 計算機視覺的基礎概念和現實應用
計算機視覺的基礎概念和現實應用
今天,由于其廣泛應用和巨大潛力,計算機視覺成為最熱的人工智能和機器學習子領域之一。其目標是:復制人類視覺的強大能力。
但是,到底什么是計算機視覺?它在不同行業中的應用現狀如何?知名的商業用例有哪些?典型的計算機視覺任務是什么?
本文將介紹計算機視覺的基礎概念和現實應用,對任何聽說過計算機視覺但不確定它是什么以及如何應用的人,本文是了解計算機視覺這一復雜問題的便捷途徑。
什么是計算機視覺?
計算機視覺解決什么問題
人類能夠理解和描述圖像中的場景。以下圖為例,人類能做到的不僅僅是檢測到圖像前景中有四個人、一條街道和幾輛車。
除了這些基本信息,人類還能夠看出圖像前景中的人正在走路,其中一人赤腳,我們甚至知道他們是誰。我們可以理性地推斷出圖中人物沒有被車撞擊的危險,白色的大眾汽車沒有停好。人類還可以描述圖中人物的穿著,不止是衣服顏色,還有材質與紋理。
這也是計算機視覺系統需要的技能。簡單來說,計算機視覺解決的主要問題是:
給出一張二維圖像,計算機視覺系統必須識別出圖像中的對象及其特征,如形狀、紋理、顏色、大小、空間排列等,從而盡可能完整地描述該圖像。
區分計算機視覺與其相關領域
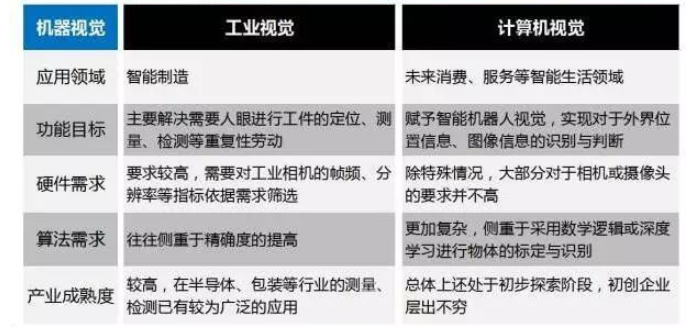
計算機視覺完成的任務遠超其他領域,如圖像處理、機器視覺,盡管它們存在一些共同點。接下來,我們就來了解一下這些領域之間的差異。
圖像處理
圖像處理旨在處理原始圖像以應用某種變換。其目標通常是改進圖像或將其作為某項特定任務的輸入,而計算機視覺的目標是描述和解釋圖像。例如,降噪、對比度或旋轉操作這些典型的圖像處理組件可以在像素層面執行,無需對圖像整體具備全面的了解。
機器視覺
機器視覺是計算機視覺用于執行某些(生產線)動作的特例。在化工行業中,機器視覺系統可以檢查生產線上的容器(是否干凈、空置、無損)或檢查成品是否恰當封裝,從而幫助產品制造。
計算機視覺
計算機視覺可以解決更復雜的問題,如人臉識別、詳細的圖像分析(可幫助實現視覺搜索,如 Google Images),或者生物識別方法。
行業應用
人類不僅能夠理解圖像中的場景,稍加訓練,還能解釋書法、印象派畫家、抽象畫,以及胎兒的二維超聲圖像。
從這個角度來看,計算機視覺領域尤其復雜,它擁有大量的實際應用。
從電商到傳統行業,各種類型和規模的公司現在都可以利用計算機視覺的強大能力,這是依賴于人工智能和機器學習(更具體地說是計算機視覺)的創新所帶來的利好。
下面我們就來看看,近年來受計算機視覺影響最大的行業應用。
零售業
近年來,計算機視覺在零售業的應用已成為最重要的技術趨勢之一。下文將介紹一些常見的用例。如果你想對計算機視覺在零售業的潛在應用有更詳細的了解,請參考:https://tryolabs.com/resources/retail-innovations-machine-learning/。
行為追蹤
實體零售店利用計算機視覺算法和攝像頭,了解顧客及其行為。
計算機視覺算法能夠識別人臉,確定人物特征,如性別或年齡范圍。此外,零售店還可以利用計算機視覺技術追蹤顧客在店內的移動軌跡,分析其移動路線,檢測行走模式,并統計零售店店面受到行人注意的次數。
