 優化OpenVINO模型效能:參數設定影響實測
優化OpenVINO模型效能:參數設定影響實測
三年前剛接觸OpenVINO的時候,開始感覺機器學習發展的生態似乎有許多的轉變,隨著執行許多范例的過程中,漸漸了解Open Model Zoo的Github支持了許多可以下載的模型,有種感覺是不是模型加載與使用,會變成即插即用的狀態。
以前要自己看許多論文,花時間搜集各種模型的執行方法,今年實驗的模型,過一陣子想再執行時常會忘記如何使用,就算記得但碰到模型本身運作環境升級,或者平臺不再支持某個方法,辛苦弄完的模型跟寫好的程序又要重新再來一次,這樣的感覺在接觸OpenVINO之前,會覺的似乎是做機器學習的無奈與必然。
接觸OpenVINO后,讓人感覺是一個有趣的環境,過去在教學現場很難與學生介紹機器學習要怎么學跟用,雖然有云端的架構可以直接運作準備好的教學環境,實際現場要使用時,還是會碰到不知道如何安裝跟配置的問題。
雖然一般的安裝文件嘗試盡可能寫清楚了,但其實許多操作系統環境差異,或開發工具包兼容性的狀態,常會造成這個月可以執行的模型跟架構,過幾個月又開始不太支持,還好這兩年容器環境相對更成熟,系統安裝的生態也開始發生轉變,透過容器化技術許多套件安裝的流程跟問題,也隨著容器化技術得到緩解。
本文嘗試從兩個觀點出發,第一個是如何能夠較為方便快速使用OpenVINO,主要的目的是介紹容器化的方式使用OpenVINO,相對過去需要閱讀大量安裝文件,目前已經有較為成熟穩定的容器化環境可以直接安裝與啟動OpenVINO。
第二個是了解如何利用OpenVINO跟Open Model Zoo所提供訓練好的模型,在運作OpenVINO的過程,透過不同參數設定值,觀察系統預測效率的改變,對于機器學習運作環境,除了程序設計技巧與架構整合外,累積模型運作與不同參數設定狀態下需要具備的觀念。
相對于操作系統調校的觀念,在OpenVINO運作時可以觀察系統在模型運作時預測效能的變化,這個部份可做為后續使用模型時經驗的提升,在機器運作時累積更好的模型使用經驗,觀察同一臺機器運作OpenVINO時,可以思考與注意的部份。
透過容器化技術快速部署OpenVINO運作環境
透過容器啟動OpenVINO,可以快速方便的達成OpenVINO上線狀態,相對省下非常多套件安裝過程的時間,過去常認為要執行機器學習推論的環境會很復雜,或者需要許多步驟的執行過程。透過Docker容器的架構來執行OpenVINO,可以將過去系統在操作系統不同版本間運作環境產生問題的數量降低,大量減少系統除錯、兼容性測試與環境安裝配置的問題與步驟。
本文使用的運作環境是Ubutnu20.04.2 LTS,OpenVINO的docker容器是openvino/ubuntu20_data_dev:2021.4_tgl,使用docker在Linux運作OpenVINO最大的好處是幾乎沒有兼容性的問題,下載之后就可以直接執行,對于要直接使用或學習OpenVINO,相對過去容易非常非常多,透過下面的指令就可以執行OpenVINO的容器環境。
如果機器上面沒有docker的環境,要先安裝docker容器環境,在Linux上面執行以下指令,前面的指令會先把原來的docker環境移除,如果你已經安裝過docker環境,可以跳過這個步驟,直接執行下載OpenVINO docker的pull指令:
sudo aptupdate
sudoapt-get remove docker docker-engine docker.io containerd runc
sudo aptinstall curl
curl-fsSL https://get.docker.com -o get-docker.sh
sudo shget-docker.sh
sudousermod -aG docker $USER
## Needto logout or reboot to run docker as non-root user
dockerrun hello-world
