 淺談LLVM LibFuzzer工具和實踐
淺談LLVM LibFuzzer工具和實踐
摘要
我們在代碼編輯器 (IDE) 中編寫源代碼,將源代碼保存到文本文件中,然后用對應的編譯器讀取文件、分析代碼,并將其翻譯成適合目標平臺的格式,比如 X86、X86-64、Nvidia-GPU。不同的目標平臺涉及的指令集有所不同,拿 X86 指令集來說,總數上千條,如果將每條組合不同的參數一一去驗證,可以想象這個工程量有多么的龐大。除了 CPU 指令,GPU 指令也是如此。面對如此復雜的工作,有沒有一種強大且智能的測試方式呢?答案是肯定的,它就是出自 LLVM 編譯器框架的 LibFuzzer 工具。
利用 LibFuzzer 可以輕松發現程序常見的致命錯誤,包括不限于這些 crash:堆/棧/全局越界 (OOM)、內存泄漏、未初始化、互斥作用等,這樣可以最大限度地發現人為很難發現的問題,提高產品的安全和穩定性。
本文將介紹什么是 Fuzzer、LibFuzzer,如何編譯 LLVM-Fuzzer,以及快速寫一個 Hello World 目標函數,幫助大家熟悉并了解以上工具的用法、特性和需要注意的問題,提高代碼編譯的效率。
1什么是 Fuzzing Testing
在編程和軟件開發中,Fuzzing 測試是一種自動化的軟件測試技術,其核心思想是將自動或半自動生成的隨機數據輸入到一個程序中,并檢測程序異常,如 Crash,Assertion 失敗,以盡可能地發現程序錯誤,比如內存泄漏。Fuzzing 測試常常用于檢測軟件或計算機系統的安全漏洞。
通常,Fuzzer 用于測試采用參數化輸入的程序。例如,在參數一定的前提下,在一個圖片編碼過程中,區分有效和無效的編碼數據,使代碼在不同分支下(比如:if…else if),產生不同的結果。無效輸入會導致程序得不到正確處理,從而發現問題。
Fuzzer 可以分為以下幾類:生成型、突變型,以及前面兩種情況的結合-進化型,今天介紹的是最后一種進化型,即 LLVM 自帶 LibFuzzer。
2什么是 LibFuzzer
我們先了解下這個強大的編譯器框架 LLVM 是什么?
LLVM 是一套編譯器和工具鏈技術,可用于開發任何編程語言的前端和任何指令集架構的后端。LLVM 是圍繞獨立于語言的中間表示 (IR) 設計的,它作為一種可移植的高級匯編語言,可以通過多次轉換進行優化。
LibFuzzer 與被測庫鏈接,并通過特定的 Fuzzy 入口函數 (LLVMFuzzerTestOneInput),又稱目標函數,將 Fuzzy 隨機生成的參數提供給庫;然后,Fuzzer 跟蹤到達的代碼區域,并在輸入數據的主體上生成不同的參數組合,以最大限度地提高代碼覆蓋率。LibFuzzer 的代碼覆蓋率信息由 LLVM 的 SanitizerCoverage 工具提供。
LibFuzzer 有 3 個特性:第一個是in-process(進程內),即 LibFuzzer 在 fuzz 時并不是產生出多個進程來分別處理不同的輸入,而是將所有的測試數據放入進程的內存空間中。
這有利于進行高效的數據傳輸。為了提高這種高輸入,還可以結合 Google 序列化結構化數據庫 protobuf,如 LLVM 里面的 clang-proto-fuzzer 就是這種類型。
第二個特性是coverage-guided(覆蓋率)。Fuzzer 測試是隨機的,不清楚覆蓋了多少代碼,那么就可以用這個特性來統計代碼覆蓋率。
