 簡單總結幾種NLP常用的對抗訓練方法
簡單總結幾種NLP常用的對抗訓練方法
對抗訓練本質是為了提高模型的魯棒性,一般情況下在傳統訓練的基礎上,添加了對抗訓練是可以進一步提升效果的,在比賽打榜、調參時是非常重要的一個trick。對抗訓練在CV領域內非常常用,那么在NLP領域如何使用呢?本文簡單總結幾種常用的對抗訓練方法。
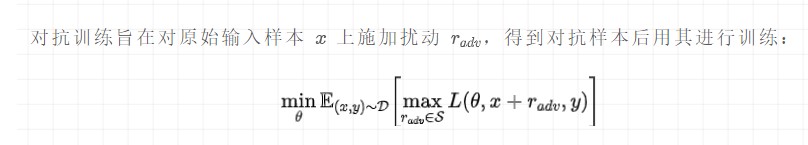
公式理解:
最大化擾動:挑選一個能使得模型產生更大損失(梯度較大)的擾動量,作為攻擊;
最小化損失:根據最大的擾動量,添加到輸入樣本后,朝著最小化含有擾動的損失(梯度下降)方向更新參數;
這個被構造出來的“對抗樣本”并不能具體對應到某個單詞,因此,反過來在推理階段是沒有辦法通過修改原始輸入得到這樣的對抗樣本。
對抗訓練有兩個作用,一是 提高模型對惡意攻擊的魯棒性 ,二是 提高模型的泛化能力 。
在CV任務,根據經驗性的結論,對抗訓練往往會使得模型在非對抗樣本上的表現變差,然而神奇的是,在NLP任務中,模型的泛化能力反而變強了。
常用的幾種對抗訓練方法有FGSM、FGM、PGD、FreeAT、YOPO、FreeLB、SMART。本文暫時只介紹博主常用的3個方法,分別是 FGM 、 PGD 和 FreeLB 。
具體實現時,不同的對抗方法會有差異,但是 從訓練速度和代碼編輯難易程度的角度考慮,推薦使用FGM和迭代次數較少的PGD 。
一、FGM算法

FGM的代碼量很少,只需要自行實現簡單的類即可:
importtorch classFGM(): def__init__(self,model): self.model=model self.backup={}#用于保存模型擾動前的參數 defattack( self, epsilon=1., emb_name='word_embeddings'#emb_name表示模型中embedding的參數名 ): ''' 生成擾動和對抗樣本 ''' forname,paraminself.model.named_parameters():#遍歷模型的所有參數 ifparam.requires_gradandemb_nameinname:#只取wordembedding層的參數 self.backup[name]=param.data.clone()#保存參數值 norm=torch.norm(param.grad)#對參數梯度進行二范式歸一化 ifnorm!=0andnottorch.isnan(norm):#計算擾動,并在輸入參數值上添加擾動 r_at=epsilon*param.grad/norm param.data.add_(r_at) defrestore( self, emb_name='word_embeddings'#emb_name表示模型中embedding的參數名 ): ''' 恢復添加擾動的參數 ''' forname,paraminself.model.named_parameters():#遍歷模型的所有參數 ifparam.requires_gradandemb_nameinname:#只取wordembedding層的參數 assertnameinself.backup param.data=self.backup[name]#重新加載保存的參數值 self.backup={}
在訓練時,只需要額外添加5行代碼:
fgm=FGM(model)#(#1)初始化 forbatch_input,batch_labelindata: loss=model(batch_input,batch_label)#正常訓練 loss.backward()#反向傳播,得到正常的grad #對抗訓練 fgm.attack()#(#2)在embedding上添加對抗擾動 loss_adv=model(batch_input,batch_label)#(#3)計算含有擾動的對抗樣本的loss loss_adv.backward()#(#4)反向傳播,并在正常的grad基礎上,累加對抗訓練的梯度 fgm.restore()#(#5)恢復embedding參數 #梯度下降,更新參數 optimizer.step() model.zero_grad()
二、PGD算法
Project Gradient Descent(PGD)是一種迭代攻擊算法,相比于普通的FGM 僅做一次迭代,PGD是做多次迭代,每次走一小步,每次迭代都會將擾動投射到規定范圍內。形式化描述為:

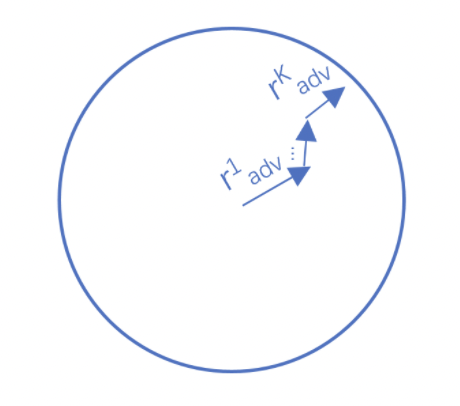
代碼實現如下所示:
importtorch classPGD(): def__init__(self,model): self.model=model self.emb_backup={} self.grad_backup={} defattack(self,epsilon=1.,alpha=0.3,emb_name='word_embeddings',is_first_attack=False): forname,paraminself.model.named_parameters(): ifparam.requires_gradandemb_nameinname: ifis_first_attack: self.emb_backup[name]=param.data.clone() norm=torch.norm(param.grad) ifnorm!=0andnottorch.isnan(norm): r_at=alpha*param.grad/norm param.data.add_(r_at) param.data=self.project(name,param.data,epsilon) defrestore(self,emb_name='word_embeddings'): forname,paraminself.model.named_parameters(): ifparam.requires_gradandemb_nameinname: assertnameinself.emb_backup param.data=self.emb_backup[name] self.emb_backup={} defproject(self,param_name,param_data,epsilon): r=param_data-self.emb_backup[param_name] iftorch.norm(r)>epsilon: r=epsilon*r/torch.norm(r) returnself.emb_backup[param_name]+r defbackup_grad(self): forname,paraminself.model.named_parameters(): ifparam.requires_grad: self.grad_backup[name]=param.grad.clone() defrestore_grad(self): forname,paraminself.model.named_parameters(): ifparam.requires_grad: param.grad=self.grad_backup[name]
pgd=PGD(model) K=3 forbatch_input,batch_labelindata: #正常訓練 loss=model(batch_input,batch_label) loss.backward()#反向傳播,得到正常的grad pgd.backup_grad() #累積多次對抗訓練——每次生成對抗樣本后,進行一次對抗訓練,并不斷累積梯度 fortinrange(K): pgd.attack(is_first_attack=(t==0))#在embedding上添加對抗擾動,firstattack時備份param.data ift!=K-1: model.zero_grad() else: pgd.restore_grad() loss_adv=model(batch_input,batch_label) loss_adv.backward()#反向傳播,并在正常的grad基礎上,累加對抗訓練的梯度 pgd.restore()#恢復embedding參數 #梯度下降,更新參數 optimizer.step() model.zero_grad()
三、FreeLB算法


很明顯找到FreeLB與PGD的區別在于累積的方式:
FreeLB:通過對 K K K 次梯度的平均累積作為擾動更新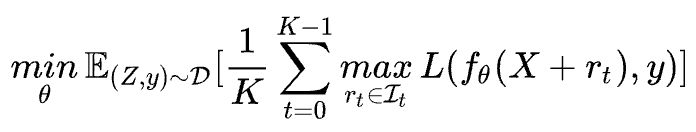
PGD:只取最后一次的梯度進行更新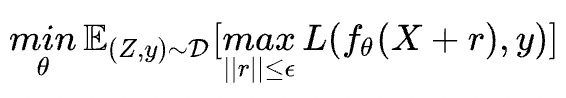
實現流程如下圖所示: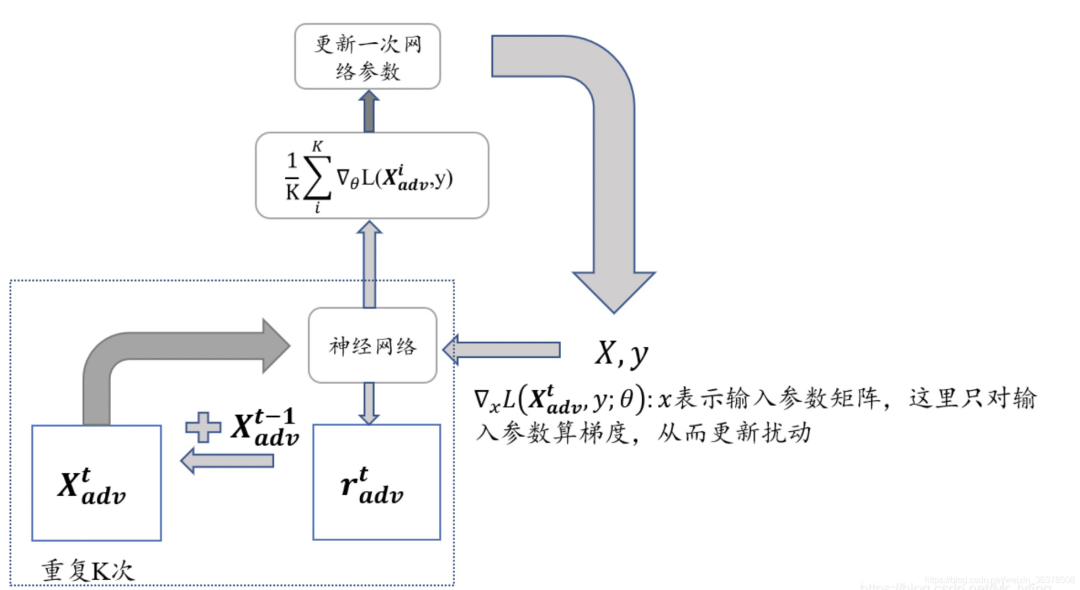
審核編輯:劉清
-
算法
+關注
關注
23文章
4600瀏覽量
92646 -
nlp
+關注
關注
1文章
487瀏覽量
22012
原文標題:煉丹之道 | NLP中的對抗訓練
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
微軟在ICML 2019上提出了一個全新的通用預訓練方法MASS

新的預訓練方法——MASS!MASS預訓練幾大優勢!

關于語言模型和對抗訓練的工作

NLP中的對抗訓練到底是什么
總結幾種常用的單片機加密方法

時識科技提出新脈沖神經網絡訓練方法 助推類腦智能產業落地
幾種常用的NLP數據增強方法
混合專家模型 (MoE)核心組件和訓練方法介紹





 工商網監
工商網監
評論