 利用Transformer和CNN 各自的優勢以獲得更好的分割性能
利用Transformer和CNN 各自的優勢以獲得更好的分割性能
概述
在這篇論文中,提出了一種新的醫學圖像分割混合架構:PHTrans,它在主要構建塊中并行混合 Transformer 和 CNN,分別從全局和局部特征中生成層次表示并自適應聚合它們,旨在充分利用 Transformer 和 CNN 各自的優勢以獲得更好的分割性能。
具體來說,PHTrans 沿用 U 形設計,在深層引入并行混合模塊,其中卷積塊和修改后的 3D Swin Transformer 塊分別學習局部特征和全局依賴關系,然后使用 sequence-to-volume 操作統一輸出維度以實現特征聚合,操作的具體細節在這篇閱讀筆記的后面詳細介紹。最后在 BCV 和 ACDC 數據集上驗證了其有效性,并用 nnUNet 包預處理 BCV 和 ACDC 數據集。
為什么要并行
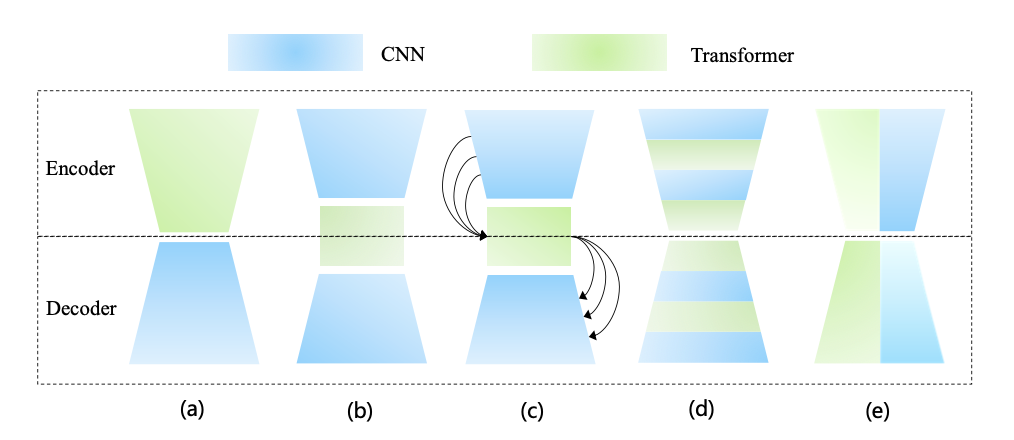
下圖的 (a)~(d) 是幾種流行的基于 Transformer 和 CNN 的混合架構,既將 Transformer 添加到以 CNN 為 backbone 的模型中,或替換部分組件。其中 (c) 與 (b) 的區別是通過 Transformer 橋接從編碼器到解碼器的所有階段,而不僅僅是相鄰的階段,這就捕獲了多尺度全局依賴。(d) 表示將 Transformer 和 CNN 交織成一個混合模型,其中卷積編碼精確的空間信息,而自注意力機制捕獲全局上下文信息。
圖 (e) 表示二者的并行。在串行組合中,卷積和自注意力機制無法貫穿整個網絡架構,難以連續建模局部和全局表示,因此這篇論文里認為并行可以充分發揮它們的潛力。
PHTrans 架構 overview
