 深入理解Linux I/O系統
深入理解Linux I/O系統
read(file_fd,tmp_buf,len);
write(socket_fd,tmp_buf,len);
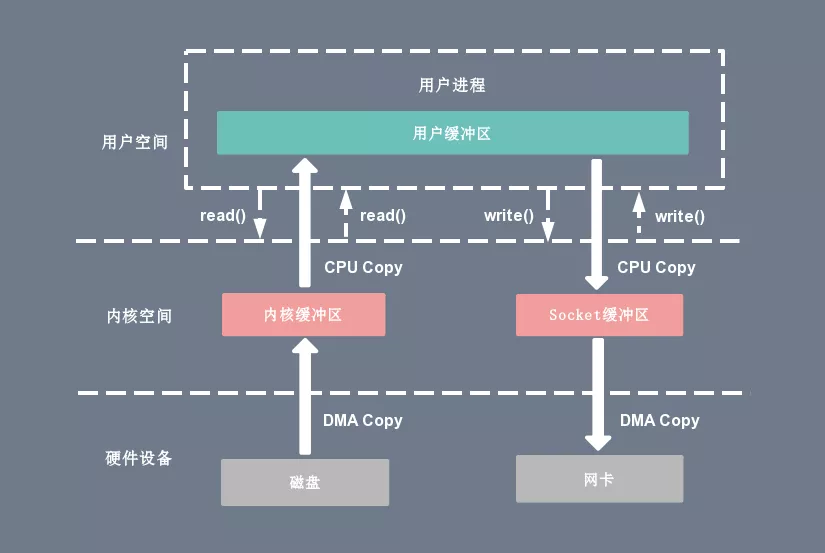
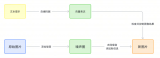
下圖分別對應傳統 I/O 操作的數據讀寫流程,整個過程涉及 2 次 CPU 拷貝、2 次 DMA 拷貝,總共 4 次拷貝,以及 4 次上下文切換。
-
CPU 拷貝:
由 CPU 直接處理數據的傳送,數據拷貝時會一直占用 CPU 的資源; -
DMA 拷貝:
由 CPU 向DMA磁盤控制器下達指令,讓 DMA 控制器來處理數據的傳送,數據傳送完畢再把信息反饋給 CPU,從而減輕了 CPU 資源的占有率; -
上下文切換:
當用戶程序向內核發起系統調用時,CPU 將用戶進程從用戶態切換到內核態;
當系統調用返回時,CPU 將用戶進程從內核態切換回用戶態。
讀操作 當應用程序執行 read 系統調用讀取一塊數據的時候,如果這塊數據已經存在于用戶進程的頁內存中,就直接從內存中讀取數據。
如果數據不存在,則先將數據從磁盤加載數據到內核空間的讀緩存(Read Buffer)中,再從讀緩存拷貝到用戶進程的頁內存中。
read(file_fd,tmp_buf,len);
