 一種新穎的標簽驅動去噪框架(LDF)
一種新穎的標簽驅動去噪框架(LDF)
01
研究動機
方面類別檢測(簡稱ACD)是細粒度情感分析的一個重要子任務,旨在從一組預定義的方面類別中檢測出評論句子中提到的方面類別。例如,給定句子”雖然房間很貴,但是服務很好.”,ACD 的任務是從句子中識別出兩個方面類別,即”服務”和”價格”。顯然,ACD 屬于多標簽分類問題。
最近,隨著深度學習的發展,研究者們提出了大量用于 ACD 任務的神經網絡模型[1, 2, 3]。所有這些模型的性能在很大程度上依賴于足夠的標記數據。但是,ACD 任務中方面類別的注釋非常昂貴。有限的標記數據嚴重限制了神經網絡模型的有效性。為了緩解這個問題,Hu等人[4]參考了小樣本學習 (FSL) 的思路[5, 6,7 ,8],將 ACD任務形式化為小樣本學習問題 (FS-ACD),即使用少量的監督數據來判評論句子所屬的方面類別。
表1: 3-way 2-shot 元任務的示例
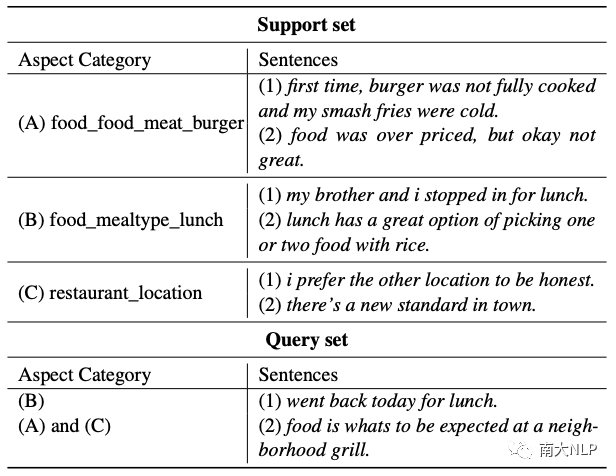
FS-ACD 遵循元學習范式[9],構建了一個 N-way K-shot 的元任務集合。表1顯示了一個 3-way 2-shot 的元任務,它由一個支持集和一個查詢集組成。支持集隨機采樣三個類(即方面類別),每個類隨機選擇兩個句子(即實例)。元任務旨在借助少量標記的支持集來推斷查詢集中句子所屬的方面類別。
通過在訓練階段對不同的元任務進行采樣,FS-ACD 可以在少樣本場景中學習到很好的泛化能力,并且在測試階段表現良好。為了執行 FS-ACD 任務,Hu等人[4]提出了一個基于注意力的原型網絡Proto-AWATT。它首先利用注意力機制從支持集中的方面類別對應的句子中提取關鍵字,然后將它們聚合為證據為每個方面類別生成一個原型。
然后,查詢集利用原型生成相應的查詢表示。最后,通過測量每個原型表示與相應查詢表示之間的距離來進行類別預測。
盡管取得了很好的效果,但是我們發現噪聲仍然是 FS-ACD 任務的關鍵問題。原因來自兩個方面:一方面,由于缺乏足夠的監督數據,以前的模型很容易捕捉到與當前方面類別無關的噪聲詞,這在很大程度上影響了生成原型的質量。如圖1所示,以方面類別 food_food_meat_burger的原型為例。
我們根據Proto-AWATT 的注意力權重突出顯示其前 10 個單詞。由于缺乏足夠的監督數據,我們觀察到模型傾向于關注那些常見但嘈雜的單詞,例如“a”、“the”、“my”。這些嘈雜的詞無法為每個方面生成具有代表性的原型,從而導致性能打折。另一方面,語義上接近的方面類別通常會產生相似的原型,這些語義接近的原型互為噪音,極大地混淆了分類器。