上面安裝好docker的容器環境以后,可以用底下的指令直接下載OpenVINO的docker環境。
dockerpull openvino/ubuntu20_data_dev:2021.4_tgl
要執行docker環境的時候,如果是使用ubuntu桌面版內建的vnc環境,可以使用底下的指令來啟動OpenVINO docker環境,這樣之后在docker環境內如果需要使用到窗口環境,會比較方便做后續的測試。
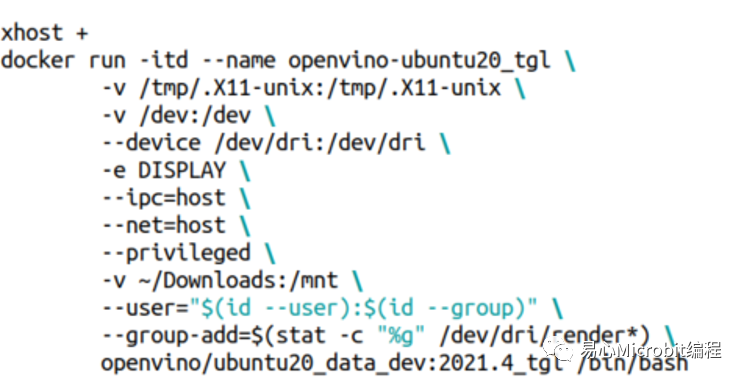
要進入docker環境下命令測試OpenVINO時,可以使用底下的指令,就可以順利的在ubuntu桌面環境下同時使用多個OpenVINO docker環境終端做測試。
dockerexec -it openvino-ubuntu20_tgl /bin/bash
參數設定在模型運作時效能的變化
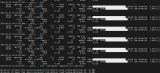
OpenVINO效能量測工具名稱為benchmark_app,可以在機器上量測模型的執行效能,OpenVINO 2021.4的benchmark_app提供許多參數設定,另一個思考方向是自己寫程序加載模型時,實際的效能是如何,或者日后如何能在自己寫的程序達到測試環境相同的效能,如常用的ssd模型在執行object model zoo的范例時,運作過程中可以設定許多參數,例如nireq、nthreads、nstreams等,device參數可以設定運作的硬件環境CPU、GPU、同時使用CPU與GPU的MULTI: CPU,GPU等,令人好奇這些參數之間實際運作的情況,在運作過程中要如何設定,或者朝哪個方向去思考調整會有相對較好的執行結果。
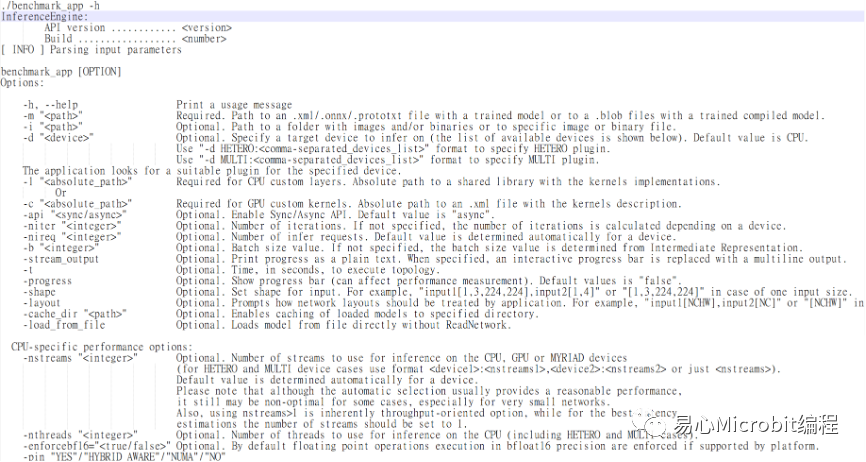
圖1 – OpenVINO效能評估程序benchmark_app提供的部份參數
benchmark_app提供許多參數進行效能量測,相對當執行范例程序時,nireq、nthreads這樣的參數做調整,會觀察到什么結果,以下說明一些紀錄與觀察過程,同時可以更了解OpenVINO在docker環境下執行的方式。
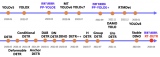
在docker環境中包含OpenVINO2021.4.582的執行版本,并且提供許多模型運作范例,在Open Model Zoo中內含Object_sample_ssd的范例,內含models.lst檔案。表1為models.lst檔案里面支持部份的ssd模型列表,跟過去版本最大差異是多了-at參數設定,在models.lst中說明各種模型對應-at參數的設定值。
使用模型的時候可以使用download.py下載模型,如果下載的不是OpenVINO的IR格式(附檔名為.xml與.bin),需要透過convert.py轉換成OpenVINO的IR格式。
OpenVINO系統目錄內定會安裝在/opt/intel/openvino,內含子目錄deployment_tools/open_model_zoo/demos/object_detection_demo/python,此目錄主要為對象偵測的python范例程序,可以執行許多機器學習開發架構已經訓練好的模型,包含 centernet、ctpn、faceboxes、ssd、yolo、yolov4等機器學習框架所訓練好的對象偵測模型。
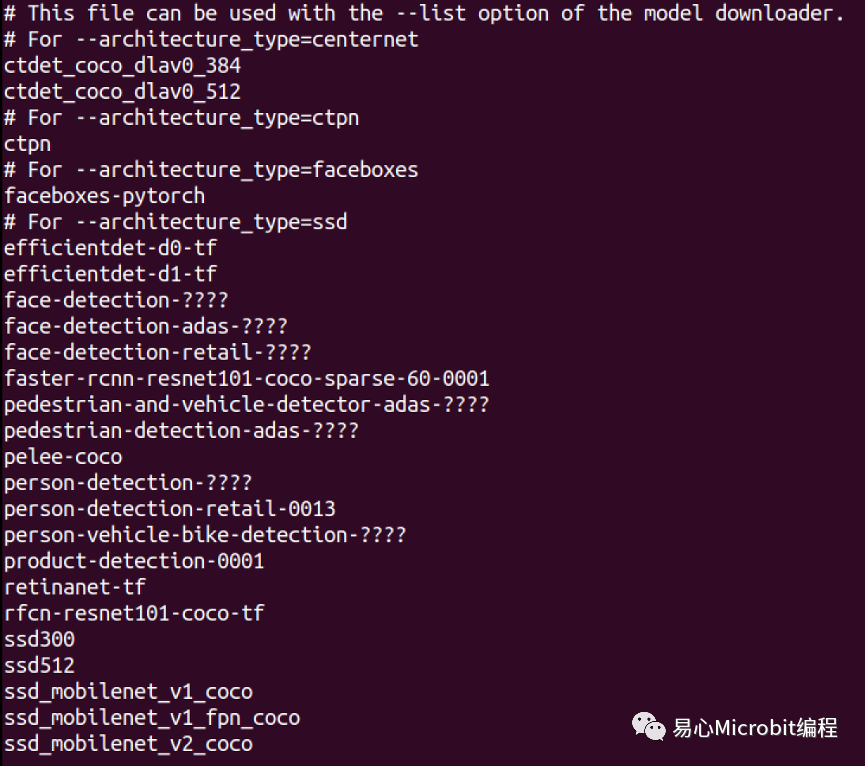
表1 – OpenVINOobject_detection_demo可以執行的機器學習模型
參數與預測效能之間的觀察
兩年前剛學習使用OpenVINO的時候,有很多時候覺得模型會動就好了,但是有些時候希望效能能夠變快一點,嘗試把某些參數調大,但是又感覺好像不是這樣,本文透過object_detecion_demo運作觀察,參數設定過程如何影響模型在同一臺機器上推論效率的變化,接下來的內容為觀察到的現象,可以作為日后模型推論在配置時參數設定的一些參考。