基于傳統的 I/O 讀取方式,read 系統調用會觸發 2 次上下文切換,1 次 DMA 拷貝和 1 次 CPU 拷貝。
發起數據讀取的流程如下:
用戶進程通過 read() 函數向 Kernel 發起 System Call,上下文從 user space 切換為 kernel space。
CPU 利用 DMA 控制器將數據從主存或硬盤拷貝到 kernel space 的讀緩沖區(Read Buffer)。
CPU 將讀緩沖區(Read Buffer)中的數據拷貝到 user space 的用戶緩沖區(User Buffer)。
上下文從 kernel space 切換回用戶態(User Space),read 調用執行返回。
寫操作 當應用程序準備好數據,執行 write 系統調用發送網絡數據時,先將數據從用戶空間的頁緩存拷貝到內核空間的網絡緩沖區(Socket Buffer)中,然后再將寫緩存中的數據拷貝到網卡設備完成數據發送。
write(socket_fd,tmp_buf,len);
基于傳統的 I/O 寫入方式,write() 系統調用會觸發 2 次上下文切換,1 次 CPU 拷貝和 1 次 DMA 拷貝。
用戶程序發送網絡數據的流程如下:
用戶進程通過 write() 函數向 kernel 發起 System Call,上下文從 user space 切換為 kernel space。
