 第一個大規模點云的自監督預訓練MAE算法Voxel-MAE
第一個大規模點云的自監督預訓練MAE算法Voxel-MAE
作者:Chen Min, Xinli Xu, Dawei Zhao, Liang Xiao, Yiming Nie, Bin Dai
基于掩碼的自監督預訓練方法在圖像和文本領域得到了成功的應用。但是,對于同樣信息冗余的大規模點云,基于掩碼的自監督預訓練學習的研究還沒有展開。在這篇文章中,我們提出了第一個將掩碼自編碼器引入大規模點云自監督預訓練學習的方法:Voxel-MAE。不同于2D MAE采用RGB像素回歸,3D點云數量巨大,無法直接學習每個點云的數據分布,因此Voxel-MAE將點云轉成體素形式,然后進行體素內是否包含點云的二分類任務學習。這種簡單但是有效的分類學習策略能使模型在體素級別上對物體形狀敏感,進而提高下游任務的精度。即使掩蔽率高達90%,Voxel-MAE依然可以學習有代表性的特征,這是因為大規模點云的冗余度非常高。另外考慮點云隨著距離增大變稀疏,設計了距離感知的掩碼策略。2D MAE的Transformer結構無法處理大規模點云,因此Voxel-MAE利用3D稀疏卷積來構建encoder,其中position encoding同樣可以只處理unmasked的體素。我們同時在無監督領域自適應任務上驗證了Voxel-MAE的遷移性能。Voxel-MAE證明了對大規模點云進行基于掩碼的自監督預訓練學習,來提高無人車的感知性能是可行的。KITTI、nuScenes、Waymo數據集上,SECOND、CenterPoint和PV-RCNN上的充分的實驗證明Voxel-MAE在大規模點云上的自監督預訓練性能。
Voxel-MAE是第一個大規模點云的自監督掩碼自編碼器預訓練方法。
不同于MAE中,Voxel-MAE為大規模點云設計了適合的體素二分類任務、距離感知的掩碼策略和3D稀疏卷積構建的encoder等。
Voxel-MAE的自監督掩碼自編碼器預訓練模型有效提升了SECOND、CenterPoint和PV-RCNN等算法在KITTI、nuScenes、Waymo數據集上的性能。
Voxel-MAE同時在無監督領域自適應3D目標檢測任務上驗證了遷移性能。
算法流程
![]()
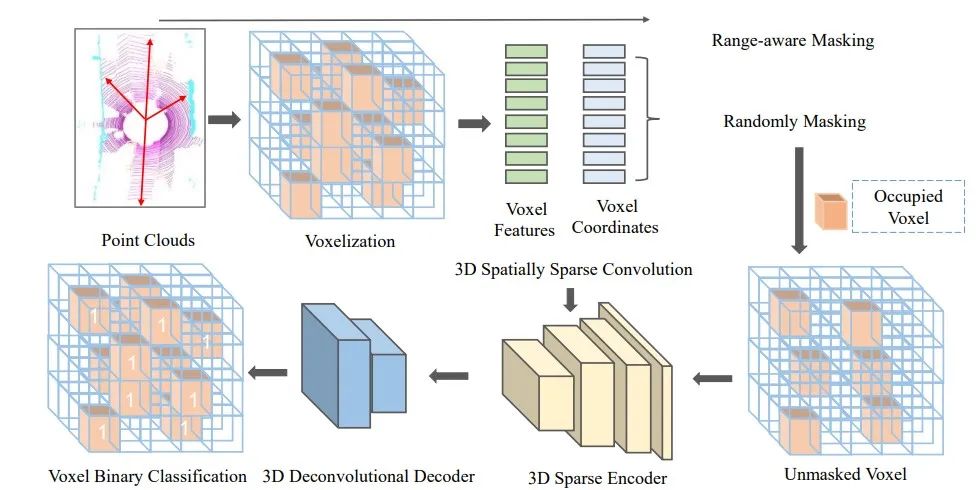
圖1 Voxel-MAE的整體框圖:首先將大規模點云轉成體素表示,然后采用距離感知的掩碼策略對體素進行mask,再將unmasked的體素送入不對稱的encoder-decoder網絡,重建體素。最后,采用判斷體素內是否包含點云的二分類交叉熵損失函數端到端訓練整個網絡。Encoder采用三維稀疏卷積網絡構建,Decoder采用三維反卷積實現。
Range-aware Masking
遵循常見的3D點云目標檢測的設置,我們將WXHXD范圍內的大規模點云沿著XYZ方向分成大小為VWXVHXVD的體素。所有體素的個數為nl,包含點云的體素個數為nv。
不同于2D圖像,3D點云的分布隨著離激光雷達的距離增加越來越稀疏。因此不能對不同位置的點云采用相同的掩碼策略。
對此我們設計了距離感知的掩碼策略。即對近處稠密的點云masking多,對遠處稀疏的點云masking少。具體我們將點云分成30米以內,30-50米,50米以外,然后分別采用r1,r2和r3三種掩碼率來對點云體素進行隨機掩蔽,其中r1》r2》r3。剩余的unmasked的體素個數為nun。對于所有包含點云的體素nl,我們將其點云體素分類目標設為1,其他設為0。
3D Sparse Convolutional Encoder
MAE論文中采用Transformer網絡架構對訓練集中的unmasked部分進行自注意力機制學習,不會被masked部分影響。但是由于unmasked的點云數量仍然很大,幾十萬級別,Transformer網絡無法處理如此大規模unmasked的點云數據。研究者通常采用3D SparseConvolutions來處理大規模稀疏3D點云。因此不同于2D MAE,Voxel-MAE采用3D SparseConvolutions來構建MAE中的encoder,其采用positional encoding來只對unmasked的體素聚合信息,從而類似MAE中的Transformer結構,可以降低訓練模型的計算復雜度。
3D Deconvolutional Decoder
Voxel-MAE采用3D反卷積構建decoder。最后一層輸出每個體素包含點云的概率。decoder網絡簡單,只用于訓練過程。
Voxel-MAE的encoder和decoder的結構如下:

