 Redis分布式鎖的使用場景
Redis分布式鎖的使用場景
分布式鎖(SET NX)
分布式鎖Redlock
基于ZooKeeper的分布式鎖更安全嗎?
總結
今天我們來聊一聊Redis分布式鎖。
首先大家可以先思考一個簡單的問題,為什么要使用分布式鎖?普通的jvm鎖為什么不可以?
這個時候,大家肯定會吧啦吧啦想到一堆,例如java應用屬于進程級,不同的ecs中部署相同的應用,他們之間相互獨立。
所以,在分布式系統中,當有多個客戶端需要獲取鎖時,我們需要分布式鎖。此時,鎖是保存在一個共享存儲系統中的,可以被多個客戶端共享訪問和獲取。
分布式鎖(SET NX)
知道了分布式鎖的使用場景,我們來自己簡單的實現下分布式鎖:
publicclassIndexController{ publicStringdeductStock(){ StringlockKey="lock:product_101"; //setNx獲取分布式鎖 StringclientId=UUID.randomUUID().toString(); Booleanresult=stringRedisTemplate.opsForValue().setIfAbsent(lockKey,clientId,30,TimeUnit.SECONDS);//jedis.setnx(k,v) if(!result){ return"error_code"; } try{ intstock=Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));//jedis.get("stock") if(stock>0){ intrealStock=stock-1; stringRedisTemplate.opsForValue().set("stock",realStock+"");//jedis.set(key,value) System.out.println("扣減成功,剩余庫存:"+realStock); }else{ System.out.println("扣減失敗,庫存不足"); } }finally{ //解鎖 if(clientId.equals(stringRedisTemplate.opsForValue().get(lockKey))){ stringRedisTemplate.delete(lockKey); } } }
以上代碼簡單的實現了一個扣減庫存的業務邏輯,我們拆開來說下都做了什么事情:
1、首先聲明了lockkey,表示我們需要set的keyName
2、其次UUID.randomUUID().toString();生成該次請求的requestId,為什么需要生成這個唯一的UUID,后面在解鎖的時候會說到
3、獲取分布式鎖,通過stringRedisTemplate.opsForValue().setIfAbsent來實現,該語句的意思是如果存在該key則返回false,若不存在則進行key的設置,設置成功后返回true,將當前線程獲取的uuid設置成value,給定一個鎖的過期時間,防止該線程無限制持久鎖導致死鎖,也為了防止該服務器突然宕機,導致其他機器的應用無法獲取該鎖,這個是必須要做的設置,至于過期的時間,可以根據內層業務邏輯的執行時間來決定
4、執行內層的業務邏輯,進行扣庫存的操作
5、業務邏輯執行完成后,走到finally的解鎖操作,進行解鎖操作時,首先我們來判斷當前鎖的值是否為該線程持有的,防止當前線程執行較慢,導致鎖過期,從而刪除了其他線程持有的分布式鎖,對于該操作,我來舉個例子:
時刻1:線程A獲取分布式鎖,開始執行業務邏輯
時刻2:線程B等待分布式鎖釋放
時刻3:線程A所在機器IO處理緩慢、GC pause等問題導致處理緩慢
時刻4:線程A依舊處于block狀態,鎖過期
時刻5:線程B獲取分布式鎖,開始執行業務邏輯,此時線程A結束block,開始釋放鎖
時刻6:線程B處理業務邏輯緩慢,線程A釋放分布式鎖,但是此時釋放的是線程B的鎖,導致其他線程可以開始獲取鎖
看到這里,為什么每個請求需要requestId,并且在釋放鎖的情況下判斷是否是當前的requestId是有必要的。
以上,就是一個簡單的分布式鎖的實現過程。但是你覺得上述實現還存在問題嗎?
答案是肯定的。若是在判斷完分布式鎖的value與requestId之后,鎖過期了,依然會存在以上問題。
那么有沒有什么辦法可以規避以上問題,讓我們不需要去完成這些實現,只需要專注于業務邏輯呢?