CPU 將用戶緩沖區(User Buffer)中的數據拷貝到 kernel space 的網絡緩沖區(Socket Buffer)。
CPU 利用 DMA 控制器將數據從網絡緩沖區(Socket Buffer)拷貝到 NIC 進行數據傳輸。
上下文從 kernel space 切換回 user space,write 系統調用執行返回。
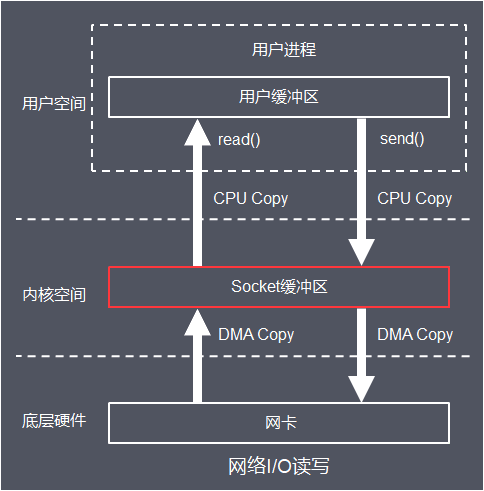
網絡 I/O
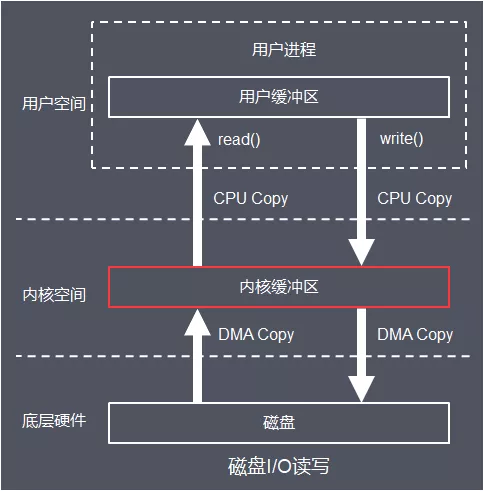
磁盤 I/O
 ?
?
高性能優化的 I/O1. 零拷貝技術。2. 多路復用技術。
3. 頁緩存(PageCache)技術。
其中,頁緩存(PageCache)是操作系統對文件的緩存,用來減少對磁盤的 I/O 操作,以頁為單位的,內容就是磁盤上的物理塊,頁緩存能幫助程序對文件進行順序讀寫的速度幾乎接近于內存的讀寫速度,主要原因就是由于 OS 使用 PageCache 機制對讀寫訪問操作進行了性能優化。
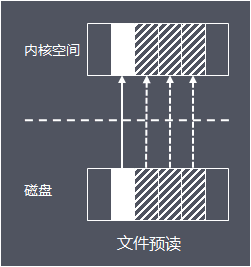
頁緩存讀取策略:當進程發起一個讀操作 (比如,進程發起一個 read() 系統調用),它首先會檢查需要的數據是否在頁緩存中:
- 如果在,則放棄訪問磁盤,而直接從頁緩存中讀取。
- 如果不在,則內核調度塊 I/O 操作從磁盤去讀取數據,并讀入緊隨其后的少數幾個頁面(不少于一個頁面,通常是三個頁面),然后將數據放入頁緩存中。
