 一個全新的文本到視頻跨模態檢索子任務
一個全新的文本到視頻跨模態檢索子任務
概覽
本文介紹一篇ACM MM 2022 Oral的工作。基于傳統的跨模態文本-視頻檢索(Video-to-Text Retrieval, T2VR)任務,該工作提出了一個全新的文本到視頻跨模態檢索子任務,即部分相關的視頻檢索(Partially Relevant Video Retrieval, PRVR)。
PRVR任務旨在從大量未剪輯的長視頻中檢索出與查詢文本部分相關的對應視頻。若一個未經剪輯的長視頻中存在某一片段與給出的查詢文本相關,則認為該長視頻與給出的查詢文本呈部分相關的關系。
而在傳統的T2VR任務中,視頻都是預剪輯后的短視頻,且通常希望檢索得到整個視頻與文本查詢完全相關。相比之下,PRVR任務更加符合實際應用場景,且更具有挑戰性。
作者將PRVR任務視為一個多示例學習的問題,將視頻同時視為由多個片段以及視頻幀所組成的包。若文本與長視頻的某幀或者某個片段相關,則視為文本與該長視頻相關。基于此,作者設計了多尺度多示例模型,該模型分別對視頻進行片段尺度和幀尺度的特征表示,并引入了以關鍵片段為向導的注意力聚合方法,模型整體以從粗到細的方式學習文本-視頻間的相似度關系。該模型除了在PRVR任務上表現較好之外,也可用于提高視頻庫片段檢索(Video Corpus Moment Retrieval,VCMR)模型的性能。

論文:Partially Relevant Video Retrieval
收錄:ACM MM 2022 (Oral Paper)
主頁:http://danieljf24.github.io/prvr/
代碼:https://github.com/HuiGuanLab/ms-sl
1. 背景與挑戰
