 用于模型評估和選擇的常見方法
用于模型評估和選擇的常見方法
摘要:模型評估、模型選擇和算法選擇技術的正確使用在學術性機器學習研究和諸多產業環境中異常關鍵。本文回顧了用于解決以上三項任務中任何一個的不同技術,并參考理論和實證研究討論了每一項技術的主要優勢和劣勢。進而,給出建議以促進機器學習研究與應用方面的最佳實踐。本文涵蓋了用于模型評估和選擇的常見方法,比如留出方法,但是不推薦用于小數據集。不同風格的 bootstrap 技術也被介紹,以評估性能的不確定性,以作為通過正態空間的置信區間的替代,如果 bootstrapping 在計算上是可行的。在討論偏差-方差權衡時,把 leave-one-out 交叉驗證和 k 折交叉驗證進行對比,并基于實證證據給出 k 的最優選擇的實際提示。論文展示了用于算法對比的不同統計測試,以及處理多種對比的策略(比如綜合測試、多對比糾正)。最后,當數據集很小時,本文推薦替代方法(比如 5×2cv 交叉驗證和嵌套交叉驗證)以對比機器學習算法。
1 簡介:基本的模型評估項和技術
機器學習已經成為我們生活的中心,無論是作為消費者、客戶、研究者還是從業人員。無論將預測建模技術應用到研究還是商業問題,我認為其共同點是:做出足夠好的預測。用模型擬合訓練數據是一回事,但我們如何了解模型的泛化能力?我們如何確定模型是否只是簡單地記憶訓練數據,無法對未見過的樣本做出好的預測?還有,我們如何選擇好的模型呢?也許還有更好的算法可以處理眼前的問題呢?
模型評估當然不是機器學習工作流程的終點。在處理數據之前,我們希望事先計劃并使用合適的技術。本文將概述這類技術和選擇方法,并介紹如何將其應用到更大的工程中,即典型的機器學習工作流。
1.1 性能評估:泛化性能 vs. 模型選擇
讓我們考慮這個問題:「如何評估機器學習模型的性能?」典型的回答可能是:「首先,將訓練數據饋送給學習算法以學習一個模型。第二,預測測試集的標簽。第三,計算模型對測試集的預測準確率。」然而,評估模型性能并非那么簡單。也許我們應該從不同的角度解決之前的問題:「為什么我們要關心性能評估呢?」理論上,模型的性能評估能給出模型的泛化能力,在未見過的數據上執行預測是應用機器學習或開發新算法的主要問題。通常,機器學習包含大量實驗,例如超參數調整。在訓練數據集上用不同的超參數設置運行學習算法最終會得到不同的模型。由于我們感興趣的是從該超參數設置中選擇最優性能的模型,因此我們需要找到評估每個模型性能的方法,以將它們進行排序。
我們需要在微調算法之外更進一步,即不僅僅是在給定的環境下實驗單個算法,而是對比不同的算法,通常從預測性能和計算性能方面進行比較。我們總結一下評估模型的預測性能的主要作用:
評估模型的泛化性能,即模型泛化到未見過數據的能力;
通過調整學習算法和在給定的假設空間中選擇性能最優的模型,以提升預測性能;
確定最適用于待解決問題的機器學習算法。因此,我們可以比較不同的算法,選擇其中性能最優的模型;或者選擇算法的假設空間中的性能最優模型。
雖然上面列出的三個子任務都是為了評估模型的性能,但是它們需要使用的方法是不同的。本文將概述解決這些子任務需要的不同方法。
我們當然希望盡可能精確地預測模型的泛化性能。然而,本文的一個要點就是,如果偏差對所有模型的影響是等價的,那么偏差性能評估基本可以完美地進行模型選擇和算法選擇。如果要用排序選擇最優的模型或算法,我們只需要知道它們的相對性能就可以了。例如,如果所有的性能評估都是有偏差的,并且低估了它們的性能(10%),這不會影響最終的排序。更具體地說,如果我們得到如下三個模型,這些模型的預測準確率如下:
M2: 75% > M1: 70% > M3: 65%,
如果我們添加了 10% 的性能偏差(低估),則三種模型的排序沒有發生改變:
M2: 65% > M1: 60% > M3: 55%.