這兩年間比較有趣的變化是同一個模型有FP32、FP16、FP16-INT8的版本可以選擇,因此同一個模型在內存空間的使用量、運作效能以及預測的精確度,有許多部份可進一步觀察運作過程中的變化。
本文針對object_detection_demo.py指令的參數,在執行person-detection-retail-0013模型中進行效能量測,分別就FP32、FP16、FP16-INT8等模型格式,在CPU、GPU、CPU+GPU的硬件條件下,分別進行不同的nireq以及nthreads參數設定,觀察FPS(Frame per second)變化情形進行描述與討論。
要注意的是本文所使用的是M.2 Key MSSD硬盤作為結果輸出裝置,用一般的USB隨身碟作為預測檔案結果輸出時,會影響檔案輸出的效能,進而影響效能觀察的結果。
在本文效能量測的結果呈現前,要注意的是FP16-INT8模型的運作方式,OpenVINO中POT套件轉換FP16模型為INT8模型的方式,是經由在FP16模型各層間插入INT8格式的FakeQuantize,對于設定不同的POT模型優化參數, FakeQuantize將會自動調整的INT8的模型數值,或刪除一些不需要的模型計算步驟,在可以滿足精度要求的狀態下,達成模型運作時真正的轉換為INT8低精度模型,雖然層數相對可能會增加,但是因為INT8所需空間較小且執行效能相對快很多,因而能夠獲得真正的模型空間縮小與效能提升。
因此在FP16-INT8模型的運作過程中,透過了FP16與INT8整數運算于不同層之間的切換的運算過程,如果許多的FP16層級被轉換為INT8,有機會得到儲存空間的較小模型及較快速指令周期的推論效能。同時INT8的運算過程于i7第11代CPU中因為支持了AVX512的指令集,以及i7第11代所使用的內顯GPU支持INT8運算處理,因此在本文量測的結果中FP16-INT8的效能將大幅度相對提升s。
object_detection_demo.py程序執行的參數如下:
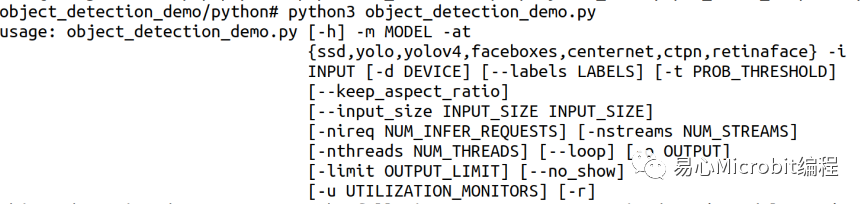
指令執行的參數常用的范例如下:
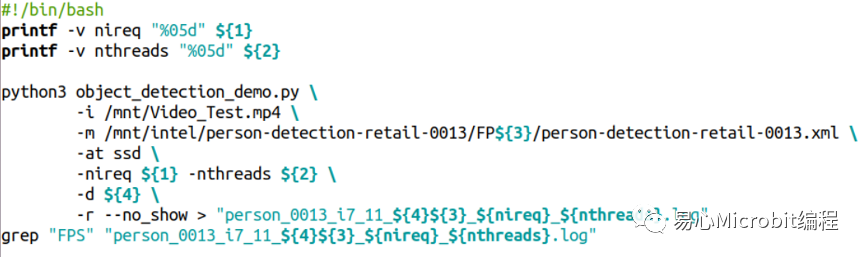
其中${1}、${2}分別代表nireq與nthreads的參數設定值,${3}表示32、16、16-INT8等設定值,${4}代表使用的是CPU、GPU、MULTI:CPU,GPU等設定值,透過這些設定值的更改,最后將執行過程輸出至各個條件的文本文件,范例程序執行結束時,于各文本文件的尾端會得到此次執行的FPS數值結果,最后以這個FPS數值作為相關的量測效能結果進行討論,詳細的參數設定值說明如表2。
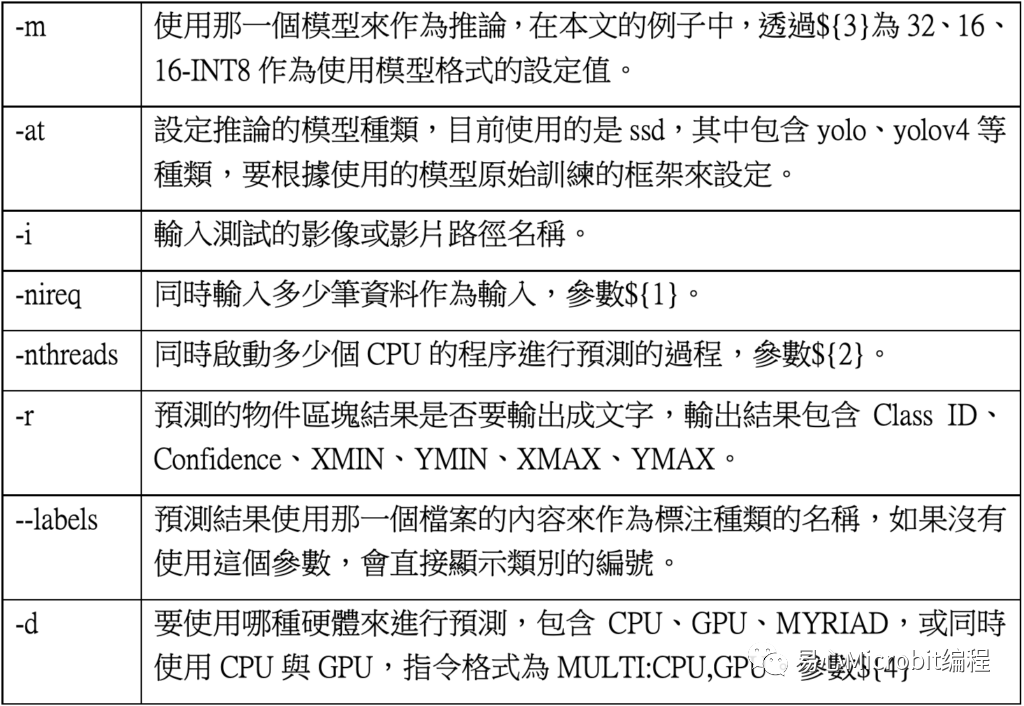
表2 –object_detection_demo.py相關的參數設定說明
本文量測數值使用之硬件環境
圖2為本文以東擎NUCBOX-1165G7工業用計算機,硬件環境為Intel i7第11代CPU,軟件環境使用Ubuntu 20.04.2 LTS為操作系統,執行OpenVINO 2021.4.582作為系統量測的運作環境,CPU型號為11th Gen Intel(R) Core(TM) i7-1185G7E @ 2.80GHz、cache 12288KB,共有8個Hyper-threading,內存為16GByte、硬盤型號為KINGSTON OM8PDP3256B-A01(NVM容量256GByte)。
特別要說明的是Intel第11代Core CPU內建的GPU,是第一個可以執行INT8的內建GPU,利用這個特性在執行OpenVINO時可以獲得更好的效能提升。

圖2 – 本文量測使用之工業用計算機,內含Intel第11代CPU與Wifi-6無線網絡芯片
