 現代化的數據管理平臺的性能
現代化的數據管理平臺的性能
今年9月8日,愛數AnyBackup神盾會(七)上首次劇透了AnyBackup Family 8,并正式亮相了AnyBackup Family 8的核心技術架構——備份數據湖。
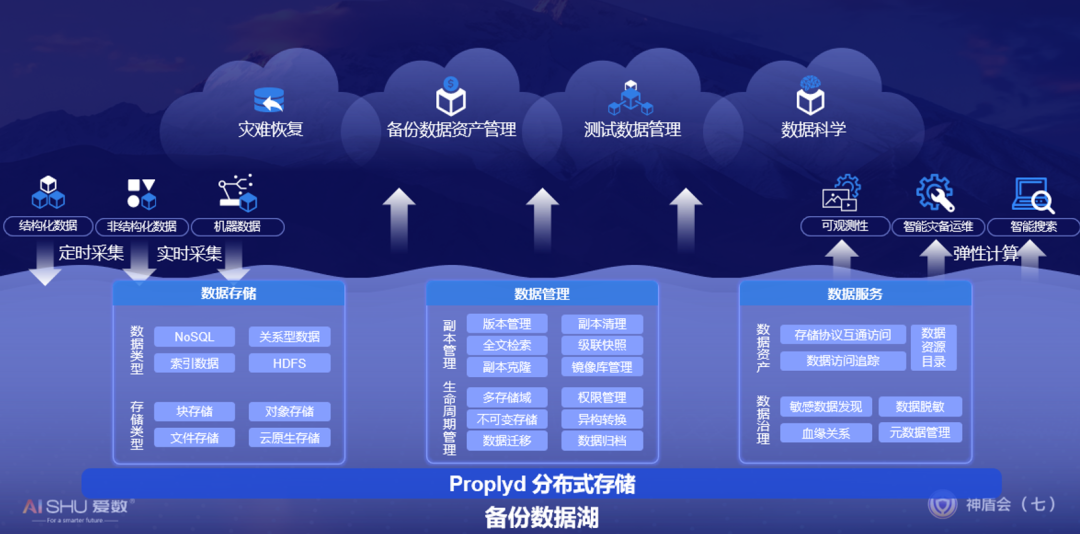
備份數據湖的概念不難理解,類似國外提到的第二存儲理念,即把備份系統和數據湖系統合二為一。備份數據湖提供數據存儲、數據管理和數據服務三大能力,除了支撐傳統的災難恢復、備份數據資產管理類應用外,還支持測試數據管理和數據科學類應用,有效降低企業在數據管理方面的TCO,提高企業數據的利用率,充分挖掘企業數據的價值。
但是,AnyBackup Family 8如此龐大和復雜的系統,功能已經完全超越了傳統備份,對性能的要求也必須與時俱進,否則上面的理念都變為空談。比如你從上面拉起一個數據庫副本進行開發測試,性能比生產系統慢非常多,會大大影響企業的開發速度,造成人力的極大浪費,這樣的備份數據湖也就沒有什么實用價值。
愛數也了解大家的困惑,因此在10月27日下午,舉辦了以“性能爆表”為主題的神盾會(八),延續上一次神盾會,繼續對神秘的AnyBackup Family 8進行劇透,展示AnyBackup Family 8領先技術的性能表現。
