 基于Transform的神經網絡結構FlowFormer用于光流量估計
基于Transform的神經網絡結構FlowFormer用于光流量估計
摘要 ? 大家好,今天為大家帶來的文章 A Transformer Architecture for Optical Flow 我們介紹了光流估計網絡,稱為FlowFormer,一種基于Transform的神經網絡架構,用于學習光流。FlowFormer化由圖像對構建的4D cost volume,將成本編碼到一個新的潛在空間中具有交替組轉換器(AGT)層的成本內存中,并通過一個帶有動態位置成本查詢的循環Transform解碼器對位置 cost queries進行解碼。在sinintel基準測試中,FlowFormer的平均終點誤差(AEPE)分別為1.159和2.088,比已發布的最佳結果誤差分別降低了16.5%和15.5%
? 大家好,今天為大家帶來的文章 A Transformer Architecture for Optical Flow 我們介紹了光流估計網絡,稱為FlowFormer,一種基于Transform的神經網絡架構,用于學習光流。FlowFormer化由圖像對構建的4D cost volume,將成本編碼到一個新的潛在空間中具有交替組轉換器(AGT)層的成本內存中,并通過一個帶有動態位置成本查詢的循環Transform解碼器對位置 cost queries進行解碼。在sinintel基準測試中,FlowFormer的平均終點誤差(AEPE)分別為1.159和2.088,比已發布的最佳結果誤差分別降低了16.5%和15.5%
主要工作與貢獻
? 我們的貢獻可以概括為四個方面。 1)我們提出了一種新的基于Transform的神經網絡結構FlowFormer,用于光流量估計,它實現了最先進的流量估計性能。 2)設計了一種新穎的cost volume編碼器,有效地將成本信息聚合為緊湊的潛在cost tokens。 3)我們提出了一種循環成本解碼器,該解碼器通過動態位置成本查詢循環解碼成本特征,迭代細化估計光流。 4)據我們所知,我們第一次驗證imagenet預先訓練的傳輸
方法
? 光流估計任務要求輸出逐像素位移場f: R2→R2,將源圖像的每個二維位置x∈R2 Is映射到目標圖像It對應的二維位置p = x+f (x)。為了充分利用現有的視覺Transform體系結構,以及之前基于cnn的光流估計方法廣泛使用的四維成本體積,我們提出了一種基于Transform的結構FlowFormer,它對四維成本體積進行編碼和解碼,以實現精確的光流估計。在圖1中,我們展示了FlowFormer的總體架構,它處理來自siamese特征的4D成本卷,包含兩個主要組件: 1)cost volume編碼器,將4D成本卷編碼到潛在空間中形成cost memory; 2)成本記憶解碼器,用于基于編碼的成本記憶和上下文特征預測每像素位移場。 