當前的文本到視頻檢索(T2VR)方法通常是在面向視頻描述生成任務的數據集(如MSVD、MSR-VTT和VATEX)上訓練和測試的。這些數據集存在共同的特性,即其包含的視頻通常是以較短的持續時間進行預剪輯得到,同時提供的對應文本能充分描述視頻內容的要點。因此,在此類數據集中所給出的文本-視頻對呈完全相關的關系。
然而在現實的視頻檢索場景中,由于查詢文本是未知的,預先剪輯好的視頻可能不包含足夠的內容來完全滿足查詢文本。這表明現階段在學術研究的T2VR與實際應用存在一定的鴻溝。
如圖1所示,上半部分的圖取自傳統T2VR數據集MSR-VTT,由于視頻長度較短,場景單一,所以對應的文本"兩個男人在開車的同時進行交談"能夠很好地概括視頻的所有內容。而在下半部分取自TV show Retrieval數據集的長視頻場景多變,持續時間較長。文本"豪斯使用記號筆在玻璃表面寫字"僅能表述視頻中的某一片段。在現實世界中的檢索場景大多符合后者。
為了彌補這一鴻溝,作者提出了一種新的T2VR子任務——部分相關的視頻檢索(Partially Relevant Video Retrieval, PRVR)。PRVR任務旨在從大量未剪輯的長視頻中檢索出與查詢文本部分相關的對應視頻。若一個未經剪輯的長視頻中存在某一片段與給出的查詢文本相關,則認為該長視頻與給出的查詢文本呈部分相關的關系。

圖1 傳統T2VR任務中文本-視頻對的相關關系與現實世界的差別
雖然PRVR任務和傳統的T2VR任務的目標均為從視頻庫中檢索出查詢文本的對應視頻,但在PRVR任務中視頻通常比較長,同時文本查詢對應的片段在原視頻中的時長占比分布較廣。如圖3所示,在TVR和Charades-STA數據集中,時長占比大多分布在50%以下;Activitynet數據集的占比則在1%-100%之間均有分布。