CPU執行person-detection-retail-0013模型效能變化情形
圖3為CPU使用person-detection-retail-0013FP32模型的執行結果,可以觀察當nireq(nr)為1、nthreads(nt)為1時,每秒鐘可以辨識的畫面張數為35.1 FPS(每秒鐘能預測35.1張影像),進一步調整nireq、nthreads參數的數值進行預測,會發現nireq(nr)與nthreads(nt)設定不同數值時,會影響每秒所能預測的FPS效能。
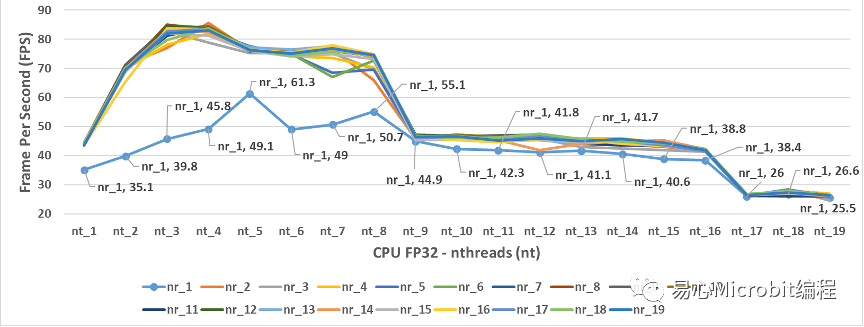
圖3 – CPU執行person-detection-retail-0013FP32模型結果
圖3中可以觀察到一個現象,當nthreads設定的值為3時,會得到相對最高的FPS結果,圖4為將圖3放大之后,由nthreads(nt)數值為2到8的設定值,分別在不同的nireq(nr)條件下,nireq(nr)數值為3到8的執行結果。
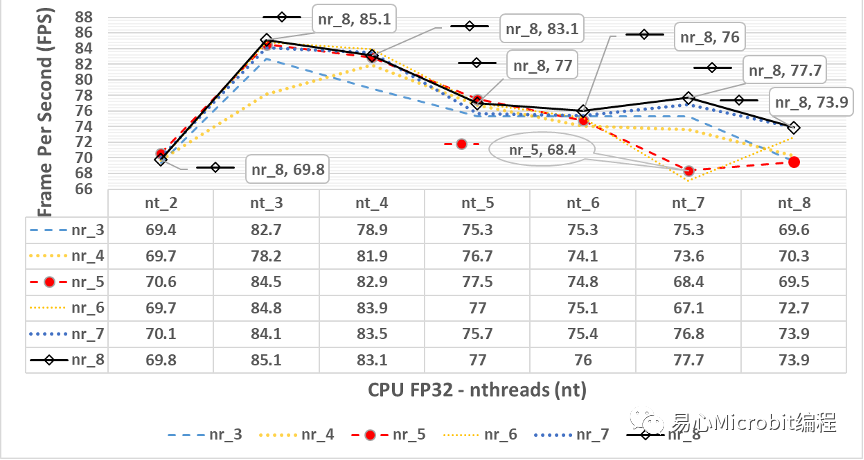
圖4 – CPU執行person-detection-retail-0013.xmlFP32模型,nthreads(nt)數值為2到8、nireq(nr)為3到8的FPS變化情形
由圖4中可以觀察到當nthreads設定值為3、nireq等于8,CPU執行FP32模型FPS此時為85.1 FPS,之后無論nthreads與nireq調整為其他數值,執行結果都無法超過此FPS,一般概念上會認為同時輸入的影像稍微多一點比較好,因為同時處理多一點影像,在機器有能力響應的狀態下,執行結果的效能相對應該會高一些,從這個觀點得到的FPS為nthreads為3與nireq為8時,表示一次輸入8張影像時,同時使用3個CPU的處理程序來處理person-detection-retail-0013模型的運作過程,會有較好的執行效能。
圖4同時顯示如果我們認為將nireq與nthreads的值設的越大越好可以得到更好的效能,結果顯示并不會有這樣的狀態產生,甚至當nthreads(nt)為19時,不管nireq(nr)設定多大的值,會發現此時約為25.1FPS,這樣的執行效能相對nthreads(nt)為3時的85.1 FPS,相當于只能得到最高效能的1/3執行效率,可以觀察到很明顯的,單純將nthreads與nireq值調大,只會效能更差而不會變好。
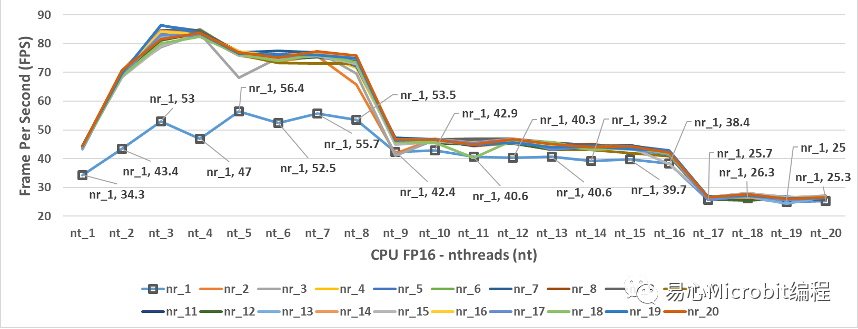
圖5 – CPU執行person-detection-retail-0013FP16模型效能的變化情形
圖5為CPU執行person-detection-retail-0013FP16模型的結果,相對CPU執行FP32模型效能的情形,觀察圖3與圖5可以發現最高的FPS都約為86 FPS,圖3與圖5的效能變化非常相似,這個狀態顯示CPU在FP32與FP16的執行具有相同的效能變化趨勢,nthreads為9時同樣會有一個很大的效能下降,原因與執行環境所采用的硬件有關,本文章所使用硬件為i7第11代核心,包含4核心共8個Hyper-threading,發現nthreads分別在9與17的設定值時,會產生一個相對陡降的FPS結果。
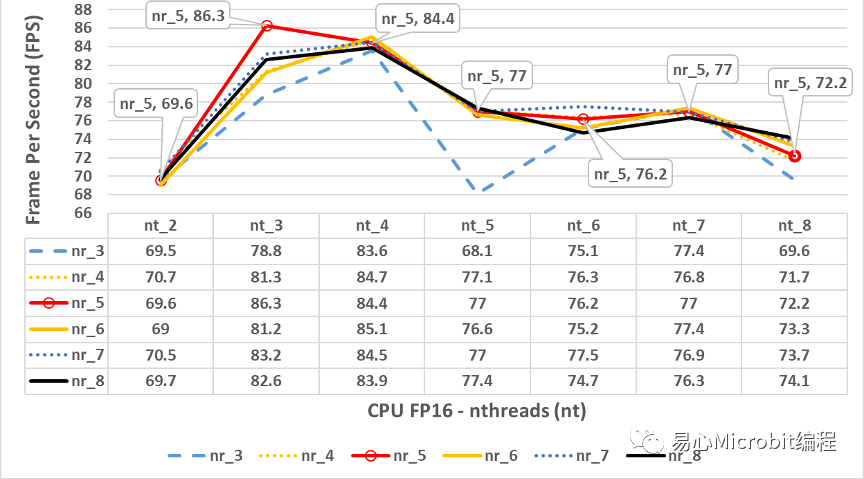
圖6 – CPU執行person-detection-retail-0013FP16模型效能的變化情形,nthreads(nt)數值為2到8、nireq(nr)為3到8的FPS變化情形
由圖6中會發現最高效能的值雖然在nthreads為3的時候,但是相對的此時的nireq為5,與圖4的nireq為8的情況并不同,此種最佳效能點的差異在各個模型選用時,可以再針對不同的nireq的數值做最后的量測進行尋找最佳參數點。