首先,我們從總體上分析一下 PHTrans 架構,然后在下一部分看它的細節。如下圖 (b),其主要構建塊由 CNN 和 Swin Transformer 組成,以同時聚合全局和局部表示。圖 (a) 依舊遵循的 U 形架構設計,在淺層只是普通的卷積塊,在深層引入了 sequence-to-volume 操作來實現 Swin Transformer 和 CNN 在一個塊中的并行組合。
我們上一篇解析的 UNeXT 也是只在深層使用 TokMLP 的,看來淺層的卷積還是必要的。也就是說,與串行混合架構相比,PHTrans 可以獨立并行構建分層的局部和全局表示,并在每個階段融合它們。
進一步解釋下為什么輸入的第一層也就是 U 型架構的淺層沒有用 Trans&Conv Block?因為自注意力機制的計算復雜度高,Transformer 無法直接接收以像素為標記的輸入。在論文的實現中,使用了級聯卷積塊和下采樣操作來減小空間大小,逐步提取高分辨率的低級特征以獲得精細的空間信息。類似地,這些純卷積模塊也部署在解碼器的對應層,并通過上采樣恢復原始維度。
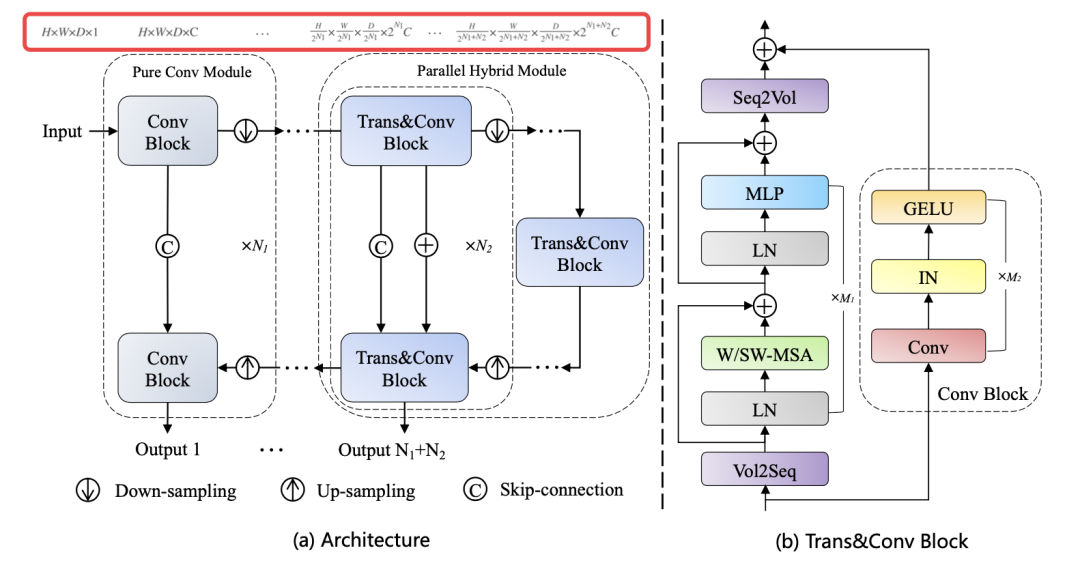
我們仔細看下 PHTrans 的編碼器,對于 H×W×D 的輸入 volume(3D 醫學圖像),其中 H、W 和 D 分別表示高度、寬度和深度,首先使用幾個純卷積模塊得到的 volume,其中 N1 和 C 表示卷積塊和通道的數量。然后輸入到 Trans&Conv Block 重復 N2 次。對于解碼器同樣基于純卷積模塊和并行混合模塊構建,并通過跳躍連接和加法操作融合來自編碼器的語義信息。此外,在訓練期間在解碼器的每個階段都使用深度監督機制,產生總共 N1 + N2 個輸出,其中應用了由交叉熵和 DICE 的聯合損失。
