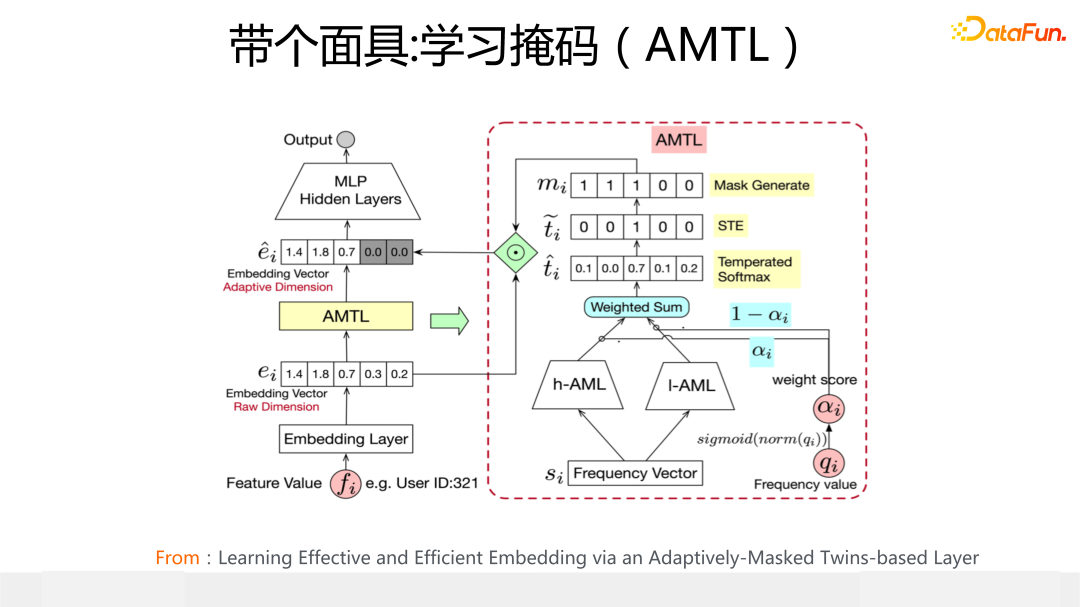
第二種做法的代表模型是阿里媽媽提出的 AMTL,核心思想是:根據特征頻次,為每個特征學習一個獨有的內容為 0 或者 1 的掩碼向量 ,通過學習到的掩碼向量中 1 的不同個數,來控制 Embedding 實際分配的長度,1 越多則分配的 Embedding 越長。這是另外一類“擠水分”的典型做法。
05
補營養:提升特征表達質量
第三類特征建模方式是“補營養“,核心思路是想辦法提升稀疏特征的表達質量。至于具體思路,又可以分為兩個子方向:“苦練內功”提質量和“引入外援”提質量。
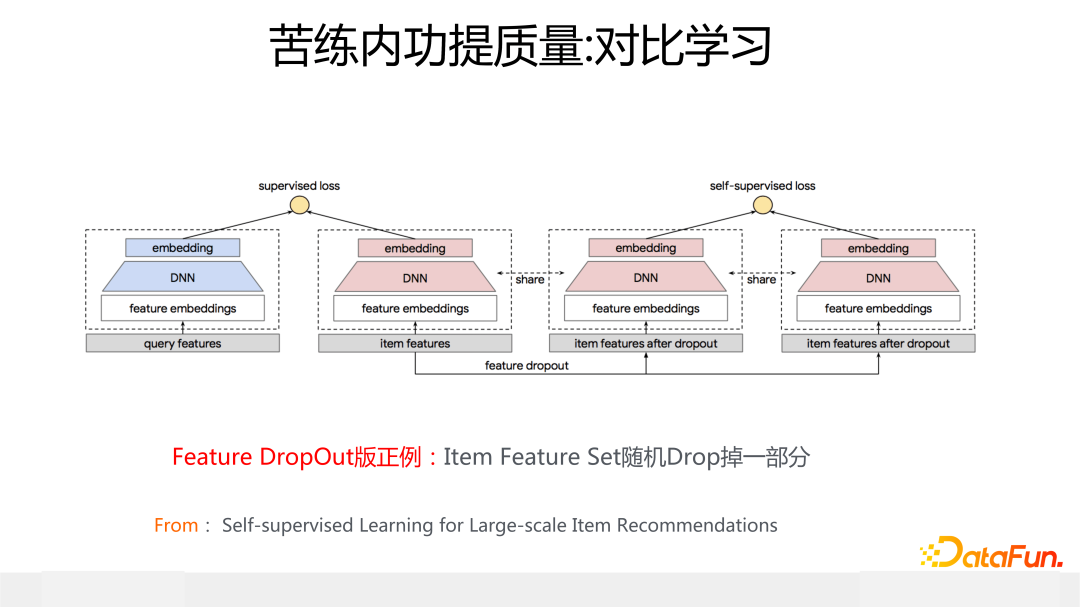
上面列出的谷歌使用對比學習來改進召回/粗排模型的工作,是典型的“苦練內功”提質量的思路。上圖展示的模型是用于召回或者粗排的經典的雙塔 DNN 模型,在 Item 側的塔引入一個輔助的對比學習 loss,對比學習的正例通過隨機 drop 掉 Item 所有特征中的一部分特征來構造,對比學習 loss 采用 infoNCE,這使得正例在投影空間之間的距離更近,正例和負例的距離更遠。這樣就可以提升低頻特征 Embedding 的質量,緩解特征稀疏問題。
那為啥這樣可以緩解特征的稀疏性,以及為啥把這種做法叫做“苦練內功”呢?其實你深入思考一下,就會發現:設想構造出的正例對為
其實就是把高頻特征 b 的 Embedding 表達遷移給稀疏特征 a,因為只有這樣,A 和 B 才能在投影空間靠近。所以這種使用對比學習的本質是:把同一個輸入實例中高頻特征 Embedding 遷移給低頻稀疏特征的 Embedding,它靠自己,不靠外力因素來豐富稀疏特征的表達質量,所以我把它叫做“苦練內功”提質量。無疑“苦練內功”這種方式是很辛苦的。