添加視線方向檢測后,零售店能夠回答這一重要問題:將店內商品放在哪個位置可以提升消費者體驗,最大化銷售額。
計算機視覺還是開發防盜竊機制的強大工具。人臉識別算法可用于識別已知的商店扒手,或檢測出某位顧客將商品放入自己的背包。
庫存管理
計算機視覺在庫存管理方面有兩個主要的應用。
通過安防攝像頭圖像分析,計算機視覺算法可以對店內剩余商品生成非常準確的估計。對于店鋪管理者來說,這是非常寶貴的信息,它可以幫助管理者立即察覺不尋常的貨物需求,并及早作出反應。
另一個常見應用是:分析貨架空間利用情況,識別次優配置。除了發現被浪費的空間以外,此類算法還可以提供更好的貨品擺放方案。
制造業
生產線上的主要問題是機器中斷或殘次品,這些問題會導致生產延遲和利潤損失。
計算機視覺算法被證實是實施預測性維護的好方法。算法通過分析(來自機器人身上攝像頭等的)視覺信息,預先發現機器的潛在問題。此類系統可以預測包裝或汽車裝配機器人是否會中斷,這是一項巨大的貢獻。
這同樣可用于降低不良率,系統可以檢測出整個生產線上各個組件中的缺陷。這使得制造商實時響應,采取解決辦法。缺陷可能不那么嚴重,生產流程可以繼續,但是產品以某種方式被標記,或者被指向特定的生產路徑。但是,有時停止生產線是必要的。為了進一步的利益,此類系統可以針對每個用例進行訓練,按類型和嚴重程度對缺陷進行分類。
醫療行業
在醫療行業中,現有計算機視覺應用的數量非常龐大。
毫無疑問,醫療圖像分析是最著名的例子,它可以顯著提升醫療診斷流程。此類系統對 MRI 圖像、CT 掃描圖像和 X 光圖像進行分析,找出腫瘤等異常,或者搜索神經系統疾病的癥狀。
在很多情況下,圖像分析技術從圖像中提取特征,從而訓練能夠檢測異常的分類器。但是,一些特定應用需要更細化的圖像處理。例如,對結腸鏡檢查圖像進行分析時,分割圖像是必要的,這樣才能找出腸息肉,防止結直腸癌。
胸腔 3D 渲染 CT 掃描圖像的體分割。(圖源:https://en.wikipedia.org/wiki/Image_segmentation)
上圖是觀察胸腔元素所需的圖像分割結果。該系統分割每個重要部分并著色:肺動脈(藍色)、肺靜脈(紅色)、縱膈(黃色)和橫膈(紫色)。
目前大量此類應用已經投入使用,如估計產后出血量、量化冠狀動脈鈣化情況、在沒有 MRI 的情況下測定人體內的血流量。
但是,醫療圖像并非計算機視覺在醫療行業中唯一的用武之地。比如,計算機視覺技術為視障人士提供室內導航幫助。這些系統可以在樓層平面圖中定位行人和周圍事物等,以便實時提供視覺體驗。視線追蹤和眼部分析可用于檢測早期認知障礙,如兒童自閉癥或閱讀障礙,這些疾病與異常注視行為高度相關。
你是否思考過,自動駕駛汽車如何「看」路?計算機視覺在其中扮演核心角色,它幫助自動駕駛汽車感知和了解周圍環境,進而恰當運行。
計算機視覺最令人興奮的挑戰之一是圖像和視頻目標檢測。這包括對不同數量的對象進行定位和分類,以便區分某個對象是交通信號燈、汽車還是行人,如下圖所示:
自動駕駛汽車目標檢測。(圖源:https://cdn-images-1.medium.com/max/1600/1*q1uVc-MU-tC-WwFp2yXJow.gif)
此類技術,加上對來自傳感器和/或雷達等來源的數據進行分析,使得汽車能夠「看見」。
圖像目標檢測是一項復雜的強大任務,之前我們曾經討論過,參見:https://tryolabs.com/blog/2017/08/30/object-detection-an-overview-in-the-age-of-deep-learning/。
另一篇文章從人類-圖像交互的角度探討這一主題,參見:https://tryolabs.com/blog/2018/03/01/introduction-to-visual-question-answering/。
保險業
計算機視覺在保險業中的應用影響很大,尤其是在理賠處理中。
計算機視覺應用可以指導客戶以視覺形式進行理賠文件處理。它可以實時分析圖像并發送至適合的保險經紀人。同時,它可以估計和調整維護費用,確定是否在保險覆蓋范圍內,甚至檢測是否存在保險欺詐。所有這些最大程度上縮短了索賠流程,為客戶提供更好的體驗。
從預防的角度來看,計算機視覺在避免意外事故方面用處極大。大量可用于阻止碰撞的計算機視覺應用被整合到工業機械、汽車和無人機中。這是風險管理的新時代,可能改變整個保險業。
農業
計算機視覺對農業有極大影響,尤其是精準農業。
在糧食生產這一全球經濟活動中,存在一系列寶貴的計算機視覺應用。糧食生產面臨一些反復出現的問題,之前這些問題通常由人類監控。而現在,計算機視覺算法可以檢測或合理預測病蟲害。此類早期診斷可幫助農民快速采取合適措施,減少損失,保證生產質量。
另一項長期挑戰是除草,因為雜草對除草劑產生抗藥性,可能給農民帶來嚴重損失。現在出現了配備有計算機視覺技術的機器人,它們可以監控整片農田,精準噴灑除草劑。這極大地節約了使用農藥量,為地球環境和生產成本均帶來了極大的益處。
土壤質量也是農業中的一大主要因素。一些計算機視覺應用可以從手機拍攝的照片中識別出土壤的潛在缺陷和營養缺乏問題。分析之后,這些應用會針對檢測出的土壤問題,提供土壤恢復技術和可能的解決方案。
計算機視覺還可用于分類。一些算法通過識別水果、蔬菜甚至花卉的主要特性(如大小、質量、重量、顏色、紋理等),對其進行分類。這些算法還能夠檢測缺陷,估計出哪些農產品保鮮期較長、哪些應該放置在本地市場售賣。這極大延長了農產品的保鮮期,減少了農產品上市前所需時間。
安防
與零售業類似,對安全具備高要求的企業(如銀行或賭場)可從計算機視覺應用中獲益,這些應用對安防攝像頭拍攝的圖像進行分析,從而識別顧客。
而從另一個層面上來講,計算機視覺是國土安全任務中的強大工具。它可用于改進港口貨物檢驗,或者監控敏感場所,如大使館、發電站、醫院、鐵路和體育場。這里,計算機視覺不僅能夠分析和分類圖像,還能對場景提供詳細且有意義的描述,為決策實時提供關鍵因素。
通常,計算機視覺廣泛應用于國防任務,如偵察敵軍地形、自動確認圖像中的敵軍、自動化車輛和機器移動,以及搜索援救。
典型的計算機視覺任務
高度復制人類視覺系統,這是如何做到的呢?