第三個特性就是Evolutionary(進化型), LibFuzzer 不僅可以生成數據,還可以對目前的數據進行突變,如前面講到的,結合了生成和突變兩種形式。
不過這些特性也在一定程度上約束了 LibFuzzer 在某些場景的使用,比如在內存上完成生成、突變作為輸入,速度非常快,但需要避免目標函數太大、太復雜,以及不能出現exit()函數。
在使用 Fuzzer 進行測試的時候,在編譯目標函數時,需要指定-fsanitize類型,包括 AddressSanitizer (ASAN),UndefinedBehaviorSanitizer (UBSAN), 以及 MemorySanitizer (MSAN)。
3環境準備
為了能夠讓更多的程序員使用這個強大的工具,LibFuzzer 是獨立的,并不依賴于 LLVM 框架,使用時只需下載對應的庫和頭文件即可,在 ubuntu , centos 以及 windows 系統中,都可以快速獲取到,關鍵字搜索:llvm-toolset。
不要被 LLVM 編譯器這種龐然大物嚇到,其實它與其他的編譯構建原理類似,下面就以 LLVM 內置的 Fuzzer 為例來進行詳細介紹。
首先是克隆 LLVM 的源代碼,然后編譯 LLVM 和 compile-rt,命令如下。
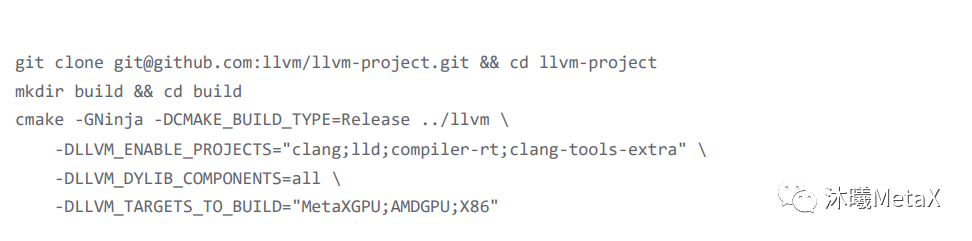
這里推薦編譯類型為 Release,因為 debug 的編譯實在太慢,通常前者 10 分鐘內可以完成,后者大概需要 2 個小時。
如果要用 LLVM 自帶的 LLVM-Fuzzer 工具,可以手動編譯自帶的 Fuzzer 工具,參考下面的命令,編譯好之后,在 bin 目錄可以找到有 clang-fuzzer、llvm-as-fuzzer、llvm-isel-fuzzer、llvm-mc-fuzzer 等 Fuzzer (模糊測試器),能夠用于測試 LLVM 前后端的功能,包括匯編、反匯編、指令選擇、優化等等。

值得注意的是需要指定-DMAKE_C_COMPILER為上一步編譯 LLVM 的 clang 文件,而且是不同的 build 目錄。就地取材,用LLVM 工程自帶的compiler-rt/test/fuzzer/CompressedTest.cpp來編譯完成之后,來將程序運行一下。
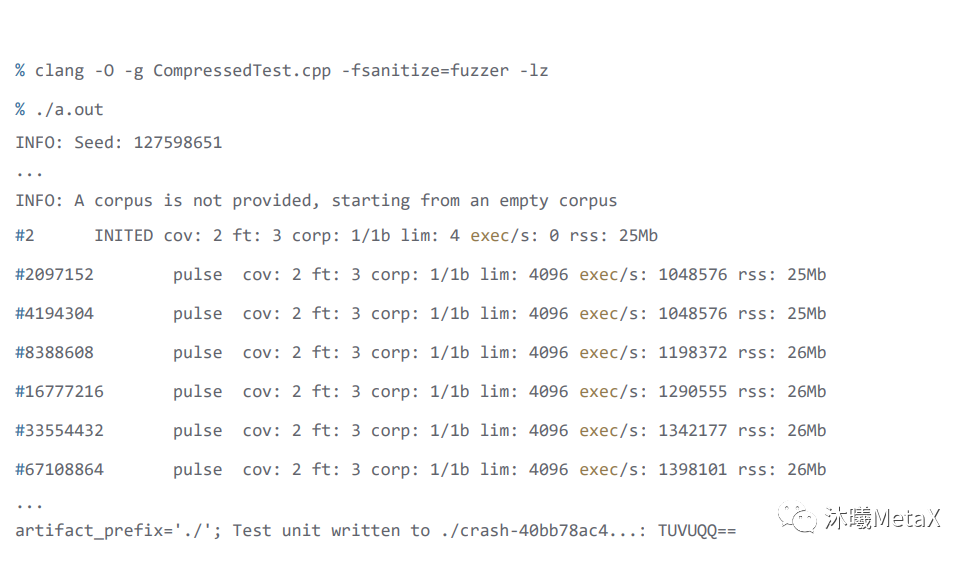
以上程序運行之后的日志信息里,可以看到如下信息,分別代表的意義為:
Seed 即 ./a.out -seed=xxx 可以指定的隨機 seed
INFO 第一行提示沒有指定 corpus,corpus 是一個提高 fuzzer 效率的方法
#2 后面的 INITED 代表初始化、開始執行, pulse 代表在運行,但沒有新的產生,執行了 2 的 n 次方后會顯示 pulse,有新的輸入產生會顯示 new 等等
cov: 2 代表覆蓋率是 2, 執行當前輸入所覆蓋的代碼塊的總數
ft: 3 feature 泛指代碼覆蓋率:邊緣覆蓋率、邊緣技術、配置文件等
corp: 1/1b 當前內存中測試輸入 corpus 庫中的條目數及其大小(以字節為單位)
lim: 4 exec/s 當前對語料庫中新條目長度的限制。隨時間增加,直到達到設置的最大長度 (-max_len),目前長度是 4
rss: 25MB 當前內存消耗,當前是25MB