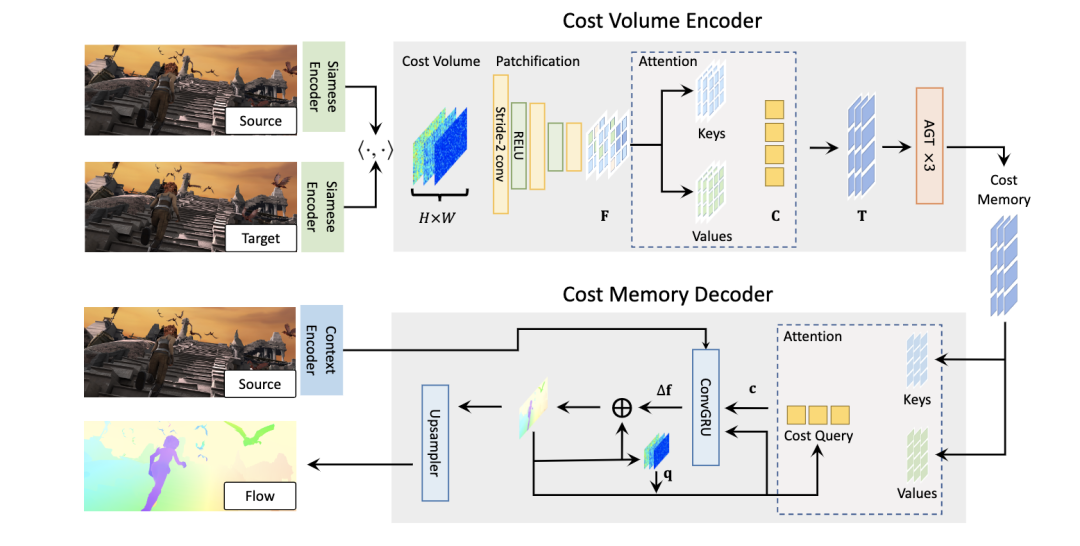 圖1 FlowFormer的體系結構。FlowFormer通過三個步驟估算光流量:1)根據圖像特征構建4Dcost volume。2)成本卷編碼器,將成本卷編碼到成本內存中。3)循環Transform解碼器,將具有源圖像上下文特征的代價內存解碼為流 1.1 構建 4D Cost Volume 骨干網用于從輸入HI × WI × 3rgb圖像中提取H ×W ×Df特征圖,通常我們設置(H, W) = (HI /8, WI /8)。在提取出源圖像和目標圖像的特征圖后,通過計算源圖像和目標圖像之間所有像素對的點積相似度,構造H × W × H × W 4D代價體。 3.2 Cost Volume Encoder 為了估計光流,需要基于4D代價體中編碼的源目標視覺相似性來識別源像素在目標圖像中的對應位置。構建的4D成本體積可以被視為一系列大小為H × W的2D成本圖,每個成本圖度量單個源像素和所有目標像素之間的視覺相似性。我們將源像素x的代價映射表示為Mx∈RH×W。 在這樣的成本圖中找到對應的位置通常是具有挑戰性的,因為在兩個圖像中可能存在重復的模式和非歧視性區域。當只考慮來自地圖局部窗口的成本時,任務變得更加具有挑戰性,就像以前基于cnn的光流估計方法所做的那樣。即使是估計單個源像素的精確位移,考慮其上下文源像素的代價圖也是有益的。 為了解決這一難題,我們提出了一種基于Transform的成本體積編碼器,該編碼器將整個成本體積編碼到成本內存中。我們的成本卷編碼器包括三個步驟:1)成本映射補丁化,2)成本補丁嵌入,3)成本內存編碼。我們詳細闡述這三個步驟如下。 1.2 地圖patchification成本我們根據已有的視覺轉換器,對每個源像素x的代價映射Mx∈RH×W進行跨卷積拼接,得到代價補丁嵌入序列。具體來說,給定一個H ×Wcost圖,我們首先在它的右側和底部填充0,使其寬度和高度為8的倍數。然后,填充的代價映射通過三個stride-2卷積的堆棧和ReLU轉換為特征映射Fx∈R?H/8?×?W/8?×Dp。特征圖中的每個特征代表輸入成本圖中的一個8 × 8補丁。三種卷積的輸出通道均為Dp / 4, Dp / 2 Dp。 1.3基于潛在摘要的補丁特征標記盡管對每個源像素進行修補會得到一系列cost patch特征向量,但這種patch特征的數量仍然很大,影響了信息在不同源像素間傳播的效率。實際上,成本圖是高度冗余的,因為只有少數高成本是最有信息的。為了獲得更緊湊的代價特征,我們進一步通過K個潛碼字C∈RK×D總結了每個源像素x的patch特征Fx。具體來說,latent codewords query每個源像素的cost補丁特征,通過點積注意機制將每個成本圖進一步總結為K個D維的潛在向量。潛碼字C∈RK×D隨機初始化,通過反向傳播進行更新,并在所有源像素之間共享。歸納Fx的潛在表示Tx得到為
