 無需權重更新、微調,Transformer在試錯中自主改進!
無需權重更新、微調,Transformer在試錯中自主改進!
DeepMind 表示,他們提出的算法蒸餾(AD)是首個通過對具有模仿損失的離線數據進行順序建模以展示上下文強化學習的方法。同時基于觀察結果開啟了一種可能,即任何 RL 算法都可以通過模仿學習蒸餾成足夠強大的序列模型如 transformer,并將這些模型轉換為上下文 RL 算法。
目前,Transformers 已經成為序列建模的強大神經網絡架構。預訓練 transformer 的一個顯著特性是它們有能力通過提示 conditioning 或上下文學習來適應下游任務。經過大型離線數據集上的預訓練之后,大規模 transformers 已被證明可以高效地泛化到文本補全、語言理解和圖像生成方面的下游任務。
最近的工作表明,transformers 還可以通過將離線強化學習(RL)視作順序預測問題,進而從離線數據中學習策略。Chen et al. (2021)的工作表明,transformers 可以通過模仿學習從離線 RL 數據中學習單任務策略,隨后的工作表明 transformers 可以在同領域和跨領域設置中提取多任務策略。這些工作都展示了提取通用多任務策略的范式,即首先收集大規模和多樣化的環境交互數據集,然后通過順序建模從數據中提取策略。這類通過模仿學習從離線 RL 數據中學習策略的方法被稱為離線策略蒸餾(Offline Policy Distillation)或策略蒸餾(Policy Distillation, PD)。
PD 具有簡單性和可擴展性,但它的一大缺點是生成的策略不會在與環境的額外交互中逐步改進。舉例而言,谷歌的通才智能體 Multi-Game Decision Transformers 學習了一個可以玩很多 Atari 游戲的返回條件式(return-conditioned)策略,而 DeepMind 的通才智能體 Gato 通過上下文任務推理來學習一個解決多樣化環境中任務的策略。遺憾的是,這兩個智能體都不能通過試錯來提升上下文中的策略。因此 PD 方法學習的是策略而不是強化學習算法。