深度監督(deep supervision)又稱為中繼監督(intermediate supervision),其實就是網絡的中間部分新添加了額外的 Loss,跟多任務是有區別的,多任務有不同的 GT 計算不同的 Loss,而深度監督的 GT 都是同一個 GT,不同位置的 Loss 按系數求和。深度監督的目的是為了淺層能夠得到更加充分的訓練,避免梯度消失(有待研究)。在提供的 Github 代碼里,提到的超參數有 N1、N2、M1 和 M2,M1 和M2 是并行混合模塊中 Swin Transformer 塊和卷積塊的數量。
Trans&Conv block
Trans&Conv block 的設計是我們最感興趣的地方。縮小比例的特征圖分別輸入 Swin Transformer (ST) 塊和卷積 (Conv) 塊,分別在 ST 塊的開頭和結尾引入 Volume-to-Sequence (V2S) 和 Sequence-to-Volume (S2V) 操作來實現 volume 和 sequence 的變換,使其與 Conv 塊產生的輸出兼容。具體來說,V2S 用于將整個 3D 圖像重塑為具有窗口大小的 3D patches 序列。S2V 是相反的操作。
如上一節的圖 (b) 所示,一個 ST 塊由一個基于移位窗口的多頭自注意力 (MSA) 模塊組成,然后是一個 2 層 MLP。在每個 MSA 模塊和每個 MLP 之前應用一個 LayerNorm (LN) 層,在每個模塊之后應用一個殘差連接。在 M1 個連續的 ST 塊中,W-MSA 和 SW-MSA 交替嵌入到 ST 塊中,W-MSA能夠降低計算復雜度,但是不重合的窗口之間缺乏信息交流,這樣其實就失去了 Transformer 利用 Self-Attention 從全局構建關系的能力,于是用 SW-MSA 來跨窗口進行信息交流(跨窗口連接),同時保持非重疊窗口的高效計算。