圖1 FlowFormer的體系結構。FlowFormer通過三個步驟估算光流量:1)根據圖像特征構建4Dcost volume。2)成本卷編碼器,將成本卷編碼到成本內存中。3)循環Transform解碼器,將具有源圖像上下文特征的代價內存解碼為流 1.1 構建 4D Cost Volume 骨干網用于從輸入HI × WI × 3rgb圖像中提取H ×W ×Df特征圖,通常我們設置(H, W) = (HI /8, WI /8)。在提取出源圖像和目標圖像的特征圖后,通過計算源圖像和目標圖像之間所有像素對的點積相似度,構造H × W × H × W 4D代價體。 3.2 Cost Volume Encoder 為了估計光流,需要基于4D代價體中編碼的源目標視覺相似性來識別源像素在目標圖像中的對應位置。構建的4D成本體積可以被視為一系列大小為H × W的2D成本圖,每個成本圖度量單個源像素和所有目標像素之間的視覺相似性。我們將源像素x的代價映射表示為Mx∈RH×W。 在這樣的成本圖中找到對應的位置通常是具有挑戰性的,因為在兩個圖像中可能存在重復的模式和非歧視性區域。當只考慮來自地圖局部窗口的成本時,任務變得更加具有挑戰性,就像以前基于cnn的光流估計方法所做的那樣。即使是估計單個源像素的精確位移,考慮其上下文源像素的代價圖也是有益的。 為了解決這一難題,我們提出了一種基于Transform的成本體積編碼器,該編碼器將整個成本體積編碼到成本內存中。我們的成本卷編碼器包括三個步驟:1)成本映射補丁化,2)成本補丁嵌入,3)成本內存編碼。我們詳細闡述這三個步驟如下。 1.2 地圖patchification成本我們根據已有的視覺轉換器,對每個源像素x的代價映射Mx∈RH×W進行跨卷積拼接,得到代價補丁嵌入序列。具體來說,給定一個H ×Wcost圖,我們首先在它的右側和底部填充0,使其寬度和高度為8的倍數。然后,填充的代價映射通過三個stride-2卷積的堆棧和ReLU轉換為特征映射Fx∈R?H/8?×?W/8?×Dp。特征圖中的每個特征代表輸入成本圖中的一個8 × 8補丁。三種卷積的輸出通道均為Dp / 4, Dp / 2 Dp。 1.3基于潛在摘要的補丁特征標記盡管對每個源像素進行修補會得到一系列cost patch特征向量,但這種patch特征的數量仍然很大,影響了信息在不同源像素間傳播的效率。實際上,成本圖是高度冗余的,因為只有少數高成本是最有信息的。為了獲得更緊湊的代價特征,我們進一步通過K個潛碼字C∈RK×D總結了每個源像素x的patch特征Fx。具體來說,latent codewords query每個源像素的cost補丁特征,通過點積注意機制將每個成本圖進一步總結為K個D維的潛在向量。潛碼字C∈RK×D隨機初始化,通過反向傳播進行更新,并在所有源像素之間共享。