觀察CPU執行FP32與FP16的模型效能變化狀態后,圖7中為CPU模式執行person-detection-retail-0013FP16-INT8模型的結果,當nthreads(nt)設定的值為4、nireq(nr)等于20,量測范圍中最高的效能為116.5 FPS,很明顯的相較于FP32條件下最高為86 FPS高出許多。
從圖7中也可以觀察到nireq等于1,每次輸入1個影像,可以發現nthreads為4時,最高的效能為68.3FPS,無論nthreads設定多大,預測的FPS效能也無法提升,從這個結果可以觀察到,就算是硬件有很大的效能,nireq控制同時輸入數據的數量,nireq太小相對也會影響整體工作效能。
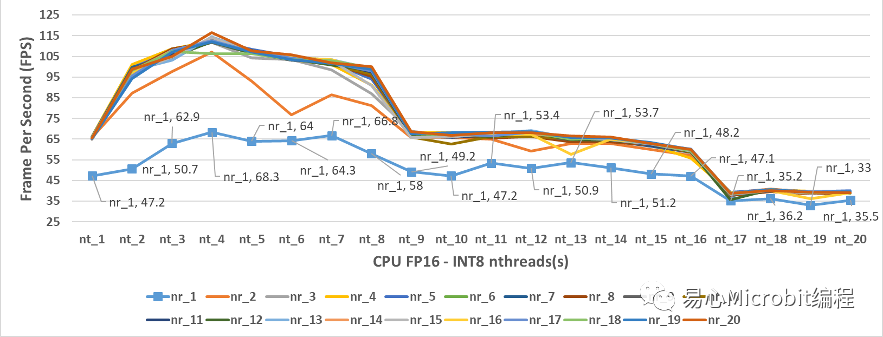
圖7 – CPU執行person-detection-retail-0013FP16-INT8模型效能的變化情形
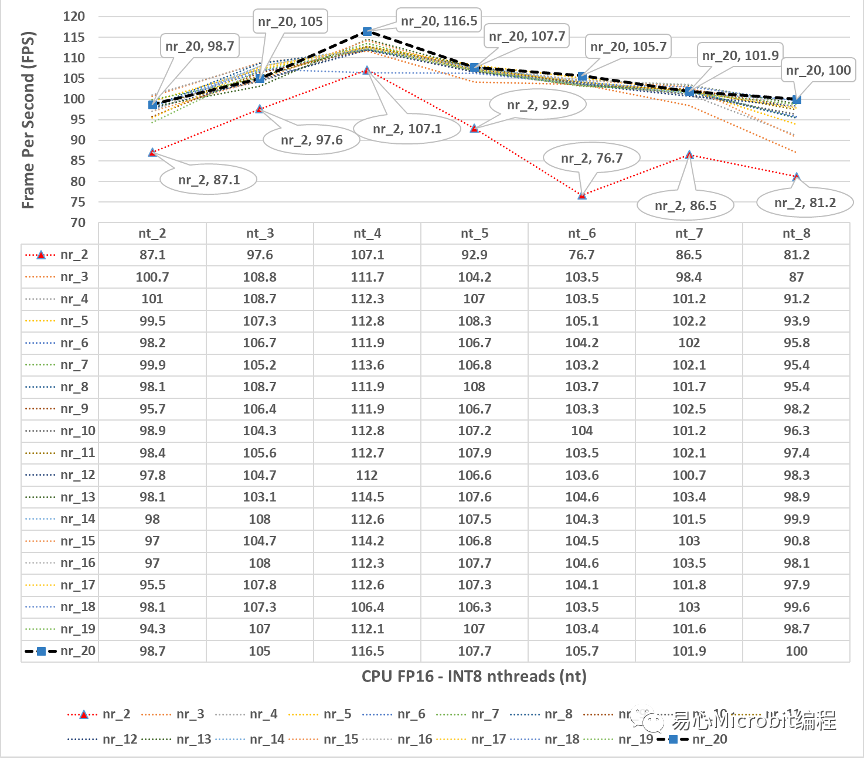
圖8 – CPU執行person-detection-retail-0013FP16-INT8模型效能的變化情形,nthreads(nt)數值為2到8、nireq(nr)為2到20的FPS變化情形
圖8為圖7詳細的變化情形,可以觀察到當nthreads(nt)的數值是4的時候,nireq設定值大于等于3之后,相對每秒可以執行推論的影像效能,相對高于其他的nthreads數值的推論效能,可以很明顯的感覺在CPU執行FP16-INT8的條件下,CPU的核心數量、nthreads設定數值,與推論效能最高點較為一致,進一步要注意的是,雖然印象上FP16-INT8執行效率相對會好很多,可是同樣的在nthreads為9的時候,一樣會有很大的效能陡降現象出現,在模型實際上線運作時候,需要先注意到這樣的現象對應于所使用的硬件運作條件(如核心數量、最大的Hyper-threading數量)。
GPU執行person-detection-retail-0013模型效能變化情形
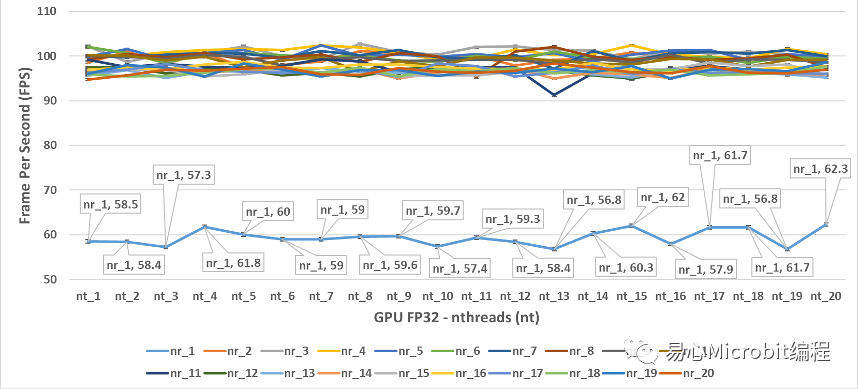
圖9 – GPU執行person-detection-retail-0013FP32模型效能的變化情形
圖9為GPU執行person-detection-retail-0013FP32模型效能的變化情形,相對CPU的運作狀態,以nthreads的形式為橫軸坐標軸時,會觀察到nireq為1的時候,系統的運作效能相對是最低的,nireq大于1以上很明顯FPS效率好很多,有趣的情況是將圖9轉換坐標軸,以nireq作為橫軸的狀態下,可以得到圖10的結果,此時會發現有趣的現象,當nireq大于3之后,在nireq持續增加相當于不斷的將同時輸入的影像數量提高時,在同樣的nthreads的情況下,GPU執行FP32模型的狀態,效能其實會持續降低。
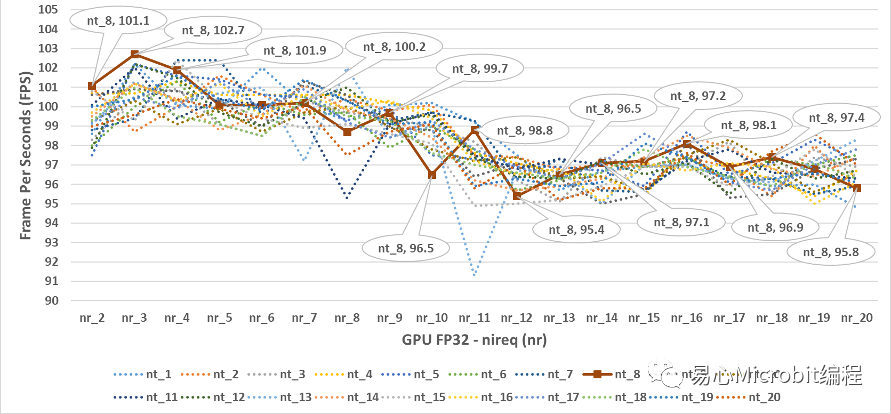
圖10 – GPU執行person-detection-retail-0013FP32模型效能的變化情形
由圖10的結果可以得到一個概念,在單純使用GPU狀態下執行FP32模型的時候,同時輸入影像的數量增大并沒有幫助,GPU執行FP32的效能最高為102.7FPS,相對CPU執行FP32的效能為86 FPS的狀態下,單純使用GPU執行FP32模型對于單獨CPU執行FP32模型約為1.18倍的效能,相對另一個有趣的狀態是,nthreads設定的數值超過8之后,似乎在單純GPU執行FP32模型的狀態下似乎對于推論效能不會有太大的影響,似乎此時設定nthreads的值,沒有真正的對應多個CPU核心運作的效能。
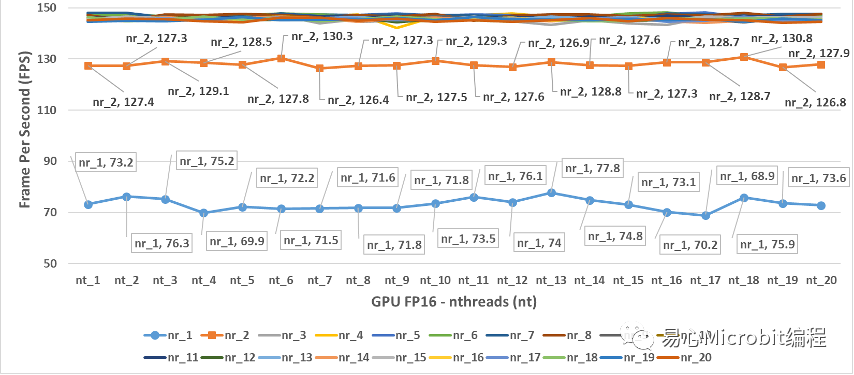
圖11- GPU執行person-detection-retail-0013FP16模型效能的變化情形