我們可以使用Redisson,并且Redisson有中文文檔,方便英文不好的同學查看(開發團隊中有中國的jackygurui)。
接下來我們再把上述代碼簡單的改造下就可以規避這些問題:
publicclassIndexController{
publicStringdeductStock(){
StringlockKey="lock:product_101";
//setNx獲取分布式鎖
//StringclientId=UUID.randomUUID().toString();
//Booleanresult=stringRedisTemplate.opsForValue().setIfAbsent(lockKey,clientId,30,TimeUnit.SECONDS);//jedis.setnx(k,v)
//獲取鎖對象
RLockredissonLock=redisson.getLock(lockKey);
//加分布式鎖
redissonLock.lock();
try{
intstock=Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));//jedis.get("stock")
if(stock>0){
intrealStock=stock-1;
stringRedisTemplate.opsForValue().set("stock",realStock+"");//jedis.set(key,value)
System.out.println("扣減成功,剩余庫存:"+realStock);
}else{
System.out.println("扣減失敗,庫存不足");
}
}finally{
//解鎖
//if(clientId.equals(stringRedisTemplate.opsForValue().get(lockKey))){
//stringRedisTemplate.delete(lockKey);
//}
//redisson分布式鎖解鎖
redissonLock.unlock();
}
}
可以看到,使用redisson分布式鎖會簡單很多,我們通過redissonLock.lock()和redissonLock.unlock()解決了這個問題,看到這里,是不是有同學會問,如果服務器宕機了,分布式鎖會一直存在嗎,也沒有去指定過期時間?
redisson分布式鎖中有一個watchdog機制,即會給一個leaseTime,默認為30s,到期后鎖自動釋放,如果一直沒有解鎖,watchdog機制會一直重新設定鎖的過期時間,通過設置TimeTask,延遲10s再次執行鎖續命,將鎖的過期時間重置為30s。下面就從redisson.lock()的源碼來看下:
lock的最終加鎖方法:
RFuture tryLockInnerAsync(longleaseTime,TimeUnitunit,longthreadId,RedisStrictCommand command){ internalLockLeaseTime=unit.toMillis(leaseTime); returncommandExecutor.evalWriteAsync(getName(),LongCodec.INSTANCE,command, "if(redis.call('exists',KEYS[1])==0)then"+ "redis.call('hset',KEYS[1],ARGV[2],1);"+ "redis.call('pexpire',KEYS[1],ARGV[1]);"+ "returnnil;"+ "end;"+ "if(redis.call('hexists',KEYS[1],ARGV[2])==1)then"+ "redis.call('hincrby',KEYS[1],ARGV[2],1);"+ "redis.call('pexpire',KEYS[1],ARGV[1]);"+ "returnnil;"+ "end;"+ "returnredis.call('pttl',KEYS[1]);", Collections.
可以看到lua腳本中redis.call('pexpire', KEYS[1], ARGV[1]);對key進行設置,并給定了一個internalLockLeaseTime,給定的internalLockLeaseTime就是默認的加鎖時間,為30s。
接下來我們在看下鎖續命的源碼:
privatevoidscheduleExpirationRenewal(finallongthreadId){
if(!expirationRenewalMap.containsKey(this.getEntryName())){
Timeouttask=this.commandExecutor.getConnectionManager().newTimeout(newTimerTask(){
publicvoidrun(Timeouttimeout)throwsException{
//重新設置鎖過期時間
RFuturefuture=RedissonLock.this.commandExecutor.evalWriteAsync(RedissonLock.this.getName(),LongCodec.INSTANCE,RedisCommands.EVAL_BOOLEAN,"if(redis.call('hexists',KEYS[1],ARGV[2])==1)thenredis.call('pexpire',KEYS[1],ARGV[1]);return1;end;return0;",Collections.singletonList(RedissonLock.this.getName()),newObject[]{RedissonLock.this.internalLockLeaseTime,RedissonLock.this.getLockName(threadId)});
future.addListener(newFutureListener(){
publicvoidoperationComplete(Futurefuture)throwsException{
RedissonLock.expirationRenewalMap.remove(RedissonLock.this.getEntryName());
if(!future.isSuccess()){
RedissonLock.log.error("Can'tupdatelock"+RedissonLock.this.getName()+"expiration",future.cause());
}else{
//獲取方法調用的結果
if((Boolean)future.getNow()){
//進行遞歸調用
RedissonLock.this.scheduleExpirationRenewal(threadId);
}
}
}
});
}
//延遲this.internalLockLeaseTime/3L再執行run方法
},this.internalLockLeaseTime/3L,TimeUnit.MILLISECONDS);
if(expirationRenewalMap.putIfAbsent(this.getEntryName(),task)!=null){
task.cancel();
}
}
}
從源碼層可以看到,加鎖成功后,會延遲10s執行task中的run方法,然后在run方法里面執行鎖過期時間的重置,如果時間重置成功,則繼續遞歸調用該方法,延遲10s后進行鎖續命,若重置鎖時間失敗,則可能表示鎖已釋放,退出該方法。
以上,就是關于一個redis分布式鎖的說明,看到這里,大家應該對分布式鎖有一個大致的了解了。
但是盡管使用了redisson完成分布式鎖的實現,對于分布式鎖是否還存在問題,分布式鎖真的安全嗎?
