 一種快速的激光視覺慣導融合的slam系統
一種快速的激光視覺慣導融合的slam系統
本文提出了一種快速的激光視覺慣導融合的slam系統,可以分為LIO和VIO兩個緊耦合的子系統。LIO直接把當前的掃描點和增量構建的地圖對齊,地圖點也會輔助基于直接法的VIO系統進行圖像對齊。為了進一步提高vio系統的魯棒性和準確性,作者提出了一種新的方法來剔除邊緣或者在視覺中遮擋的地圖點。
本文方法可以適用于機械雷達和固態雷達,并能實時的ARM和Intel的處理器上運行,作者已經開源了代碼。
代碼地址:https://github.com/hku- mars/FAST- LIVO
本文的主要貢獻有:
一個建立在兩個基于直接法的緊耦合的完整的激光視覺慣導融合的slam框架;
一個直接高效的最大程度重用LIO構建的地圖的VIO框架,具體來說利用地圖點和觀測到的圖像像素塊結合后投影到一個新的圖像上通過最小化光度誤差來得到全部狀態的位姿估計結果。
通過在視覺中使用雷達點云可以避免特征的提取和三角化,同時可以在測量層對視覺和激光雷達進行融合。
開源了這項偉大的工作。
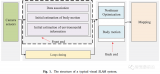
這項工作的系統框架如下所示: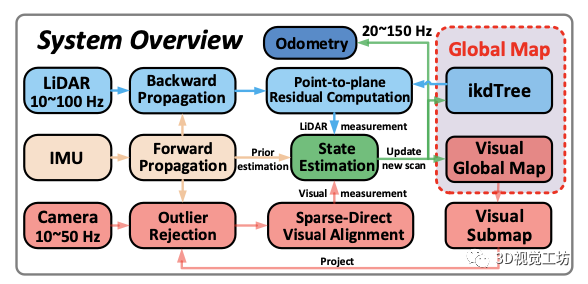
LIO:利用后向遞推的方法剔除點云的運動畸變,利用去畸變的點云基于點到平面的距離進行幀到地圖的匹配。
VIO:視覺基于當前的FOV從全局的視覺地圖中選取當前能觀測到的子地圖并剔除被遮擋和深度不連續的點,然后基于稀疏光流進行幀到地圖點匹配。
最后激光點到平面的殘差和視覺的光度誤差及IMU前向傳播的值放到基于誤差狀態的迭代卡爾曼濾波器中得到準確的位姿,并利用該位姿把新的觀測加到地圖中。
狀態估計: 系統利用緊耦合的ESIKF來進行狀態估計,首選需要知道兩個運算的定義: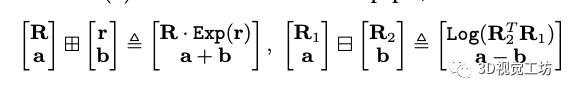
其中Exp和Log表示旋轉矩陣和旋轉向量之間的基于羅德里格斯公式的映射關系。
狀態轉移模型: 在本文的系統中假設激光雷達,相機和imu之間的時間offset是已知的,定義imu的第一幀為全局坐標系,三個傳感器之間固聯且外參已知。第i幀imu在離散模型下的狀態轉移方程為: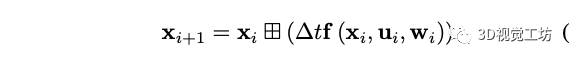
T表示imu采樣的時間間隔,x是狀態,u是輸入,w是噪聲,f的具體形式為: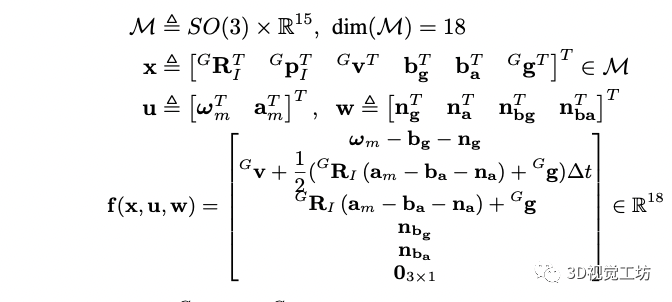
前兩個狀態分別表示imu在全局坐標系下的姿態和平移,最后一個表示重力在全局坐標系下的方向。 前向傳播: 利用前向傳播來得到i+1時刻的狀態和協方差矩陣,具體形式為: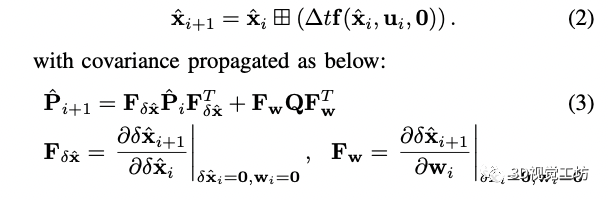
在前向傳播中把噪聲項設置為0,其中Q是噪聲的協方差矩陣。大家應該知道下尖是后驗,就是已經融合了視覺和激光雷達觀測的結果,通過運動方程我們可以得到新的視覺或者激光雷達來的時候的先驗的狀態,然后等激光或者視覺幀來的時候進行對應的量測更新。
