 一種無晶體管的內存計算架構的原理和器件物理特性
一種無晶體管的內存計算架構的原理和器件物理特性
為了推進人工智能,賓夕法尼亞大學的研究人員最近開發了一種新的內存計算 (CIM) 架構,用于數據密集型計算。CIM 在大數據應用方面具有諸多優勢,UPenn 集團在生產小型、強大的 CIM 電路方面邁出了第一步。
在本文中,我們將深入研究 CIM 的原理和支持研究人員無晶體管 CIM 架構的器件物理特性。
為什么要在內存中計算?
傳統上,計算主要依賴于基于馮諾依曼架構的互連設備。在此架構的簡化版本中,存在三個計算構建塊:內存、輸入/輸出 (I/O) 接口和中央處理單元 (CPU)。
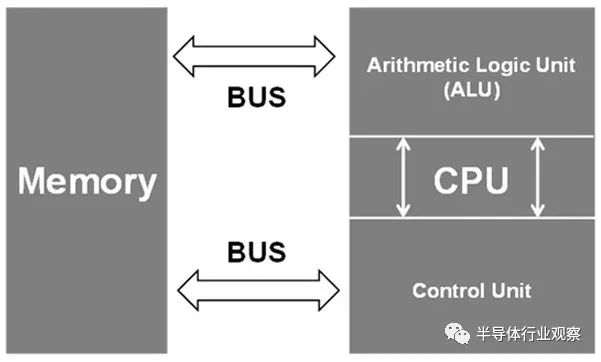
每個構建塊都可以根據 CPU 給出的指令與其他構建塊交互。然而,隨著 CPU 速度的提高,內存訪問速度會大大降低整個系統的性能。這在需要大量數據的人工智能等數據密集型用例中更為復雜。此外,如果內存未與處理器位于同一位置,則基本光速限制會進一步降低性能。
所有這些問題都可以通過 CIM 系統來解決。在 CIM 系統中,內存塊和處理器之間的距離大大縮短,內存傳輸速度可能會更高,從而可以更快地計算。
氮化鈧鋁(Aluminum Scandium Nitride):內置高效內存
UPenn 的 CIM 系統利用氮化鈧鋁(AlScN) 的獨特材料特性來生產小型高效的內存塊。AlScN 是一種鐵電材料,這意味著它可能會響應外部電場而變得電極化。通過改變施加的電場超過某個閾值,鐵電二極管 (FeD) 可以被編程為低電阻或高電阻狀態(分別為 LRS 或 HRS)。
除了作為存儲單元的可操作性之外,AlScN 還可用于創建沒有晶體管的三元內容可尋址存儲 (TCAM) 單元。TCAM 單元對于大數據應用程序極為重要,因為使用馮諾依曼架構搜索數據可能非常耗時。使用 LRS 和 HRS 狀態的組合,研究人員實現了一個有效的三態并聯,所有這些都沒有使用晶體管。
使用無晶體管 CIM 陣列的神經網絡
為了展示 AlScN 執行 CIM 操作的能力,UPenn 小組開發了一個使用 FeD 陣列的卷積神經網絡 (CNN)。該陣列通過對輸入電壓產生的輸出電流求和來有效地完成矩陣乘法。權重矩陣(即輸出電流和輸入電壓之間的關系)可以通過修改cell的電導率來調整到離散水平。這種調諧是通過偏置 AlScN 薄膜以表現出所需的電導來實現的。
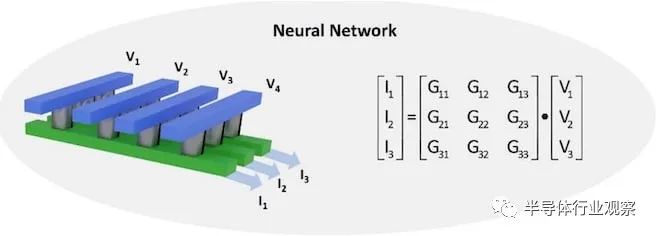
AlScN CNN 僅使用 4 位電導率分辨率就成功地從MNIST 數據集中識別出手寫數字,與 32 位浮點軟件相比,降級約為 2%。此外,沒有晶體管使架構簡單且可擴展,使其成為未來需要高性能矩陣代數的人工智能應用的優秀計算技術。
打破馮諾依曼瓶頸
在其存在的大部分時間里,人工智能計算主要是一個軟件領域。然而,隨著問題變得更加數據密集,馮諾依曼瓶頸對系統有效計算的能力產生了更深的影響,使得非常規架構變得更有價值。
基于 AlScN FeD 的模擬 CIM 系統消除了訓練和評估神經網絡延遲的主要原因,使它們更容易在現場部署。與現有硅硬件集成的 AlScN 設備的多功能性可能會為將 AI 集成到更多領域提供開創性的方法。
原文:重新思考人工智能時代的計算機芯片
人工智能對傳統計算架構提出了重大挑戰。在標準模型中,內存存儲和計算發生在機器的不同部分,數據必須從其存儲區域移動到 CPU 或 GPU 進行處理。
這種設計的問題是移動需要時間,太多時間。你可以擁有市場上最強大的處理單元,但它的性能將受到限制,因為它會等待數據,這個問題被稱為“內存墻”或“瓶頸”。
當計算性能優于內存傳輸時,延遲是不可避免的。在處理機器學習和人工智能應用程序所必需的大量數據時,這些延遲成為嚴重的問題。
隨著人工智能軟件的不斷發展,傳感器密集型物聯網的興起產生了越來越大的數據集,研究人員已將注意力集中在硬件重新設計上,以在速度、敏捷性和能源使用方面提供所需的改進。
賓夕法尼亞大學工程與應用科學學院的一組研究人員與桑迪亞國家實驗室和布魯克海文國家實驗室的科學家合作,推出了一種非常適合人工智能的計算架構。
該項目由電氣與系統工程 (ESE) 系助理教授Deep Jariwala 、ESE副教授Troy Olsson和博士劉希文共同領導。作為 Jarawala設備研究和工程實驗室的候選人,該研究小組依靠一種稱為內存計算 (CIM) 的方法。