Reconstruction Target
2D MAE中采用masked部分的RGB像素回歸作為掩碼自編碼器自監督學習的目標,但是3D點云的數量很大,回歸點云需要學習每個點云的數據分布,是難以學習的。
對于3D點云的體素表示,體素內是否包含點云非常重要。因此我們為Voxel-MAE設計了體素是否包含點云的二分類任務。目標是恢復masked的體素的位置信息。雖然分類任務很簡單,但是可以學習到大規模點云的數據分布信息,從而提高預訓練模型的性能。
實驗結果
![]()
采用OpenPCDet算法基準庫,在KITTI、nuScenes、Waymo數據集上進行了實驗驗證。
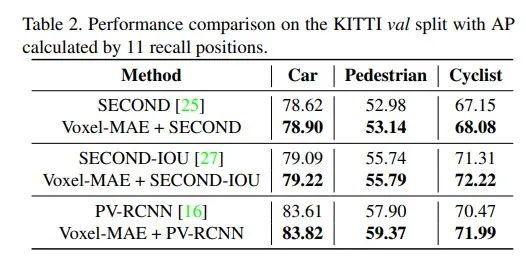
1.KITTI
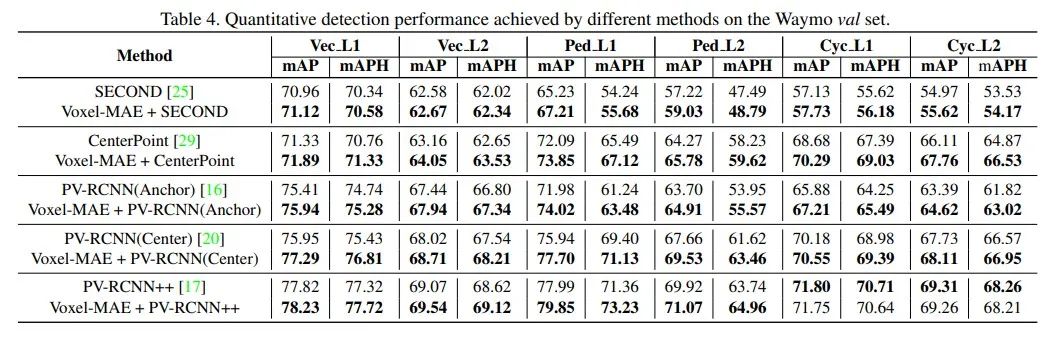
2. Waymo
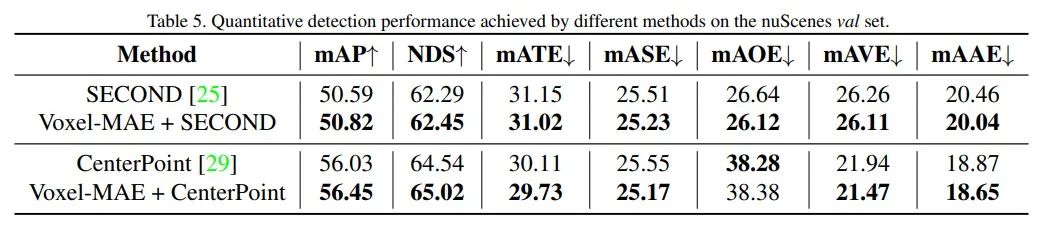
3. nuScenes
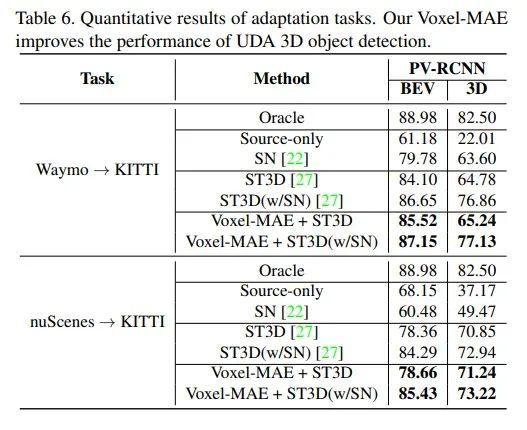
4. 3D點云無監督領域自適應任務驗證遷移性能
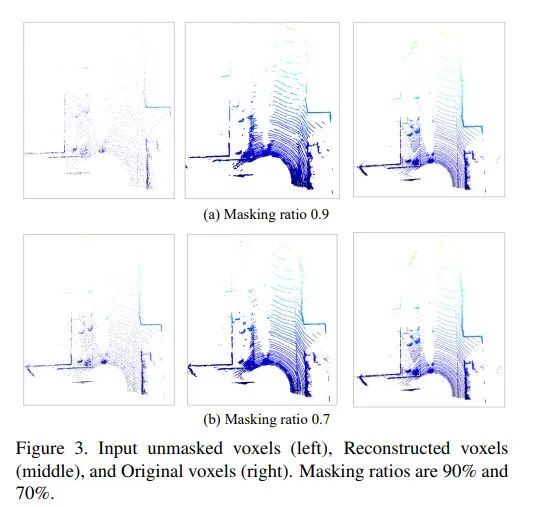
5. 3D點云重建可視化圖
審核編輯:郭婷
-
編碼器
+關注
關注
44文章
3529瀏覽量
133313 -
激光雷達
+關注
關注
967文章
3863瀏覽量
188767 -
數據集
+關注
關注
4文章
1197瀏覽量
24538
原文標題:Voxel-MAE: 第一個大規模點云的自監督預訓練MAE算法
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
名單公布!【書籍評測活動NO.30】大規模語言模型:從理論到實踐
一個大規模電路是怎么設計出來的???
AU1200 MAE驅動程序的開發流程是什么?
神經網絡在訓練時常用的一些損失函數介紹
AU 1200 MAE驅動程序開發流程


用于弱監督大規模點云語義分割的混合對比正則化框架
MAE再發力,跨模態交互式自編碼器PiMAE席卷3D目標檢測領域
PyTorch教程11.9之使用Transformer進行大規模預訓練

基礎模型自監督預訓練的數據之謎:大量數據究竟是福還是禍?

NeurIPS 2023 | 全新的自監督視覺預訓練代理任務:DropPos






 工商網監
工商網監
評論