頁緩存寫策略:當進程發起 write 系統調用寫數據到文件中,先寫到頁緩存,然后方法返回。此時數據還沒有真正的保存到文件中去,Linux 僅僅將頁緩存中的這一頁數據標記為 “臟”,并且被加入到臟頁鏈表中。
然后,由 flusher 回寫線程周期性將臟頁鏈表中的頁寫到磁盤,讓磁盤中的數據和內存中保持一致,最后清理“臟”標識。在以下三種情況下,臟頁會被寫回磁盤:
空閑內存低于一個特定閾值。
臟頁在內存中駐留超過一個特定的閾值時。
當用戶進程調用 sync() 和 fsync() 系統調用時。
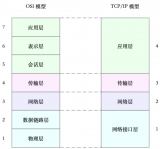
存儲設備的 I/O 棧
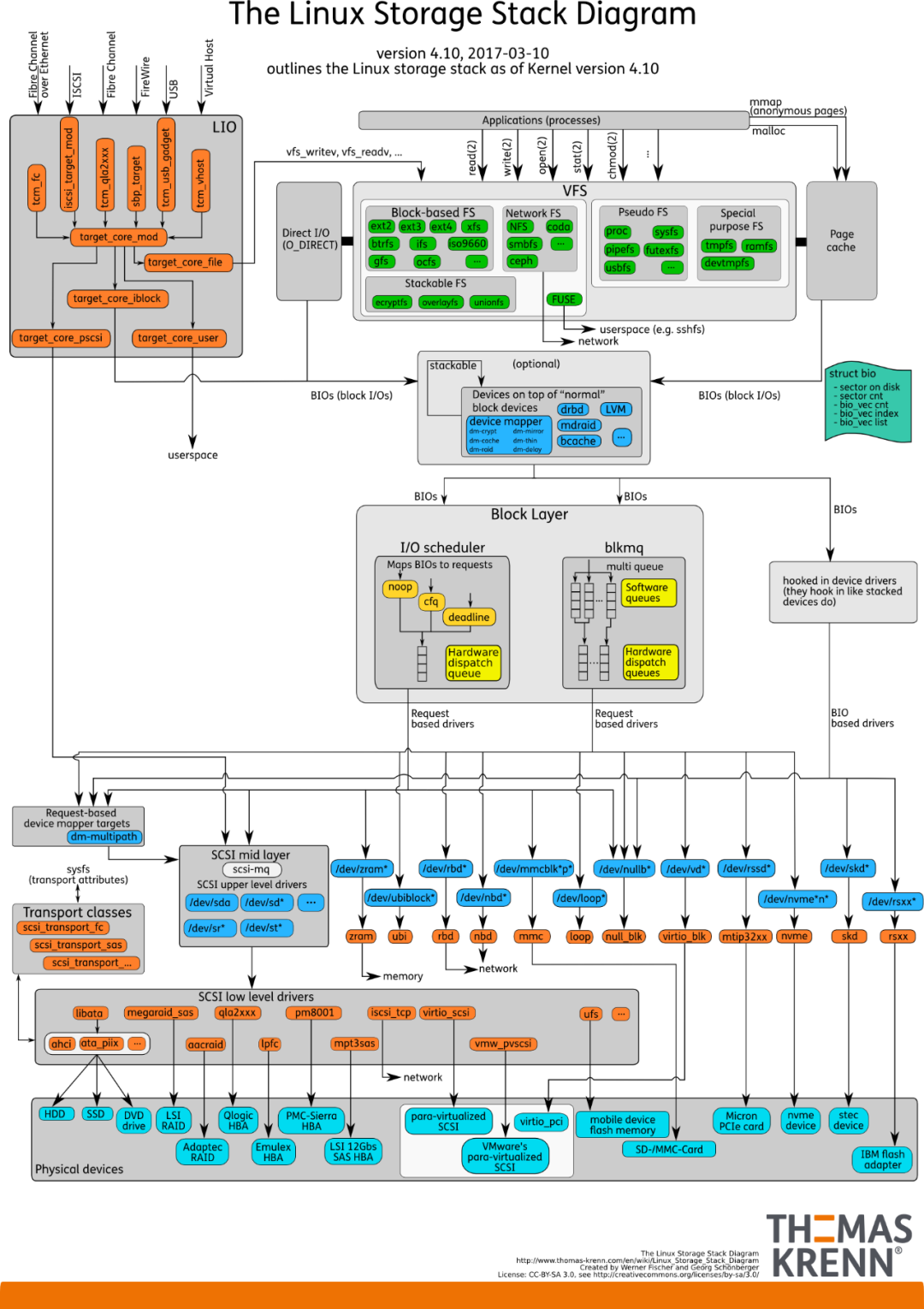
由圖可見,從系統調用的接口再往下,Linux 下的 IO 棧致大致有三個層次:
結合這個圖,想想 Linux 系統編程里用到的 Buffered IO、mmap、Direct IO,這些機制怎么和 Linux I/O 棧聯系起來呢?上面的圖有點復雜,我畫一幅簡圖,把這些機制所在的位置添加進去:
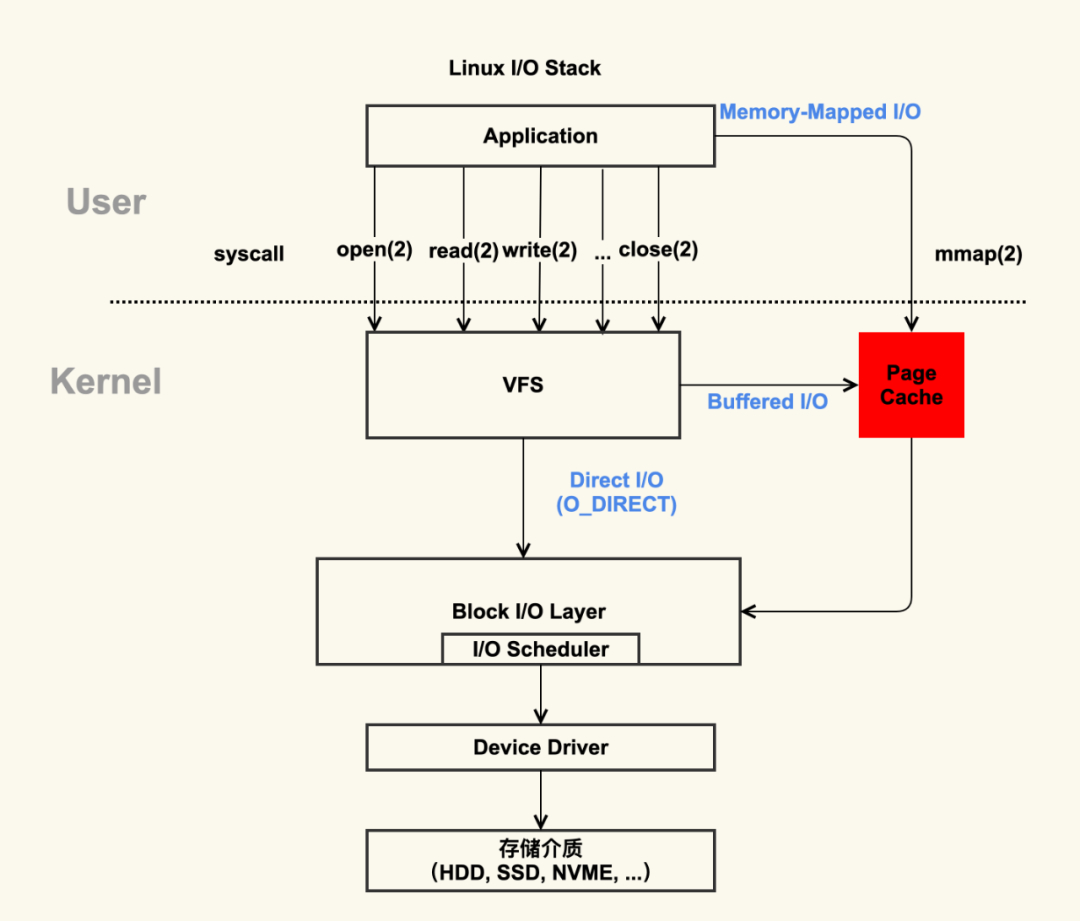
Linux IO系統
這下一目了然了吧?傳統的 Buffered IO 使用 read 讀取文件的過程什么樣的?