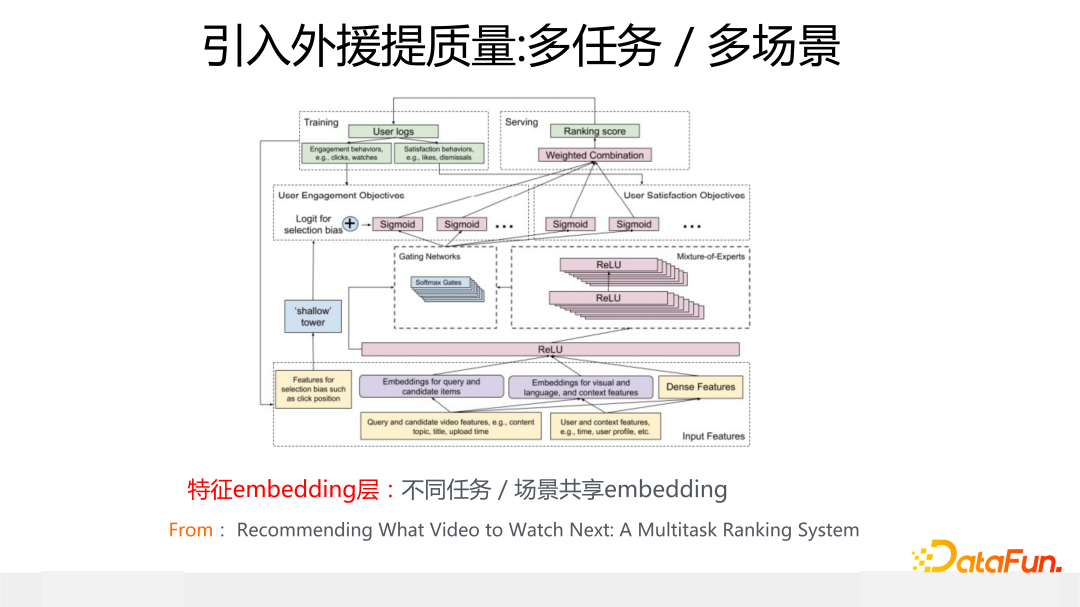
另一種提升稀疏特征表達能力的是“引入外援”。典型的例子就是多任務/多場景模型,這個目前大家都在做,模型也有很多,比如 MMOE/PLE 等。上圖展示的是 MMOE 模型的模型結構,這里我覺得最關鍵的是 Embedding 層,因為不同場景或任務,一般大家共享同一套特征 Embedding。你可以想想這么做有什么好處?很明顯,因為大家共享同一套特征 embedding,對于在場景 A 下的某個稀疏特征 a 來說,盡管它在場景 A 下是稀疏的,因為包含特征 a 的訓練數據很少,但是對于數據豐富的場景 B 來說,因為數據量多,那么經過 B 的訓練數據訓練出來的 a 的特征 Embedding,就不那么稀疏了,因為它見到了另外一個場景更多的數據,這樣就能提升場景 A 的模型效果。
對于場景 A 來說,引入了場景 B 的數據來豐富稀疏特征的表達,所以這是為何我把它叫做“引入外援”提質量的原因。很明顯,相對“苦練內功”來說,“引入外援“更容易做,也更容易見成效。我個人認為,多場景多任務模型,特征 Embedding 共享,很可能是帶來收益的主要原因,而上層模型結構,盡管不同模型收益不同,但是相對特征共享來說,總體而言影響相對小,當然這純粹是個人猜測,并無實驗支撐。
06
Q&A環節
Q1:推薦系統的特征數量為什么會有 10 億這么多?