計算機視覺基于大量不同任務,并組合在一起實現高度復雜的應用。計算機視覺中最常見的任務是圖像和視頻識別,涉及確定圖像包含的不同對象。
圖像分類
計算機視覺中最知名的任務可能就是圖像分類了,它對給定圖像進行分類。我們看一個簡單的二分類例子:我們想根據圖像是否包含旅游景點對其進行分類。假設我們為此任務構建了一個分類器,并提供了一張圖像(見下圖)。
該分類器認為上述圖像屬于包含旅游景點的圖像類別。但這并不意味著分類器認出埃菲爾鐵塔了,它可能只是曾經見過這座塔的照片,并且當時被告知圖像中包含旅游景點。
該分類器的更強大版本可以處理不止兩個類別。例如,分類器將圖像分類為旅游景點的特定類型,如埃菲爾鐵塔、凱旋門、圣心大教堂等。那么在此類場景中,每個圖像輸入可能有多個答案,就像上面那張明信片一樣。
定位
假設,現在我們不僅想知道圖像中出現的旅游景點名稱,還對其在圖像中的位置感興趣。定位的目標就是找出圖像中單個對象的位置。例如,下圖中埃菲爾鐵塔的位置就被標記出來了。
被紅色邊界框標記出的埃菲爾鐵塔。(圖源:https://cdn.pariscityvision.com/media/wysiwyg/tour-eiffel.jpg)
執行定位的標準方式是,在圖像中定義一個將對象圍住的邊界框。
定位是一個很有用的任務。比如,它可以對大量圖像執行自動對象剪裁。將定位與分類任務結合起來,就可以快速構建著名旅游景點(剪裁)圖像數據集。
目標檢測
我們想象一個同時包含定位和分類的動作,對一張圖像中的所有感興趣對象重復執行該動作,這就是目標檢測。該場景中,圖像中的對象數量是未知的。因此,目標檢測的目標是找出圖像中的對象,并進行分類。
在這個密集圖像中,我們可以看到計算機視覺系統識別出大量不同對象:汽車、人、自行車,甚至包含文本的標志牌。
這個問題對人類來說都算困難的。一些對象只顯示出一部分,因為它們有一部分在圖像外,或者彼此重疊。此外,相似對象的大小差別極大。
目標檢測的一個直接應用是計數,它在現實生活中應用廣泛,從計算收獲水果的種類到計算公眾集會或足球賽等活動的人數,不一而足。
目標識別
目標識別與目標檢測略有不同,盡管它們使用類似的技術。給出一個特定對象,目標識別的目標是在圖像中找出該對象的實例。這并不是分類,而是確定該對象是否出現在圖像中,如果出現,則執行定位。搜索包含某公司 logo 的圖像就是一個例子。另一個例子是監控安防攝像頭拍攝的實時圖像以識別某個人的面部。
實例分割
我們可以把實例分割看作是目標檢測的下一步。它不僅涉及從圖像中找出對象,還需要為檢測到的每個對象創建一個盡可能準確的掩碼。
(圖注)實例分割結果。
你可以從上圖中看到,實例分割算法為四位披頭士成員和一些汽車創建掩碼(不過該結果并不完整,尤其是列儂)。
人工執行此類任務的成本很高,而實例分割技術使得此類任務的實現變得簡單。在法國,法律禁止媒體在未經監護人明確同意的情況下暴露兒童形象。使用實例分割技術,可以模糊電視或電影中的兒童面部。
目標追蹤
目標追蹤旨在追蹤隨著時間不斷移動的對象,它使用連續視頻幀作為輸入。該功能對于機器人來說是必要的,以守門員機器人舉例,它們需要執行從追球到擋球等各種任務。目標追蹤對于自動駕駛汽車而言同樣重要,它可以實現高級空間推理和路徑規劃。類似地,目標追蹤在多人追蹤系統中也很有用,包括用于理解用戶行為的系統(如零售店的計算機視覺系統),以及在游戲中監控足球或籃球運動員的系統。