./crash-xxx 是用來復現問題的 binary 文件
是不是很方便?最后一個crash 文件用于復現問題,這樣我們就可以有針對性的對程序進行動態調試,利用造成 crash 的輸入重現出漏洞的細節。
4提高 Fuzz 效率
從以上 CompressedTest 例子,可以看到一個簡單的 Fuzzer 目標函數執行之后的一些打印信息。同時在執行時 LibFuzzer 還內置了一些可選參數供程序員使用,比如最大長度默認是100,如果某個 bug 輸入的參數長度是 101 才能觸發,那這個 bug 用長度 100 的輸入永遠都跑不出來。
因此可見,我們設置一些常見的可選參數也能夠提高效率,并找到真正的問題所在。如下這些參數是比較常見的。
max_len 生成輸入的最大長度
len_control 首先嘗試生成較小的輸入,越小就代表執行的速度就越快,然后隨著時間的推移嘗試生成較大的輸入
除了這些常見的可選參數之外,還有兩個非常重要的能夠提高效率的參數:dict 和 corpus。
Dict 字典
相信「字典」對我們來說并不陌生,小學的時候基本人手一本「新華字典」。字典是從一種或多種特定語言的詞典中列出的詞匯,通常按字母順序排列。
對于 Fuzzer 的字典,就是從一個目標函數中列舉出所有輸入特性相關的詞匯。比如對應編譯器的 MC(machine code),字典就包括但不限于:指令集、寄存器、const 常量、寄存器寬度等等。再舉個程序員熟悉的例子,常見的編程語言,包含有條件、跳轉、邏輯處理等等,對應的字典包括但不限于:if、else、for、defined、template、include、pragma、!=、+= 等等,這樣相對比較好理解。

Fuzzer 字典的好處是提供一組我們希望在輸入中找到的常用詞或值來作為輸入,幫助 Fuzzer更快地擴大其覆蓋范圍。使用也非常簡單,用-dict參數即可:./a.out -dict=dict.txt。
程序員可以根據被測函數的特性手動生成一個字典,除此之外,每次程序跑完之后 LibFuzzer 會提供一個建議的字典,只要更新到對應的字典文件里即可。
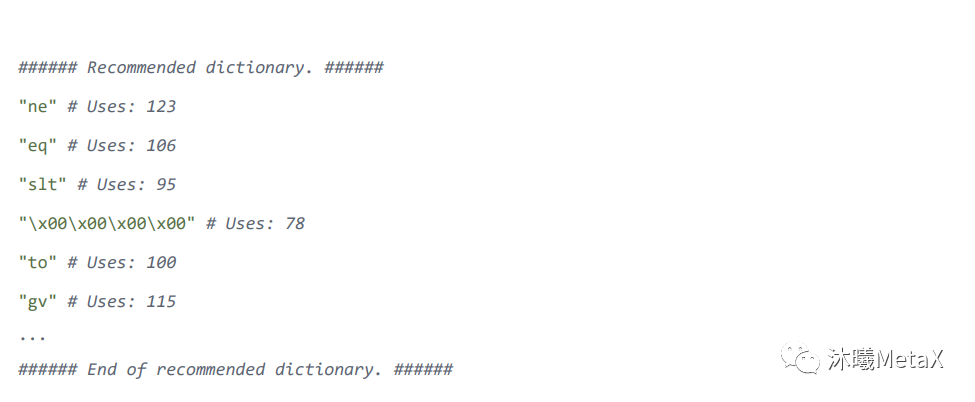
Corpus 語料庫
Corpus 語料庫,可以想象為一個函數的參數及各種參數的組合,即 Fuzzer 的測試用例。
在未使用語料庫的情況下就得到了 crash,實屬意外收獲。如果我們在使用字典的情況下仍然暫時未得到 crash,就可以去尋找一些有效的輸入語料庫。因為 LibFuzzer 是進化型的 fuzz,結合了產生和突變兩個方面。
如果我們可以提供一些好的語料庫,雖然它本身無法造成程序 crash,但LibFuzzer 會在此基礎上進行變異,有可能變異出更好的輸入參數,從而增大程序 crash 的概率。具體的變異策略需閱讀 LibFuzzer 源碼或網上搜索相關的文章。
在多種情況下,提供語料庫可以將代碼覆蓋率提高一個數量級。
在學習 Fuzzer 時,以下資料會對大家有所幫助,可以參考 Google Oss-Fuzz 開源倉庫。語料庫不能適用所有的場景,但特別適用于嚴格定義的文件格式和數據傳輸協議,比如:
對于文件格式解析器,添加測試套件中的有效文件
對于協議解析器,將測試套件中的有效原始流添加到單獨的文件中
對于圖形庫,添加各種小的 PNG/JPG/GIF 文件