一般的,線上的環境肯定使用redis cluster,如果數據量不大,也會使用的redis sentinal。那么就存在主從復制的問題,那么是否會存在這種情況,在主庫設置了分布式鎖,但是可能由于網絡或其他原因導致數據還沒有同步到從庫,此時主庫宕機,選擇從庫作為主庫,新主庫中并沒有該鎖的信息,其他線程又可以進行鎖申請,造成了發生線程安全問題的可能。
為了解決這個問題,redis的作者實現了redlock,基于redlock的實現有很大的爭論,并且現在已經棄用了,但是我們還是需要了解下原理,以及之后基于這些問題的解決方案。
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
項目地址:https://gitee.com/zhijiantianya/ruoyi-vue-pro
視頻教程:https://doc.iocoder.cn/video/
分布式鎖Redlock
Redlock是基于單Redis節點的分布式鎖在failover的時候會產生解決不了的安全性問題而產生的,基于N個完全獨立的Redis節點。
下面我來看下redlock獲取鎖的過程:
運行Redlock算法的客戶端依次執行下面各個步驟,來完成獲取鎖 的操作:
獲取當前時間(毫秒數)。
按順序依次向N個Redis節點執行獲取鎖 的操作。這個獲取操作跟前面基于單Redis節點的獲取鎖 的過程相同,包含隨機字符串my_random_value,也包含過期時間(比如PX 30000,即鎖的有效時間)。為了保證在某個Redis節點不可用的時候算法能夠繼續運行,這個獲取鎖 的操作還有一個超時時間(time out),它要遠小于鎖的有效時間(幾十毫秒量級)。客戶端在向某個Redis節點獲取鎖失敗以后,應該立即嘗試下一個Redis節點。這里的失敗,應該包含任何類型的失敗,比如該Redis節點不可用,或者該Redis節點上的鎖已經被其它客戶端持有
計算整個獲取鎖的過程總共消耗了多長時間,計算方法是用當前時間減去第1步記錄的時間。如果客戶端從大多數Redis節點(>= N/2+1)成功獲取到了鎖,并且獲取鎖總共消耗的時間沒有超過鎖的有效時間(lock validity time),那么這時客戶端才認為最終獲取鎖成功;否則,認為最終獲取鎖失敗。
如果最終獲取鎖成功了,那么這個鎖的有效時間應該重新計算,它等于最初的鎖的有效時間減去第3步計算出來的獲取鎖消耗的時間。
如果最終獲取鎖失敗了(可能由于獲取到鎖的Redis節點個數少于N/2+1,或者整個獲取鎖的過程消耗的時間超過了鎖的最初有效時間),那么客戶端應該立即向所有Redis節點發起釋放鎖 的操作。
好了,了解了redlock獲取鎖的機制之后,我們再來討論下redlock會有哪些問題:
問題一:
假設一共有5個Redis節點:A, B, C, D, E。設想發生了如下的事件序列:
客戶端1成功鎖住了A, B, C,獲取鎖 成功(但D和E沒有鎖住)。
節點C崩潰重啟了,但客戶端1在C上加的鎖沒有持久化下來,丟失了。
節點C重啟后,客戶端2鎖住了C, D, E,獲取鎖 成功。
這樣,客戶端1和客戶端2同時獲得了鎖(針對同一資源)。