假設要去讀一個冷文件(Cache 中不存在),open 打開文件內核后建立了一系列的數據結構,接下來調用 read,到達文件系統這一層,發現 Page Cache 中不存在該位置的磁盤映射,然后創建相應的 Page Cache 并和相關的扇區關聯。
然后請求繼續到達塊設備層,在 IO 隊列里排隊,接受一系列的調度后到達設備驅動層,此時一般使用 DMA 方式讀取相應的磁盤扇區到 Cache 中,然后 read 拷貝數據到用戶提供的用戶態 buffer 中去(read 的參數指出的)。
整個過程有幾次拷貝?
從磁盤到 Page Cache 算第一次的話,從 Page Cache 到用戶態 buffer 就是第二次了。
而 mmap 做了什么?
mmap 直接把 Page Cache 映射到了用戶態的地址空間里了,所以 mmap 的方式讀文件是沒有第二次拷貝過程的。
那 Direct IO 做了什么?
這個機制更狠,直接讓用戶態和塊 IO 層對接,直接放棄 Page Cache,從磁盤直接和用戶態拷貝數據。
好處是什么?
寫操作直接映射進程的buffer到磁盤扇區,以 DMA 的方式傳輸數據,減少了原本需要到 Page Cache 層的一次拷貝,提升了寫的效率。
對于讀而言,第一次肯定也是快于傳統的方式的,但是之后的讀就不如傳統方式了(當然也可以在用戶態自己做 Cache,有些商用數據庫就是這么做的)。
除了傳統的 Buffered IO 可以比較自由的用偏移+長度的方式讀寫文件之外,mmap 和 Direct IO 均有數據按頁對齊的要求,Direct IO 還限制讀寫必須是底層存儲設備塊大小的整數倍(甚至 Linux 2.4 還要求是文件系統邏輯塊的整數倍)。
所以接口越來越底層,換來表面上的效率提升的背后,需要在應用程序這一層做更多的事情。
所以想用好這些高級特性,除了深刻理解其背后的機制之外,也要在系統設計上下一番功夫。
I/O Buffering
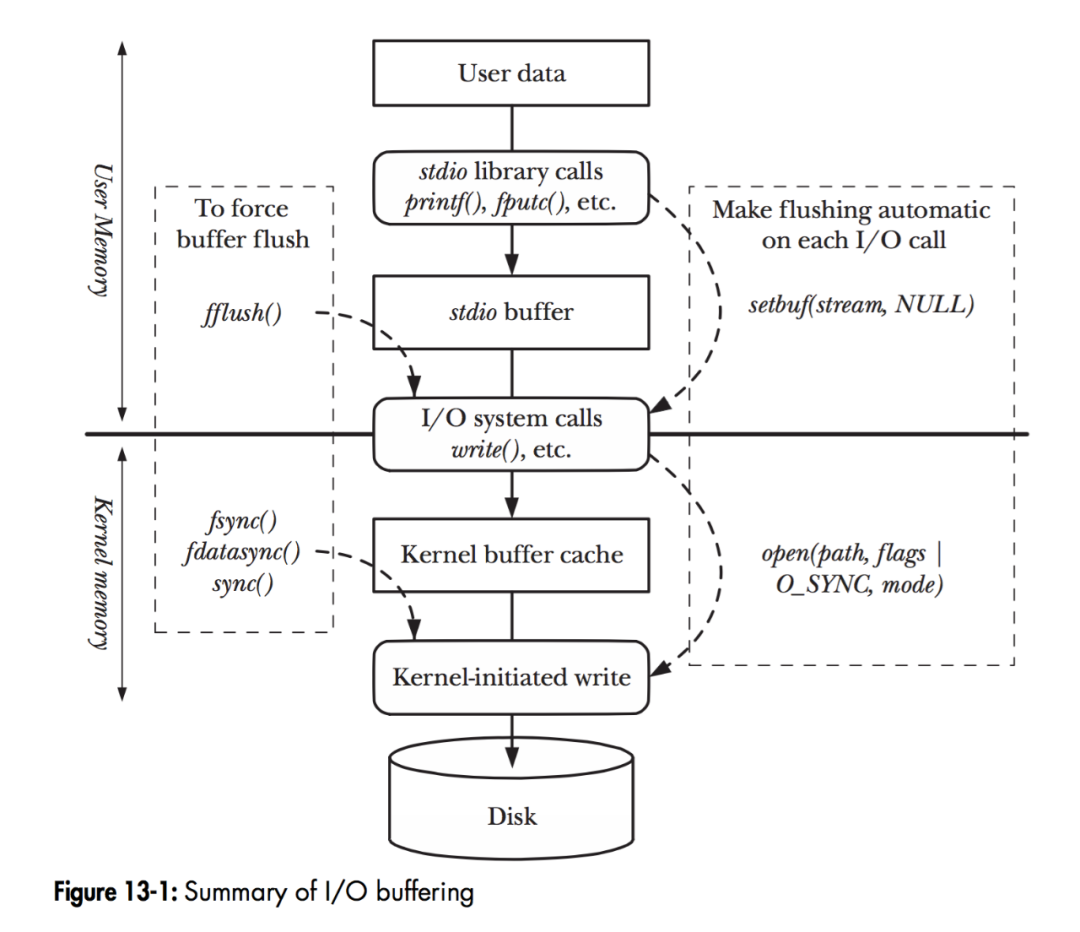
如圖,當程序調用各類文件操作函數后,用戶數據(User Data)到達磁盤(Disk)的流程如圖所示。
圖中描述了 Linux 下文件操作函數的層級關系和內存緩存層的存在位置。中間的黑色實線是用戶態和內核態的分界線。
從上往下分析這張圖:
1. 首先是 C 語言 stdio 庫定義的相關文件操作函數,這些都是用戶態實現的跨平臺封裝函數。