整體的會議內容很充實,從現代化數據管理平臺“性能觀”的思想碰撞,到火力全開、性能爆表的炸裂表現,再到超能打領先技術分享,非常值得一看。
西瓜哥作為多年存儲從業人員,可謂閱存儲無數,還是發現這個神盾會有很多技術干貨,對專業的存儲人士來說也非常有啟發,因此,這次我就來解讀一下其中的技術干貨。
愛數的“性能觀”
愛數認為,現代化的數據管理平臺的性能是一個綜合的指標,和相關的生產系統、傳輸網絡都密切相關。
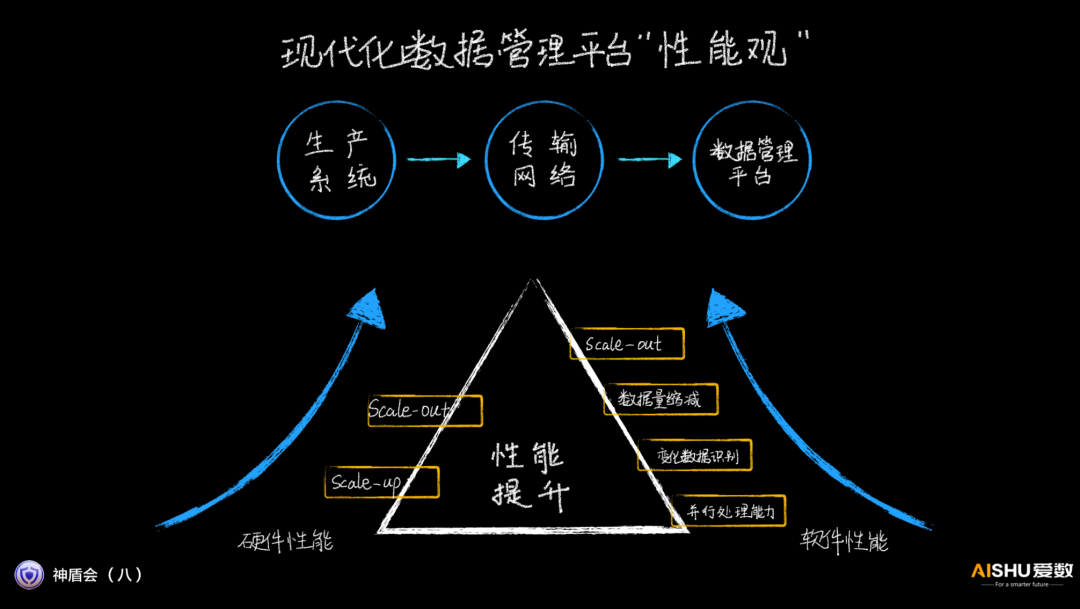
而性能的提升,也需要從硬件和軟件兩個方面努力。這次的會議,主要聚焦在AnyBackup Family 8在軟件scale-out能力提升方面。
總體思路:和應用集成設計
首先,愛數認為,備份軟件+分布式存儲≠分布式備份系統。
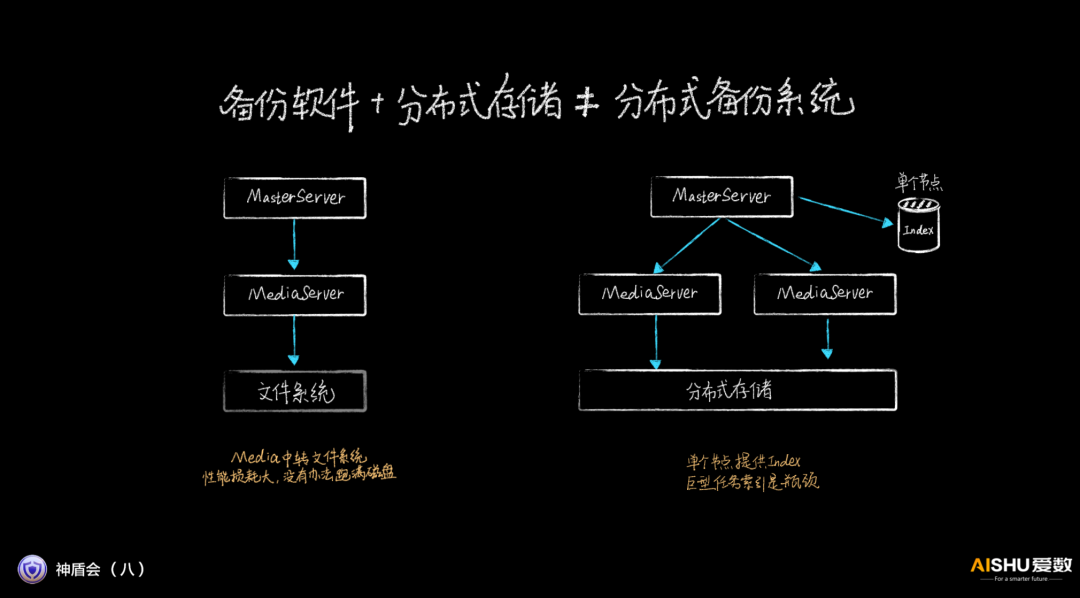
這個其實不難理解,因為備份系統本身沒有分布式化,很多部件都不是分布式設計的。比如Media不能跨節點,單個節點依然是性能瓶頸;Media中轉文件系統,性能損耗大,無法跑滿磁盤帶寬;單個節點提供Index,巨型應用索引是瓶頸。