執行時,只需要在目標函數后面跟一個目錄即可,./a.out corpus,這里的 corpus 目錄就是用來存放corpus 集的。隨著運行時間而增長變多。
同時可以精簡合并corpus,./a.out -merge=1 corpus_min corpus, 這樣,corpus_min 和 corpus 將會存放到新的 corpus 精簡后的輸入樣例。
為提高效率,程序員可以從可選參數的組合、字典以及 corpus這三方面入手,即可以保證目標函數的穩定性。除了以上手段外,還有一個重點也是難點,就是如何寫好一個目標函數。
5Hello World Fuzzer
下面就從幾個簡單的 Hello world 入手,熟悉下 LibFuzzer 如何寫一個目標函數。
創建一個文 fuzz_target.cc, 內容如下,不要使用 main 等作為函數名,因為 Libfuzzer 自帶了main 函數。
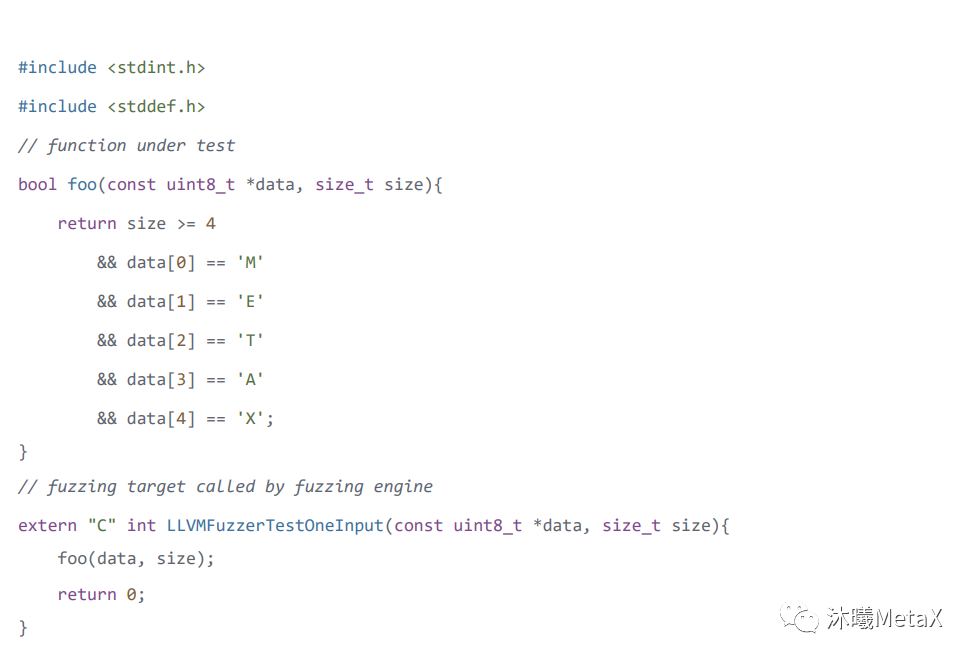
需要注意的是LLVMFuzzerTestOneInput函數是要實現的接口函數,包含兩個參數 Data (LibFuzzer 的測試樣本數據)及 size (樣本數據的大小)。
分析問題:當foo函數被調用的時候,條件 size>=4,但是 data[4], index 取到 4,相當于 size 應該是 5,就會觸發超出邊界的異常。
編譯這個文件,命令clang++ -g -O1 -fsanitize=fuzzer,address fuzz_target.cc -ofuzzer_target,這里的 clang 是用 LLVM 編譯出來的。
如果是直接安裝的 clang,就需要添加 LibFuzzer的庫函數:clang++ -g -O1 -fsanitize=fuzzer,addresslibFuzzer/Fuzzer/libFuzzer.a fuzz_target.cc -o fuzzer_target,否則可能會報錯。
參數的含義:
g 可選參數,保留調試符號
O1 指定優化等級為 1,對應的還有 O0 (optimize 0,1,2),以及 OS (optimize size)使用后 binary 大小會變小
fsanitize 指定 sanitize, 類型有幾種:fuzzer, address, 和memory(單獨使用,檢查內存),undefined(未定義)
編譯這一步驟整體過程就是通過 clang 的 -fsanitize=fuzzer 選項啟用 LibFuzzer,這個選項在編譯和鏈接過程中生效,實現了條件判斷語句和分支執行的記錄,通過生成不同的測試樣例獲得代碼的覆蓋率情況,最終實現所謂的 fuzz-testing。
注意:編譯的選項會影響 Fuzzer 的效率,比如是否保存指針。遇到問題可以在網上搜索,或問下身邊的大佬。另外,關注「沐曦MetaX」也會有意想不到的收獲。
clang 編譯的時候,參數-fno-omit-frame-pointer對于不需要棧指針的函數就不在寄存器中保存指針,因此可以忽略存儲和檢索地址的代碼,同時對眾多函數提供一個額外的寄存器。在 AMD64 平臺上此選項默認打開,但是在 x86 平臺上則默認關閉,建議編譯的時候做顯式設置。
gline-tables-only 表示使用采樣分析器, 在應用程序執行時,抽樣探查器用于收集運行時信息(如硬件計數器)。一般情況下,這個參數非常有效,并且不會引起大量的運行時開銷。分析器收集的示例數據可用于編譯期間確定代碼中執行最多的區域是什么,在編譯器使用分析信息之前,代碼需要在分析器下執行,這對提高 Fuzzing 效率很重要。
