 聊一聊互聯網三高架構中的系統穩定性
聊一聊互聯網三高架構中的系統穩定性
一、前言
高并發、高可用、高性能被稱為互聯網三高架構,這三者都是工程師和架構師在系統架構設計中必須考慮的因素之一。今天我們就來聊一聊三H中的高可用,也是我們常說的系統穩定性。
本篇文章只聊思路,沒有太多的深入細節。閱讀全文大概需要5~10分鐘。
二、高可用的定義
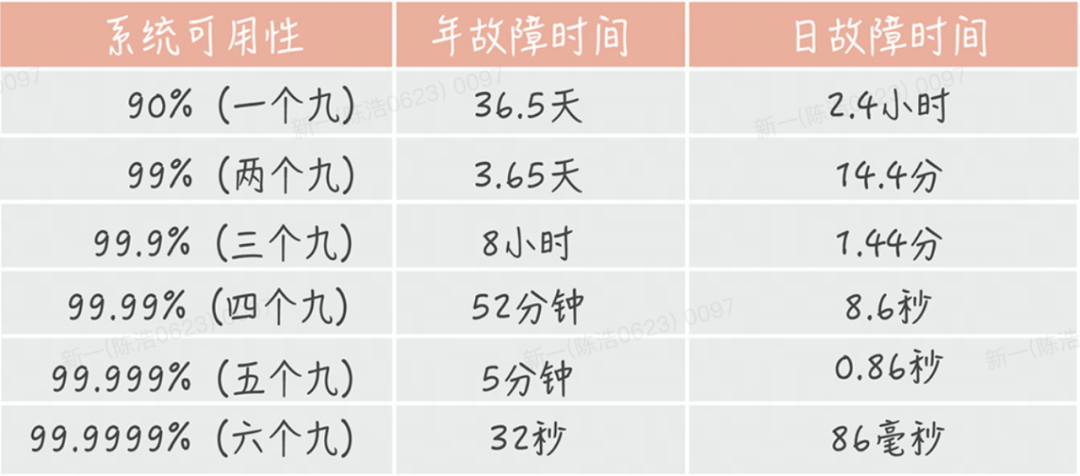
業界常用 N 個 9 來量化一個系統可用性程度,可以直接映射到網站正常運行時間的百分比上。
可用性的計算公式:
 ?
?
大部分公司的要求是4個9,也就是年度宕機時長不能超過53分鐘,實際要達到這個目標還是非常困難的,需要各個子模塊相互配合。
要想提升一個系統的可用性,首先需要知道影響系統穩定性的因素有哪些。
三、影響穩定性的因素
首先我們先梳理一下影響系統穩定性的一些常見的問題場景,大致可分為三類:
人為因素
不合理的變更、外部攻擊等等
軟件因素
代碼bug、設計漏洞、GC問題、線程池異常、上下游異常
硬件因素
網絡故障、機器故障等 下面就是對癥下藥,首先是故障前的預防,其次是故障后的快速恢復能力,下面我們就聊聊幾種常見的解決思路。
四、提升穩定性的幾種思路
4.1 系統拆分
拆分不是以減少不可用時間為目的,而是以減少故障影響面為目的。因為一個大的系統拆分成了幾個小的獨立模塊,一個模塊出了問題不會影響到其他的模塊,從而降低故障的影響面。系統拆分又包括接入層拆分、服務拆分、數據庫拆分。
接入層&服務層
一般是按照業務模塊、重要程度、變更頻次等維度拆分。
數據層
一般先按照業務拆分后,如果有需要還可以做垂直拆分也就是數據分片、讀寫分離、數據冷熱分離等。
4.2 解耦
系統進行拆分之后,會分成多個模塊。模塊之間的依賴有強弱之分。如果是強依賴的,那么如果依賴方出問題了,也會受到牽連出問題。這時可以梳理整個流程的調用關系,做成弱依賴調用。弱依賴調用可以用MQ的方式來實現解耦。即使下游出現問題,也不會影響當前模塊。
4.3 技術選型
可以在適用性、優缺點、產品口碑、社區活躍度、實戰案例、擴展性等多個方面進行全量評估,挑選出適合當前業務場景的中間件&數據庫。前期的調研一定要充分,先對比、測試、研究,再決定,磨刀不誤砍柴工。
4.4 冗余部署&故障自動轉移
服務層的冗余部署很好理解,一個服務部署多個節點,有了冗余之后還不夠,每次出現故障需要人工介入恢復勢必會增加系統的不可服務時間。