歸納Fx的潛在表示Tx得到為 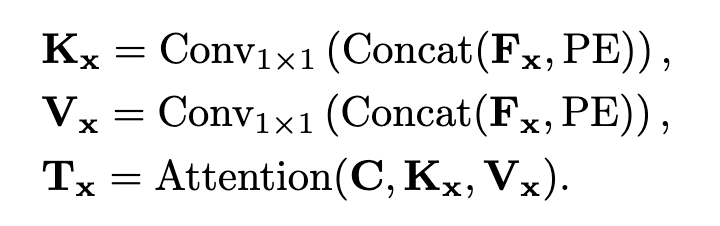 在投影成本-補丁特征Fx以獲得鍵Kx和值Vx之前,將補丁特征與位置嵌入序列PE∈R?H/8?×?W/8?×Dp進行拼接。給定一個2D位置p,我們將其編碼為一個長度為Dp的位置嵌入,跟隨COTR[27]。最后,通過對查詢、鍵和值進行多頭點積注意,可以將源像素x的代價圖匯總為K個潛在表示Tx∈RK×D。 關注潛在cost空間。上述兩個階段將原始的4D成本體積轉化為潛在的、緊湊的4D成本體積t。但是,直接對4D體積中的所有向量應用自注意仍然過于昂貴,因為計算成本隨tokens數量的增加呈二次增長。 如圖2所示,我們提出了一種交替分組轉換層(AGT),該層以兩種相互正交的方式對標記進行分組,并在兩組中交替應用注意,減少了注意成本,同時仍然能夠在所有標記之間傳播信息。
在投影成本-補丁特征Fx以獲得鍵Kx和值Vx之前,將補丁特征與位置嵌入序列PE∈R?H/8?×?W/8?×Dp進行拼接。給定一個2D位置p,我們將其編碼為一個長度為Dp的位置嵌入,跟隨COTR[27]。最后,通過對查詢、鍵和值進行多頭點積注意,可以將源像素x的代價圖匯總為K個潛在表示Tx∈RK×D。 關注潛在cost空間。上述兩個階段將原始的4D成本體積轉化為潛在的、緊湊的4D成本體積t。但是,直接對4D體積中的所有向量應用自注意仍然過于昂貴,因為計算成本隨tokens數量的增加呈二次增長。 如圖2所示,我們提出了一種交替分組轉換層(AGT),該層以兩種相互正交的方式對標記進行分組,并在兩組中交替應用注意,減少了注意成本,同時仍然能夠在所有標記之間傳播信息。 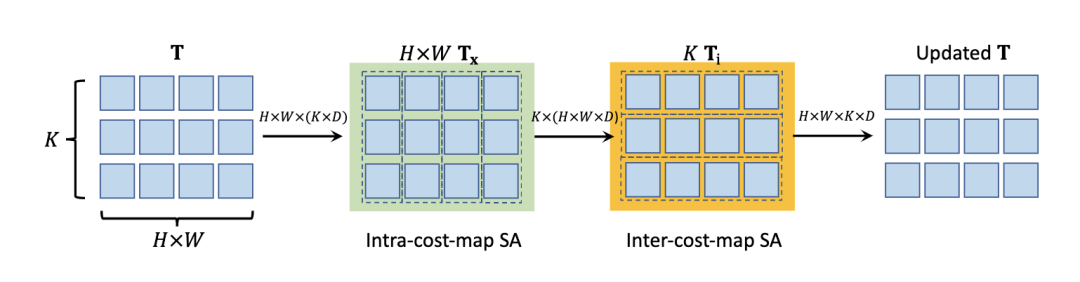 圖2 Alternate-Group Transform層。交替組轉換層(AGT)將T中的token交替分組為包含K token的H × W組(Tx)和包含H × W token的K組(Ti),并分別通過self-attention和ss self-attention[8]對組內的token進行編碼。 對每個源像素進行第一次分組,即每個Tx∈RK×D組成一個組,在每個組內進行自我注意。
圖2 Alternate-Group Transform層。交替組轉換層(AGT)將T中的token交替分組為包含K token的H × W組(Tx)和包含H × W token的K組(Ti),并分別通過self-attention和ss self-attention[8]對組內的token進行編碼。 對每個源像素進行第一次分組,即每個Tx∈RK×D組成一個組,在每個組內進行自我注意。 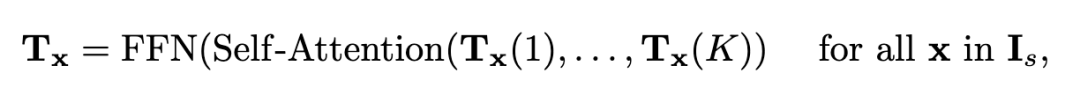 在每個源像素x的所有K個潛在令牌之間進行自注意后,更新的Tx通過前饋網絡(FFN)進一步變換,然后重新組織,形成更新的4D成本體積t。