常用的編譯命令就是這樣:clang++ -g -O2 -fno-omit-frame-pointer -gline-tables-only -fsanitize=address,fuzzer-no-link test.cc libFuzzer/Fuzzer/libFuzzer.a -o test
第一個目標函數里面被調用的 foo 函數是硬編碼,有沒有一種好的方法直接生成輸入數據呢?YES,上代碼。

用 FuzzedDataProvider 這樣一個 helper,組合生成我們需要的數據,上面兩段代碼分別獲取 value, amount,可以達到相同的效果。
事實上筆者接觸 LibFuzzer 并不久,但在編寫 Fuzzer 過程中,也發現了一些小技巧,比如可以用LLVMFuzzerCustomMutator來對現有的數據進行突變,然后輸入到目標函數。此外,還可以用LLVMFuzzerCustomCrossOver來自定義數據的交叉組合,從而在相同時間內達到更高的代碼覆蓋率。
6總結
通過本文我們可以了解 Fuzzer、LibFuzzer 工具、如何編譯 LLVM-Fuzzer,以及寫一個 Fuzzer 目標函數。利用 LibFuzzer 的功能可以自動發現一些未知的問題,寫好了工具,還需要用起來,至于如何管理 corpus、crash bug,集成到項目中,也需要掌握和了解。LibFuzzer 是最常見的 Fuzzing 工具之一,它是獨立的、不依賴 LLVM,提供的接口和 helper 非常強大,在運行的過程中,還需要用 dict、corpus 來提高 Fuzzing 的效率。corpus 語料庫在 Fuzzy 過程中不斷演變,我們可以找到代碼中很難人被為發現的問題。隨著運行時間的增加,要不斷優化合并我們的 corpus,用較小的輸入達到同樣的覆蓋率。
最后,Fuzzer 有開源、半開源、商業等不同類型,如面向安全的 Google-honggfuzz、面向 HTTP 的 Fuzz-Monkey,在工作中需選擇適合項目的類型。歸根結底 LibFuzzer 只是一個工具,但解決問題還要靠程序員自己。
審核編輯:湯梓紅
-
源代碼
+關注
關注
96文章
2944瀏覽量
66670 -
編譯器
+關注
關注
1文章
1618瀏覽量
49051
原文標題:【智算芯聞】淺談 LLVM LibFuzzer 工具和實踐
文章出處:【微信號:沐曦MetaX,微信公眾號:沐曦MetaX】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
淺談公共機房樣機制作及日常維護
LLVM clang 公開 -std=c++23
在Swift中使用LLVM的四個要點

四個不同的系統上進行LLVM/Clang 6.0 和 5.0 的編譯器Benchmark測試
智變未來-淺談人工智能技術應用與實踐

OLLVM和LLVM功能介紹
LLVM源碼淺析-1

LLVM國際開源軟件社區發布正式支持LoongArch架構的版本
什么是LLVM?LLVM的優勢和特點有哪些?
使用LLVM-embedded-toolchain-for-Arm-17.0.1開發STM32





 工商網監
工商網監
評論