") 基于重構(gòu)的方法存在的“恒等映射”問題
基于重構(gòu)的方法存在的“恒等映射”問題
Introduction
異常檢測已經(jīng)取得了非常突出的進(jìn)展。考慮到異常的多樣性,通常的異常檢測方案是首先擬合出正常樣本的分布,之后檢測該分布之外的離群點(diǎn)作為異常。因此,異常檢測需要學(xué)習(xí)出一個(gè)非常緊湊的正常樣本的邊界 (下圖a)。出于這種目的,當(dāng)前所有的異常檢測方法都只能用一個(gè)模型解決一個(gè)類別 (下圖c)。但是,這種“一個(gè)模型只處理一個(gè)類別”的separate setting是十分耗費(fèi)儲(chǔ)存空間的,并且無法處理正常樣本具有一定多樣性的場景 (比如,一種物體有多種正常的型號(hào))。

傳統(tǒng)的separate setting V.S. our unified setting
我們致力于解決一個(gè)更困難的unified setting,那就是用一個(gè)模型解決所有類別的異常檢測 (上圖d)。這就需要所有類別共享相同的分類邊界 (上圖b),因此,如何擬合出多類正常樣本的分布是十分重要的。
基于重構(gòu)的方法是一種常用的異常檢測方法。這種方法在正常樣本上訓(xùn)練一個(gè)重構(gòu)模型,并假設(shè)重構(gòu)只能在正常樣本上成功,對于異常樣本將會(huì)具有較大的重構(gòu)誤差。因此,重構(gòu)誤差可以作為異常評分。但是,基于重構(gòu)的方法會(huì)遇到“恒等映射”的問題。所謂“恒等映射”指的是,雖然重構(gòu)模型是在正常樣本上訓(xùn)練的,其遇到異常樣本同樣會(huì)重構(gòu)成功。這使得正常樣本和異常樣本的重構(gòu)誤差都很小,難以被區(qū)分開來。更重要的是,相比于傳統(tǒng)的separate setting,在unified setting下,正常樣本的分布更加復(fù)雜,這加劇了“恒等映射”的問題 (詳見paper的實(shí)驗(yàn)及分析)。
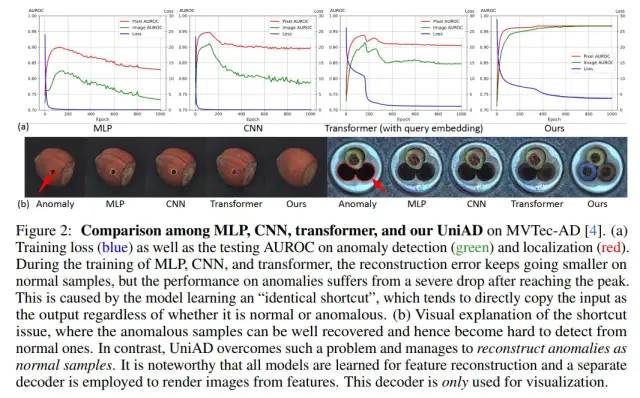
MLP, CNN, transformer都會(huì)遇到“恒等映射”的問題
我們首先follow了特征重構(gòu) [2] 的框架,并測試了3種通用的網(wǎng)絡(luò)架構(gòu)MLP、CNN、transformer (上圖)。我們發(fā)現(xiàn),3種網(wǎng)絡(luò)結(jié)構(gòu)都會(huì)遇到“恒等映射”的問題。這使得在訓(xùn)練過程中,重構(gòu)的loss (上圖藍(lán)線) 可以降到非常小,但其檢測性能 (上圖綠線) 和定位性能 (上圖紅線) 甚至?xí)S著loss的下降而下降。這證明了“恒等映射”的問題,即,可以非常好地完成重構(gòu),但卻無法區(qū)分正常和異常。
因此,我們希望,從重構(gòu)網(wǎng)絡(luò)的結(jié)構(gòu)設(shè)計(jì)上徹底解決“恒等映射”問題。具體的,我們提出了三個(gè)創(chuàng)新點(diǎn),構(gòu)成了我們的UniAD網(wǎng)絡(luò)。
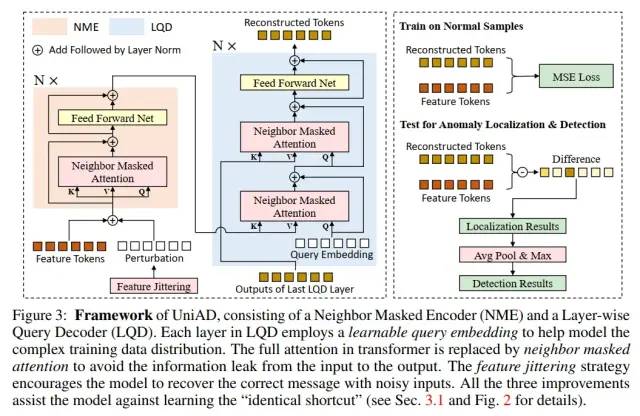