在近日 DeepMind 的一篇論文中,研究者假設 PD 沒能通過試錯得到改進的原因是它訓練用的數據無法顯示學習進度。當前方法要么從不含學習的數據中學習策略(例如通過蒸餾固定專家策略),要么從包含學習的數據中學習策略(例如 RL 智能體的重放緩沖區),但后者的上下文大小(太小)無法捕獲策略改進。

論文地址:https://arxiv.org/pdf/2210.14215.pdf
研究者的主要觀察結果是,RL 算法訓練中學習的順序性在原則上可以將強化學習本身建模為一個因果序列預測問題。具體地,如果一個 transformer 的上下文足夠長,包含了由學習更新帶來的策略改進,那么它不僅應該可以表示一個固定策略,而且能夠通過關注之前 episodes 的狀態、動作和獎勵來表示一個策略改進算子。這樣開啟了一種可能性,即任何 RL 算法都可以通過模仿學習蒸餾成足夠強大的序列模型如 transformer,并將這些模型轉換為上下文 RL 算法。
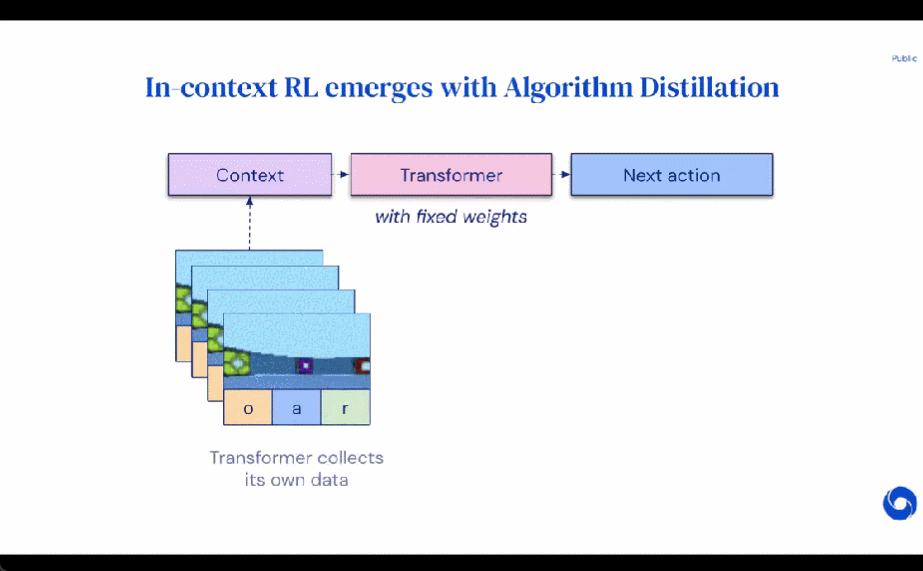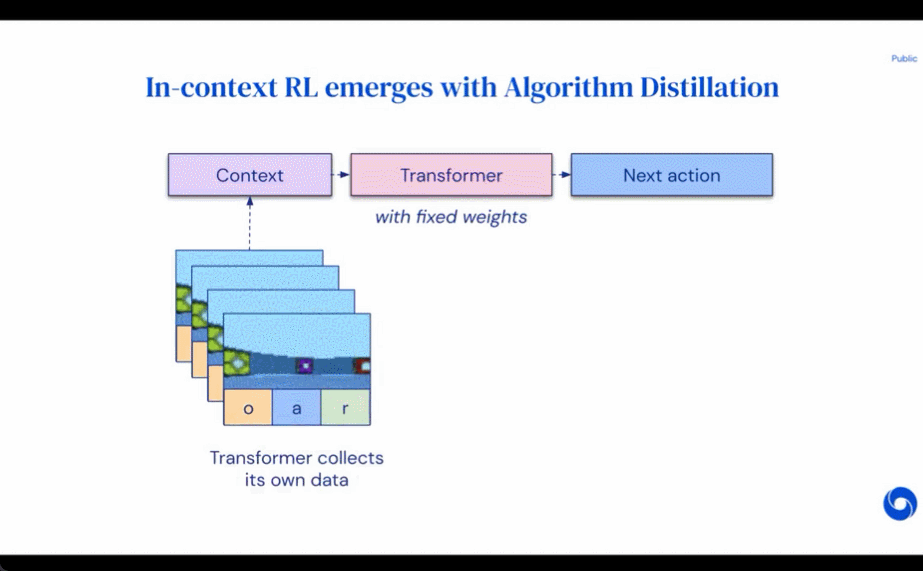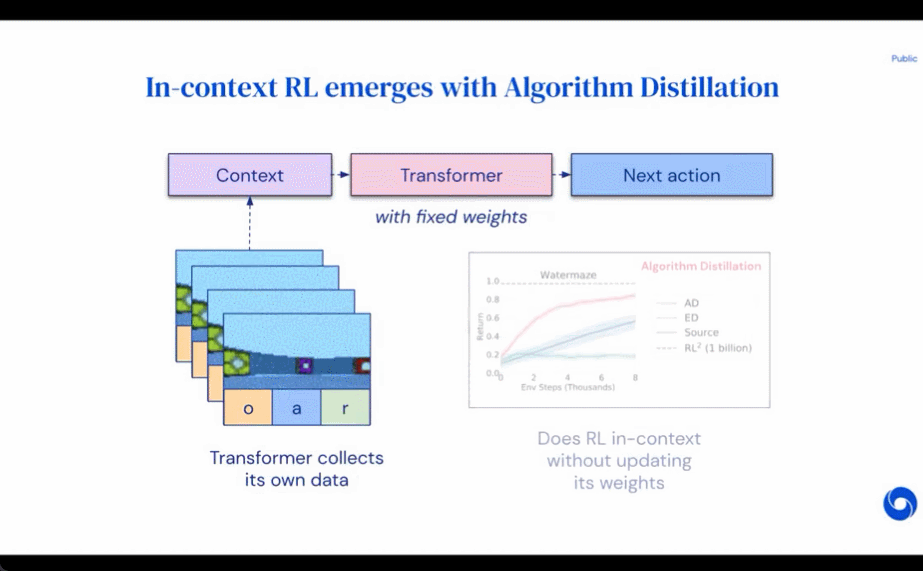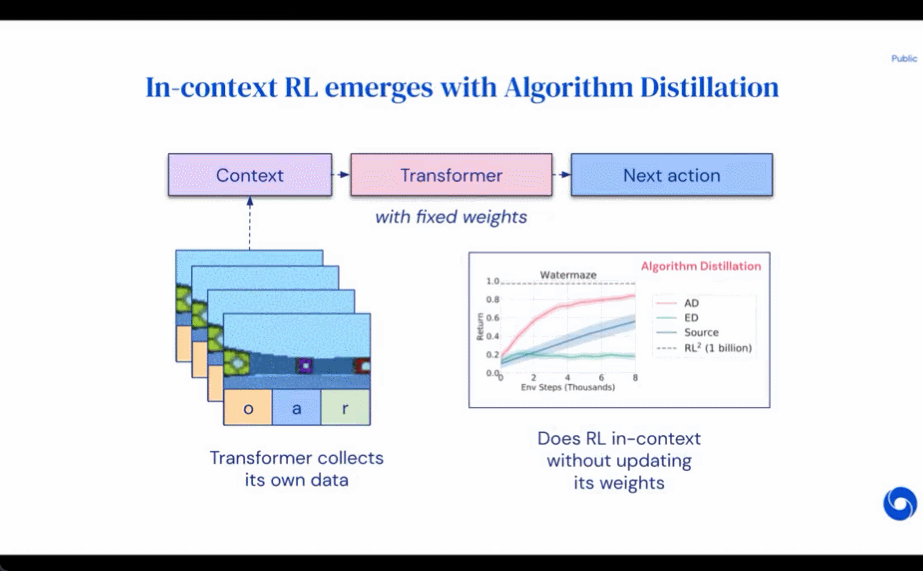
研究者提出了算法蒸餾(Algorithm Distillation, AD),這是一種通過優化 RL 算法學習歷史中因果序列預測損失來學習上下文策略改進算子的方法。如下圖 1 所示,AD 由兩部分組成。首先通過保存 RL 算法在大量單獨任務上的訓練歷史來生成大型多任務數據集,然后 transformer 模型通過將前面的學習歷史用作其上下文來對動作進行因果建模。