(這里多說一點,在做自動駕駛的時候,由于觀測后的補償量可能較大導致位姿產生小范圍的跳變,所以我們一般都會把大的補償量分成小的補償量進行補償,雖然這種做法不嚴密但是能保證位姿的平滑性,大家也可以想想有什么更好的辦法)。
幀到地圖的量測更新:
激光雷達的測量模型:
新的激光幀來之后首先進行點云運動畸變矯正,當進行幀到地圖匹配到時候我們假設新觀測的點在和他近鄰的地圖中的平面上(用方向向量和中心點表示),如果先驗的位姿是準的可以得到如下約束: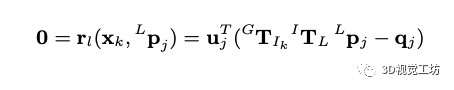
這個約束是把當前的點利用先驗的位姿投影到地圖上,找到最近的平面后投影點應該在平面上,所以兩個點相減得到的向量為平面上的向量,和平面的法向量垂直,點乘為0。
實際上,為了找到距離該點最近的平面,利用先驗的位姿把點投影到地圖中找到距離該投影點最近的五個點(地圖點是用ikd_tree維護的)來擬合平面,為了考慮雷達點的測量噪聲,會加上一個矩陣表示每個點的權重。
2.視覺的測量模型:
當接收到一幀新的圖像,我們從全局的視覺地圖中提取落在當前視野內的地圖點。對于地圖中的點,已經被先前的幀觀測過很多次,我們找到和當前觀測角度相近的一幀作為參考幀,然后把地圖點投影到當前幀獲取地圖點的光度值,應該和參考幀中的patch獲取的光度值一樣,以此構建殘差: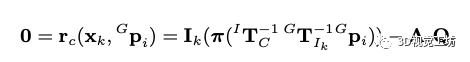
預印版沒有解釋A,我猜測因為是像素塊進行光度匹配,所以A矩陣是權重矩陣,patch中心點權重高,周圍點權重低,大家可以看代碼驗證一下。 基于迭代的卡爾曼濾波器更新:?通過公式3我們可以得到先驗的狀態和協方差的值,先驗的分布可以表示為: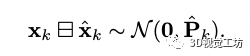
當視覺和激光的觀測來的時候我們可以進行量測更新以得到狀態量后驗的結果: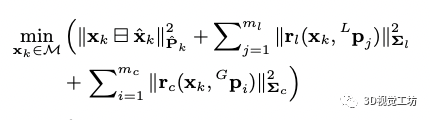
上式為非凸的函數,可以基于高斯牛頓的方法優化求解最小值,但是高斯牛頓和基于迭代的卡爾曼濾波器是等價的,參考文獻的21有證明。為了保證流型的約束,在每次迭代的時候,都把誤差狀態參數化到切空間中(通過第一個公式定義的方法),得到的誤差狀態更新到狀態量然后進行下次迭代直到收斂,收斂的狀態和協方差用于imu的前向遞推,也用于視覺地圖和激光雷達地圖點增量更新。
地圖管理: 地圖主要有LIO構建的雷達點云圖和VIO構建的用patchs表示的視覺全局地圖。
1.雷達地圖管理: 激光雷達點云圖的管理和FAST-LIO2一致,利用ikd_tree進行管理,ikd_tree提供了一些查詢、插入和刪除的接口,還可以根據配置參數下采樣地圖,同時新幀來的時候基于kd_tree的數據結構可以大大縮短最近點查找的時間(基于并行化加速后,2000個點大概0.6ms)。
2.視覺全局地圖管理: 視覺的全局地圖是原來觀測過的雷達點云的集合,每個雷達點都對應著多個觀測到這個激光點點視覺幀到多個像素塊。