這就代表若簡單地將視頻表示為單一向量,會大量丟失與查詢文本相關的關鍵信息。同時查詢文本在對應長視頻的相關時刻起始位置和持續時間都是未知的,需要模型具備在沒有時刻標簽指導下建模出文本和對應長視頻間部分相關關系的能力,所以PRVR任務相較于傳統的T2VR任務更具挑戰性。
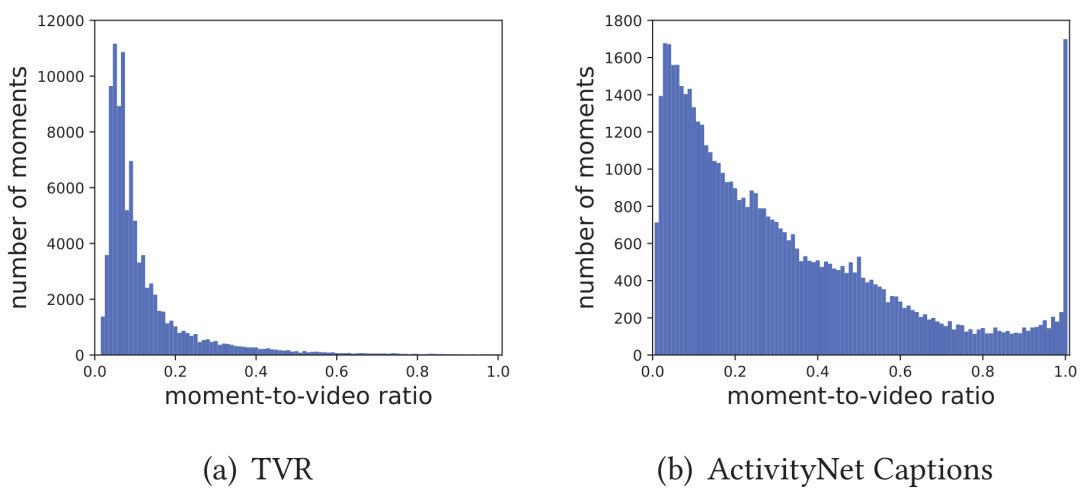
圖3 不同數據集中片段時長占比分布
2. 方法
作者將PRVR定義為多示例學習(Multiple Instance Learning, MIL)問題。
多示例學習是弱標注數據學習的經典框架,并被廣泛用于分類任務。在多示例學習中,一個樣本被視為由大量示例所組成的包,若包中的某一個或多個示例為正樣本時,則該包為正樣本;反之則該包為負樣本。作者將長視頻整體視為一個包,視頻中的各幀或由不同大小幀組成的片段則被視為不同示例。若文本與長視頻的某幀或者某個片段相關,則視為文本與該長視頻相關。
此外,由于不同查詢文本與長視頻的相關時刻持續時長區別較大,所以作者在多個時間尺度進行視頻表示,進一步提出了多尺度相似性學習來度量查詢文本和長視頻間的部分相關性。
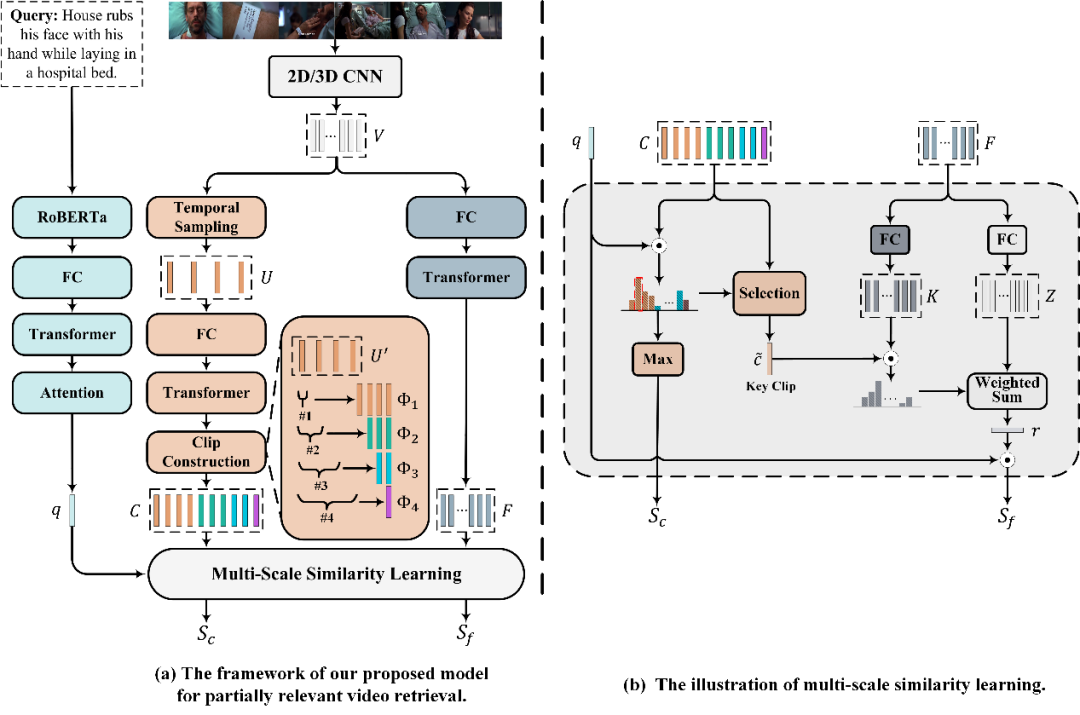
圖4 模型框架圖
2.1 文本特征表示
由于當前模型的重點并不在于文本編碼,所以作者使用了一個較為簡單且有效的文本編碼框架,它也可以被任意當下熱門的文本編碼框架替代。
具體地,給定一句由個單詞所組成的查詢文本,使用預訓練的RoBERTa模型來提取每個單詞的特征向量作為文本的初始特征。之后通過全連接層進行特征降維后,使用一層的標準Transformer模塊對其進行進一步編碼得到。最終通過注意力模塊得到句子級別的特征表示,既:
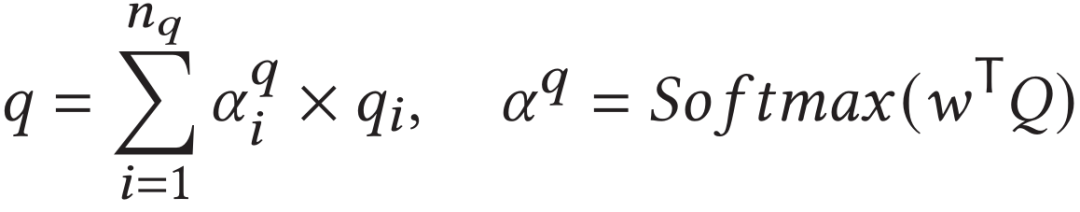
2.2 視頻特征表示