但是,注意如果最佳模型(M2)的泛化準確率是 65%,很明顯這個精度是非常低的。評估模型的絕對性能可能是機器學習中最難的任務之一。
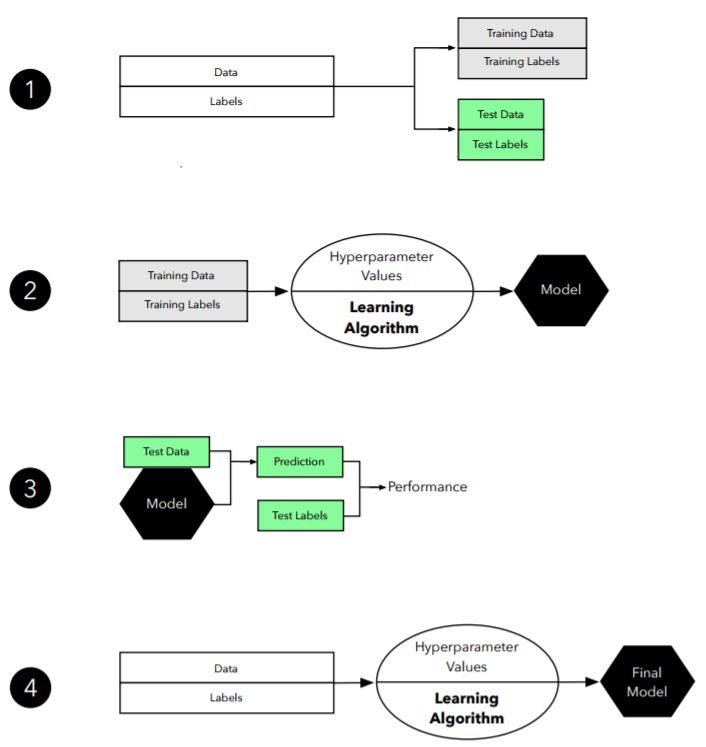
圖 2:留出驗證方法的圖示。
2 Bootstrapping 和不確定性 
本章介紹一些用于模型評估的高級技術。我們首先討論用來評估模型性能不確定性和模型方差、穩定性的技術。之后我們將介紹交叉驗證方法用于模型選擇。如第一章所述,關于我們為什么要關心模型評估,存在三個相關但不同的任務或原因。
我們想評估泛化準確度,即模型在未見數據上的預測性能。
我們想通過調整學習算法、從給定假設空間中選擇性能最好的模型,來改善預測性能。