因此,AnyBackup Family 8把備份系統和分布式存儲集成在一起設計,是一種集成系統的思路。AnyBackup Family 8通過三副本的存儲池、NVMe分布式緩存、兼具快照系統和各類數據結構化服務的數據引擎服務、高性能客戶端和協議網關,構建的分布式存儲架構,全力打造超高性能,即使在海量數據場景下,依然表現優異。
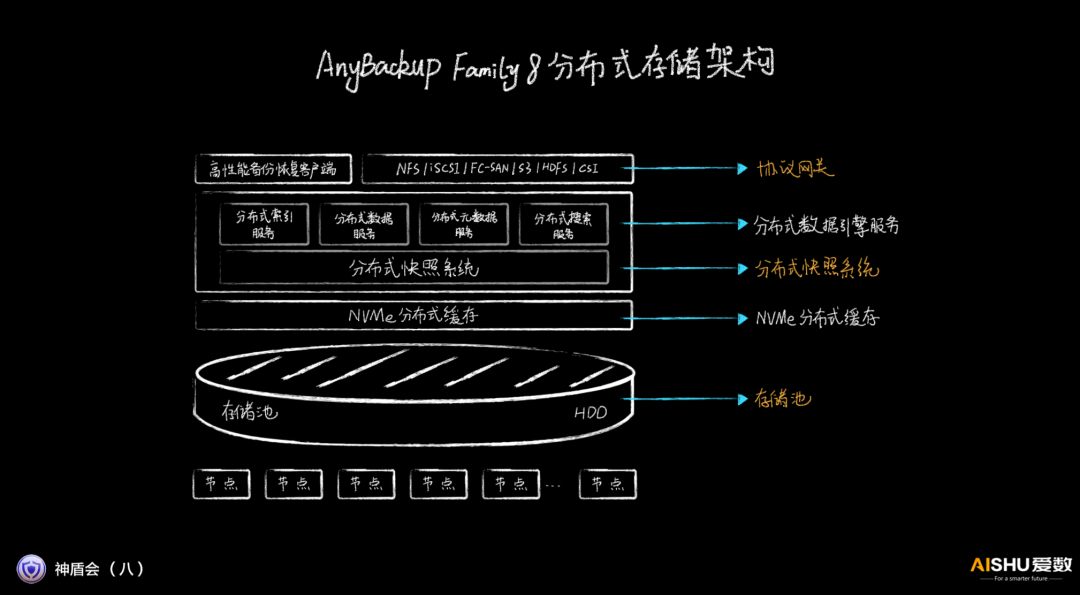
和業界的通用存儲不同,AnyBackup Family 8特別清楚自己的定位,其優化思路和ORACLE數據庫一體機類似,讓存儲在特定的應用場景下性能最優。
存儲池采用三副本,而不是EC(糾刪碼)。這種做法類似Nutanix等很多超融合廠商,采用三副本,可以讓應用直接感知副本的存儲位置,能夠大大提升數據的存取速度。
協議網關除了支撐通用的存儲協議,還支持專用的備份恢復客戶端。這種做法類似很多高性能文件系統,通過專用客戶端來提升單客戶端的性能。
在備份系統的分布式化上,愛數采用全分布式的設計思路。分布式索引服務、分布式數據服務、分布式元數據服務、分布式搜索服務,再加上底層分布式快照服務,可以提供無限快照能力,讓所有可能成為性能瓶頸的部件全部都支持scale-out線性擴展,從架構上徹底解決性能問題。