在默認情況下,Redis的AOF持久化方式是每秒寫一次磁盤(即執行fsync),因此最壞情況下可能丟失1秒的數據。為了盡可能不丟數據,Redis允許設置成每次修改數據都進行fsync,但這會降低性能。當然,即使執行了fsync也仍然有可能丟失數據(這取決于系統而不是Redis的實現)。所以,上面分析的由于節點重啟引發的鎖失效問題,總是有可能出現的。為了應對這一問題,Redis作者antirez又提出了延遲重啟 (delayed restarts)的概念。也就是說,一個節點崩潰后,先不立即重啟它,而是等待一段時間再重啟,這段時間應該大于鎖的有效時間(lock validity time)。這樣的話,這個節點在重啟前所參與的鎖都會過期,它在重啟后就不會對現有的鎖造成影響。
關于Redlock還有一點細節值得拿出來分析一下:在最后釋放鎖 的時候,antirez在算法描述中特別強調,客戶端應該向所有Redis節點發起釋放鎖 的操作。也就是說,即使當時向某個節點獲取鎖沒有成功,在釋放鎖的時候也不應該漏掉這個節點。這是為什么呢?設想這樣一種情況,客戶端發給某個Redis節點的獲取鎖 的請求成功到達了該Redis節點,這個節點也成功執行了SET操作,但是它返回給客戶端的響應包卻丟失了。這在客戶端看來,獲取鎖的請求由于超時而失敗了,但在Redis這邊看來,加鎖已經成功了。因此,釋放鎖的時候,客戶端也應該對當時獲取鎖失敗的那些Redis節點同樣發起請求。實際上,這種情況在異步通信模型中是有可能發生的:客戶端向服務器通信是正常的,但反方向卻是有問題的。
所以,如果不進行延遲重啟,或者對于同一個主節點進行多個從節點的備份,并要求從節點的同步必須實時跟住主節點,也就是說需要配置redis從庫的同步策略,將延遲設置為最小(主從同步是異步進行的),通過min-replicas-max-lag(舊版本的redis使用min-slaves-max-lag)來設置主從庫間進行數據復制時,從庫給主庫發送 ACK 消息的最大延遲(以秒為單位),也就是說,這個值需要設置為0,否則都有可能出現延遲,但是這個實際上在redis中是不存在的,min-replicas-max-lag設置為0,就代表著這個配置不生效。redis本身是為了高效而存在的,如果因為需要保證業務的準確性而使用,大大降低了redis的性能,建議使用的別的方式。
問題二:
如果客戶端長期阻塞導致鎖過期,那么它接下來訪問共享資源就不安全了(沒有了鎖的保護)。在RedLock中還是存在該問題的。
雖然在獲取鎖之后Redlock會去判斷鎖的有效性,如果鎖過期了,則會再去重新拿鎖。但是如果發生在獲取鎖之后,那么該有效性都得不到保障了。
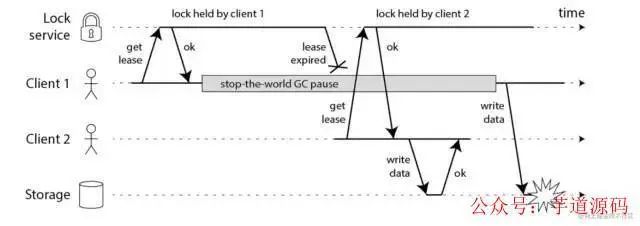
在上面的時序圖中,假設鎖服務本身是沒有問題的,它總是能保證任一時刻最多只有一個客戶端獲得鎖。上圖中出現的lease這個詞可以暫且認為就等同于一個帶有自動過期功能的鎖。客戶端1在獲得鎖之后發生了很長時間的GC pause,在此期間,它獲得的鎖過期了,而客戶端2獲得了鎖。當客戶端1從GC pause中恢復過來的時候,它不知道自己持有的鎖已經過期了,它依然向共享資源(上圖中是一個存儲服務)發起了寫數據請求,而這時鎖實際上被客戶端2持有,因此兩個客戶端的寫請求就有可能沖突(鎖的互斥作用失效了)。
初看上去,有人可能會說,既然客戶端1從GC pause中恢復過來以后不知道自己持有的鎖已經過期了,那么它可以在訪問共享資源之前先判斷一下鎖是否過期。但仔細想想,這絲毫也沒有幫助。因為GC pause可能發生在任意時刻,也許恰好在判斷完之后。
也有人會說,如果客戶端使用沒有GC的語言來實現,是不是就沒有這個問題呢?質疑者Martin指出,系統環境太復雜,仍然有很多原因導致進程的pause,比如虛存造成的缺頁故障(page fault),再比如CPU資源的競爭。即使不考慮進程pause的情況,網絡延遲也仍然會造成類似的結果。