我們想確定手頭最適合待解決問題的機器學習算法。因此,我們想對比不同的算法,選出性能最好的一個;或從算法的假設空間中選出性能最好的模型。
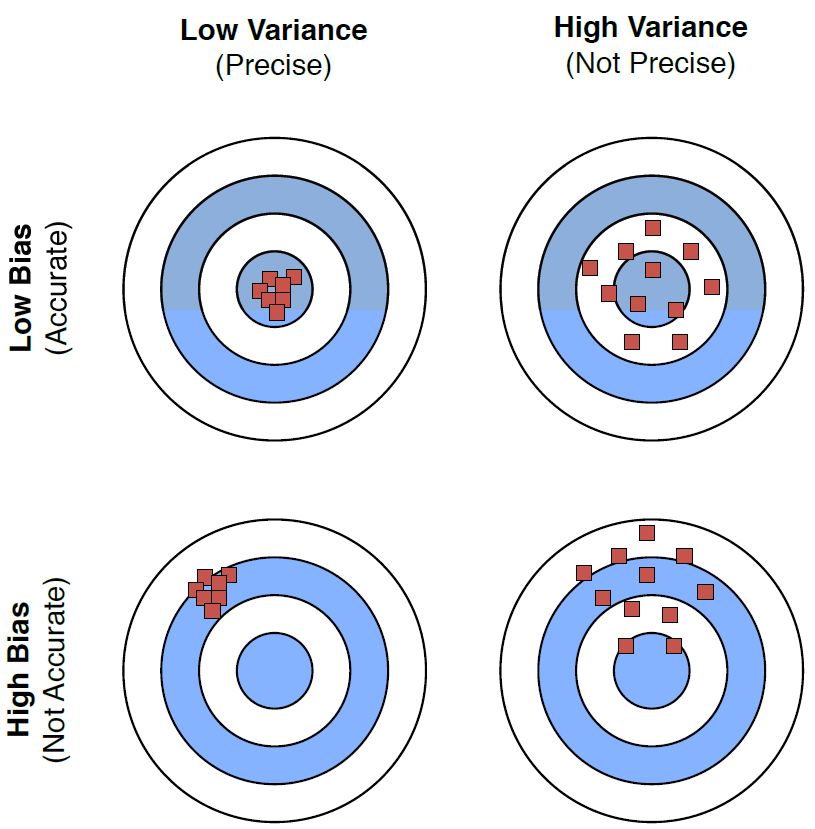
圖 3:偏差和方差的不同組合的圖示。
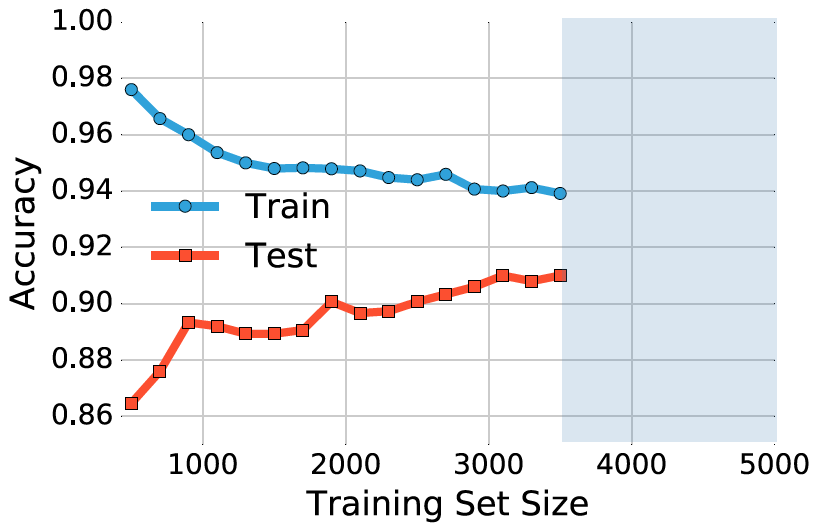
圖 4:在 MNIST 數據集上 softmax 分類器的學習曲線。
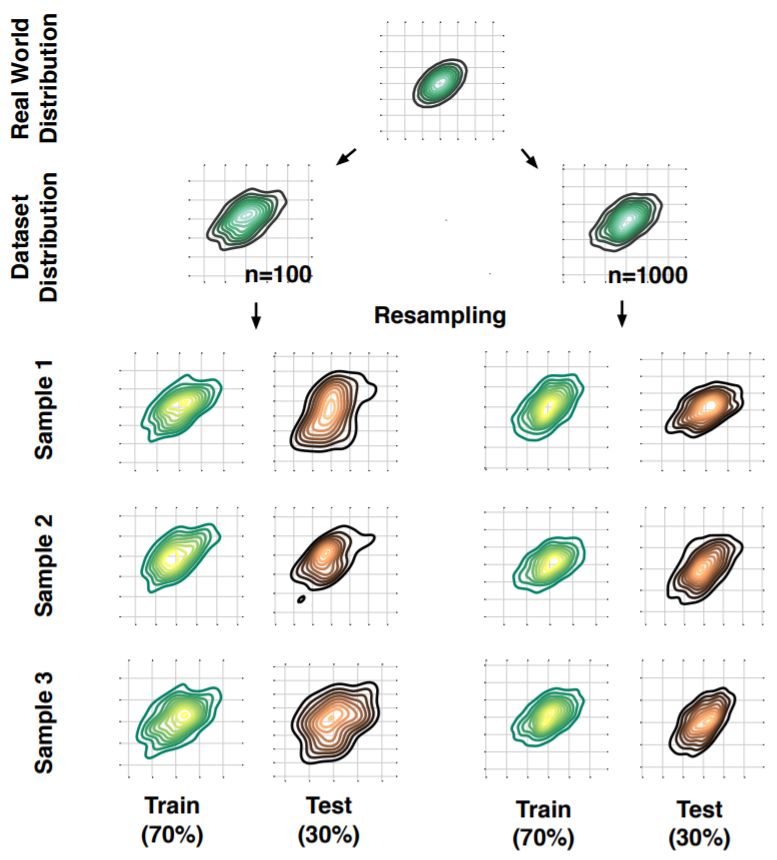
圖 5:二維高斯分布中的重復子采樣。
3 交叉驗證和超參數優化
幾乎所有機器學習算法都需要我們機器學習研究者和從業者指定大量設置。