據統計,數據集中近 25% 的方面類別對具有相似的語義,例如表 1 中的 food_food_meat_burger 和 food_mealtype_lunch。顯然,這些語義相近的方面類別生成的原型會相互干擾并嚴重混淆 FS-ACD的檢測結果。
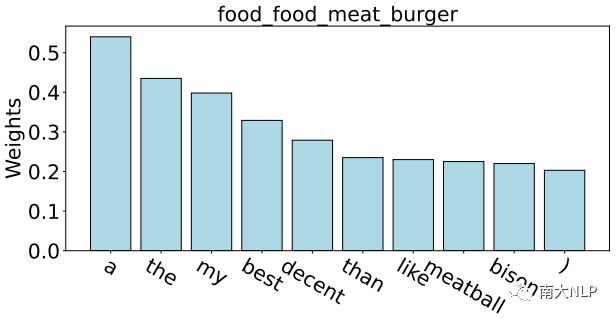
圖1:根據 Proto-AWATT 的注意力權重可視化方面類別 food_food_meat_burger 原型的前 10 個單詞
為了解決上述問題,我們為 FS-ACD 任務提出了一種新穎的標簽驅動去噪框架(LDF)。具體來說,對于第一個問題,方面類別的標簽文本包含豐富的語義描述方面的概念和范圍,例如方面類別restaurant_location的標簽文本“restaurant“和”location”,它們可以幫助注意力機制更好地捕捉與標簽相關的單詞。
因此,我們提出了一種標簽引導的注意力策略來過濾噪聲詞并引導 LDF 產生更好的方面原型。鑒于第二個問題,我們提出了一種有效的標簽加權對比損失,它將支持集的類間關系合并到對比學習函數中,從而擴大了相似原型之間的距離。
02
貢獻
1、據我們所知,我們是第一個利用方面類別的標簽信息來解決FS-ACD任務中噪聲問題的工作;
2、我們提出了一種新穎的標簽驅動去噪框架(LDF),它包含一個標簽引導的注意力策略來過濾嘈雜的單詞并為每個方面生成一個有代表性的原型,以及一個標簽加權的對比損失來避免為語義接近的方面類別生成相似的原型;
3、LDF框架具有良好的兼容性,可以很容易地擴展到現有模型。在這項工作中,我們將其應用于兩個最新的FS-ACD模型,Proto-HATT[8]和Proto-AWATT[4]。三個基準數據集的實驗結果證明了我們框架的優越性。
03
背景
在這項工作中,我們基于 Proto-AWATT[4]和 Proto-HATT[8]模型抽象了一個通用的架構,它們都實現了令人滿意的性能,因此被選為我們工作的基礎。
給定一個包含l個單詞的實例,我們首先通過查找嵌入表將其映射到單詞序列中。然后,我們使用卷積神經網絡(CNN)將單詞序列編碼為上下文表示。接下來,注意力層為實例中的每個單詞分配一個權重。最終實例表示由下式給出:
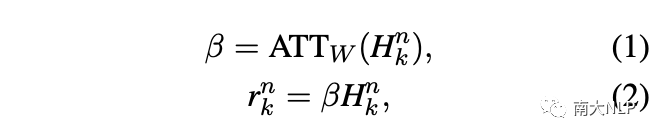
之后,我們聚合類n的所有實例表示來生成原型表示:
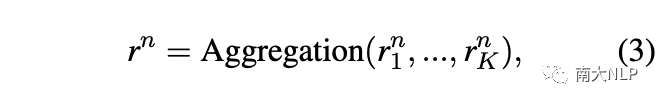
在處理了支持集中的所有類之后,我們得到了N個原型表示。類似地,對于查詢實例,我們首先利用注意力機制生成N個原型特定的查詢表示。之后,我們計算每個原型與對應的原型特定查詢表示之間的歐幾里得距離(ED)。最后,我們對負歐幾里得距離進行歸一化以獲得原型的排名,并使用閾值來選擇方面類別:
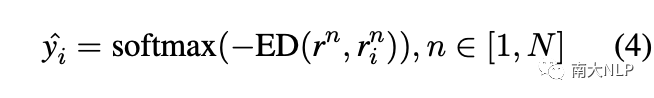
最終的訓練目標是均方誤差(MSE)損失:
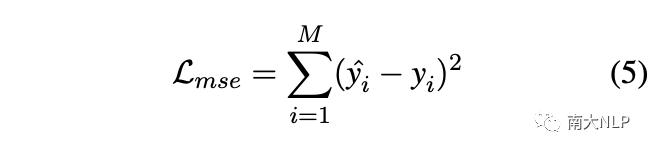
04
解決方案
圖 2 展示了 LDF 的整體架構,其中包含兩個組件:標簽引導的注意力策略和標簽加權的對比損失。在標簽信息的幫助下,前者可以更好地關注與方面類別相關的單詞,從而為每個方面生成更準確的原型,后者利用支持集的類間關系避免生成相似的原型。
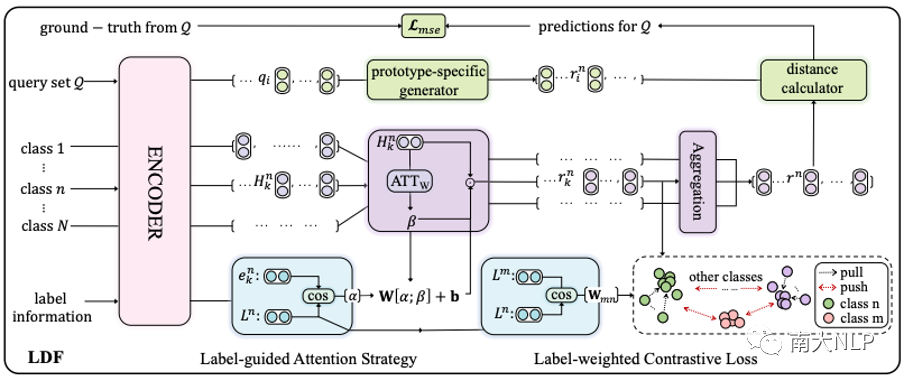
圖2:標簽驅動去噪框架(LDF)的整體架構
3.1 標簽引導的注意力策略
由于缺乏足夠的監督數據,公式1中的注意力權重通常會關注一些與當前類別無關的噪聲詞,導致原型變得不具有代表性。直覺上來說,每個類的標簽文本都包含豐富的語義,可以為捕獲方面類別相關的單詞提供指導。因此,我們利用標簽信息來解決上述問題并提出標簽引導的注意力策略。
具體來說,我們首先計算標簽文本與實例中每個單詞的語義相似度來定位每個類的關鍵詞:
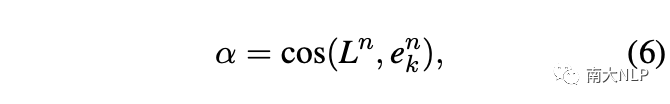
在標簽信息的約束下,相似度權重傾向于關注與標簽文本高度相關的少量單詞,這樣可能會忽略其它有信息量的詞。因此,我們將其作為注意力權重的補充,以生成更全面、更準確的注意力權重:
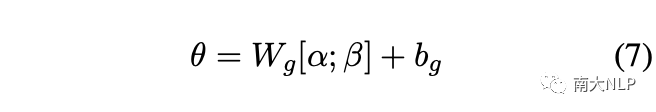
然后,為了重新獲得注意力分布,注意力權重被重新歸一化為:
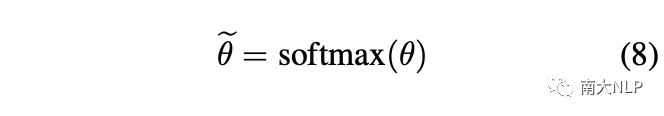
最后,我們將方程1中的注意力權重替換為方程8中新的注意力權重,從而獲得支持集中每個類的代表性原型。
3.2 標簽加權的對比損失
如前所述,語義上接近的方面類別通常會在支持集中生成相似的原型,它們互為噪聲并嚴重混淆分類器。
直觀地說,一種可行且自然的方法是利用有監督對比學習,它可以將不同類別的原型推開如下:
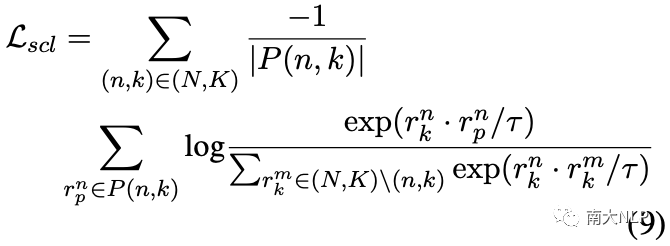