圖11為GPU執行person-detection-retail-0013FP16模型效能的變化情形,由圖11的結果可以得到一個概念,在單純使用GPU狀態執行FP16模型的時候,nireq在小于3的狀態下,GPU相對的執行效能并沒有達到滿載的狀態,相對GPU執行FP32模型效能最高為102.7FPS,很明顯GPU 在執行FP16模型nireq等于2時就已經接近130 FPS。
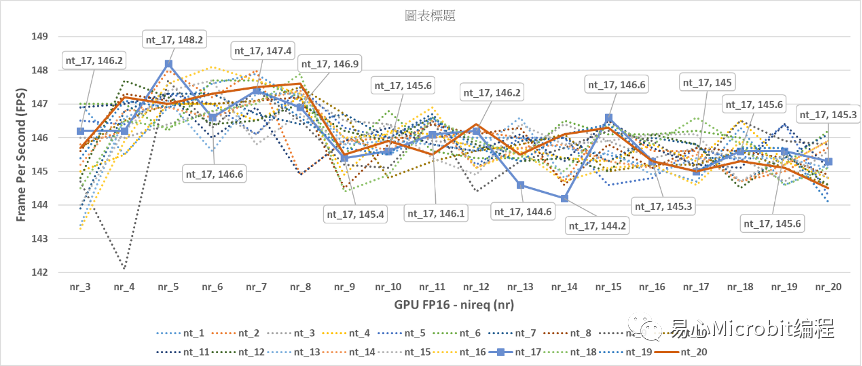
圖12- GPU執行person-detection-retail-0013FP16模型,顯示nireq(nr)為3到20,nthreads(nt)為1到20的效能變化情形
由圖12的結果可以觀察到,當GPU執行nireqperson-detection-retail-0013 FP16模型,最高的效能在nireq為5、nthreads(nt)為17此時為148.2FPS,相對在FP32的GPU與CPU運作條件下已有大幅度性能提升,可以觀察到nireq大于等于5之后效能會微幅的下降,nthreads的設定值大小對于效能的影響并不算太明顯,總結來說nireq大于3、nthreads設定值不論是多少,效能都會大于140FPS。
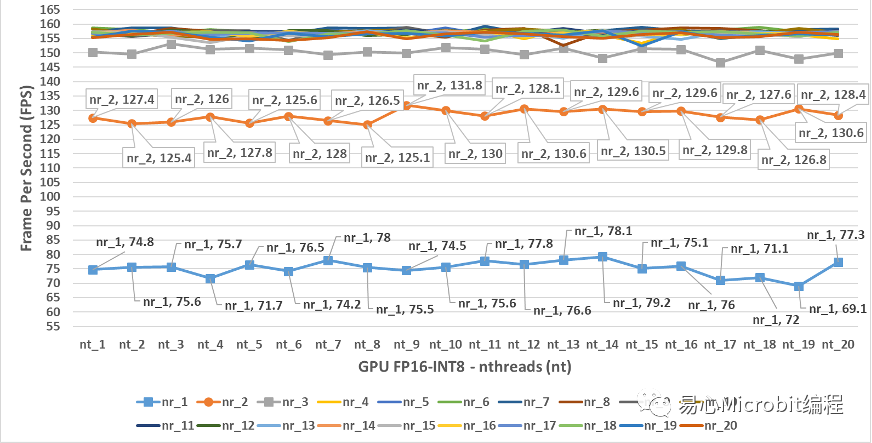
圖13 – GPU執行person-detection-retail-0013FP16-INT8模型效能變化
圖13為GPU執行person-detection-retail-0013FP16-INT8模型效能變化,與GPU執行person-detection-retail-0013 FP16模型比較時,會發現GPUFP16-INT8之nireq為1與2時,執行的FPS與GPU FP16時nireq為1與2的結果相當,而nireq為3時,執行效能與GPU執行FP16模型的最高FPS相當,進一步的當nireq持續增加大于5時,nthreads無論是哪種數值,均可達到150FPS以上,此結果顯示GPU執行FP16-INT8的效能相對在CPU與其他的GPU模式下,有著非常高的FPS執行效率。
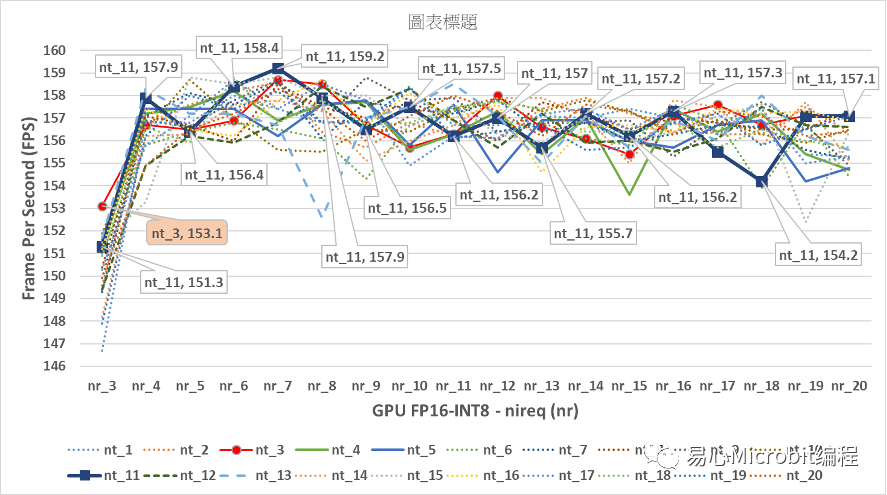
圖14 – GPU執行person-detection-retail-0013FP16-INT8模型效能變化
由圖14的結果可以觀察到GPU執行person-detection-retail-0013FP16-INT8模型效能,與GPU執行nireq person-detection-retail-0013 FP16模型比較時會發現,最高效能為nireq為7、nthreads(nt)為11,此時效能為159.2FPS,明顯高于GPU執行FP16模型的148.2FPS的效能。
CPU+GPU執行person-detection-retail-0013模型效能變化情形
圖15的結果可以觀察到CPU+GPU執行person-detection-retail-0013FP32模型效能的變化,要注意的是OpenVINO在同時使用CPU與GPU運作時,nthreads最大的數值在使用本硬件時只能設定到7,超過8之后會顯示只能最大設定到7的訊息,nthreads超過8之后就會顯示會將nthreads 自動設定為7進行預測,因此CPU+GPU同時運作的環境,nthreads的量測結果只有1到8的范圍,而nireq維持1到20的設定值。另外,在運作的參數-d中,采用的設定值是MULTI:GPU,CPU,這樣的條件下會將輸入數據優先派送GPU,之后再給CPU進行處理。
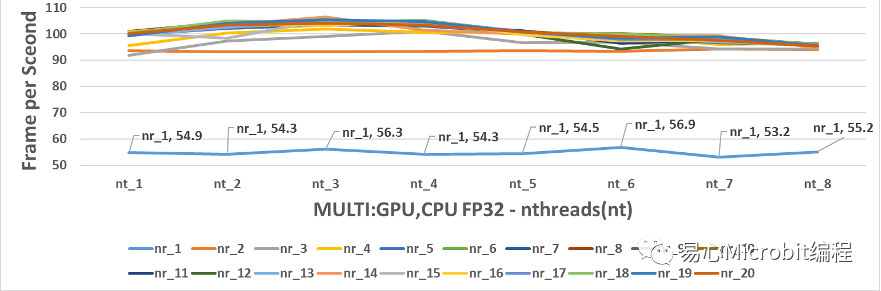
圖15 – CPU+GPU執行person-detection-retail-0013FP32模型效能變化
圖15的結果可以觀察到CPU+GPU執行person-detection-retail-0013FP32模型效能的變化,與單純使用GPU執行nireq person-detection-retail-0013 FP32模型比較時,將圖15放大為圖16,會發現最高的效能為nireq為14、nthreads(nt)為3,此時效能為106.4FPS,綜合圖15與圖16并且比較單純 CPU執行FP32的模型時,當nireq大于3時,nthreads持續增加效能同樣無法繼續提升。