這些超參數幫助我們控制機器學習算法在優化性能、找出偏差方差最佳平衡時的行為。用于性能優化的超參數調整本身就是一門藝術,沒有固定規則可以保證在給定數據集上的性能最優。前面的章節提到了用于評估模型泛化性能的留出技術和 bootstrap 技術。偏差-方差權衡和計算性能估計的不穩定性方法都得到了介紹。本章主要介紹用于模型評估和選擇的不同交叉驗證方法,包括對不同超參數配置的模型進行排序和評估其泛化至獨立數據集的性能。
本章生成圖像的代碼詳見:https://github.com/rasbt/model-eval-article-supplementary/blob/master/code/resampling-and-kfold.ipynb。
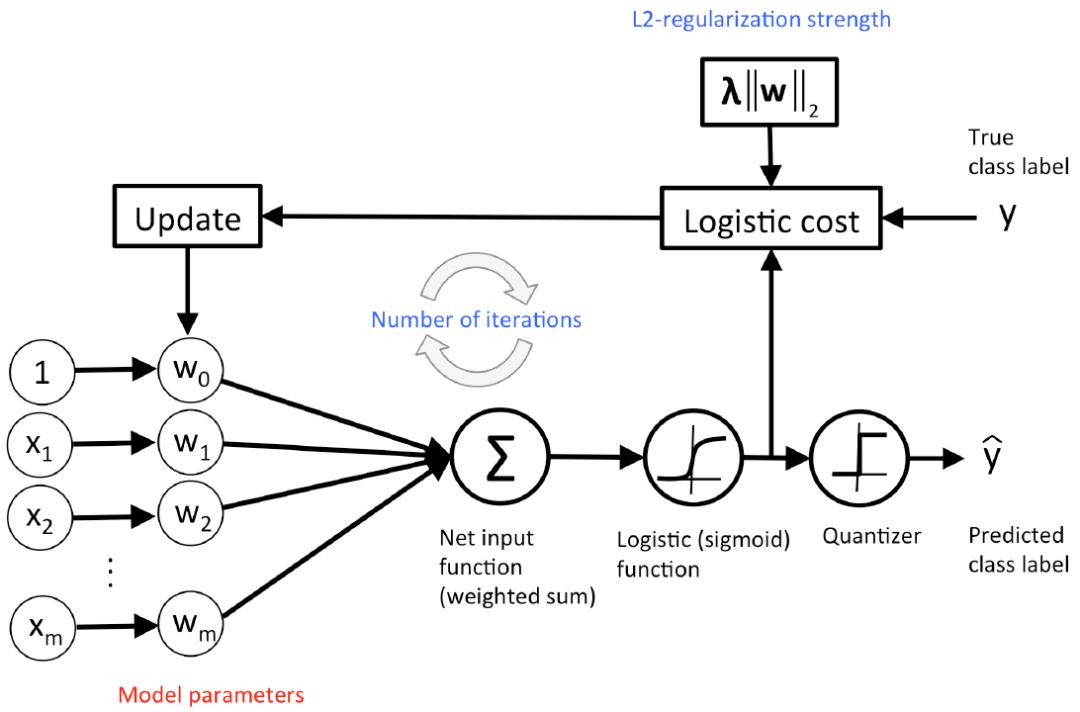
圖 11:logistic 回歸的概念圖示。
我們可以把超參數調整(又稱超參數優化)和模型選擇的過程看作元優化任務。當學習算法在訓練集上優化目標函數時(懶惰學習器是例外),超參數優化是基于它的另一項任務。這里,我們通常想優化性能指標,如分類準確度或接受者操作特征曲線(ROC 曲線)下面積。超參數調整階段之后,基于測試集性能選擇模型似乎是一種合理的方法。但是,多次重復使用測試集可能會帶來偏差和最終性能估計,且可能導致對泛化性能的預期過分樂觀,可以說是「測試集泄露信息」。為了避免這個問題,我們可以使用三次分割(three-way split),將數據集分割成訓練集、驗證集和測試集。對超參數調整和模型選擇進行訓練-驗證可以保證測試集「獨立」于模型選擇。這里,我們再回顧一下性能估計的「3 個目標」:
我們想評估泛化準確度,即模型在未見數據上的預測性能。
我們想通過調整學習算法、從給定假設空間中選擇性能最好的模型,來改善預測性能。
我們想確定最適合待解決問題的機器學習算法。因此,我們想對比不同的算法,選出性能最好的一個,從算法的假設空間中選出性能最好的模型。
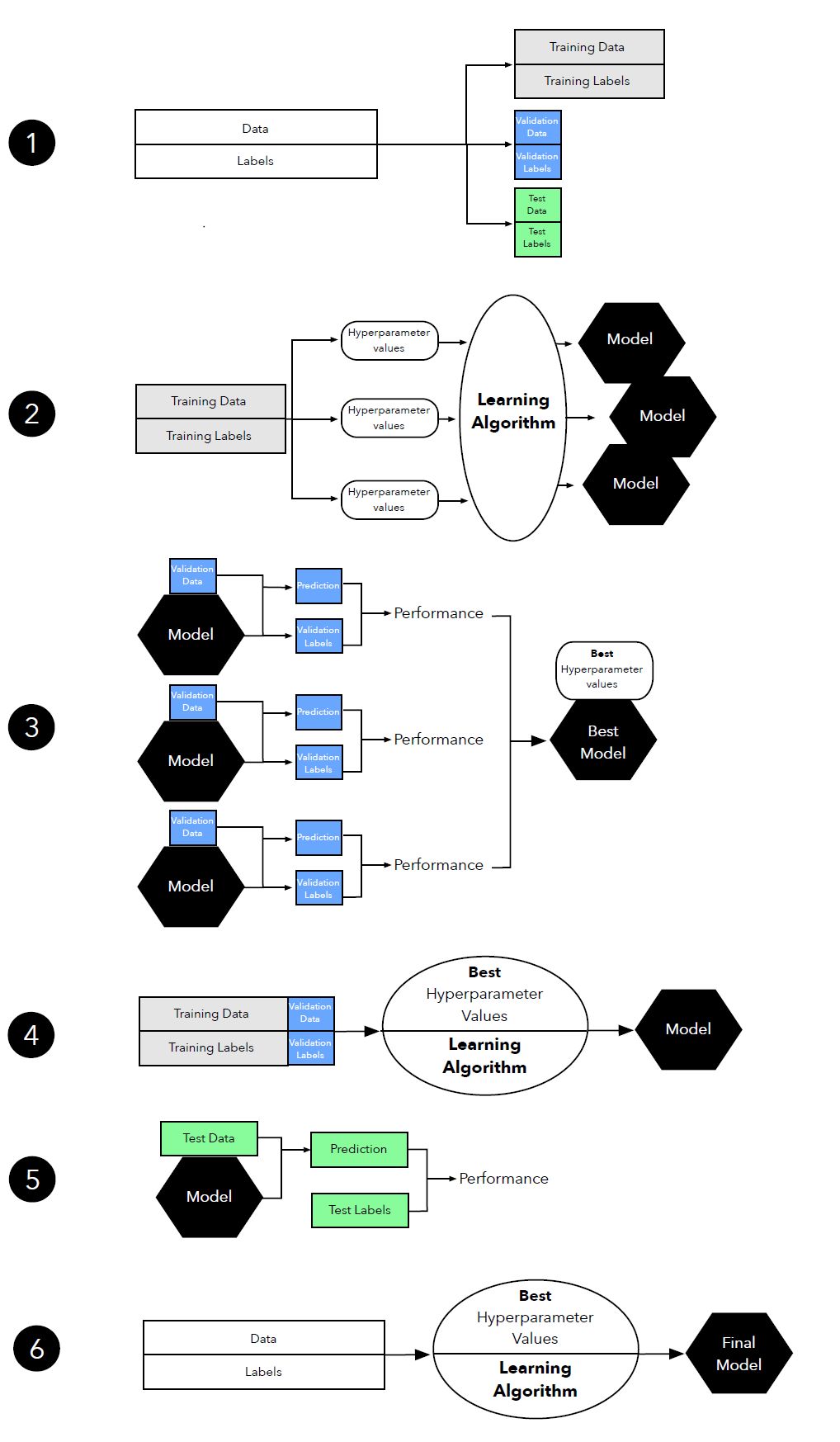
圖 12:超參數調整中三路留出方法(three-way holdout method)圖示。
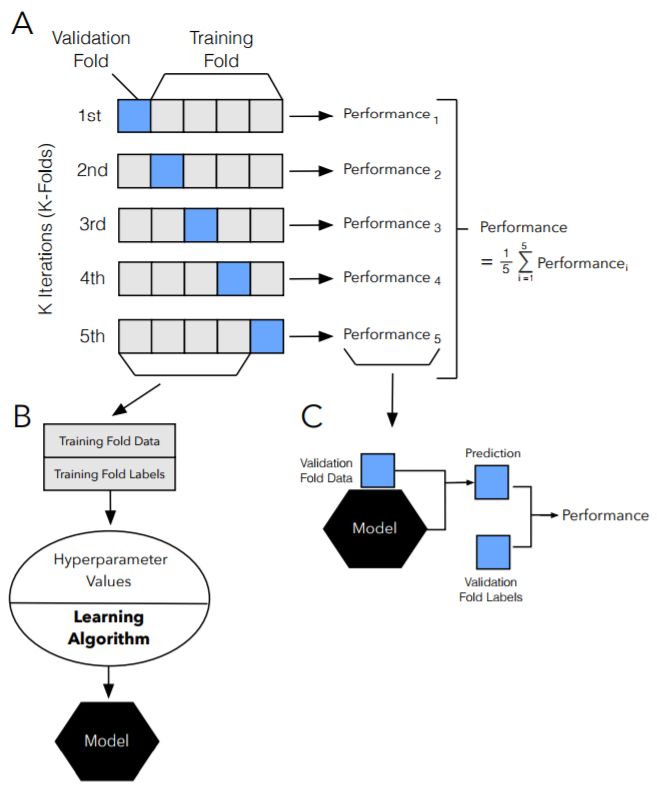
圖 13:k 折交叉驗證步驟圖示。