然而,有監督對比學習并不能很好地解決我們的問題,因為它在負集中平等地對待不同的原型,而我們的目標是鼓勵越相似的原型相距越遠。
例如,“food_food_meat_burger”在語義上比“room_bed”更接近“food_mealtype_lunch”。因此,“food_food_meat_burger”在負集中應該比“room_bed”更遠離“food_mealtype_lunch”。
為了實現這一目標,我們再次利用標簽信息并提出將類間關系合并到有監督的對比學習中,以自適應地區分負集中的相似原型:
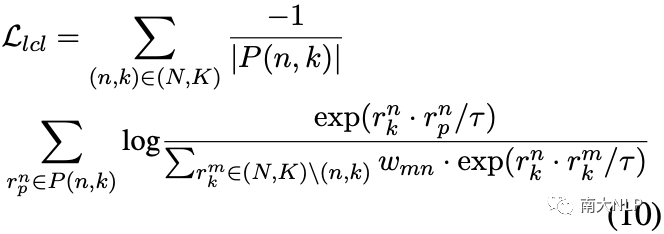
其中 wmn表示負集中不同方面類別之間的 cos 相似度,計算如下:
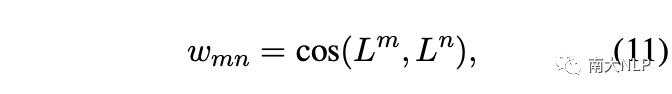
在標簽加權的對比損失模塊中,最終的損失函數為:
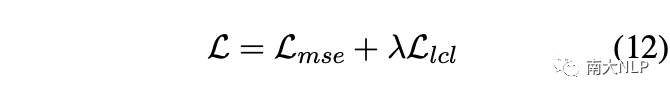
05
實驗
5.1 實驗設置
我們在三個公開的數據集FewAsp(single)、FewAsp(multi)和FewAsp上進行了實驗,它們共享相同的100個方面類別,其中64個方面用于訓練,16個方面用于驗證,20個方面用于測試。我們使用 Macro-F1 和 AUC 分數作為評估指標,并且 5-way 設置和 10-way 設置中的閾值分別設置為0.3和0.2。
為了驗證LDF框架的優越性,我們選擇了兩個性能最好的主流模型作為我們工作的基礎,即Proto-HATT[8]和Proto-AWATT[4]。換句話說,我們將LDF集成到Proto-HATT和Proto-AWATT中,得到最終模型LDF-HATT和LDF-AWATT。
5.2 主實驗
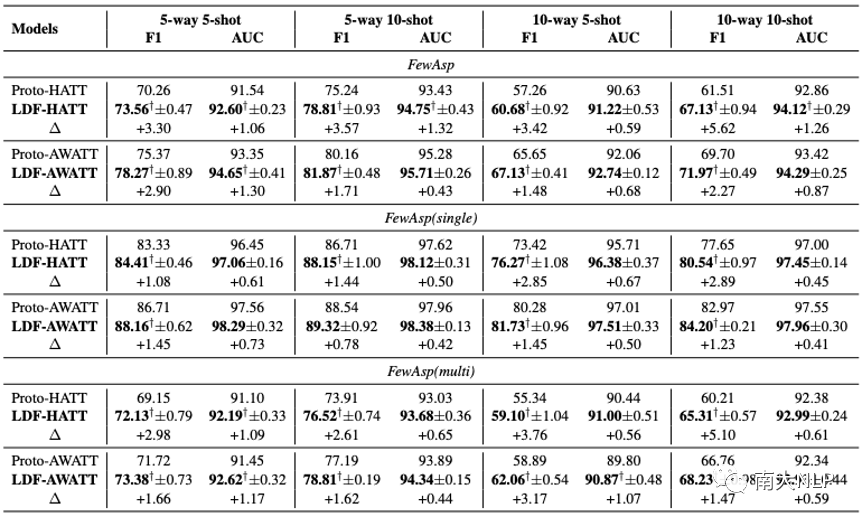
從表2可以看出,LDF-HATT和LDF-AWATT在三個數據集上的性能始終優于其基礎模型。值得一提的是LDF-HATT在Macro-F1和AUC分數上最多獲得了5.62%和1.32%的提升。相比之下,LDF-AWATT最多比Proto-AWATT高3.17%和1.30%。這些結果表明我們的框架具有良好的兼容性。
事實上,LDF-AWATT的Macro-F1在大多數情況下提高了大約2%,而LDF-HATT的Macro-F1平均提高了大約3%。這與我們的預期一致,因為原始Proto-AWATT具有更強大的性能。LDF-HATT和LDF-AWATT在FewAsp(multi)數據集上比在FewAsp(single)數據集上表現更好。