執行目標追蹤的一種相對直接的方式是,對視頻序列中的每張圖像執行目標追蹤并對比每個對象實例,以確定它們的移動軌跡。該方法的缺陷是為每張圖像執行目標檢測通常成本高昂。另一種替換方式僅需捕捉被追蹤對象一次(通常是該對象出現的第一次),然后在不明確識別該對象的情況下在后續圖像中辨別它的移動軌跡。最后,目標追蹤方法未必就能檢測出對象,它可以在不知道追蹤對象是什么的情況下,僅查看目標的移動軌跡。
計算機視覺運行原理
如前所示,計算機視覺的目標是模仿人類視覺系統的工作方式。算法如何實現這一目標呢?本文將介紹其中最重要的幾個概念。
通用策略
深度學習方法和技術深刻改變了計算機視覺以及其他人工智能領域,對于很多任務而言,使用深度學習方法已經成為標準操作。尤其是,卷積神經網絡(CNN)的性能超過了使用傳統計算機視覺技術所能達到的最優結果。
以下四步展示了利用 CNN 構建計算機視覺模型的通用方法:
創建一個包含標注圖像的數據集或者使用現有的數據集。標注可以是圖像類別(適用于分類任務)、邊界框和類別對(適用于目標檢測問題),或者對圖像中每個感興趣對象進行像素級分割(適用于實例分割問題)。
從每張圖像中提取與待處理任務相關的特征,這是建模的重點。例如,用來識別人臉的特征、基于人臉標準的特征與用來識別旅游景點或人體器官的特征存在顯著區別。
基于特征訓練深度學習模型。訓練意味著向機器學習模型輸入很多圖像,然后模型基于特征學習如何解決任務。
使用不同于訓練所用數據的圖像評估模型,從而測試訓練模型的準確率。
該策略非常基礎,但效果不錯。這類方法叫做監督機器學習,它需要包含模型待學習現象的數據集。
現有數據集
構建數據集通常成本高昂,但是它們對于開發計算機視覺應用至關重要。幸運的是,目前有一些現成的數據集。其中規模最大、最著名的是 ImageNet,該數據集包含 1400 萬人工標注圖像。該數據集包含 100 萬張具備邊界框標注的圖像。
另一個著名數據集是 Microsoft Common Objects in Context (COCO) 數據集,它包含 328,000 張圖像、91 個對象類別(這些類別很容易識別,4 歲孩童也可以輕松識別出來),以及 250 萬標注實例。
盡管該領域可用數據集并不是特別多,但仍然有一些適合不同的任務,如 CelebFaces Attributes Dataset(CelebA 數據集,該人臉屬性數據集包含超過 20 萬張名人圖像)、Indoor Scene Recognition 數據集(包含 15,620 張室內場景圖像)、Plant Image Analysis 數據集(包括屬于 11 個不同類別的 100 萬張植物圖像)。
訓練目標檢測模型
Viola–Jones 方法
有很多種方法可以解決目標檢測問題。很多年來,Paul Viola 和 Michael Jones 在論文《Robust Real-time Object Detection》中提出的方法成為流行的方法。
盡管該方法可用來檢測大量對象類別,但它最初是受人臉檢測目標的啟發。該方法快速、直接,是傻瓜相機中所使用的算法,它可以在幾乎不浪費處理能力的情況下執行實時人臉檢測。
該方法的核心特征是:基于哈爾特征與大量二分類器一起訓練。哈爾特征表示邊和線,計算簡單。
盡管比較基礎,但在人臉檢測這一特定案例下,這些特征可以捕捉到重要元素,如鼻子、嘴或眉間距。該監督方法需要很多正類和負類樣本。
檢測蒙娜麗莎的面部。
本文暫不討論算法細節。不過,上圖展示了該算法檢測蒙娜麗莎面部的過程。
基于 CNN 的方法
深度學習變革了機器學習,尤其是計算機視覺。目前基于深度學習的方法已經成為很多計算機視覺任務的前沿技術。