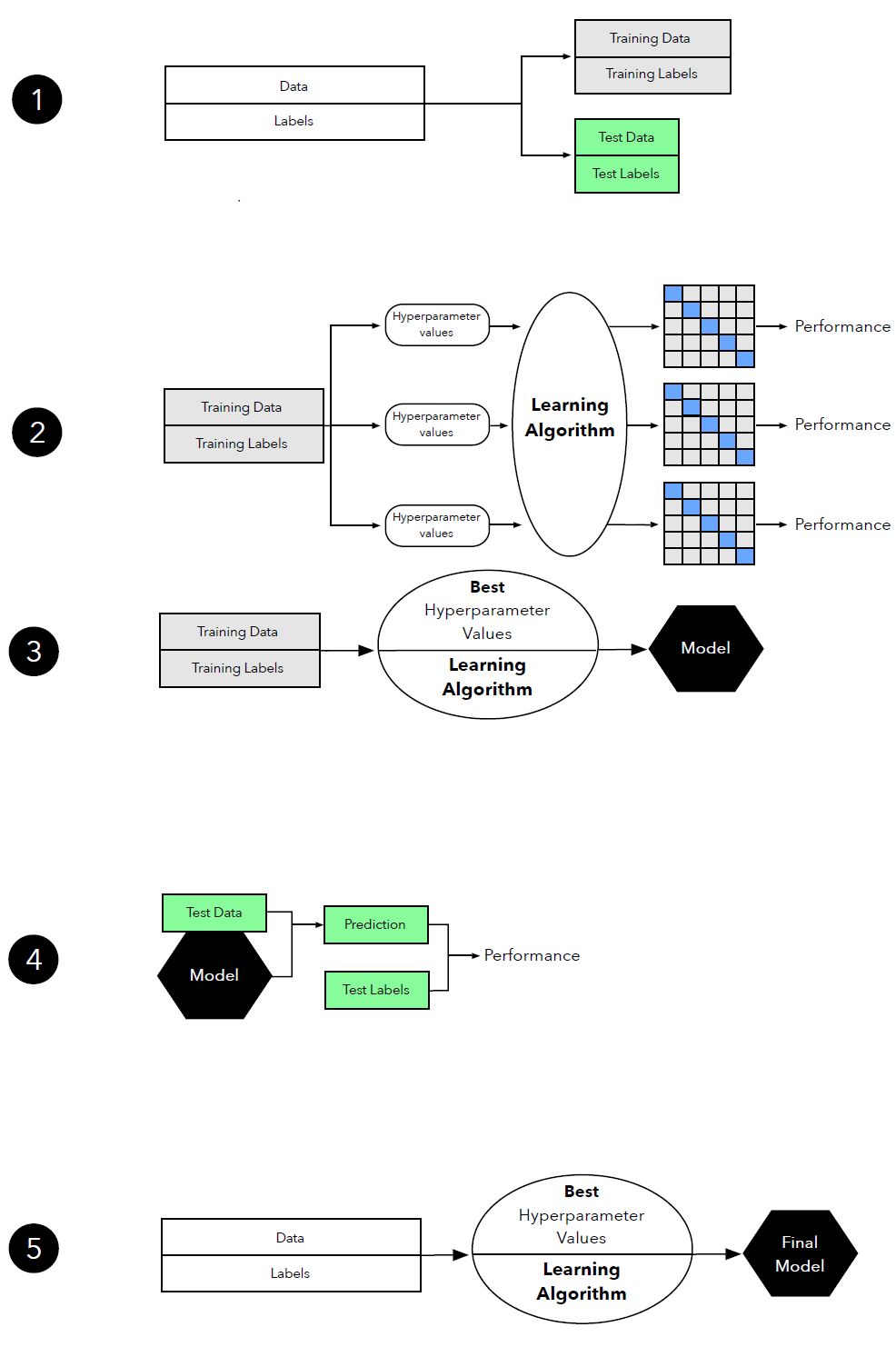
圖 16:模型選擇中 k 折交叉驗證的圖示。
-
模型
+關注
關注
1文章
3177瀏覽量
48722 -
機器學習
+關注
關注
66文章
8381瀏覽量
132428 -
數據集
+關注
關注
4文章
1205瀏覽量
24648
原文標題:模型評價、模型選擇、算法選擇
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
PCBA測試的常見方法
IDC設備資產運營中四種“折舊率計算”的常見方法
檢測LED單元板的常見方法

電平轉換常見方法的匯總比較資料下載






 工商網監
工商網監
評論