一個可能的原因是FewAsp(multi)數據集中的每個類包含更多的實例,這使得LDF-HATT和LDF-AWATT在多標簽分類中可以生成更準確的原型。
表2:主實驗結果
5.3 消融實驗
在不失一般性的情況下,我們選擇 LDF-AWATT模型進行消融實驗,以研究LDF中單個模塊對模型整體效果的影響。標簽引導的注意力策略簡稱LAS,-標簽加權的對比損失簡稱LCL,有監督的對比學習簡稱SCL。根據表3報告的結果,我們可以觀察到以下幾點:
表3:消融實驗結果

1、與基礎模型Proto-AWATT相比, Proto-AWATT+LAS在三個數據集上取得了具有競爭力的性能,這驗證了利用標簽信息為每個類生成具有代表性原型的合理性;
2、將 LCL 集成到 Proto-AWATT+LAS后,LDF-AWATT 實現了 state-of-the-art 的性能,這表明 LCL 有利于區分相似的原型;
3、LAS 比 LCL 更有效。一個可能的原因是注意力機制是生成原型的核心因素。因此,它對我們的框架貢獻更大;
4、Proto-AWATT+SCL 在FewAsp 數據集上的性能略好于Proto-AWATT,但它們的結果遠低于 Proto-AWATT+LCL,這些結果進一步凸顯了LCL的有效性;
5、將類間關系集成到Proto-AWATT+SCL后,Proto-AWATT+LCL取得了更好的性能,這表明類間關系在區分相似原型方面起著至關重要的作用;
06
案例分析
為了更好地理解我們框架的優勢,我們從FewAsp 數據集中選擇一些樣本進行案例研究。具體來說,我們隨機抽取 5 個類,然后為這5個類抽取 50 次 5-way 5-shot 元任務。最后對于每個類,我們得到 50 個原型向量。
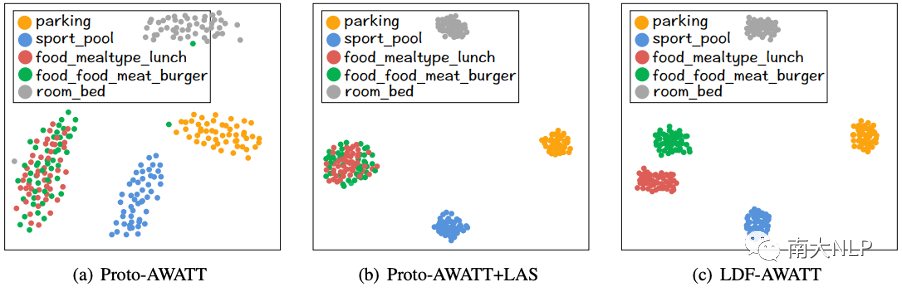
圖4:可視化Proto-AWATT、Proto-AWATT+LAS 和 LDF-AWATT 原型表示
6.1 Proto-AWATT vs. Proto-AWATT+LAS
如圖4(a) 和圖4(b) 所示,我們可以看到Proto-AWATT+LAS 學習到的每個類的原型表示顯然比Proto-AWATT 更集中。這些觀察表明Proto-AWATT+LAS確實可以為每個類生成更準確的原型。
6.2 Proto-AWATT+LAS vs. LDF-AWATT