總結起來就是說,即使鎖服務本身是沒有問題的,而僅僅是客戶端有長時間的pause或網絡延遲,仍然會造成兩個客戶端同時訪問共享資源的沖突情況發生。
那怎么解決這個問題呢?Martin給出了一種方法,稱為fencing token。fencing token是一個單調遞增的數字,當客戶端成功獲取鎖的時候它隨同鎖一起返回給客戶端。而客戶端訪問共享資源的時候帶著這個fencing token,這樣提供共享資源的服務就能根據它進行檢查,拒絕掉延遲到來的訪問請求(避免了沖突)。如下圖:
在上圖中,客戶端1先獲取到的鎖,因此有一個較小的fencing token,等于33,而客戶端2后獲取到的鎖,有一個較大的fencing token,等于34。客戶端1從GC pause中恢復過來之后,依然是向存儲服務發送訪問請求,但是帶了fencing token = 33。存儲服務發現它之前已經處理過34的請求,所以會拒絕掉這次33的請求。這樣就避免了沖突。
但是,對于客戶端和資源服務器之間的延遲(即發生在算法第3步之后的延遲),antirez是承認所有的分布式鎖的實現,包括Redlock,是沒有什么好辦法來應對的。包括在我們到生產環境中,無法避免分布式鎖超時。
在討論中,有人提出客戶端1和客戶端2都發生了GC pause,兩個fencing token都延遲了,它們幾乎同時到達了文件服務器,而且保持了順序。那么,我們新加入的判斷邏輯,即判斷fencing token的合理性,應該對兩個請求都會放過,而放過之后它們幾乎同時在操作文件,還是沖突了。既然Martin宣稱fencing token能保證分布式鎖的正確性,那么上面這種可能的猜測也許是我們理解錯了。但是Martin并沒有在后面做出解釋。
問題三:
Redlock對系統記時(timing)的過分依賴,下面給出一個例子(還是假設有5個Redis節點A, B, C, D, E):
客戶端1從Redis節點A, B, C成功獲取了鎖(多數節點)。由于網絡問題,與D和E通信失敗。
節點C上的時鐘發生了向前跳躍,導致它上面維護的鎖快速過期。
客戶端2從Redis節點C, D, E成功獲取了同一個資源的鎖(多數節點)。
客戶端1和客戶端2現在都認為自己持有了鎖。
上面這種情況之所以有可能發生,本質上是因為Redlock的安全性(safety property)對系統的時鐘有比較強的依賴,一旦系統的時鐘變得不準確,算法的安全性也就保證不了了。
但是作者反駁到,通過恰當的運維,完全可以避免時鐘發生大的跳動,而Redlock對于時鐘的要求在現實系統中是完全可以滿足的。哪怕是手動修改時鐘這種人為原因,不要那么做就是了。否則的話,都會出現問題。
說了這么多關于Redlock的問題,到底有沒有什么分布式鎖能保證安全性呢?我們接下來再來看看ZooKeeper分布式鎖。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
項目地址:https://gitee.com/zhijiantianya/yudao-cloud
視頻教程:https://doc.iocoder.cn/video/
基于ZooKeeper的分布式鎖更安全嗎?
很多人(也包括Martin在內)都認為,如果你想構建一個更安全的分布式鎖,那么應該使用ZooKeeper,而不是Redis。那么,為了對比的目的,讓我們先暫時脫離開本文的題目,討論一下基于ZooKeeper的分布式鎖能提供絕對的安全嗎?它需要fencing token機制的保護嗎?