A1:主要是由于 ID 特征導致的,比如 user id,item id等,還有其它各種 id,絕對數量比較多,當然在實際實現時,未必每個 id 會給個 embedding。
Q2:卡門檻類的方案中,特征是如何被卡掉的?
A2:以 SENet 為例,如果打權重那層網絡的激活函數使用 Relu,你會發現大量特征的重要性得分經過激活函數后打分都是 0,把 0 乘到對應特征的 embedding 里,那這樣等于把這個特征的作用抹掉了。當然也可以用其它非線性函數或者干脆使用線形函數打分,這種情況一般被卡掉的特征表現為獲得的重要性得分都很小,等于削弱了這些特征的作用。
Q3:user/item 冷啟動怎么做?
A3:這是一個專門的方向,從技術角度,總體思路可以理解為在“補營養”環節提到的基本思想,就是借助其它數據遷移,來緩解數據稀疏問題。或者采取一些運營策略來做各種試投放等探索策略,讓好的內容自己浮現出來。
Q4:特征重要性怎么來的?
A4:其實就是你設計一個重要性計算的專用子網絡,在網絡訓練過程中,通過 loss 的引導,這個子網絡的參數和模型的其他參數一起學習,最后學好的這個網絡輸出的結果就是特征重要性的得分。
Q5:FiBiNet 如果只用重要性加權之后的 embedding,去掉原始 embedding 效果如何?
A5:如果保留原始的特征 emdding 效果會稍微好一些,相差不大。
Q6:訓練 epoch 一般用多少?
A6:CTR 模型大多數情況下模型在一個 epoch 內收斂。
Q7:SimCSE 的思路在推薦場景是否可用?
A7:原則上可以。SimCSE 這種對比學習的思路,原則上可以用在推薦的召回模型里,因為本質上它也是在用對比學習來解決特征稀疏性問題。和谷歌那個對比學習召回模型的主要區別是:做正例的時候,一個在輸入特征角度制造差異做正例;一個用 dropout 在 MLP 隱層制造差異做正例。本質是一樣的。不過,我們自己在召回模型里嘗試過 SimCSE 的思路,效果不太好,這里可能需要進一步的探索。
Q8:加入新特征如何評估重要性?
A8:兩種思路。一是做 AB 試驗,二是把特征全部加入模型,用特征重要性模塊的打分來做評估和篩選。
Q9:SENet 如果特征量大會不會速度慢?
A9:SENet 網絡的輸入層,因為每個特征只出 1 個 bit,而且隱層又會進一步壓縮寬度,所以計算速度比較快,特征量大也沒問題。
Q10:特征過濾后,特征交叉有什么思路?
A10:目前典型的做法,是在上層加一個顯式的特征交叉模塊。例如 xDeepFm 中的CIN,autoint 中的 self-attention,以及 FiBiNet 中的雙線性交叉模塊。我個人理解這樣的模塊目前來看確實有用,從技術發展來講,將來沒有存在的必要。
Q11:SENet 直接 RELU 輸出會不會有輸出不穩定的情況?例如初始化或其他問題導致 embedding 被 scale到很大。
A11:問題是存在的,所以我們在改進版本的 FiBiNet++ 里會引入特征 Norm。比如在特征 embedding 的地方引入 layerNorm 或者 batchNorm,以及在特征打上權重之后加入 Norm。
Q12:你說的在做的新模型,離線測試的進展具體指的什么?
A12:一般寫論文常用的規模比較大的兩個公開數據集是 avazu 和 criteo,進展指的是新模型在這些數據集合上 AUC 有大幅度的提升。
Q13:對特征建模是否會引起模型膨脹?
A13:不僅不會膨脹,情形正好相反,比如“擠水分”這種,對特征建模實際是在大幅減少模型參數,而其它兩類做法,模型總參數量是不變的。
Q14:參數初始化有什么經驗?