對于輸入的長視頻,首先使用預訓練的CNN對其進行特征預提取,作為視頻的初始特征向量。進一步地,作者分別從片段尺度和幀尺度分別對視頻初始特征向量進行編碼。
2.2.1 視頻的片段尺度編碼
在對視頻初始特征向量進行片段尺度編碼前,作者將其降采樣為長度為的特征,以減少初始特征序列的長度,并有助于降低編碼模塊的計算復雜度。
之后,將降采樣后的特征使用全連接層進行特征降維后,輸入到一層的標準Transformer中捕捉其上下文信息:
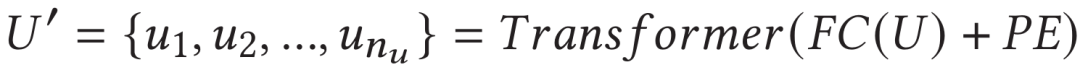
由于上文提到PRVR任務中查詢文本在對應長視頻的起止時刻是未知的,作者采用滑動窗口的方法生成不同長度的候選視頻片段。具體地,作者使用不同尺寸的滑動窗口以步長為1的幅度遍歷,在遍歷過程中通過對落在滑動窗口內的特征進行平均池化來獲得對應大小的視頻段特征序列。其形象化過程如上圖中片段構造模塊所示。通過同時使用大小從的滑動窗口,得到視頻段特征序列集合,將其展開后得到最終的視頻片段尺度特征序列,。
2.2.2 視頻的幀尺度編碼
由于視頻初始特征向量是獨立提取的,因此它們缺乏上下文的時序信息。作者使用Transformer模塊捕捉丟失的時序依賴關系。首先簡單地對初始特征使用全連接層進行特征降維,并輸入到一層標準Transformer,來得到視頻的幀尺度特征表示:
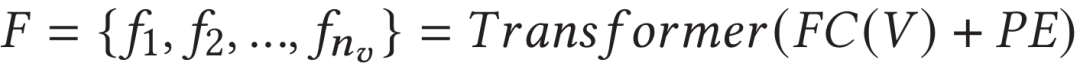
2.4 多尺度相似性學習
由于在PRVR中視頻比較長,直接在計算視頻文本相似性難度較大。
作者認為如果模型簡單地知道與查詢文本相關的大致內容,它將有助于模型在更細粒度的范圍內準確地找到更相關的內容。
因此作者提出了多尺度相似性學習,以從粗到細的方式計算文本與視頻間的相似度。它首先檢測視頻中最可能與查詢文本相關的關鍵片段,然后在關鍵片段的指導下衡量每幀的重要性。通過聯合考慮查詢文本與關鍵片段和各幀的相似度來計算最終的文本-視頻相似度。