其中,R-CNN 易于理解,其作者提出了一個包含三個階段的流程:
利用區域候選(region proposal)方法提取可能的對象。
使用 CNN 識別每個區域中的特征。
利用支持向量機(SVM)對每個區域進行分類。
該區域候選方法最初由論文《Selective Search for Object Recognition》提出,盡管 R-CNN 算法并不在意使用哪種區域候選方法。步驟 3 非常重要,因為它減少了候選對象的數量,降低了計算成本。
這里提取的特征沒有哈爾特征那么直觀。總之,CNN 可用于從每個區域候選中提取 4096 維的特征向量。鑒于 CNN 的本質,輸入應該具備同樣的維度。這也是 CNN 的弱點之一,很多方法解決了這個問題。回到 R-CNN 方法,訓練好的 CNN 架構要求輸入為 227 × 227 像素的固定區域。由于候選區域的大小各有不同,R-CNN 作者通過扭曲圖像的方式使其維度滿足要求。
滿足 CNN 輸入維度要求的扭曲圖像示例。
盡管該方法取得了很好的結果,但訓練過程中存在一些困難,并且該方法最終被其他方法超越。其中一些方法在這篇文章中有深入介紹:https://tryolabs.com/blog/2017/08/30/object-detection-an-overview-in-the-age-of-deep-learning/。
商業用例
計算機視覺應用被越來越多的公司部署,用于回答業務問題或提升產品性能。它們或許已經成為人們日常生活的一部分,你甚至都沒有注意到它。以下是一些常見的使用案例。
視覺搜索引擎
2001 年,Google Images 的出現意味著視覺搜索技術可被大眾使用。視覺搜索引擎能夠基于特定內容標準檢索圖像。常見用例是搜索關鍵詞,不過有時候我們會提供源圖像,要求引擎找出相似圖像。在某些案例中,可以指定更詳細的搜索條件,如沙灘的圖像、夏天拍攝、至少包含 10 個人。
現在有很多視覺搜索引擎,有的可以網站形式直接使用,有的需要通過 API 調用,有的則是移動應用。
最著名的視覺搜索網站無疑是 Google Images、Bing 和 Yahoo。前兩個網站均可使用多個關鍵詞或者單張圖像作為搜索輸入,以圖像作為搜索輸入又名「反向圖像搜索」(以圖搜圖)。Yahoo 僅支持關鍵詞搜索,搜索結果同樣不錯,如下圖所示。
Yahoo 圖像搜索。
還有一些視覺搜索網站同樣值得關注,如僅支持反向圖像搜索的 TinEye,以及僅支持文本搜索但覆蓋范圍極大的 Picsearch。
在移動應用方面,由于視覺搜索技術逐漸成為標準特征,此類應用之間的區別較大。
此類實現包括 Google Goggles(后被 Google Lens 取代),它可從圖像中獲取詳細信息。例如,從一張貓照片中得到其品種信息,或者提供博物館中藝術作品的信息。
在電商市場中,Pinterest 開發了 Pinterest Lens。如果你需要現有衣物的新穿搭想法,你可以為這件衣服拍張照,之后 Pinterest Lens 會返回穿搭建議,該建議包括你可以購買的搭配單品。近年來,針對網購的視覺搜索成為增長最快的趨勢之一。
最后,視覺搜索的更高階案例是視覺問答系統,參見:https://tryolabs.com/blog/2018/03/01/introduction-to-visual-question-answering/。
Facebook 人臉識別