UniAD網(wǎng)絡(luò)結(jié)構(gòu)
創(chuàng)新點(diǎn)一:Layer-wise Query Embedding
我們觀察到,transformer中“恒等映射”的問題比MLP和CNN要輕微一些。第一,在transformer中,loss并不會(huì)完全降低到0。第二,在transformer中,檢測性能和定位性能的下降幅度遠(yuǎn)小于MLP和CNN。因此,我們認(rèn)為transformer中必然存在一種結(jié)構(gòu)可以抑制“恒等映射”。經(jīng)過數(shù)學(xué)分析和消融實(shí)驗(yàn),我們認(rèn)為,具有query embedding的attention可以抑制“恒等映射” (分析與實(shí)驗(yàn)詳見paper)。
但是,現(xiàn)有的transformer網(wǎng)絡(luò),一些不具有query embedding (如類似于ViT的),一些只在decoder的第一層有query embedding (如類似于DETR的)。我們希望通過增加query embedding,來增加其抑制“恒等映射”的能力。因此,我們以transformer為基礎(chǔ),提出了Layer-wise Query Embedding,即,在decoder的每一層都加入query embedding。
創(chuàng)新點(diǎn)二:Neighbor Masked Attention
我們認(rèn)為,在傳統(tǒng)的Attention中,一個(gè)token是可以利用自己的信息的,這可能會(huì)防止信息泄漏,即,直接將輸入進(jìn)行輸出,形成“恒等映射”。因此,我們提出了Neighbor Masked Attention,即,一個(gè)token是不能利用自己和自己的鄰居的信息的。這樣,網(wǎng)絡(luò)就必須通過更遠(yuǎn)處的token來理解這個(gè)點(diǎn)的信息應(yīng)該是什么,進(jìn)而在這個(gè)過程中理解了正常樣本,擬合了正常樣本的分布。
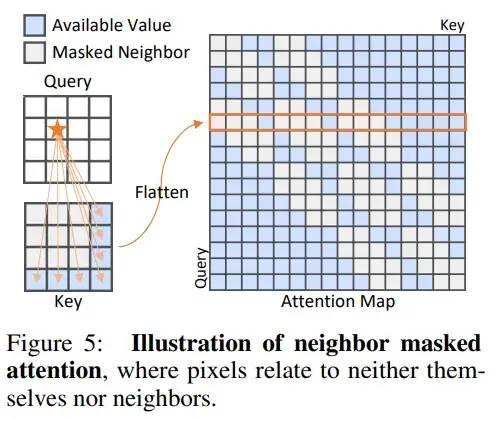
Neighbor Masked Attention
創(chuàng)新點(diǎn)三:Feature Jittering
受到De-noising Auto-Encoder的啟發(fā),我們設(shè)計(jì)了一個(gè)Feature Jittering策略。即,在輸入的feature tokens中加入噪聲,而重構(gòu)的目標(biāo)依然是未加噪聲的feature tokens。因此,F(xiàn)eature Jittering可以將重構(gòu)任務(wù)轉(zhuǎn)化為去噪任務(wù)。網(wǎng)絡(luò)通過去除噪聲來理解正常樣本,并擬合正常樣本的分布。同時(shí),恒等映射在這種情況下不能使得loss等于0,也就不是最優(yōu)解了。
性能對比
我們在MVTec-AD上“一個(gè)模型處理所有類別”的unified setting下,在檢測指標(biāo)上遠(yuǎn)超baseline達(dá)到了8.4%,在定位指標(biāo)上遠(yuǎn)超baseline達(dá)到了7.3%。