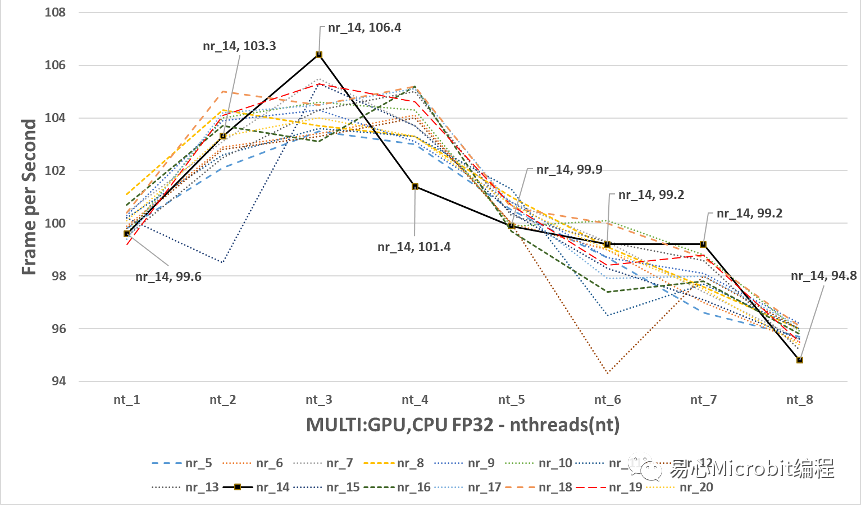
圖16 – CPU+GPU執行person-detection-retail-0013FP32模型,nireq由5到20,nthreads由1到8的效能變化
圖16的結果會發現CPU+GPU執行FP32模型最高的106.4FPS,與CPU執行FP32的最高85.1FPS相比多了約20FPS,另一方面如果與單純GPU執行FP32模型最高95.3FPS相比,大約多10FPS。因此可以得到CPU+GPU的執行person-detection-retail-0013 FP32的模型的狀態下,為FP32模型下最高的執行效能(106.4FPS)。
因此如果要求預測精度為FP32,能夠預期最好的FPS會在106附近。(nthreads設定為3、nireq設定為14、運作裝置為MULTI:GPU,CPU)。
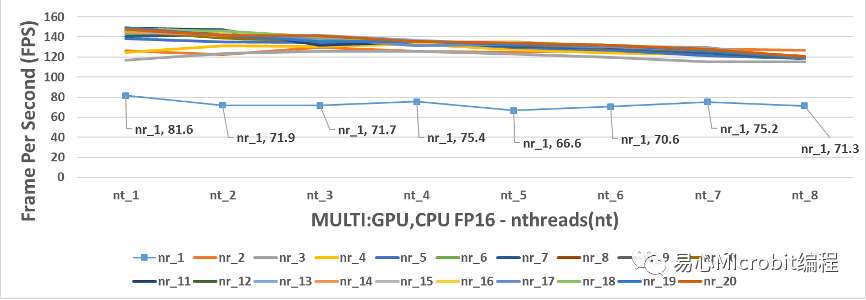
圖17 – CPU+GPU執行person-detection-retail-0013FP16模型效能變化
相對圖CPU+GPU執行FP32的結果,圖17與18為CPU+GPU執行person-detection-retail-0013F16模型效能的變化。圖18中顯示nthreads為1的狀態下,nireq為11與19時分別為149與149.5FPS,這兩個數值都非常高,但是由圖18會發現與單純GPU執行FP16的模型(圖12)有著幾乎相同的最高執行FPS,同時nthreads持續變大時FPS呈現持續下降,這種結果呈現CPU+GPU執行FP16模型的情況下,GPU與CPU+GPU執行的最高效能似乎非常接近。
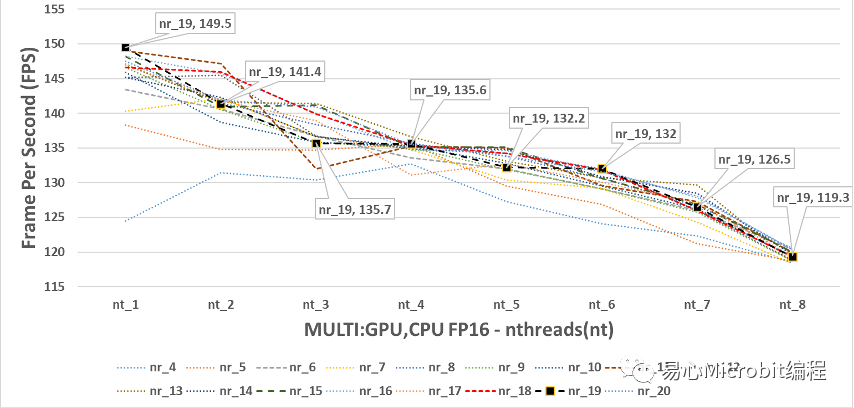
圖18 – CPU+GPU執行person-detection-retail-0013FP16模型,nireq由4到20,nthreads由1到8的效能變化
進一步的回頭觀察CPU執行FP16模型最高為86.3 FPS,由此也可以發現單純執行GPU或GPU+CPU執行FP16的效能,約提高1.73倍的效率,每秒鐘多63FPS。我們可以從上述的觀察中發現,GPU的運作環境下,其實nthreads為1的效能就是最好的狀態,至于nireq要設定多少,如果在不能夠有太多延遲畫面時間輸入的狀態下,建議一次輸入6張數據以上會有不錯的整體預測輸出效能,推論速度可以到140 FPS以上。
最后來看圖19中,顯示GPU+CPU執行FP16-INT8的模型狀態,會發現在nireq小于5的情形下,最高的預測效能都無法大于160FPS,可以明顯的看到,當nthreads為1、nireq大于5的條件下,觀察FPS效能會發現nireq為14、nthreads為1的狀態下,可跑出176.9FPS的最高效能,此效能值相對也是CPU、GPU、CPU+GPU執行FP16-INT8狀態下最高的結果。
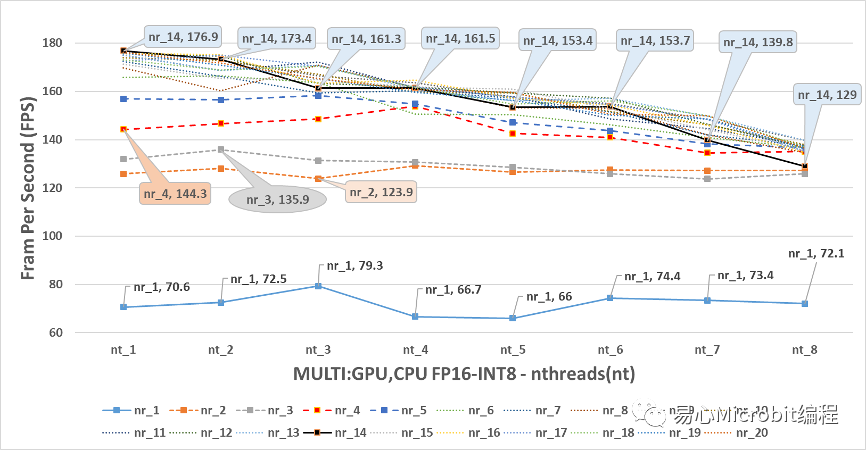
圖19 – CPU+GPU執行person-detection-retail-0013FP16-INT8模型效能變化
進一步討論CPU+GPU執行FP16-INT8的結果,會發現其實隨著nthreads的增大,在nthreads由2到8之間,其實對nireq為1到5以下似乎沒有變快的效果,另外在nireq為6到20的情況下,在nthreads大于1之后,明顯的預測的效能不升反將,推想這種情形發生的原因在于nireq其實也是需要CPU的執行資源,當把nthreads增大的時候,CPU的資源被瓜分至進行預測處理的后續工作的部份,然而實際上從數據執行結果的現象觀察,似乎只要nthreads設定為1,讓其他的CPU專心的進行數據讀取的動作把數據喂給GPU,然后CPU只需要用1個核心,專心的把GPU預測完的結果進行后續的處理,這樣的協同狀態下的工作組合,就可以達到很高的效率了。