盡管早在 2000 年代中期,出于自動對焦目的而使用人臉檢測技術的相機已經普遍,但近年來人臉識別領域出現了很多更優秀的成績。最常見(也最具爭議)的應用或許就是識別圖像或視頻中的人物。這通常用于安防系統,但也出現在社交媒體中:人臉管理系統為人臉添加過濾器,以便按人臉執行搜索,甚至在選舉過程中阻止選民多次投票。人臉識別還可用到更復雜的場景,如識別面部表情中的情緒。
其中同時引發了興趣和擔憂的用例是 Facebook 的人臉識別系統。開發團隊的一個主要目標是阻止陌生人使用出現用戶人臉的圖像(見下圖的示例),或者向視障用戶告知圖像或視頻中出現的人物。
除了那些令人擔憂的部分以外,這項技術在很多場景中是有益的,比如對抗網絡騷擾。
Amazon Go
厭倦了超市和雜貨店的排隊等待?Amazon Go 商店提供別樣的體驗。在計算機視覺的幫助下,這里不用排隊,也沒有包裝箱。
其思路很簡單:顧客進入商店,選擇所需商品,離開商店,不用排隊結賬。
這是如何實現的呢?多虧了 Amazon 的「Just Walk Out」技術。顧客必須下載一個移動 app,該 app 可以幫助 Amazon 識別他們的身份。當他們想進入 Amazon Go 商店時,該 app 提供一個二維碼。商店入口處有一些閘機供顧客出入商店,顧客進入商店時,閘機讀取顧客的二維碼。一個有趣的功能是,其他人可以陪伴該顧客一起進入商店,且陪伴者無需安裝該應用程序。
顧客可以在商店內自由移動,而這也是計算機視覺發揮作用之處。商店內安裝有一系列傳感器,包括攝像頭、運動傳感器和商品上的重量傳感器。這些設備收集了每個人的行為信息。它們實時檢測顧客從貨架上拿取的貨品。顧客可以取下某個貨品,改變主意的話再放回去。系統最終會向第一個拿起它的顧客收費,即使它被遞給另一位想要購買的顧客,第一位拿起它的顧客仍然需要支付費用。于是系統創建了一個包含所有拿起貨品的虛擬購物車,并進行實時維護。這使得顧客的購物流程非常順利。
當顧客完成購物,即可走出商店。當他們經過閘機時,系統不會讓顧客掃描貨品或二維碼,而是記錄交易額并向顧客發送確認通知。
Amazon Go 是計算機視覺對現實世界和人類日常生活產生積極影響的一個案例。
特斯拉 Autopilot
讓汽車自動行駛不只是一個遙遠的夢。特斯拉 Autopilot 技術提供非常方便的自動駕駛功能。這并不是全自動駕駛系統,而是可在特定路段上駕駛汽車的駕駛助手。這是特斯拉強調的重點:在所有情況下,控制汽車都是駕駛員的責任。
自動駕駛通過目標檢測和追蹤技術實現。
要想使 Autopilot 工作,特斯拉汽車必須「高度武裝」:八個全景攝像頭提供 250 米范圍內的 360 度圖像、超聲波傳感器用于檢測對象、雷達用來處理周圍環境信息。這樣,特斯拉汽車才能夠根據交通條件調整行駛速度,在遇到障礙物時及時剎車,保持或變換車道,拐彎以及流暢地停車。
特斯拉 Autopilot 技術是計算機視覺對人類日常活動帶來積極影響的另一個精彩案例。
微軟 InnerEye
在醫療行業中,微軟的 InnerEye 是幫助放射科醫生、腫瘤專家和外科醫生處理放射圖像的寶貴工具。其主要目的是從惡性腫瘤的 3D 圖像中準確識別出腫瘤。
癌性腫瘤的 3D 圖像。
基于計算機視覺和機器學習技術,InnerEye 輸出非常詳細的腫瘤 3D 建模圖像。以上截圖展示了 InnerEye 創建的對腦部腫瘤的完整 3D 分割。從上述視頻中,你可以看到專家控制 InnerEye 工具,指引它執行任務,InnerEye 像助手一樣運行。
在放射療法中,InnerEye 結果使得不傷害重要器官直接針對目標腫瘤進行放射成為可能。