對于醫學圖像分割,需要將標準 ST 塊修改為 3D 版本,該版本在局部 3D 窗口內計算自注意力,這些窗口被安排為以非重疊方式均勻劃分體積。計算方法是下面這樣的:假設 x ∈ H×W×S×C 是 ST 塊的輸入,首先將其 reshape 為 N×L×C,其中 N 和 L = Wh × Ww × Ws 分別表示 3D 窗口的數量和維度。每個 head 中的 self-attention 計算如下:
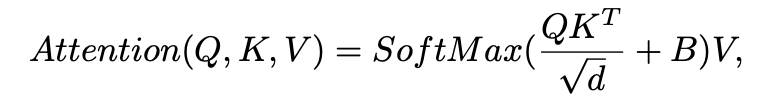
Q, K, V ∈ L×d 是查詢、鍵和值矩陣,d 是查詢/鍵維度,B ∈ L×L 是相對位置偏差。B 的取值在論文和代碼里都可以找到,這里我們就不仔細探究了。(b) 中的卷積塊以 3 × 3 × 3 卷積層、GELU 非線性和實例歸一化層為單位重復 M2 次。最后,通過加法運算融合 ST 塊和 Conv 塊的輸出。編碼器中 Trans&Conv 塊的計算過程(抽象成并行)可以總結如下:
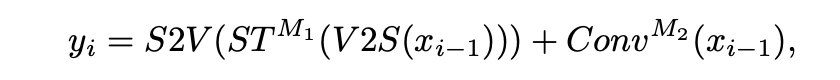
xi?1 是編碼器第 i?1 階段的下采樣結果。值得注意的是,在解碼器中,除了跳躍連接之外,還通過加法操作來補充來自編碼器的上下文信息(圖 (a) 中的圈 C 和 圈 +)。因此,解碼器中的 Trans&Conv 塊計算(抽象成并行)可以表示為:
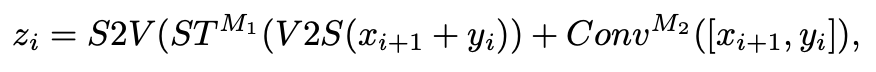
實驗
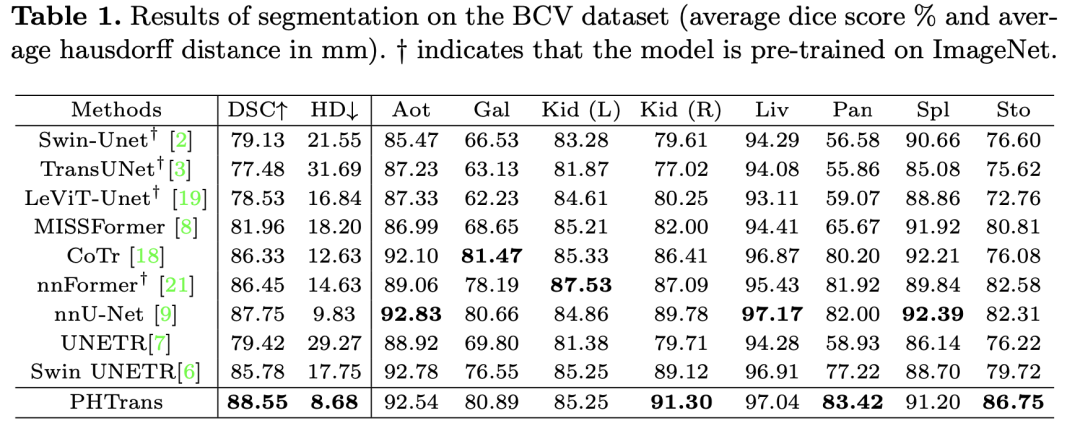
實驗在 BCV 和 ACDC 數據集上,BCV 分割腹部 CT 多個目標,ACDC 是 MRI 心臟分割,標記了左心室 (LV)、右心室 (RV) 和心肌 (MYO)。在 BCV 上和其他 SOTA 方法的比較如下表:
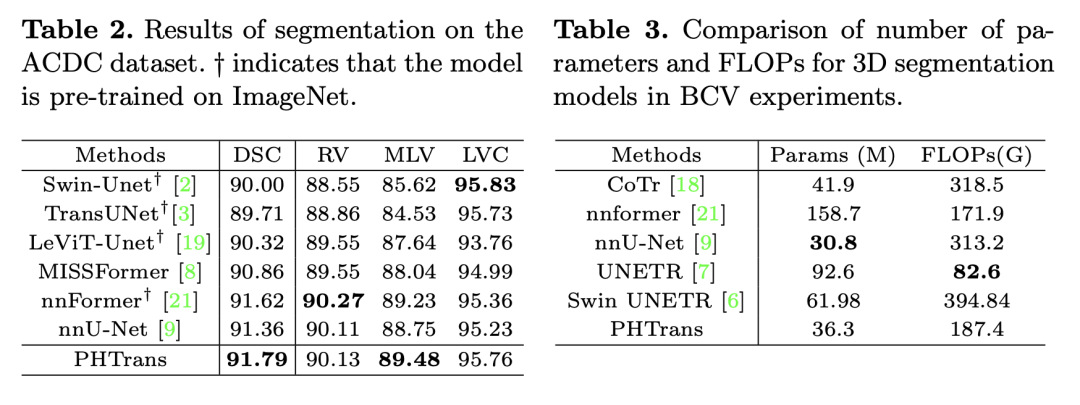
在 ACDC 上和其他 SOTA 方法的比較如 Table 2 所示,Table 3 中的參數量和 FLOPS 和其他方法比也沒有很夸張,參數量甚至和 nnU-Net 相近。