A14:不同場景效果好的初始化方法不同,建議多嘗試。
Q15:對比學習用在精排是否有意義?
A15:要具體看用在哪里。如果拿對比學習來對行為序列建模,方案非常簡單直接,也是比較適合的;如果是對平鋪特征而非行為序列建模,則比較難做,方案不容易想。單從原則上來講應該是有用的,不過目前還沒有看到比較好的方案。
Q16:SENet 這種結構是否會抑制 embedding 的學習?
A16:談不上抑制還是增強,從根本上講,還是優化目標的 loss 來引導特征重要性和特征本身 embedding 的學習。如果對優化目標有用,它就會被引導到那個方向。
Q17:Norm 的思路和工作推薦?
A17:在排序模型的不同結構上用不同的 norm,這是一個可以探索的方向。我們的結論是:數值特征用 batchNorm,類別特征用 layerNorm,MLP 用 layerNorm,這樣效果比較好。如果希望深入了解,可以搜索下 NormDNN 模型的論文,這是我們對排序模型如何應用 Norm 的探索,里面有相關細節。
Q18:所有特征都直接輸入嗎?
A18:過于低頻的特征可以過濾掉,數值特征可以做離散化,這都是常規操作。
Q19:SENet 線上的收益效果如何?
A19:SENet 已經經過很多大中型互聯網公司實際數據驗證是有效的,而且目前線上都采用了這個模塊,具體提升的數值/比例要看具體場景等情況。
Q20:如果我們場景特征數量比較小,從這幾個模型里如何選擇?
A20:建議采用 FiBiNet++,它綜合考慮了訓練線上運行的效率和效果。
Q21:特征建模有沒有可能和上層網絡模塊單獨建模?
A21:現在其實特征建模和網絡建模就是分離的,比如上面介紹的特征重要性子網絡,都是獨立的一個網絡模塊,模型結構關注特征的泛化性,特征模塊關注特征表達的充分性,這樣各司其職,效果才會好。
Q22:關于剛才說的不穩定的問題,為什么用Norm而不是把激活函數換成sigmoid?
A22:雖然 sigmoid 從函數形態來看更符合門控的思想,但是當時我們線上測試的效果是 Relu 最好,后來做改進版本的時候,測試結果是不用非線性函數最好,所以我覺得還是以效果為準。
Q23:為什么數值和類別特征用不同的 Norm 方法?
A23:數值特征有兩種常見做法。一種是離散化,和類別特征一樣 one-hot。另一種是給這一個特征域學習一個 embedding,特征值乘上特征域的 embedding 作為特征表達。第二種做法需要考慮特征值的分布,避免很大的數值主導優化過程,所以要做特殊的 Norm 處理。
Q24:低頻特征過濾多少合適?
A24:具體情況具體分析,要做對比實驗,一次卡掉一部分頻次的特征,看卡到多少時候影響開始負向,總體而言要通過實驗來確定,因為不同數據集合這個數值可能不一樣,我覺得這個數值大概率與數據集合的稀疏程度相關。
Q25:對比學習的特征 drop out 怎么理解?和 MLP 上做 drop out 對比呢?
A25:本質上區別不大,可以參考上面說的 SimCSE 的問題。
Q26:特征的 embedding size 如何設置?是否某個特征域下包含特征越多,那么特征 size 應該越大?
A26:不能這么簡單的看。比如 id 類特征,類別下特征數量極多,但是其實它是最稀疏的,用很大的 embedding size 未必合適,對于某些高頻 id,放大應該有好處,但是大量低頻 id,負面影響更大些,需要平衡考慮好處和負面影響,所以我覺得很難通過簡單規則來定義,參照“擠水分”做法讓系統自動分配可能是更好的解決思路。
審核編輯:劉清
-
圖像處理
+關注
關注
27文章
1282瀏覽量
56657 -
CTR
+關注
關注
0文章
37瀏覽量
14086 -
nlp
+關注
關注
1文章
487瀏覽量
22015
原文標題:張俊林:推薦系統排序環節特征 Embedding 建模
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【下載】《射頻微波功率場效應管的建模與特征》
【下載】《射頻微波功率場效應管的建模與特征》
做一些tranceiver設計GND沒有工作的原因是什么?
分享自己做通信設計兼職的一些心得
不同特征選擇算法的各自特點及其在微博業務應用中的演進歷程
EV電池包設計方面一些方向及趨勢
融合標簽語義的微博熱點話題挖掘方法
為什么不同模態的embedding在表征空間中形成不同的簇
介紹得物App在資源優化上做的一些實踐





 工商網監
工商網監
評論