2.4.1 片段尺度相似度
在部分相關的檢索任務中,若文本與視頻中的某一片段相關,則認為文本與該視頻相關。
因此作者首先計算視頻段特征序列中每個片段與文本特征表示之間的相似度,并將文本與片段最大的相似度作為文本與整個視頻的相似度。對于相似度取值,作者認為取平均值會使得相關片段信息被大部分的低相似度片段模糊,所以取最大值作為視頻片段尺度相似度。
此外,作者將相似度最高的視頻段特征作為關鍵視頻段特征。
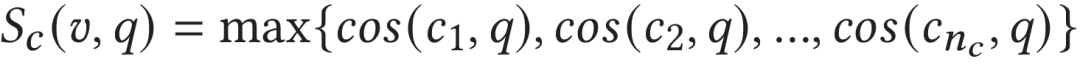
2.4.2 幀尺度相似度
檢測到長視頻中與文本最相關的關鍵片段后,作者以關鍵片段為進一步指導,在細粒度的時間尺度上衡量長視頻每幀的重要性。
具體地,作者借鑒了Multi-head Attention的編碼方式,將關鍵片段特征作為query,視頻的幀尺度特征序列作為key和value。分別計算出中各特征的權重并對其進行聚合,并計算與文本特征表示的余弦相似度作為視頻幀尺度相似度:
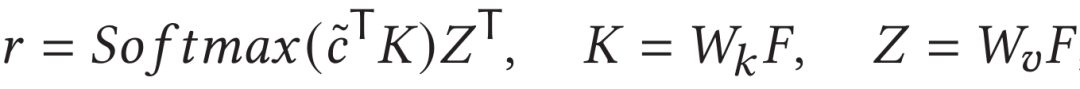
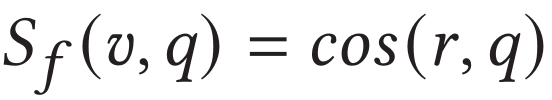
2.5 訓練和測試
在模型訓練階段,作者同時使用了三元組損失和對比學習損失進行模型優化。在測試階段,作者同時使用片段尺度相似度和幀尺度相似度以不同權重共同度量文本和視頻間的最終相似度:
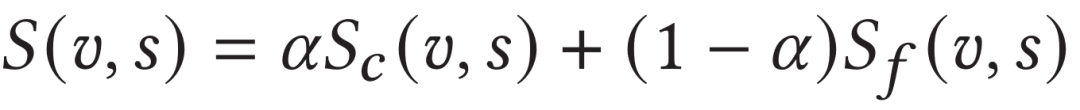
3. 實驗結果
3.1整體性能對比實驗
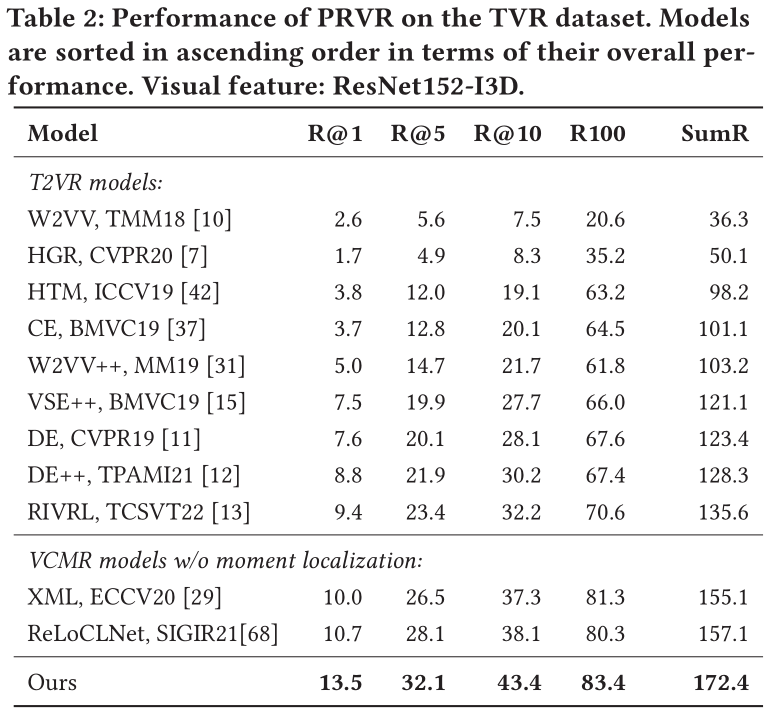
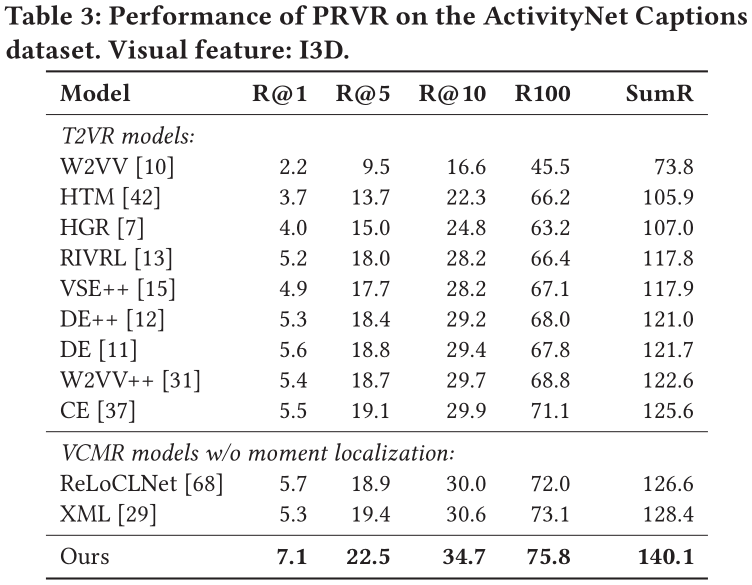