這些結果還幫助放射科醫生更好地理解圖像序列,基于腫瘤大小的變化,判斷疾病是否有進一步發展、穩定,或者對治療反應良好。這樣,醫療圖像就成為一種重要的追蹤和衡量方式。
最后,InnerEye 可用于規劃精準手術。
計算機視覺在小公司的應用現狀
計算機視覺在大公司的實現常被大家談論,但這不意味著所有公司必須是谷歌或亞馬遜那種量級才能從該機器學習技術中受益。任何規模的公司都可以利用數據和計算機視覺技術變得更加高效,制定更好的決策。
我們來看一些小公司的現實案例:
Tryolabs 曾幫助一家位于舊金山的小型風險管理公司構建和實現了一個計算機視覺系統,用于擴展對屋頂檢查圖像的處理。
在使用計算機視覺技術之前,公司專家人工分析無人機拍攝的照片,檢測屋頂建設中的損傷。盡管分析結果很準確,但由于服務耗時且人力資源有限,該服務無法得到有效擴展。
為了解決這個問題,我們構建了一個能夠理解圖像并自動識別屋頂問題(如積水、電纜松散和鐵銹)的深度學習系統。為此,我們開發了一個能夠基于屋頂圖像檢測問題的深度神經網絡、分析輸入圖像的流程,以及使檢測結果可用于外部工具的 API。
因此,這家公司的訂單量和收益都有所增長。
如何實現計算機視覺項目
和在組織內值得進行的所有創新一樣,你應該選擇一種有策略的方式來實現計算機視覺項目。
利用計算機視覺技術實現成功創新取決于整體業務策略、資源和數據。
以下問題可以幫助你為計算機視覺項目構建戰略路線圖。
1、計算機視覺解決方案應該降低成本還是增加收益?
成功的計算機視覺項目要么降低成本要么提高收益(或者二者兼顧),你應該定義該項目的目標。只有這樣,它才能對組織及其發展產生重要影響。
2、如何衡量項目的成功?
每個計算機視覺項目都是不同的,你需要定義一個特定于該項目的成功指標。設置好指標后,你應該確保它被業務人員和數據科學家等認可。
3、能否保證信息的獲取?
開啟計算機視覺項目時,數據科學家應該能夠輕松訪問數據。他們需要和來自不同部門(如 IT 部門)的重要同事合作。這些同事應以其業務知識提供支持,內部官僚主義則會成為主要約束。
4、組織收集的數據是否合適?
計算機視覺算法并非魔法。它們需要數據才能運作,輸入數據的質量決定其性能。有多種不同方法和來源可供收集合適數據,這取決于你的目標。無論如何,擁有的輸入數據越多,計算機視覺模型性能優秀的可能性越大。如果你對數據的量和質存在疑慮,你可以請數據科學家幫忙評估數據集質量,必要情況下,找到獲取第三方數據的最優方式。
5. 組織是否以恰當格式收集數據?
除了擁有合適量和類型的數據以外,你還需要確保數據的格式。假設你使用數千張完美的手機照片(分辨率高,背景為白色)訓練目標檢測算法。然后發現算法無法運行,因為實際用例是在不同光照/對比度/背景條件下檢測持有手機的人,而不是檢測手機本身。這樣你之前的數據收集努力基本上就作廢了,你還需要重頭再來。此外,你應該了解,如果數據存在偏見,算法會學到該偏見。
審核編輯:郭婷
-
計算機
+關注
關注
19文章
7430瀏覽量
87732 -
人工智能
+關注
關注
1791文章
46896瀏覽量
237657 -
機器學習
+關注
關注
66文章
8382瀏覽量
132438
發布評論請先 登錄
相關推薦
計算機視覺有哪些優缺點
計算機視覺的五大技術
計算機視覺的工作原理和應用
計算機視覺與人工智能的關系是什么
計算機視覺與智能感知是干嘛的
深度學習在計算機視覺領域的應用
機器視覺與計算機視覺的區別
計算機視覺的主要研究方向
計算機視覺的十大算法


工業視覺與計算機視覺的區別





 工商網監
工商網監
評論