下面我們來展開看看,AnyBackup Family 8的幾個性能提升設計思路。
索引拆分和分布式化
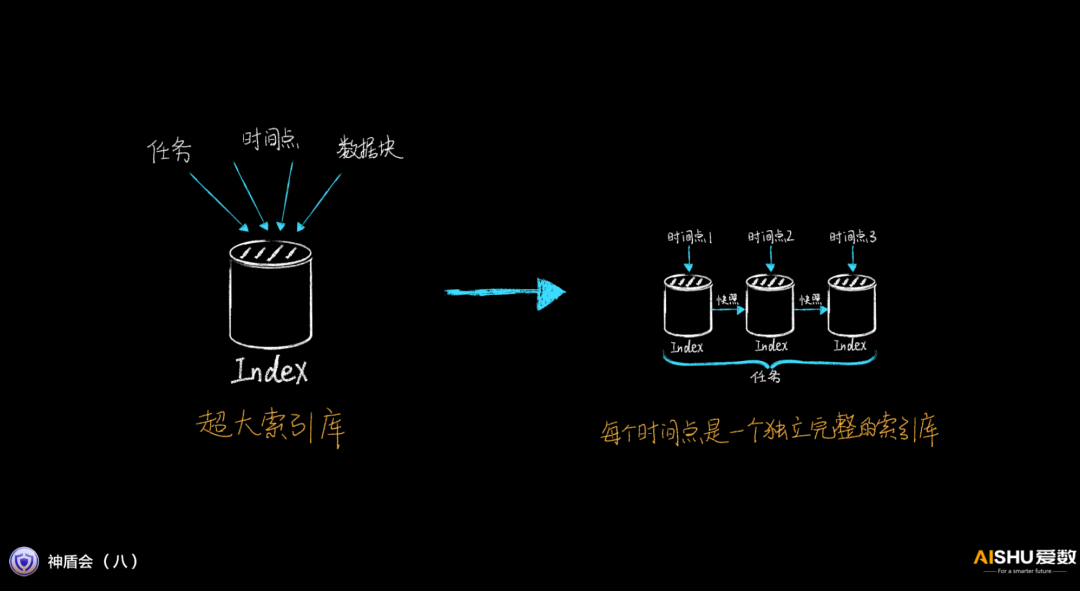
愛數第一件事就是在索引庫引入快照機制,每次增量備份完成就做一個快照,全量備份就產生一個新的索引。這樣做的好處就是每個時間點都有一個獨立完整的索引庫,每個索引庫都不大,后期的數據管理動作,存取該索引庫的速度就快得多。
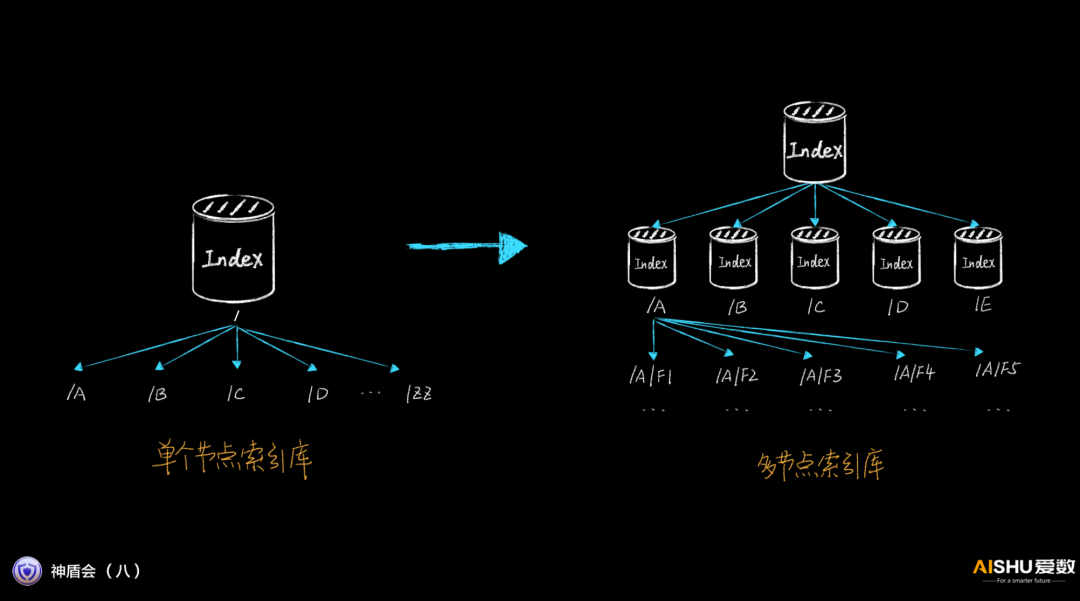
第二件事就是對單個節點索引庫進行拆分,變成多節點索引庫的架構,實現索引性能按需線性增長。拆分的策略有很多,按照應用數據源的不同,可以均衡負載,就近負載。
讀寫流程簡化,減少網絡傳輸
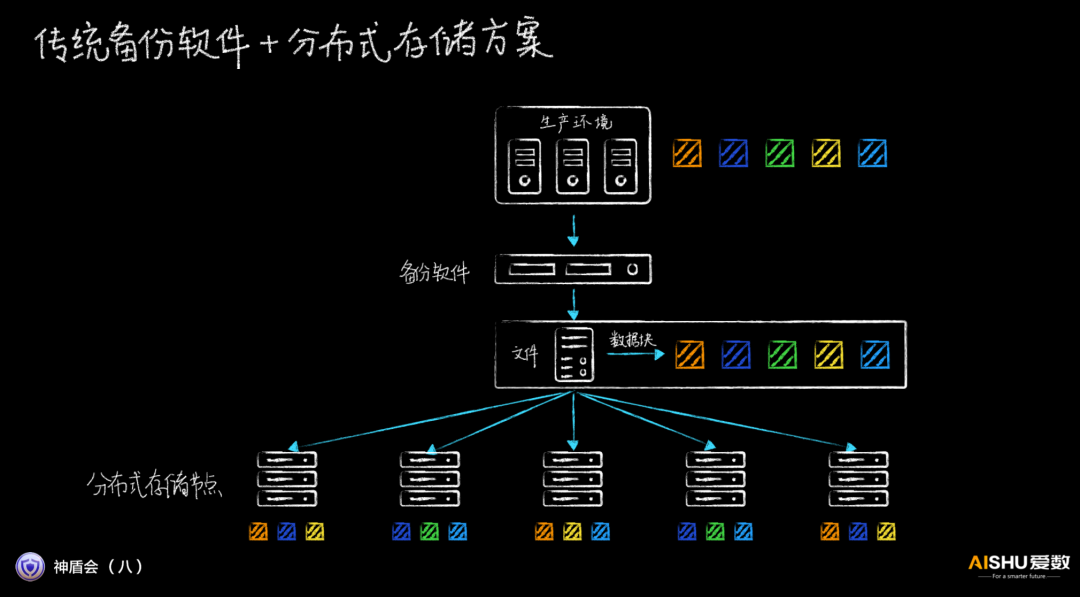
備份軟件+分布式存儲的松耦合設計,由于備份軟件無法感知底層分布式存儲的存放位置,因此,數據需要先送到備份系統,然后備份系統再送到底層分布式存儲系統,分布式存儲再找具體節點落盤,中轉太多。
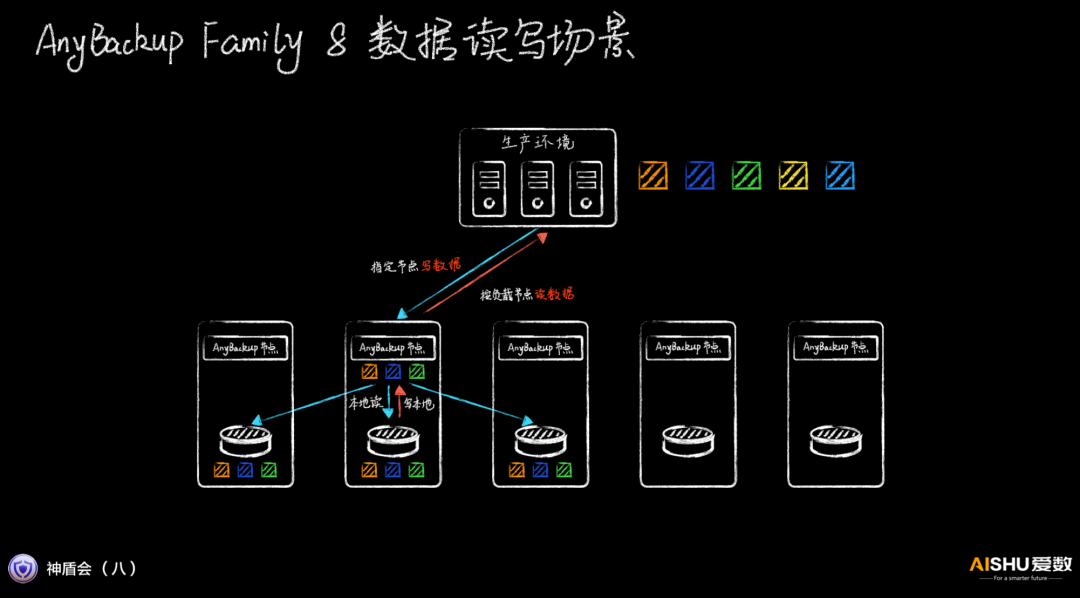