由于策略在源 RL 算法的訓練過程中持續改進,因此 AD 不得不學習改進算子以便準確地建模訓練歷史中任何給定點的動作。至關重要的一點是,transformer 上下文必須足夠大(即 across-episodic)才能捕獲訓練數據的改進。
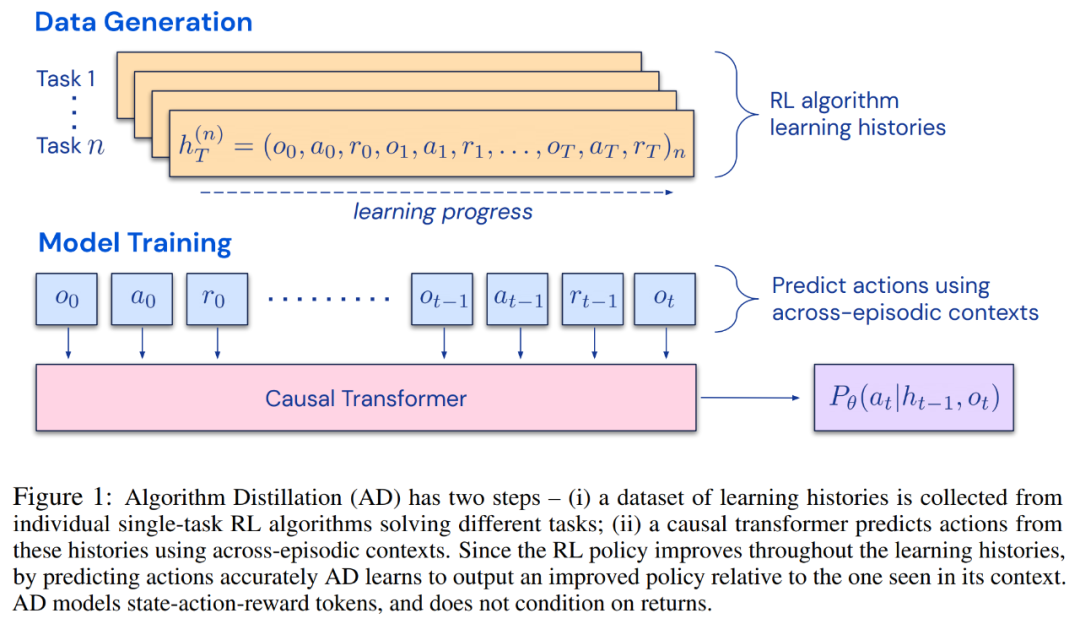
研究者表示,通過使用足夠大上下文的因果 transformer 來模仿基于梯度的 RL 算法,AD 完全可以在上下文中強化新任務學習。研究者在很多需要探索的部分可觀察環境中評估了 AD,包括來自 DMLab 的基于像素的 Watermaze,結果表明 AD 能夠進行上下文探索、時序信度分配和泛化。此外,AD 學習到的算法比生成 transformer 訓練源數據的算法更加高效。
最后值得關注的是,AD 是首個通過對具有模仿損失的離線數據進行順序建模以展示上下文強化學習的方法。
方法
在生命周期內,強化學習智能體需要在執行復雜的動作方面表現良好。對智能體而言,不管它所處的環境、內部結構和執行情況如何,都可以被視為是在過去經驗的基礎上完成的。可用如下形式表示:
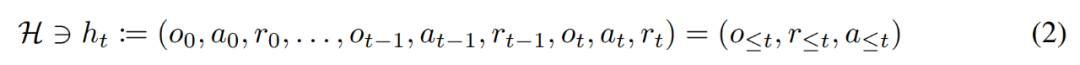
研究者同時將「長期歷史條件, long history-conditioned」策略看作一種算法,得出:

其中?(A)表示動作空間 A 上的概率分布空間。公式 (3) 表明,該算法可以在環境中展開,以生成觀察、獎勵和動作序列。為了簡單起見,該研究將算法用 P 表示,將環境(即任務)用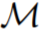 的學習歷史都是由算法表示,這樣對于任何給定任務
的學習歷史都是由算法表示,這樣對于任何給定任務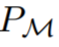 生成的。可以得到
生成的。可以得到