自注意子層和FFN子層均采用Transform殘差連接和層歸一化的共同設計。這種自我注意操作在每個成本映射內傳播信息,我們將其命名為內部成本映射的自我注意。 第二種方法根據K種不同的潛在表示,將所有潛在代價令牌T∈RH×W ×K×D分成K組。因此,每一組都有D維度的(H × W)標記,用于通過雙胞胎[8]中提出的空間可分離的自我注意(SS-SelfAttention)在空間域中傳播信息, 上述自我注意操作的參數在不同組之間共享,并按順序進行操作,形成提出的交替組注意層。通過多次疊加交替組Transform層,潛在成本令牌可以有效地跨源像素和跨潛在表示交換信息,以更好地編碼4D成本體積。通過這種方式,我們的成本體積編碼器將H × W × H × W 4D成本體積轉換為H × W × K長度為d的潛在標記。我們將最終的H × W × K標記稱為成本存儲器,用于光學解碼。 1.4用于流量估計的成本記憶解碼器 考慮到成本體積編碼器編碼的cost記憶,我們提出了一種用于光流預測的cost記憶解碼器。由于輸入圖像的原始分辨率為HI × WI,我們在H × W分辨率下估計光流,然后使用可學習的凸上采樣器[46]對預測的流進行上采樣到原始分辨率。然而,與以往的視覺Transform尋找抽象的語義特征不同,光流估計需要從記憶中恢復密集的對應。受RAFT[46]的啟發,我們建議使用成本查詢從cost內存中檢索成本特征,并使用循環注意解碼器層迭代優化流量預測。 1.5Cost memory aggregation:為了預測H × W源像素的流,我們生成了一個(H × W)成本查詢序列,每個(H × W)成本查詢通過對成本內存的共同關注負責估計單個源像素的流。為了為源像素x生成成本查詢Qx,我們首先計算其在目標圖像中的對應位置,給定其當前估計流量f (x),即p = x + f (x)。 然后,通過裁剪成本映射Mx上以p為中心的9×9本地窗口內的成本,我們檢索一個局部9×9成本映射補丁qx = Crop9×9(Mx, p)。然后根據局部成本Qx編碼的特征FFN(Qx)和p的位置嵌入PE(p)構造成本查詢Qx,通過交叉注意聚合源像素x的成本記憶Tx信息。 循環光流預測。我們的成本解碼器迭代回歸流量殘差?f (x),將每個源像素x的流量細化為f (x)←f (x) +?f (x)。我們采用ConvGRU模塊,并遵循與GMARAFT[25]類似的設計進行流量細化。然而,我們的循環模塊的關鍵區別是使用成本查詢來自適應地聚合來自成本內存的信息,以實現更精確的流量估計。具體來說,在每次迭代中,ConvGRU單元將檢索到的成本特征和成本映射補丁Concat(cx, qx)、來自上下文網絡的源圖像上下文特征tx和當前估計的流量f的拼接作為輸入,并輸出預測的流量殘差如下