而AnyBackup Family 8則另辟蹊徑,把AnyBackup節點和存儲節點集成設計,備份客戶端按照策略,直接把備份數據寫入指定節點(比如負載最輕的),該節點再復制到其他兩個節點。這樣做的好處就是減少了一次網絡轉發,寫性能會大大提高。由于恢復客戶端也能感知到副本的位置,可以直接讀取負載最輕的某個副本,恢復性能也會大大提高。
由于備份系統可以控制數據具體的存儲位置,相關的數據可以盡量放在一起,減少跨節點的傳輸。不相關的數據則可以跨節點并發讀寫,整體的集群的性能要比備份軟件+分布式存儲的松耦合情況要高出很多。唯一的問題是集群的容量可能出現不均衡,可以通過自動重平衡閑時進行處理。

專用客戶端,實現直通掛載
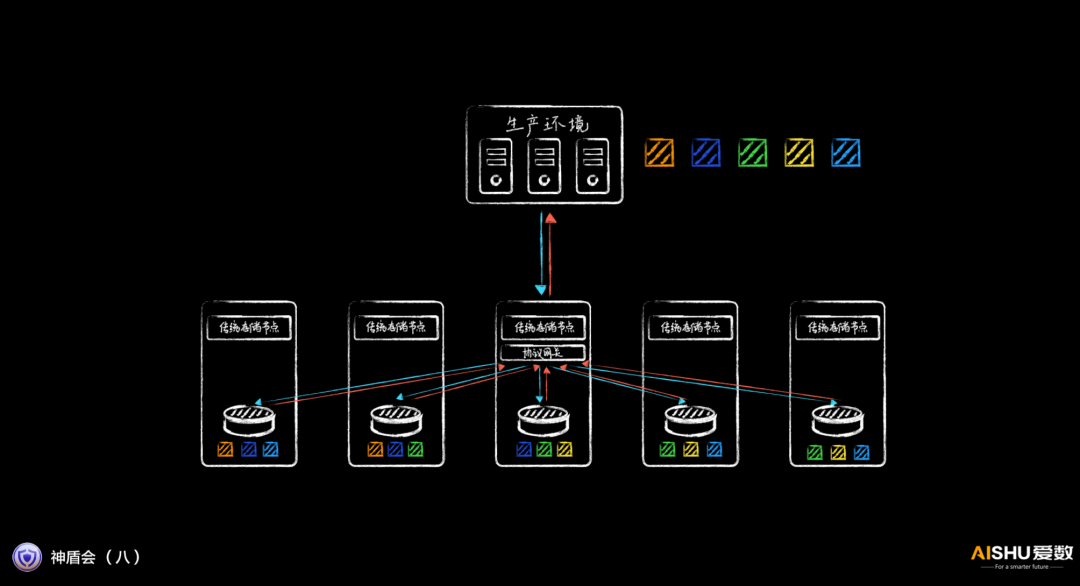
如果采用通用的存儲協議,掛載一般需要通過特定協議網關,該網關再去其他節點取數據,性能較差。
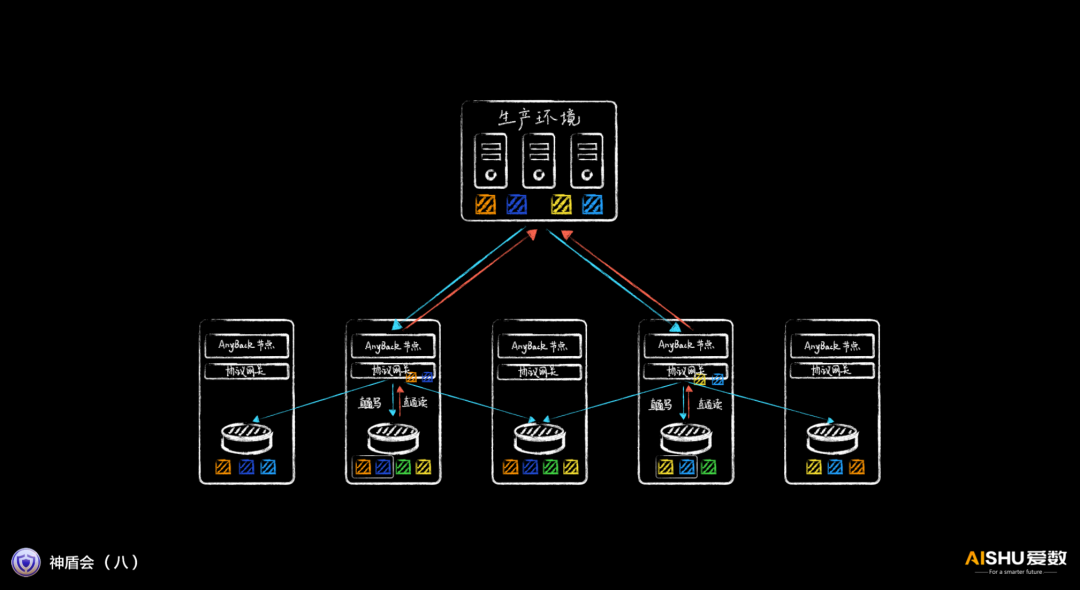
由于AnyBackup Family 8采用專門的備份恢復客戶端,可以感知數據的存放位置,因此可以直接定位到數據所在節點的協議網關,實現直通掛載,時延更低,IOPS更高。