在 CIM 架構中,處理和存儲發生在同一個地方,從而消除了傳輸時間并最大限度地減少了能源消耗。該團隊的新 CIM 設計是最近發表在Nano Letters上的一項研究的主題,以完全無晶體管而著稱。這種設計獨特地適應了大數據應用程序改變計算性質的方式。
“即使在內存計算架構中使用,晶體管也會影響數據的訪問時間,”Jariwala 說。“它們需要在芯片的整個電路中進行大量布線,因此使用的時間、空間和能量超出了我們對人工智能應用的期望。我們無晶體管設計的美妙之處在于它簡單、小巧、快速,并且只需要很少的能量。”
該架構的進步不僅體現在電路級設計。這種新的計算架構建立在該團隊早期在材料科學方面的工作之上,該工作專注于一種稱為鈧合金氮化鋁 (AlScN) 的半導體。AlScN 允許鐵電開關,其物理特性比替代的非易失性存儲元件更快、更節能。
“這種材料的一個關鍵屬性是它可以在足夠低的溫度下沉積以與硅制造廠兼容,”Olsson 說。“大多數鐵電材料需要更高的溫度。AlScN 的特殊性能意味著我們展示的存儲設備可以在垂直異質集成堆棧中的硅層頂部。想想一個可容納一百輛汽車的多層停車場和分布在一個地塊上的一百個獨立停車位之間的區別。哪個在空間方面更有效?像我們這樣高度微型化的芯片中的信息和設備也是如此。這種效率對于需要資源限制的應用程序(例如移動或可穿戴設備)和對能源極其密集的應用程序(例如數據中心)同樣重要。”
2021 年,該團隊確立了 AlScN作為內存計算強國的可行性。它在小型化、低成本、資源效率、易于制造和商業可行性方面的能力在研究和工業界都取得了重大進展。
在最近首次推出無晶體管設計的研究中,該團隊觀察到他們的 CIM 鐵二極管的執行速度可能比傳統計算架構快 100 倍。
該領域的其他研究已成功使用內存計算架構來提高 AI 應用程序的性能。然而,這些解決方案受到限制,無法克服性能和靈活性之間的矛盾權衡。使用憶阻器交叉陣列的計算架構,一種模仿人腦結構以支持神經網絡操作的高級性能的設計,也展示了令人欽佩的速度。
然而,使用多層算法來解釋數據和識別模式的神經網絡操作只是功能性 AI 所需的幾個關鍵數據任務類別之一。該設計的適應性不足以為任何其他 AI 數據操作提供足夠的性能。
Penn 團隊的鐵二極管設計提供了其他內存計算架構所沒有的突破性靈活性。它實現了卓越的準確性,在構成有效 AI 應用程序基礎的三種基本數據操作中表現同樣出色。它支持片上存儲,或容納深度學習所需的海量數據的能力,并行搜索,一種允許精確數據過濾和分析的功能,以及矩陣乘法加速,神經網絡計算的核心過程。
“假設,”Jariwala 說,“你有一個 AI 應用程序,它需要大內存來存儲以及進行模式識別和搜索的能力。想想自動駕駛汽車或自主機器人,它們需要快速準確地響應動態、不可預測的環境。使用傳統架構,您需要為每個功能使用不同的芯片區域,并且您會很快耗盡可用性和空間。我們的鐵二極管設計允許您通過簡單地更改施加電壓的方式對其進行編程,從而在一個地方完成所有工作。”
可以適應多種數據操作的 CIM 芯片的回報是顯而易見的:當團隊通過他們的芯片運行機器學習任務的模擬時,它的執行精度與在傳統 CPU 上運行的基于 AI 的軟件相當。
“這項研究非常重要,因為它證明我們可以依靠內存技術來開發集成多個人工智能數據應用程序的芯片,從而真正挑戰傳統計算技術,”該研究的第一作者劉說。
該團隊的設計方法是考慮到人工智能既不是硬件也不是軟件,而是兩者之間必不可少的協作。
“重要的是要意識到,目前完成的所有人工智能計算都是在幾十年前設計的硅硬件架構上啟用軟件的,”Jariwala 說。“這就是為什么人工智能作為一個領域一直由計算機和軟件工程師主導。從根本上重新設計人工智能硬件將成為半導體和微電子領域的下一個重大變革。我們現在的方向是軟硬件協同設計。”
“我們設計的硬件可以讓軟件更好地工作,”Liu 補充道,“通過這種新架構,我們確保技術不僅快速而且準確。”
審核編輯:郭婷
-
晶體管
+關注
關注
77文章
9641瀏覽量
137876 -
人工智能
+關注
關注
1791文章
46896瀏覽量
237666 -
大數據
+關注
關注
64文章
8864瀏覽量
137310
原文標題:【檔案室】一種無晶體管的內存計算架構
文章出處:【微信號:汽車半導體情報局,微信公眾號:汽車半導體情報局】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
晶體管反相器的原理及應用
雪崩晶體管的定義和工作原理
單結晶體管的工作原理和伏安特性

晶體管處于放大狀態的條件是什么
晶體管電流的關系有哪些類型 晶體管的類型





 工商網監
工商網監
評論