在每個源像素x的所有K個潛在令牌之間進行自注意后,更新的Tx通過前饋網絡(FFN)進一步變換,然后重新組織,形成更新的4D成本體積t。自注意子層和FFN子層均采用Transform殘差連接和層歸一化的共同設計。這種自我注意操作在每個成本映射內傳播信息,我們將其命名為內部成本映射的自我注意。 第二種方法根據K種不同的潛在表示,將所有潛在代價令牌T∈RH×W ×K×D分成K組。因此,每一組都有D維度的(H × W)標記,用于通過雙胞胎[8]中提出的空間可分離的自我注意(SS-SelfAttention)在空間域中傳播信息, 上述自我注意操作的參數在不同組之間共享,并按順序進行操作,形成提出的交替組注意層。通過多次疊加交替組Transform層,潛在成本令牌可以有效地跨源像素和跨潛在表示交換信息,以更好地編碼4D成本體積。通過這種方式,我們的成本體積編碼器將H × W × H × W 4D成本體積轉換為H × W × K長度為d的潛在標記。我們將最終的H × W × K標記稱為成本存儲器,用于光學解碼。 1.4用于流量估計的成本記憶解碼器 考慮到成本體積編碼器編碼的cost記憶,我們提出了一種用于光流預測的cost記憶解碼器。由于輸入圖像的原始分辨率為HI × WI,我們在H × W分辨率下估計光流,然后使用可學習的凸上采樣器[46]對預測的流進行上采樣到原始分辨率。然而,與以往的視覺Transform尋找抽象的語義特征不同,光流估計需要從記憶中恢復密集的對應。受RAFT[46]的啟發,我們建議使用成本查詢從cost內存中檢索成本特征,并使用循環注意解碼器層迭代優化流量預測。 1.5Cost memory aggregation:為了預測H × W源像素的流,我們生成了一個(H × W)成本查詢序列,每個(H × W)成本查詢通過對成本內存的共同關注負責估計單個源像素的流。為了為源像素x生成成本查詢Qx,我們首先計算其在目標圖像中的對應位置,給定其當前估計流量f (x),即p = x + f (x)。 然后,通過裁剪成本映射Mx上以p為中心的9×9本地窗口內的成本,我們檢索一個局部9×9成本映射補丁qx = Crop9×9(Mx, p)。然后根據局部成本Qx編碼的特征FFN(Qx)和p的位置嵌入PE(p)構造成本查詢Qx,通過交叉注意聚合源像素x的成本記憶Tx信息。 循環光流預測。我們的成本解碼器迭代回歸流量殘差?f (x),將每個源像素x的流量細化為f (x)←f (x) +?f (x)。我們采用ConvGRU模塊,并遵循與GMARAFT[25]類似的設計進行流量細化。然而,我們的循環模塊的關鍵區別是使用成本查詢來自適應地聚合來自成本內存的信息,以實現更精確的流量估計。具體來說,在每次迭代中,ConvGRU單元將檢索到的成本特征和成本映射補丁Concat(cx, qx)、來自上下文網絡的源圖像上下文特征tx和當前估計的流量f的拼接作為輸入,并輸出預測的流量殘差如下 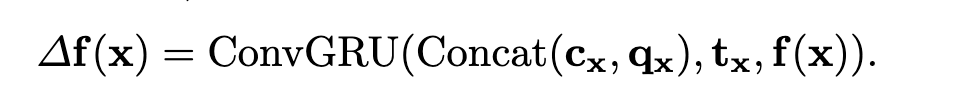