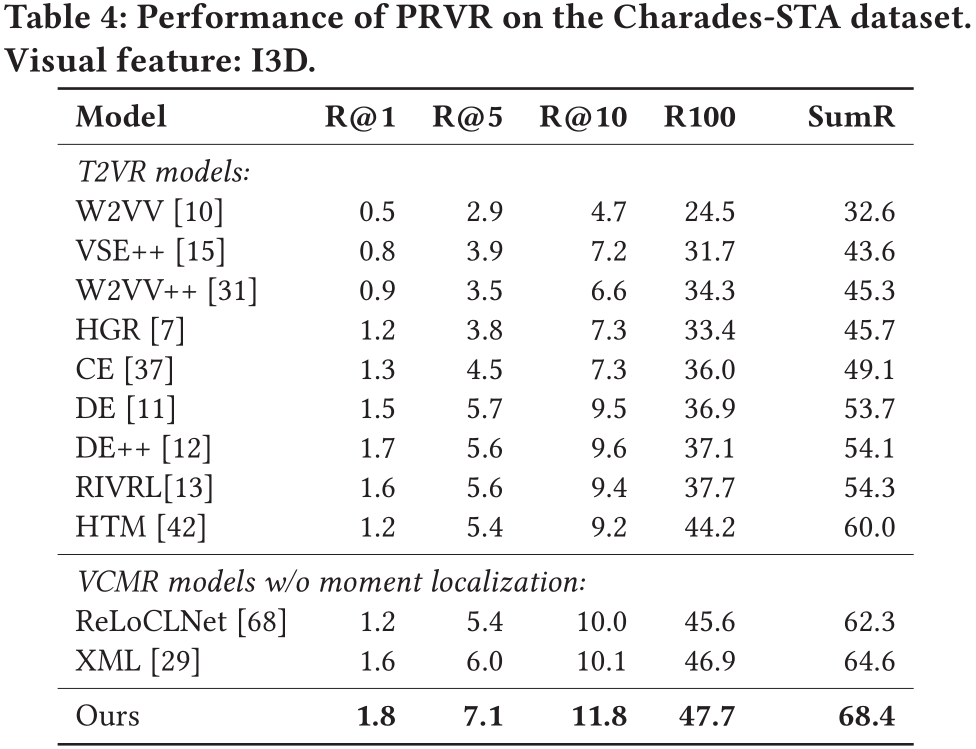
由于在上文提到,T2VR任務的傳統數據集并不適用與PRVR任務,所以作者使用了被用于單視頻定位任務(Single Video Moment Retrieval, SVMR)和視頻庫定位任務(Video Corpus Moment Retrieval, VCMR)的數據集,分別是TV show Retrieval、Activitynet Captions以及Charades-STA。
在以上三個數據集中,文本僅與視頻中的某一片段相關,且視頻的相對持續時間更長,符合PRVR任務的檢索要求。
此外,作者采用R@1、R@5、R@10、R@100以及Recall Sum等性能指標來衡量模型。同時,由于當前并沒有模型是面向PRVR任務的,作者選取了在傳統T2VR任務上表現較好的模型作為baseline并在以上三個數據集上進行重新訓練,以此進行性能對比。
在所有數據集上,論文提出的模型性能遠超各baseline。這表明論文提出的模型相較于傳統視頻檢索模型能夠更好地解決PRVR任務。
3.2 分組性能對比實驗
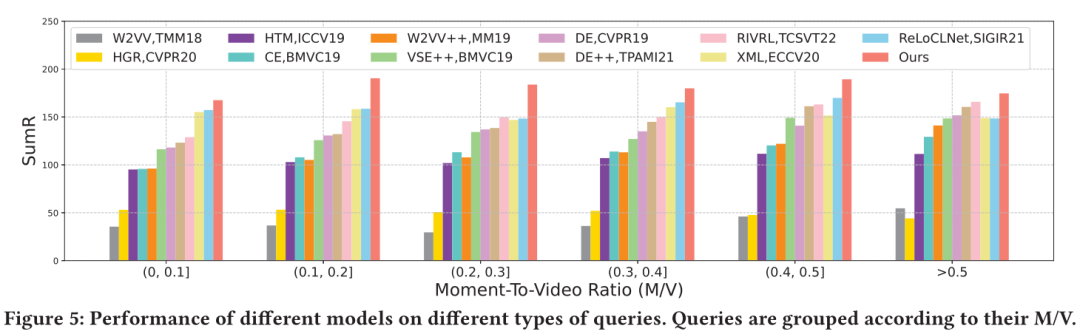
由于在上述的性能對比實驗中僅反映了模型檢索數據集中所有文本-視頻對的整體性能,為了在更加細粒度的方面探索各模型對不同相關性的文本-視頻對的檢索性能,作者定義了片段時長/視頻時長比(M/V)這一概念,它以通過查詢文本所對應的正確片段持續時間除以整個視頻的持續時間來衡量。
M/V越小,表示對應視頻與查詢文本相關的內容越少,反之則越多。此外, M/V越小,查詢文本與其對應視頻的相關性越低,而M/V越大,相關性越高。根據M/V的大小,作者將TVR數據集上的10895個測試查詢文本分為六組,并報告了在不同分組上的性能。