這種高速掛載的能力,讓備份數據湖快速提供開發測試環境,快速提供分析應用所需的數據成為功能。
無合成永久增量備份
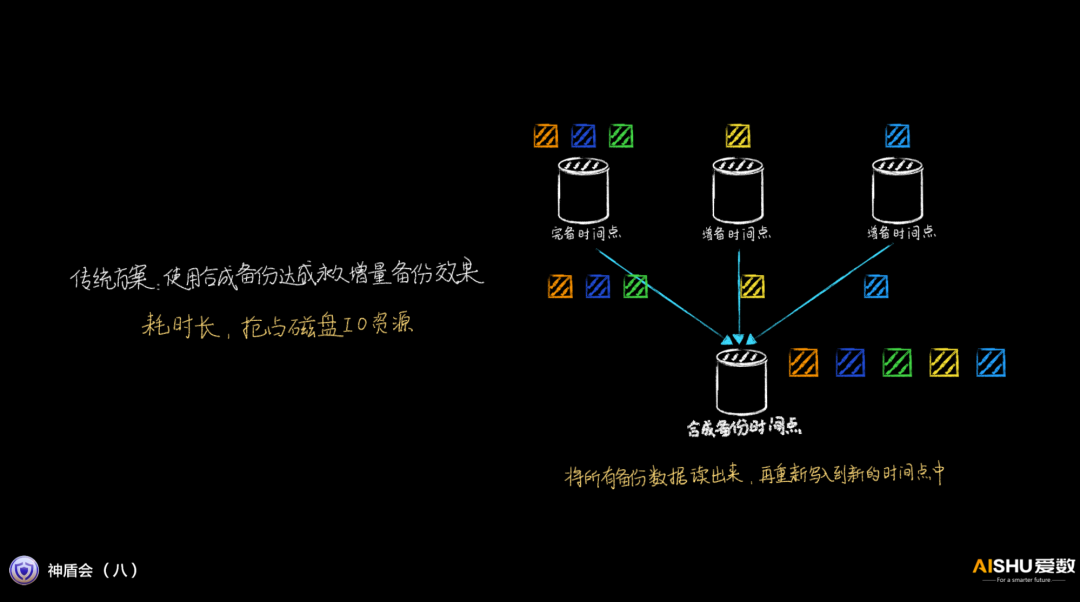
傳統的增量備份,需要在后臺進行數據的合成,對系統的性能影響很大。
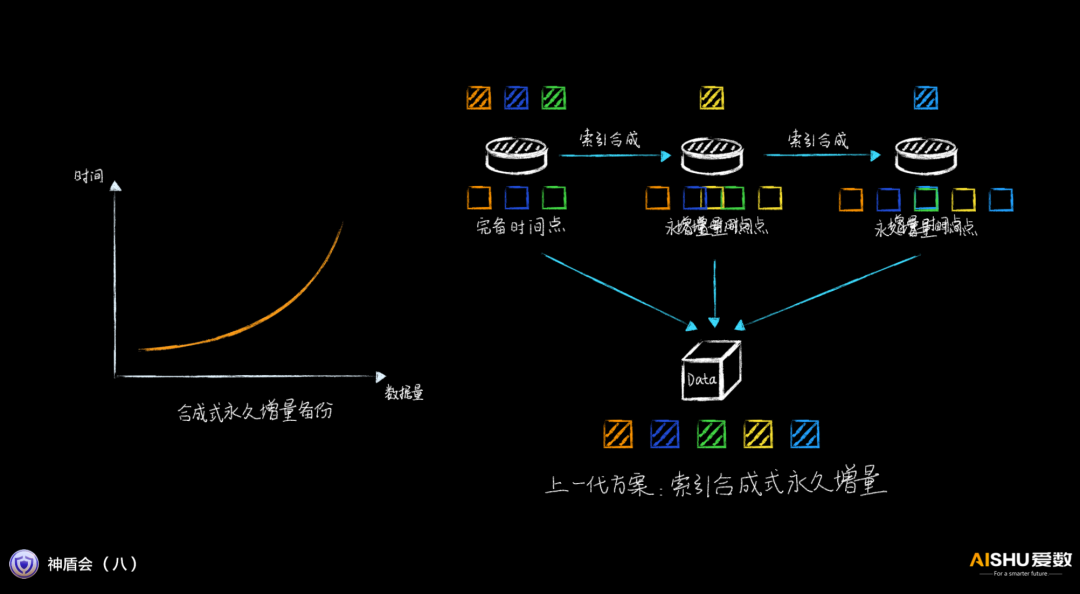
愛數的上一代產品,采用索引合并的方式,性能有所提升,但當索引的數據量上升,耗時還是很長的。
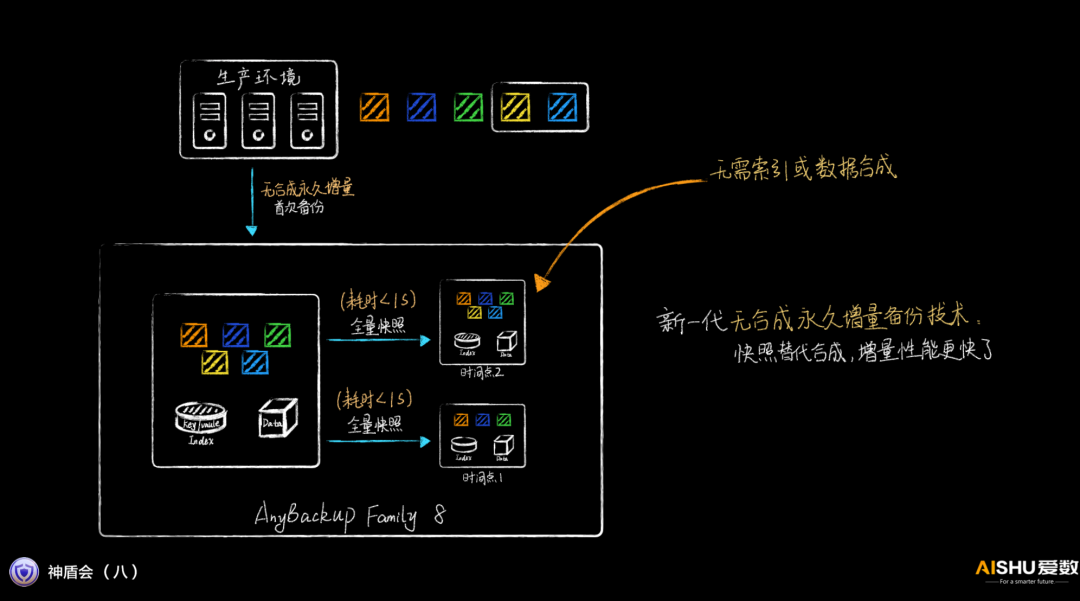
而在AnyBackup Family 8里,愛數取消了后臺合成的過程,在增量備份的時候,實時修改索引,然后利用全量快照就可以生成黃金副本,無需后臺合成過程,增量備份的性能得到巨大的提升。
無索引文件提高掛載速度
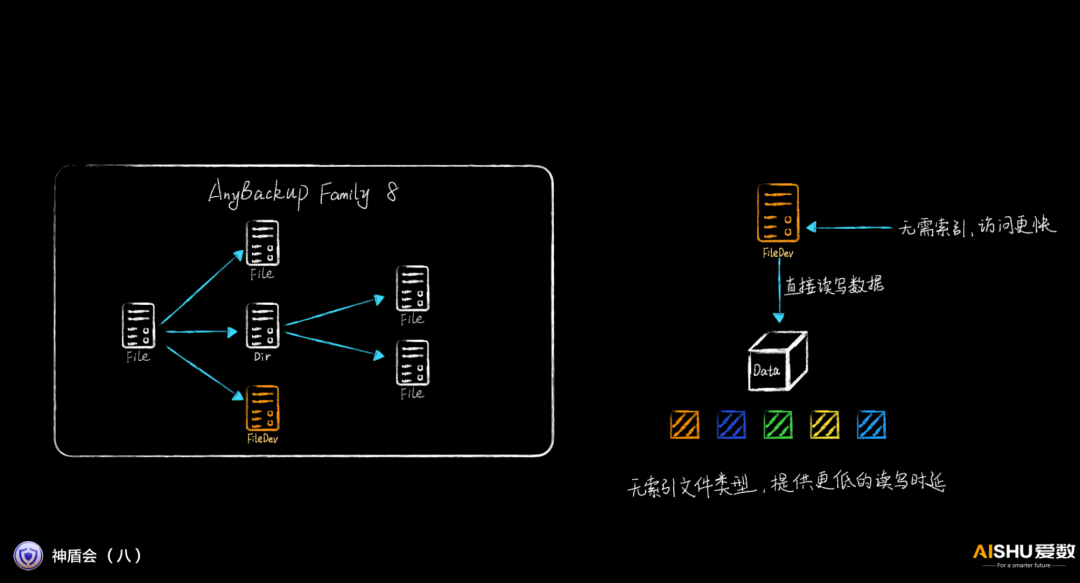
通用的文件系統,需要訪問索引,然后才能訪問到數據,因此其性能一般來說不如塊設備。AnyBackup Family 8引入一種新的文件類型FileDev,沒有索引,節省了查詢索引的過程,直接訪問數據,性能更好。