實驗結果
? 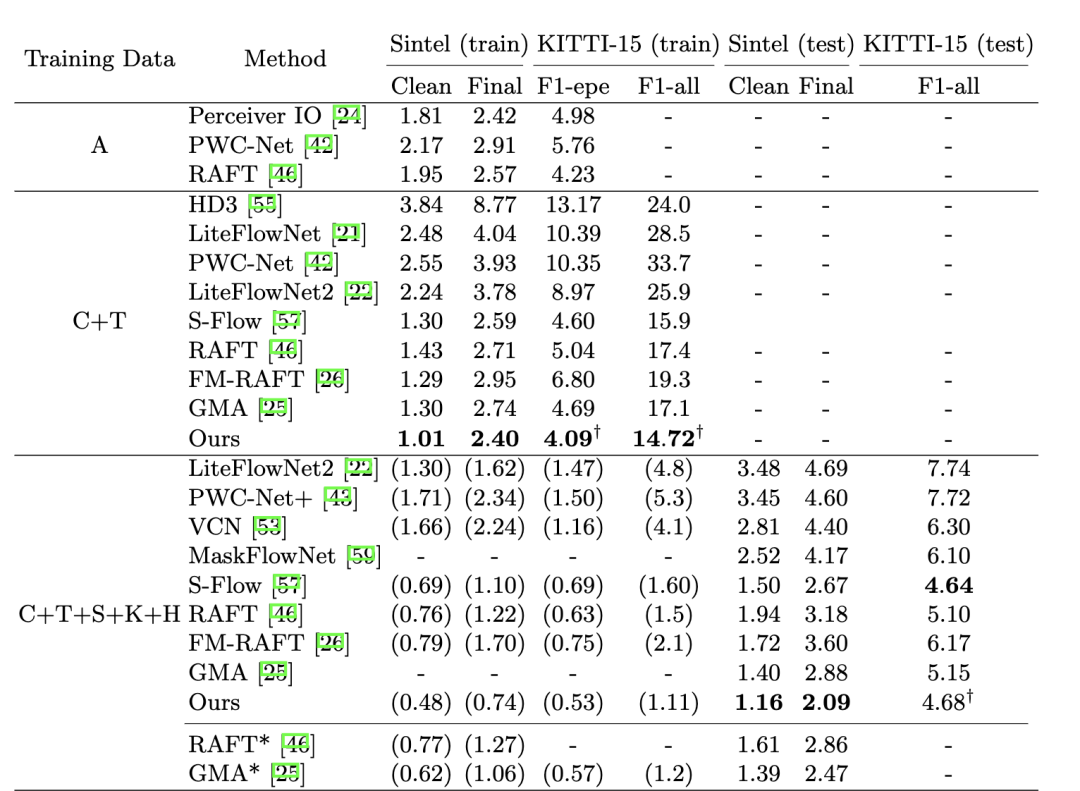 圖4 Sintel[3]和KITTI[14]數據集的實驗。' A '表示自動流數據集。“C + T”表示只在FlyingChairs和FlyingThings數據集上進行訓練。' + S + K + H '表示對Sintel、KITTI和HD1K訓練集的組合進行微調。*表示這些方法使用warm-start策略[46],該策略依賴于視頻中先前的圖像幀。?是通過補充闡述的瓦技術估計的。我們的FlowFormer實現了最佳的泛化性能(C+T),并在Sintel基準測試(C+T+S+K+H)中排名第一。
圖4 Sintel[3]和KITTI[14]數據集的實驗。' A '表示自動流數據集。“C + T”表示只在FlyingChairs和FlyingThings數據集上進行訓練。' + S + K + H '表示對Sintel、KITTI和HD1K訓練集的組合進行微調。*表示這些方法使用warm-start策略[46],該策略依賴于視頻中先前的圖像幀。?是通過補充闡述的瓦技術估計的。我們的FlowFormer實現了最佳的泛化性能(C+T),并在Sintel基準測試(C+T+S+K+H)中排名第一。  圖5 在steint檢驗集上的定性比較。FlowFormer大大減少了對象邊界(紅色箭頭所指)周圍的流動泄漏,并使細節(藍色箭頭所指)更加清晰。
圖5 在steint檢驗集上的定性比較。FlowFormer大大減少了對象邊界(紅色箭頭所指)周圍的流動泄漏,并使細節(藍色箭頭所指)更加清晰。 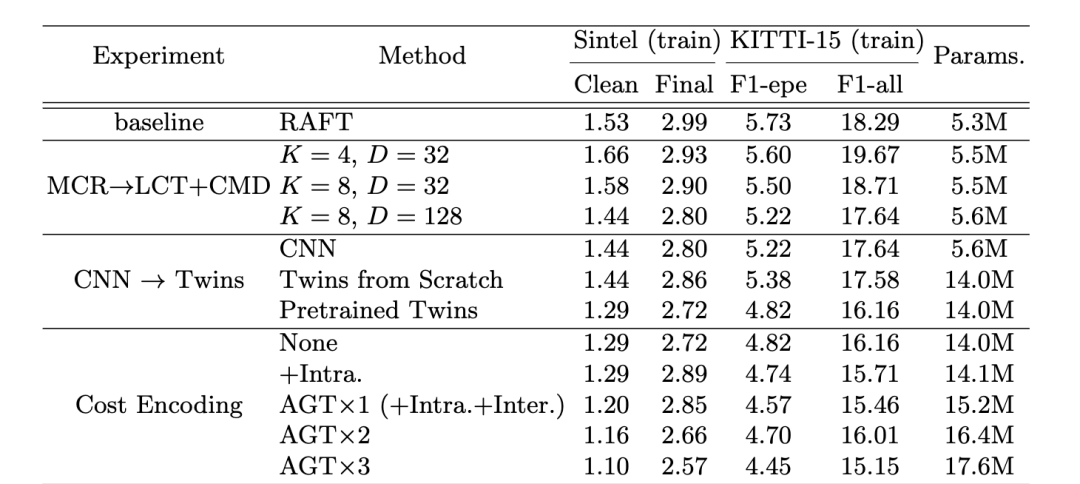 圖5 在steint檢驗集上的定性比較。FlowFormer大大減少了對象邊界(紅色箭頭所指)周圍的流動泄漏,并使細節(藍色箭頭所指)更加清晰。?
圖5 在steint檢驗集上的定性比較。FlowFormer大大減少了對象邊界(紅色箭頭所指)周圍的流動泄漏,并使細節(藍色箭頭所指)更加清晰。?
-
轉換器
+關注
關注
27文章
8624瀏覽量
146861 -
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
流量
+關注
關注
0文章
244瀏覽量
23881
原文標題:FlowFormer: Transformer結構光流估計(arXiv 2022)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
神經網絡結構搜索有什么優勢?
卷積神經網絡模型發展及應用

基于神經網絡結構在命名實體識別中應用的分析與總結

一種新型神經網絡結構:膠囊網絡
一種改進的深度神經網絡結構搜索方法

卷積神經網絡結構優化綜述






 工商網監
工商網監
評論