作者所提出的模型在所有分組中始終表現最好。從左到右觀察下圖,12個比較模型的平均性能隨著M/V的增加而增加。最低M/V組的表現最差,而最高M/V組的表現最好。
這表明,傳統的視頻檢索模型能夠更好地應對與相應視頻具有更大相關性的查詢文本。相比之下,作者所提出的模型在所有M/V組中取得的成績更為平衡。這一結果表明,作者提出的模型對視頻中的無關內容不太敏感。
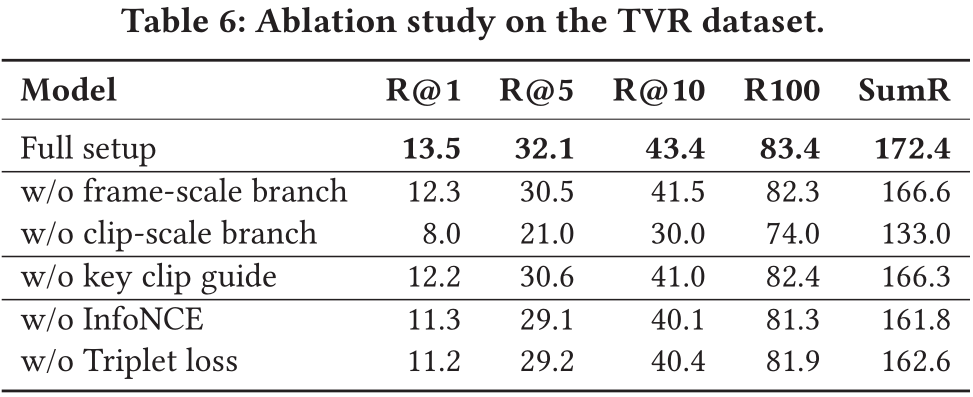
3.3 消融實驗
對于提出的多尺度多示例模型的不同組成部分,作者進行了消融分析。
模型單獨使用幀尺度或片段尺度特征表示分支時,性能都不如兩分支相結合。同時基于關鍵片段的注意力機制也能為模型帶來較大的性能提升。由于在模型訓練階段同時使用了三元組損失和對比學習損失,作者也對兩損失結合使用的有效性進行了論證。
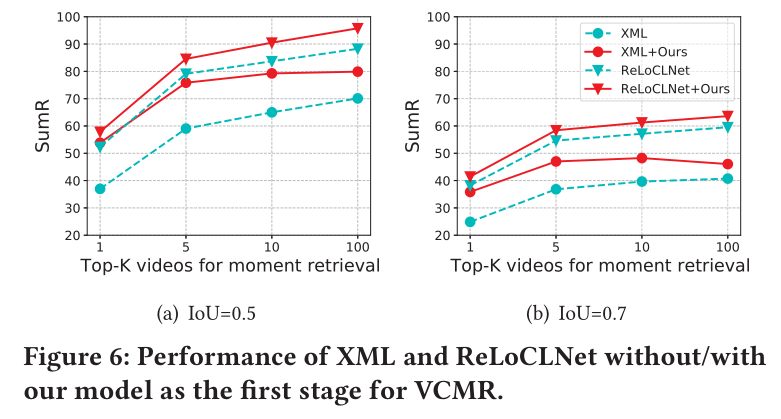
3.4 對VCMR模型的性能提升
VCMR任務旨在給定查詢文本后,在視頻庫中檢索出對應視頻,并且確定查詢文本在對應視頻中的起止時刻。當前用于VCMR任務的主流模型通常擁有兩個階段的工作流程。第一階段為從視頻庫中檢索出k個候選視頻,第二階段為從候選視頻中檢索出準確的起止時刻。
作者選取了當前性能較高的模型,XML和ReLoCLNet,將以上兩個模型在TVR數據集上的第一階段檢索結果替換為作者所提出模型的檢索結果,從下圖可以看出在進行替換后能給上述兩模型帶來VCMR任務上的性能提升。
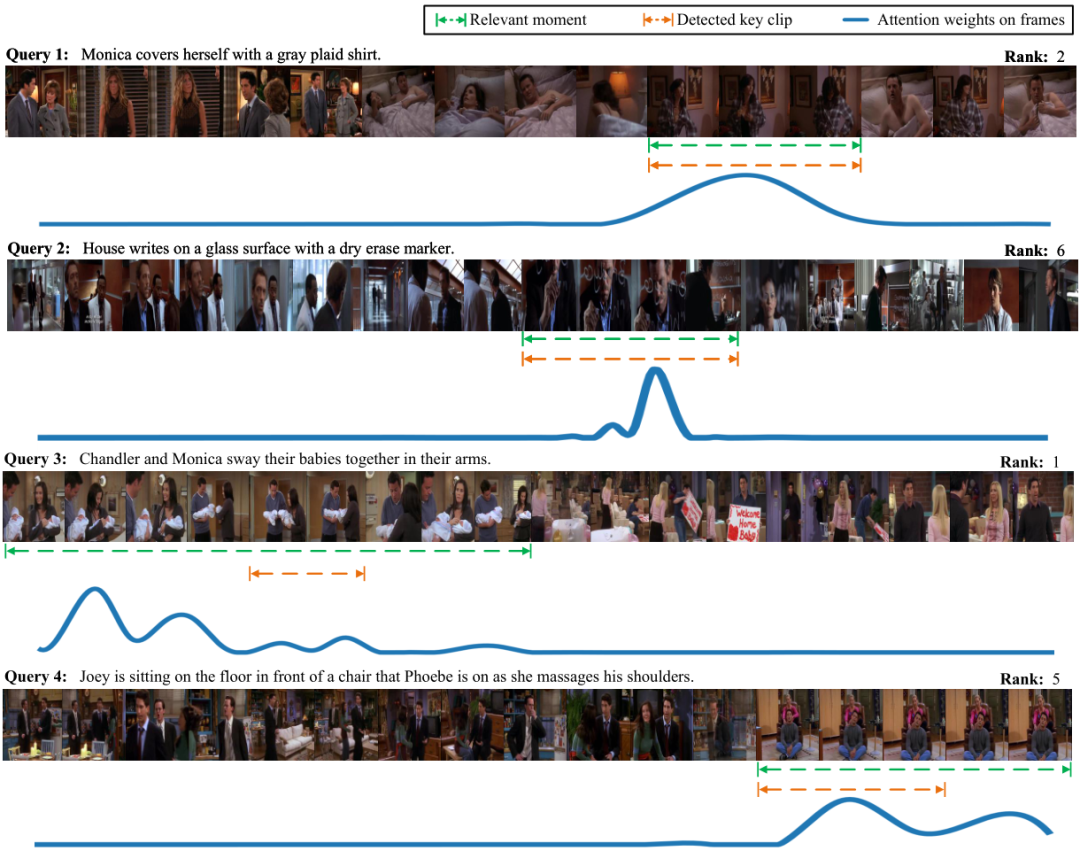
3.5 可視化展示
下圖作者給出了一些模型檢索過程中的可視化實例,分別給出了查詢文本在其對應視頻中由模型檢測出的關鍵片段范圍與關鍵片段和所有視頻幀之間的相似度曲線。