視覺全局地圖的數據結構和更新的方法如下: 數據結構:為了快速找到落在當前視野內的地圖點,我們利用體素保存視覺全局地圖。
體素通過哈希表來管理,每個體素中保存點的位置,多個觀測到該點的像素的patch的金字塔和每個patch金字塔的相機位姿。
視覺的子地圖和外點剔除:即使體素的數量比視覺地圖定的數量少的多,但是確定他們中的哪些在當前的視野中仍然非常耗時,尤其是體素數量很大時。為了解決這個問題,作者針對最近的雷達掃描的每個點基于哈希表查找這些體素。如果相機FoV和雷達大致對齊,則落在相機FoV中的地圖點很可能包含在這些體素中。
因此,視覺子圖可以通過這些體素包含的點進行FoV檢查獲得。 視覺子圖可能包含在當前的圖像幀中被遮擋或具有不連續深度的地圖點,這會降低VIO的精度。為了解決這個問題,作者基于當前的狀態量將視覺子圖中的所有點投影到當前幀并在每個40x40的像素網格中保留深度最小的點。
此外,作者將當前幀雷達掃描點投影到當前幀,并檢查他們的深度來檢查他們是否遮擋了投影到9x9領域內的其他地圖點。被遮擋的點也會被剔除。 視覺子地圖更新:在對齊新的圖像幀后,我們將當前圖像中的patch附加到FoV內的地圖點中,這樣地圖點就可能具有均勻分布視角的有效patch。
具體而言,作者在幀對齊后選擇具有高光度誤差的patch,如果距離上次添加patch超過20幀,或者當前幀中patch距離上次添加了patch的參考幀中的像素位置超過40像素,則將向地圖點中添加新的patch。從當前圖像中提取新的大小為8×8像素。并構建金字塔,并保存相機的位姿。
除了向地圖點添加patch之外,還需要向視覺全局地圖添加新的地圖點。為此作者將當前圖像分成40×40像素的網格,并在其上投影最近一次激光雷達掃描中的點。每個網格中具有最高梯度的投影激光雷達點將添加到視覺全局地圖中,以及在其中提取的patch和相機位姿。為了避免將邊緣上的激光雷達點添加到視覺地圖中,跳過了具有高局部曲率的邊緣點。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19178瀏覽量
229200 -
SLAM
+關注
關注
23文章
419瀏覽量
31789 -
激光視覺
+關注
關注
0文章
7瀏覽量
6023
原文標題:激光視覺慣導融合的slam系統
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
激光雷達在SLAM算法中的應用綜述
MG-SLAM:融合結構化線特征優化高斯SLAM算法

現代海上的電子指南針——艦艇慣導系統
一種完全分布式的點線協同視覺慣性導航系統
激光焊接視覺定位引導方法

一種新型光電吊艙用航姿測量系統
導遠科技首次公開展示其自主研發的新一代MEMS慣導芯片


激光焊接機在焊接醫療斑馬導絲的技術應用

基于濾波器的激光SLAM方案
深度解析:多傳感器融合SLAM技術全景剖析

GNSS模塊的慣導技術:引領定位科技的前沿
基于視覺SLAM的研究現狀





 工商網監
工商網監
評論