Flavio Junqueira是ZooKeeper的作者之一,他的這篇blog就寫在Martin和antirez發生爭論的那幾天。他在文中給出了一個基于ZooKeeper構建分布式鎖的描述(當然這不是唯一的方式):
客戶端嘗試創建一個znode節點,比如/lock。那么第一個客戶端就創建成功了,相當于拿到了鎖;而其它的客戶端會創建失敗(znode已存在),獲取鎖失敗。
持有鎖的客戶端訪問共享資源完成后,將znode刪掉,這樣其它客戶端接下來就能來獲取鎖了。
znode應該被創建成ephemeral的。這是znode的一個特性,它保證如果創建znode的那個客戶端崩潰了,那么相應的znode會被自動刪除。這保證了鎖一定會被釋放。
看起來這個鎖相當完美,沒有Redlock過期時間的問題,而且能在需要的時候讓鎖自動釋放。但仔細考察的話,并不盡然。
ZooKeeper是怎么檢測出某個客戶端已經崩潰了呢?實際上,每個客戶端都與ZooKeeper的某臺服務器維護著一個Session,這個Session依賴定期的心跳(heartbeat)來維持。如果ZooKeeper長時間收不到客戶端的心跳(這個時間稱為Sesion的過期時間),那么它就認為Session過期了,通過這個Session所創建的所有的ephemeral類型的znode節點都會被自動刪除。
設想如下的執行序列:
客戶端1創建了znode節點/lock,獲得了鎖。
客戶端1進入了長時間的GC pause。
客戶端1連接到ZooKeeper的Session過期了。znode節點/lock被自動刪除。
客戶端2創建了znode節點/lock,從而獲得了鎖。
客戶端1從GC pause中恢復過來,它仍然認為自己持有鎖。
最后,客戶端1和客戶端2都認為自己持有了鎖,沖突了。這與之前Martin在文章中描述的由于GC pause導致的分布式鎖失效的情況類似。
看起來,用ZooKeeper實現的分布式鎖也不一定就是安全的。該有的問題它還是有。但是,ZooKeeper作為一個專門為分布式應用提供方案的框架,它提供了一些非常好的特性,是Redis之類的方案所沒有的。像前面提到的ephemeral類型的znode自動刪除的功能就是一個例子。
還有一個很有用的特性是ZooKeeper的watch機制。這個機制可以這樣來使用,比如當客戶端試圖創建/lock的時候,發現它已經存在了,這時候創建失敗,但客戶端不一定就此對外宣告獲取鎖失敗。客戶端可以進入一種等待狀態,等待當/lock節點被刪除的時候,ZooKeeper通過watch機制通知它,這樣它就可以繼續完成創建操作(獲取鎖)。這可以讓分布式鎖在客戶端用起來就像一個本地的鎖一樣:加鎖失敗就阻塞住,直到獲取到鎖為止。這樣的特性Redlock就無法實現。
小結一下,基于ZooKeeper的鎖和基于Redis的鎖相比在實現特性上有兩個不同:
在正常情況下,客戶端可以持有鎖任意長的時間,這可以確保它做完所有需要的資源訪問操作之后再釋放鎖。這避免了基于Redis的鎖對于有效時間(lock validity time)到底設置多長的兩難問題。實際上,基于ZooKeeper的鎖是依靠Session(心跳)來維持鎖的持有狀態的,而Redis不支持Session。
基于ZooKeeper的鎖支持在獲取鎖失敗之后等待鎖重新釋放的事件。這讓客戶端對鎖的使用更加靈活。
總結
綜上所述,我們可以得出兩種結論:
如果僅是為了效率(efficiency),那么你可以自己選擇你喜歡的一種分布式鎖的實現。當然,你需要清楚地知道它在安全性上有哪些不足,以及它會帶來什么后果,這也是為什么我們需要了解實現原理的原因,大多數情況下不會出問題,但是就萬一的情況,處理起來可能需要大量的時間定位問題。
如果你是為了正確性(correctness),那么請慎之又慎。就目前來說ZooKeeper的分布鎖相對于redlock更加合理。
最后,由于redlock的出現其實是為了保證分布式鎖的可靠性,但是由于實現的種種問題其可靠性并沒有ZooKeeper分布式鎖來的高,對于可容錯的希望效率的場景下,redis分布式鎖又可以完全滿足,這也是導致了redlock被棄用的原因。
-
JAVA
+關注
關注
19文章
2958瀏覽量
104553 -
機器
+關注
關注
0文章
779瀏覽量
40687 -
Redis
+關注
關注
0文章
371瀏覽量
10846
原文標題:Redis分布式鎖真的安全嗎?
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用Redis作為分布式鎖的詳細方案
如何使用注解實現redis分布式鎖!





 工商網監
工商網監
評論