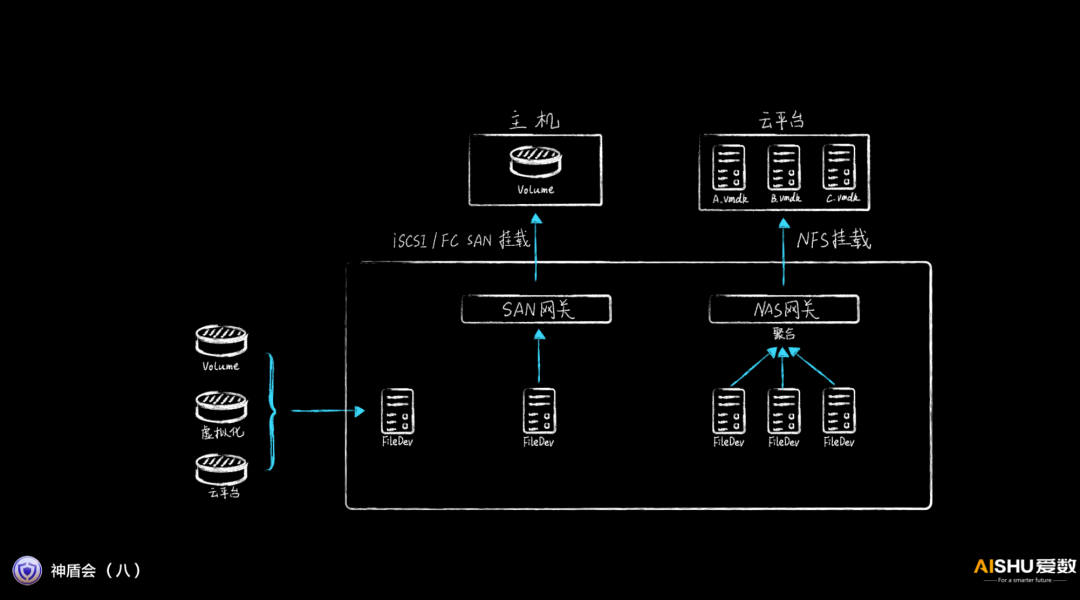
這些無索引文件FileDev,其實就是一種VMDK文件,它可以通過iSCSI掛載,也可以通過NFS進行聚合掛載,可以實現即時的數據服務。
性能爆表
正是上面的性能優化技術,將AnyBackup Family 8的3節點的備份恢復吞吐直接提升至5.1GB/s和9.21GB/s。
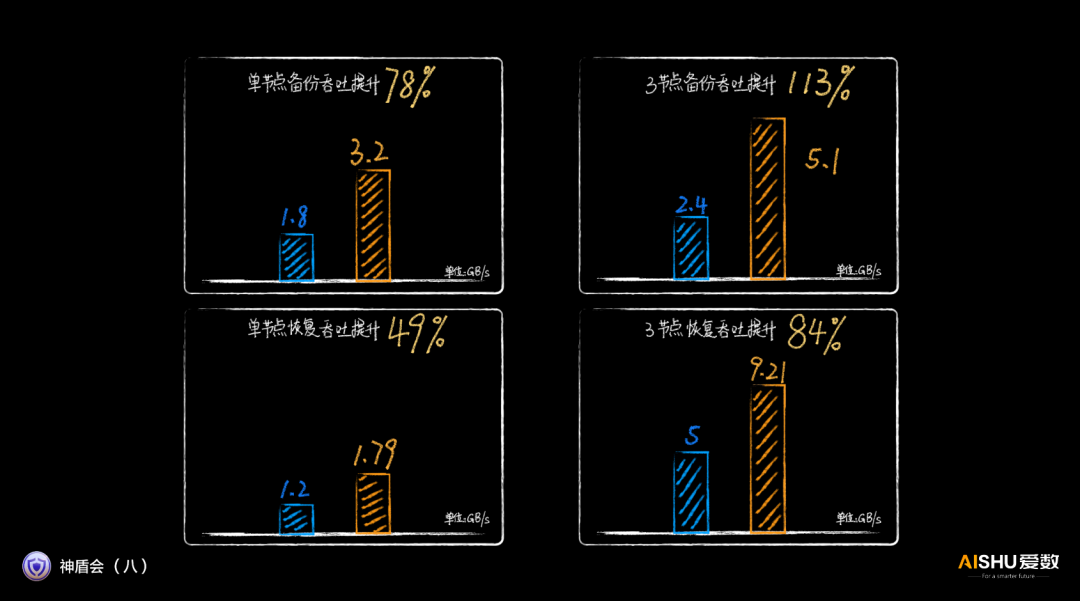
根據愛數發布的數據,相比上一代產品,AnyBackup Family 8在各方面的性能提升基本都在50%以上。
神盾會上,愛數還展示了AnyBackup Family 8在百億級小文件保護、百TB級數據庫分鐘級掛載、海量虛擬機保護、PB級數據倉庫高效備份、大規模測試數據管理等數據管理場景下的性能數據,顯示其備份數據湖的卓越性能。
小結
從上面的分析,我們看到,愛數并沒有把AnyBackup Family 8備份數據湖底層的分布式存儲做成通用的存儲,來和其他廠商的軟件定義存儲產品競爭。而是采用集成系統的思路,把數據管理應用和分布式存儲進行緊耦合的設計,讓整體數據管理平臺的性能不僅能夠進行快速的備份和恢復,也能進行高速的掛載,提供接近生產系統的高性能的數據服務,真正發揮備份數據湖的價值。
愛數的很多的性能優化思路,在業界都是獨創的,如無合成的永久增量備份等,值得其他做第二存儲的公司借鑒。當然,需要了解更多的細節,還是建議大家回看愛數的神盾會(八)。
-
存儲
+關注
關注
13文章
4263瀏覽量
85675 -
軟件
+關注
關注
69文章
4778瀏覽量
87163 -
數據管理
+關注
關注
1文章
290瀏覽量
19609
原文標題:不走尋常路,打造現代化數據管理平臺的性能爆表之路
文章出處:【微信號:High-end_Storage,微信公眾號:高端存儲知識】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

[原創]逐漸智能現代化公安裝備
基于RFID的現代化奶牛場管理應用
【學習打卡】OpenHarmony的分布式數據管理介紹
Quest :數據倉庫現代化
數據管理駕駛艙(工業數據可視化平臺)是什么?有什么功能?
喜報丨軟通動力應用現代化平臺工程產品及服務解決方案榮獲“2023年應用現代化典型案例”稱號

軟通動力應用現代化平臺工程產品及服務解決方案榮獲“2023年應用現代化典型案例”稱號






 工商網監
工商網監
評論