在前兩個查詢實例中,模型檢測出的關鍵片段與正確相關片段完全重合。在后兩個查詢實例中,檢測出的關鍵片段較為不準確,但是正確片段所包含的幀均具有較高的注意力權重。
這表明幀尺度相似度學習分支可以幫助片段尺度相似度學習分支在一定程度上補齊缺失信息,進一步反映了模型設計雙分支相似度學習模塊的合理性。
4. 結論
在本文中,針對傳統T2VR任務在現實中的局限性,作者提出了一個全新的文本到視頻跨模態檢索子任務PRVR。在PRVR中,查詢文本與對應視頻均呈部分相關關系而非傳統T2VR任務中的完全相關關系。對于PRVR,作者將其定義為多示例學習問題,并提出多尺度多示例網絡,它以從粗到細的方式計算查詢文本和長視頻在片段尺度和幀尺度上的相似性。在三個數據集上的實驗驗證了作者所提出的模型對于PRVR任務的有效性,并表明它也可以用于提升VCMR任務模型的性能。
審核編輯:劉清
-
ACM
+關注
關注
0文章
32瀏覽量
10318 -
cnn
+關注
關注
3文章
351瀏覽量
22178
原文標題:ACM MM 2022 Oral | PRVR: 新的文本到視頻跨模態檢索子任務
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
在TouchGFX中使用Modal時如何更改模態文本?
一種針對該文本檢索任務的BERT算法方案DR-BERT


基于食物圖片的食譜檢索技術
基于深度學習的特種車輛跨模態檢索和識別方法


如何去解決文本到圖像生成的跨模態對比損失問題?
一個真實閑聊多模態數據集TikTalk
ImageBind:跨模態之王,將6種模態全部綁定!


基于文本到圖像模型的可控文本到視頻生成

更強更通用:智源「悟道3.0」Emu多模態大模型開源,在多模態序列中「補全一切」

UniVL-DR: 多模態稠密向量檢索模型






 工商網監
工商網監
評論