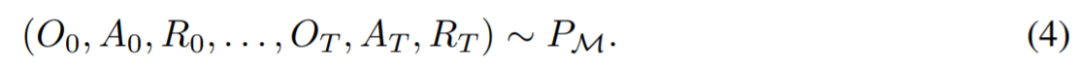
研究者用大寫拉丁字母表示隨機變量,例如 O、A、R 及其對應的小寫形式 o,α,r。通過將算法視為長期歷史條件策略,他們假設任何生成學習歷史的算法都可以通過對動作執行行為克隆來轉換成神經網絡。接下來,該研究提出了一種方法,該方法提供了智能體在生命周期內學習具有行為克隆的序列模型,以將長期歷史映射到動作分布。
實際執行
在實踐中,該研究將算法蒸餾過程 ( algorithm distillation ,AD)實現為一個兩步過程。首先,通過在許多不同的任務上運行單獨的基于梯度的 RL 算法來收集學習歷史數據集。接下來,訓練具有多情節上下文的序列模型來預測歷史中的動作。具體算法如下所示:

實驗
實驗要求所使用的環境都支持許多任務,而這些任務不能從觀察中輕易的進行推斷,并且情節(episodes)足夠短,可以有效地訓練跨情節因果 transformers。這項工作的主要目的是調查相對于先前工作,AD 強化在多大程度上是在上下文中學習的。實驗將 AD、 ED( Expert Distillation) 、RL^2 等進行了比較。
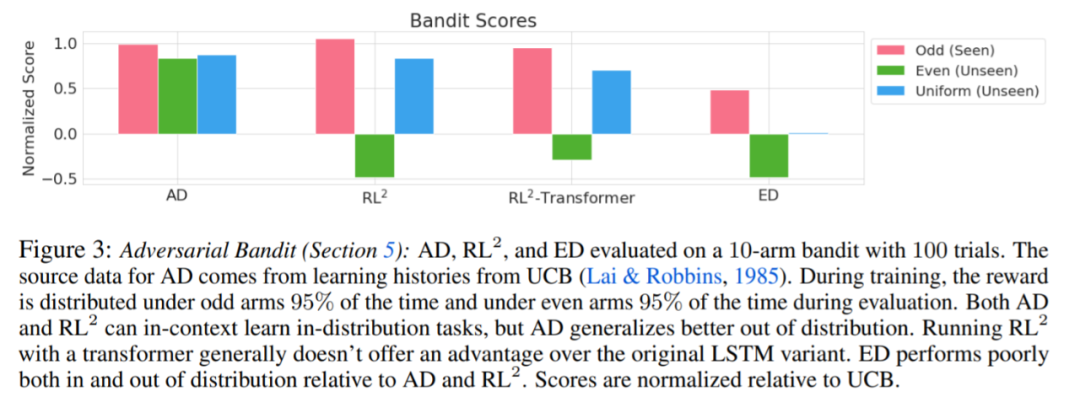
評估 AD、ED、 RL^2 結果如圖 3 所示。該研究發現 AD 和 RL^2 都可以在上下文中學習從訓練分布中采樣的任務,而 ED 則不能,盡管 ED 在分布內評估時確實比隨機猜測做得更好。
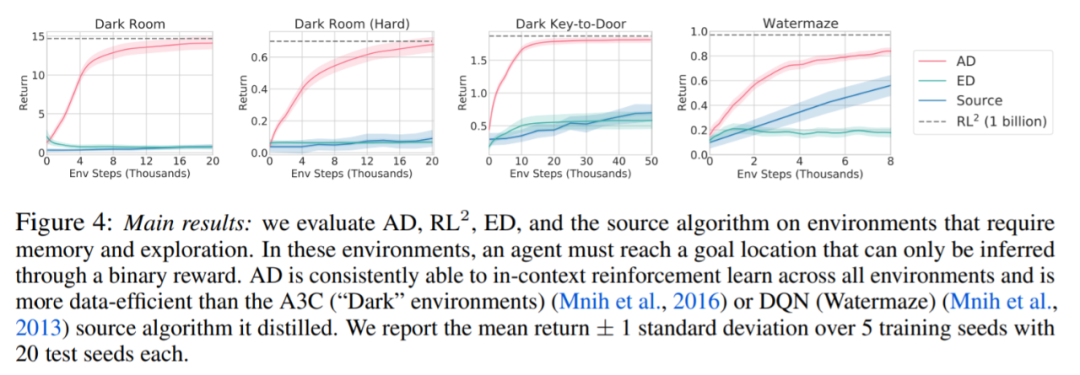
圍繞下圖 4,研究者回答了一系列問題。AD 是否表現出上下文強化學習?結果表明 AD 上下文強化學習在所有環境中都能學習,相比之下,ED 在大多數情況下都無法在上下文中探索和學習。
AD 能從基于像素的觀察中學習嗎?結果表明 AD 通過上下文 RL 最大化了情景回歸,而 ED 則不能學習。