stdio 中實現的文件操作函數有自己的 stdio buffer,這是在用戶態實現的緩存。此處使用緩存的原因很簡單 — 系統調用總是昂貴的。如果用戶代碼以較小的 size 不斷的讀或寫文件的話,stdio 庫將多次的讀或者寫操作通過 buffer 進行聚合是可以提高程序運行效率的。stdio 庫同時也支持 fflush 函數來主動的刷新 buffer,主動的調用底層的系統調用立即更新 buffer 里的數據。特別地,setbuf 函數可以對 stdio 庫的用戶態 buffer 進行設置,甚至取消 buffer 的使用。
2. 系統調用的 read/write 和真實的磁盤讀寫之間也存在一層 buffer,這里用術語 Kernel buffer cache 來指代這一層緩存。
在 Linux 下,文件的緩存習慣性的稱之為 Page Cache,而更低一級的設備的緩存稱之為 Buffer Cache。這兩個概念很容易混淆,這里簡單的介紹下概念上的區別:Page Cache 用于緩存文件的內容,和文件系統比較相關。文件的內容需要映射到實際的物理磁盤,這種映射關系由文件系統來完成;Buffer Cache 用于緩存存儲設備塊(比如磁盤扇區)的數據,而不關心是否有文件系統的存在(文件系統的元數據緩存在 Buffer Cache 中)。
審核編輯 :李倩
-
cpu
+關注
關注
68文章
10827瀏覽量
211173 -
Linux
+關注
關注
87文章
11232瀏覽量
208939
原文標題:深入理解Linux I/O 系統
文章出處:【微信號:混說Linux,微信公眾號:混說Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深入理解 Llama 3 的架構設計
物聯網中常見的I/O擴展電路設計方案_IIC I/O擴展芯片
深入理解FPD-link III ADAS解串器HUB產品

PLC的I/O點數是什么意思
《深入理解FFmpeg閱讀體驗》FFmpeg攝像頭測試
《深入理解FFmpeg閱讀體驗》
深入理解 Sora 的技術原理
深入理解 FPGA 的基礎結構
深入理解Linux網絡協議
FANUC外部I/O點數不夠用了怎么辦?可以擴展I/O點數嗎?
恒訊科技帶大家深入理解:WebSocket服務器的工作原理
深入理解光耦模擬隔離放大電路的技術奧秘
《深入理解FFmpeg閱讀體驗》+ 書收到了,嶄新的開篇
深入理解BigBird的塊稀疏高效實現方案





 工商網監
工商網監
評論