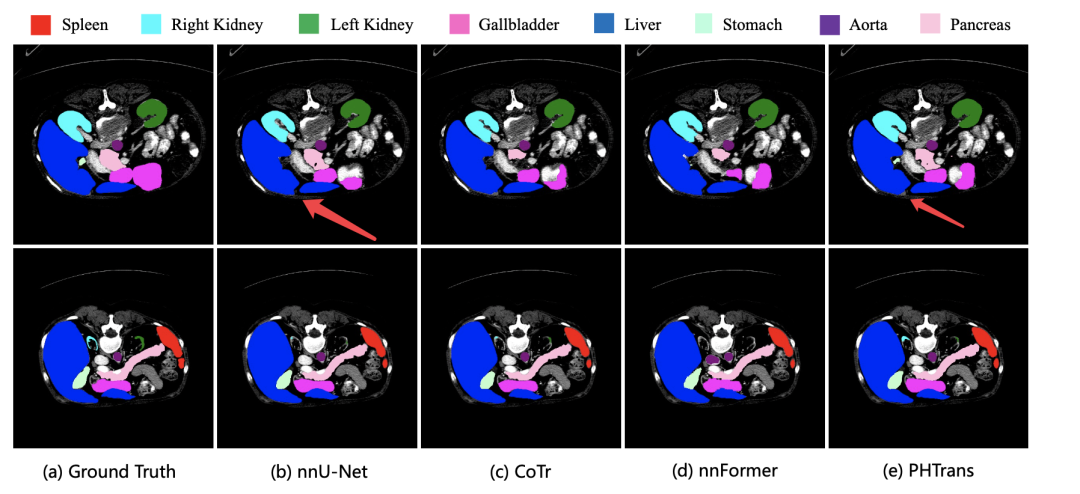
可視化分割結果如下圖,我們只定位藍色肝臟的分割效果,箭頭位置表明分割的效果 PHTrans 是更優秀的。
總結
PHTrans 也許為更多下游醫學圖像任務開發了新的可能性。在 PHTrans 中,都是普通的 Swin Transformer 和簡單的 CNN 塊,這表明性能提升源于并行混合架構設計,而不是 Transformer 和 CNN 塊。此外,PHTrans 沒有經過預訓練,因為到目前為止還沒有足夠大的通用 3D 醫學圖像數據集。
-
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
cnn
+關注
關注
3文章
351瀏覽量
22178 -
Transformer
+關注
關注
0文章
141瀏覽量
5982
原文標題:PHTrans 并行聚合全局和局部表示來進行醫學圖像分割
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
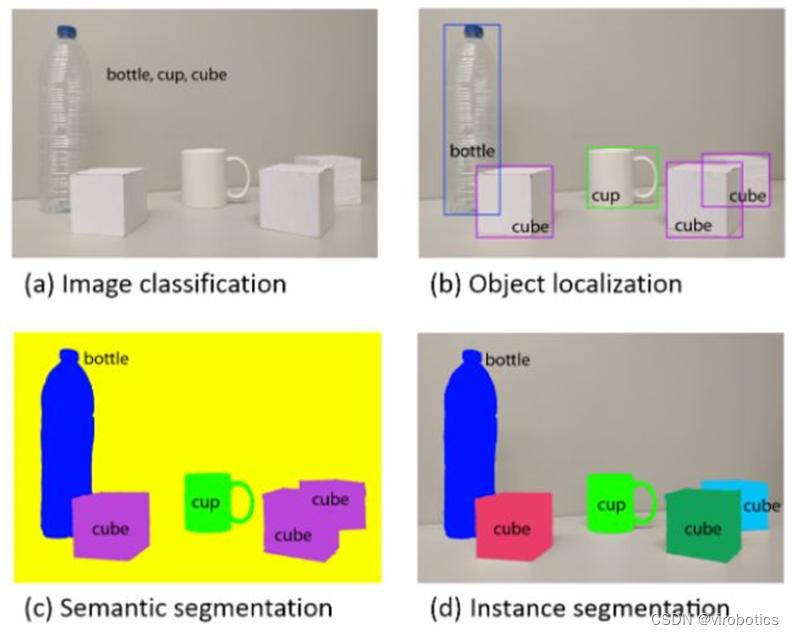
如何利用PyTorch API構建CNN?
如何利用卷積神經網絡去更好地控制巡線智能車呢
基于MLP的快速醫學圖像分割網絡UNeXt相關資料分享
介紹一種用于密集預測的mlp架構CycleMLP
一種新的彩色圖像分割算法
局部聚類分析的FCN-CNN云圖分割方法
如何在Vivado中應用物理優化獲得更好的設計性能
用于實例分割的Mask R-CNN框架
普通視覺Transformer(ViT)用于語義分割的能力
基于 Transformer 的分割與檢測方法

如何利用CNN實現圖像識別
圖像分割與語義分割中的CNN模型綜述
利用TPS61299在智能手表應用中獲得快速瞬態性能優勢






 工商網監
工商網監
評論