AD 是否可以學習一種比生成源數據的算法更有效的 RL 算法?結果表明 AD 的數據效率明顯高于源算法(A3C 和 DQN)。
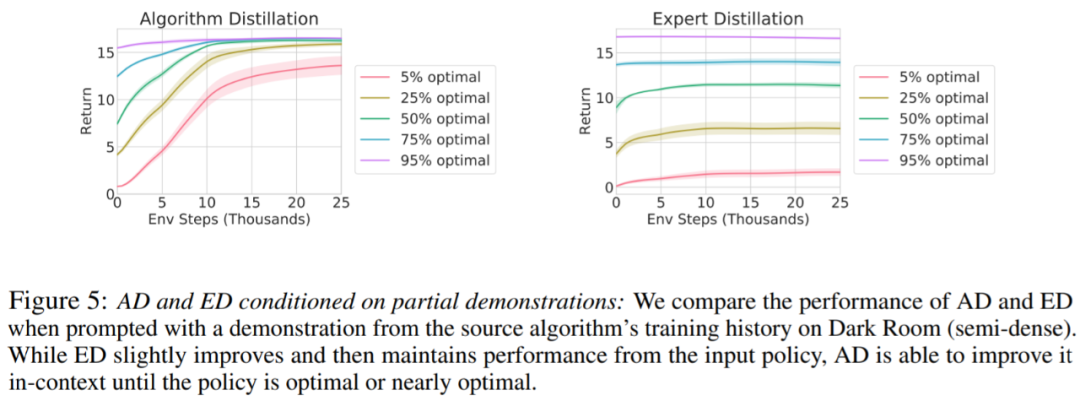
是否可以通過演示來加速 AD?為了回答這個問題,該研究保留測試集數據中沿源算法歷史的不同點采樣策略,然后,使用此策略數據預先填充 AD 和 ED 的上下文,并在 Dark Room 的環境中運行這兩種方法,將結果繪制在圖 5 中。雖然 ED 保持了輸入策略的性能,AD 在上下文中改進每個策略,直到它接近最優。重要的是,輸入策略越優化,AD 改進它的速度就越快,直到達到最優。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4764瀏覽量
100541 -
數據集
+關注
關注
4文章
1205瀏覽量
24644 -
DeepMind
+關注
關注
0文章
129瀏覽量
10819
原文標題:DeepMind新作!無需權重更新、微調,Transformer在試錯中自主改進!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦


示波器探頭補償微調旋鈕的作用
Transformer語言模型簡介與實現過程
大模型為什么要微調?大模型微調的原理
Transformer架構在自然語言處理中的應用
深度學習中的模型權重
Transformer模型在語音識別和語音生成中的應用優勢
使用PyTorch搭建Transformer模型
基于Transformer模型的壓縮方法

一文詳解Transformer神經網絡模型

四種微調大模型的方法介紹
更深層的理解視覺Transformer, 對視覺Transformer的剖析
一種新穎的大型語言模型知識更新微調范式

快速渡過新手期!華為云服務器讓小程序開發的試錯成本更低





 工商網監
工商網監
評論