結論
將目前觀察到的結果做一個總結,你的機器上面如果只有CPU,當然的狀態只能執行CPU運作FP32、FP16、FP16-INT8模型,FP16與FP32的模型在CPU模式下有同樣的效能,主要是系統會先將FP16轉換成FP32之后執行,要注意的是nthreads的值不能設定超過核心的Hyper-threading的最大總數量,否則會有效能陡降的情形。
本文目前測試的模型顯示nthreads的數量設定在CPU的核心數量減1,這個時候的CPU預測效能會是最好的狀態,當然部份的時候也可以試試看nthreads的數值設定與CPU的核心數量一樣,因為nthreads的數值超過CPU核心數目之后,FPS就只會變慢而不會變快了。
如果你的機器上面有Intel GPU的顯示芯片,目前許多桌上型機器內建Intel GPU顯示芯片,過去只能用來作為顯示適配器使用,其實這時可以將這樣的機器作為機器學習預測使用,在本文中所測試的狀態,單純使用GPU實際上有著非常好的運作效能,如果需要維持預測精準度又不希望占用CPU的運算效能,可以單純使用GPU執行FP32模型,相對已經可以快過單純使用CPU執行FP32預測的效能。
最后如果你可以提供機器全部的效能進行機器學習的預測,在這樣的狀態CPU+GPU同時協作,如果你使用的機器學習模型在FP16-INT8的狀態下可以維持預測的精確度,則使用CPU+GPU的狀態下,運作FP16-INT8將大幅度提升預測的FPS效率,相對CPU FP32格式的模型,CPU+GPU執行FP16-INT8相當于在同一臺機器上獲得2倍的預測效能。
后記
初學者透過MakerPRO系列文章可以學習OpenVINO操作,本文描述了參數調整的概念如何的影響OpenVINO模型上線時注意的事項,希望能夠讓系統上線運作模型時,有一定比較清楚要注意的觀念。
本文并沒有提及如何將模型換成FP16-INT8,以及使用benchmark_app比較FP32、FP16、FP16-INT8的結果,benchmark_app內定可以使用隨機值作為輸入,并單純的測試硬件計算效能對應模型推論的FPS結果。最后,對于多攝影機、多模型同時運作在OpenVINO的狀態,之后有機會再分享了。
審核編輯:湯梓紅
-
機器學習
+關注
關注
66文章
8377瀏覽量
132407 -
Docker
+關注
關注
0文章
454瀏覽量
11814
原文標題:優化OpenVINO模型效能:參數設定影響實測
文章出處:【微信號:易心Microbit編程,微信公眾號:易心Microbit編程】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何使用OpenVINO C++ API部署FastSAM模型
【大聯大世平Intel?神經計算棒NCS2試用體驗】模型優化器的配置流程
GPU上OpenVINO基準測試的推斷模型的默認參數與CPU上的參數不同是為什么?
如何在執行converter.py腳本時指定模型優化器的路徑?
為什么無法使用POT優化Tensorflow (TF)或MXNet模型?
OpenVINO模型優化實測:PC/NB當AI辨識引擎沒問題!
在C++中使用OpenVINO工具包部署YOLOv5模型
自訓練Pytorch模型使用OpenVINO?優化并部署在AI愛克斯開發板

如何將Pytorch自訓練模型變成OpenVINO IR模型形式

沒有“中間商賺差價”, OpenVINO? 直接支持 PyTorch 模型對象

使用OpenVINO優化并部署訓練好的YOLOv7模型
基于OpenVINO C# API部署RT-DETR模型
NNCF壓縮與量化YOLOv8模型與OpenVINO部署測試





 工商網監
工商網監
評論