如圖4(b)和圖4(c)所示,將LCL集成到Proto-AWATT+LAS后,LDF-AWATT學習到的food_mealtype_lunch和food_food_meat_burger的原型表示比Proto-AWATT+LAS更分離。這表明LCL確實可以區分相似的原型。
07
錯誤分析
為了分析我們框架的局限性,我們通過LDF-AWATT 從FewAsp 數據集中隨機抽取 100 個錯誤案例,并將它們大致分為兩類。表4顯示了每個類別的比例和一些代表性示例。主要類別是”Complex”,主要包括需要深入理解的示例。
如示例(1)所示,與 restaurant_location 相關的單詞片段“Chandler Downtown Serrano”在訓練集中出現的次數不超過 5 次,這些表達的低頻率使得我們的模型難以捕捉到它們的模式,因此給出正確的預測確實具有挑戰性。
第二類是”No obvious clues”,主要包括信息不足的例子。如示例(2)所示,句子很短,無法提供足夠的信息來預測真實標簽。
表4:LDF-AWATT模型的錯誤樣例

08
總結
在本文中,我們提出了一種新穎的標簽驅動去噪框架(LDF)來緩解 FS-ACD 任務的噪聲問題。具體來說,我們設計了兩個合理的方法:標簽引導的注意力策略和標簽加權的對比損失,旨在為每個類生成更好的原型并區分相似的原型。大量實驗的結果表明,我們的框架 LDF 與其他最先進的方法相比實現了更好的性能。
論文鏈接:
https://arxiv.org/pdf/2210.04220.pdf
代碼鏈接:
https://github.com/1429904852/LDF
審核編輯:劉清
-
ACD
+關注
關注
0文章
13瀏覽量
11309 -
分類器
+關注
關注
0文章
152瀏覽量
13175 -
卷積神經網絡
+關注
關注
4文章
366瀏覽量
11853
原文標題:EMNLP'22 Findings | 用于多標簽少樣本方面類別檢測的標簽驅動去噪框架
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種面向飛行試驗的數據融合框架

為電機一體化應用提供一種雙通道集成電機驅動方案的電機驅動芯片-SS6811H

芯科科技完整的藍牙解決方案助推電子貨架標簽應用
頻譜儀測載噪比怎么測
一種高效的KV緩存壓縮框架--GEAR


介紹一種OpenAtom OpenHarmony輕量系統適配方案

一種高效1.5V/4.2V的LED驅動器電路
賽默斐視表面瑕疵檢測系統是一種利用機器視覺技術
rfid電子標簽的兩種耦合方式
框架與芯片粘接中兩種涂膠






 工商網監
工商網監
評論