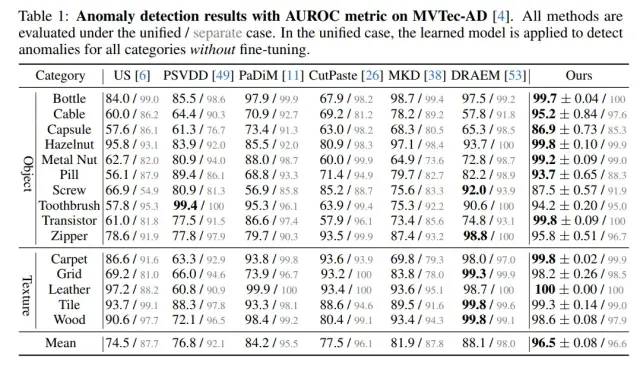
MVTec-AD的異常檢測指標(biāo)
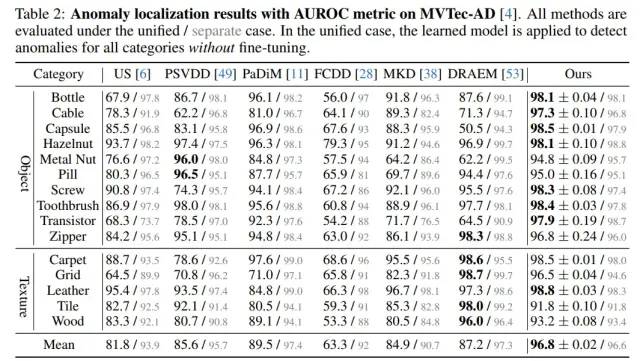
MVTec-AD的異常定位指標(biāo)
我們的異常檢測的可視化結(jié)果如下圖所示,從左到右依次為,正常 (作為reference)、異常、異常的重構(gòu)結(jié)果、ground-truth、我們的檢測結(jié)果。結(jié)果證明,我們的方法可以將異常重構(gòu)為對應(yīng)的正常,所以重構(gòu)的差異可以準(zhǔn)確地定位出異常區(qū)域。

可視化結(jié)果
我們還將unified setting拓展到了CIFAR-10數(shù)據(jù)集中,我們的方法同樣穩(wěn)定地超越了Baseline。
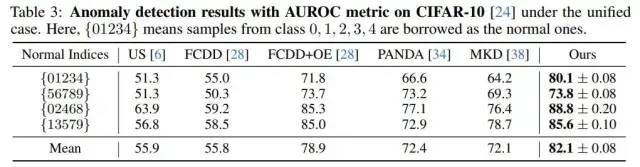
CIFAR-10的異常檢測指標(biāo)
消融實(shí)驗(yàn)
消融實(shí)驗(yàn)證明了我們所設(shè)計(jì)模塊的有效性。
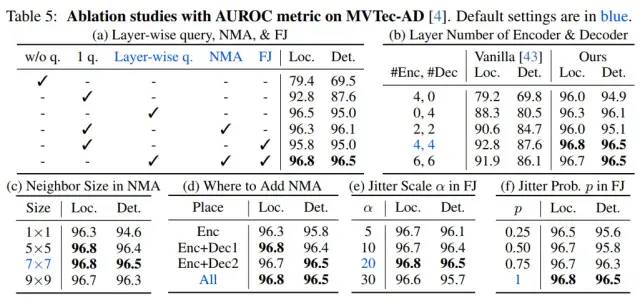
消融實(shí)驗(yàn)
結(jié)論
首先,我們提出了異常檢測的unified setting,即,可以僅僅使用一個(gè)模型,解決所有類別的異常檢測問題。之后,我們分析了基于重構(gòu)的方法存在的“恒等映射”問題,并針對性地提出了三點(diǎn)改進(jìn),形成了我們的UniAD網(wǎng)絡(luò)。我們的方法在MVTec-AD上,顯著地超越了baseline達(dá)到8.4% (異常檢測) 和7.3% (異常定位)。
-
異常檢測
+關(guān)注
關(guān)注
1文章
42瀏覽量
9730 -
模型
+關(guān)注
關(guān)注
1文章
3171瀏覽量
48711 -
網(wǎng)絡(luò)架構(gòu)
+關(guān)注
關(guān)注
1文章
92瀏覽量
12568
原文標(biāo)題:NeurIPS 2022 | 上交&清華等提出UniAD:一個(gè)模型解決所有類別的異常檢測!
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
FPGA的重構(gòu)方式
有什么FPGA可重構(gòu)方法可以對EPCS在線編程?
空間映射方法研究及其在LTCC設(shè)計(jì)中的應(yīng)用
大本體的分塊與映射方法研究
STEP模式映射的一種實(shí)用方法
基于對EPCS在線編程的FPGA可重構(gòu)方法
基于SFS方法的超空泡三維重構(gòu)研究

基于規(guī)范變量分析的數(shù)據(jù)重構(gòu)方法及應(yīng)用_盧娟
波形重構(gòu)的方法比較
基于單元相鄰關(guān)系的重構(gòu)區(qū)域構(gòu)造方法
一種多重映射的自動(dòng)短文摘方法

空間映射的分形圖像編碼方法
采用ARM和CPLD結(jié)構(gòu)的檢測系統(tǒng)可重構(gòu)設(shè)計(jì)方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論