所以,又往往是通過“自動故障轉移”來實現系統的高可用。即某個節點宕機后需要能自動摘除上游流量,這些能力基本上都可以通過負載均衡的探活機制來實現。
涉及到數據層就比較復雜了,但是一般都有成熟的方案可以做參考。一般分為一主一從、一主多從、多主多從。不過大致的原理都是數據同步實現多從,數據分片實現多主,故障轉移時都是通過選舉算法選出新的主節點后在對外提供服務(這里如果寫入的時候不做強一致同步,故障轉移時會丟失一部分數據)。具體可以參考Redis Cluster、ZK、Kafka等集群架構。
4.5 容量評估
在系統上線前需要對整個服務用到的機器、DB、cache都要做容量評估,機器容量的容量可以采用以下方式評估:
明確預期流量指標-QPS;
明確可接受的時延和安全水位指標(比如CPU%≤40%,核心鏈路RT≤50ms);
通過壓測評估單機在安全水位以下能支持的最高QPS(建議通過混合場景來驗證,比如按照預估流量配比同時壓測多個核心接口);
最后就可以估算出具體的機器數量了。
DB和cache評估除了QPS之外還需要評估數據量,方法大致相同,等到系統上線后就可以根據監控指標做擴縮容了。
4.6 服務快速擴容能力&泄洪能力
現階段不論是容器還是ECS,單純的節點復制擴容是很容易的,擴容的重點需要評估的是服務本身是不是無狀態的,比如:
下游DB的連接數最多支持當前服務擴容幾臺?
擴容后緩存是否需要預熱?
放量策略
這些因素都是需要提前做好準備,整理出完備的SOP文檔,當然最好的方式是進行演練,實際上手操作,有備無患。
泄洪能力一般是指冗余部署的情況下,選擇幾個節點作為備用節點,平時承擔很小一部分流量,當流量洪峰來臨時,通過調整流量路由策略把熱節點的一部分流量轉移到備用節點上。
對比擴容方案這種成本相對較高,但是好處就是響應快,風險小。
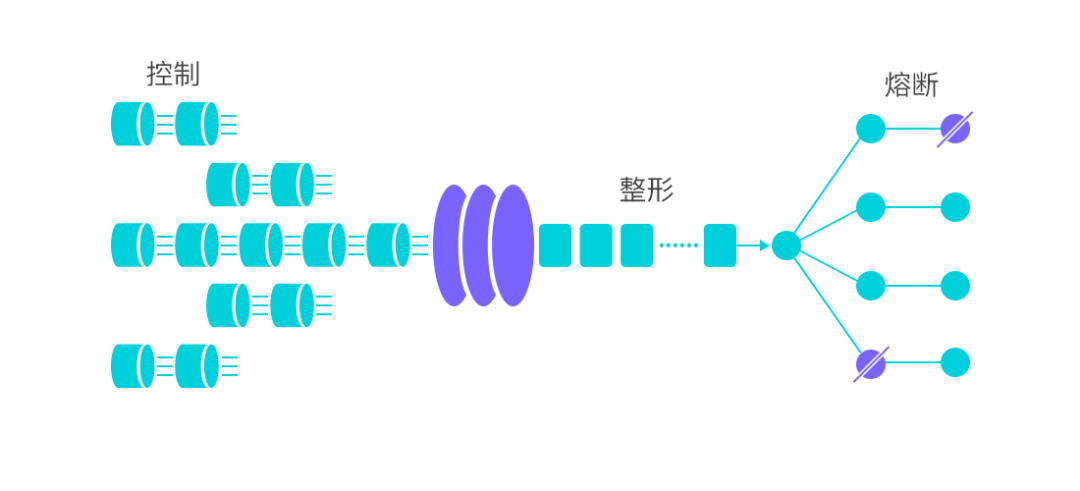
4.7 流量整形&熔斷降級
 ?
?
流量整形也就是常說的限流,主要是防止超過預期外的流量把服務打垮,熔斷則是為了自身組件或者依賴下游故障時,可以快速失敗防止長期阻塞導致雪崩。
關于限流熔斷的能力,開源組件Sentinel基本上都具備了,用起來也很簡單方便,但是有一些點需要注意。
限流閾值一般是配置為服務的某個資源能支撐的最高水位,這個需要通過壓測摸底來評估。隨著系統的迭代,這個值可能是需要持續調整的。如果配置的過高,會導致系統崩潰時還沒觸發保護,配置的過低會導致誤傷。
熔斷降級-某個接口或者某個資源熔斷后,要根據業務場景跟熔斷資源的重要程度來評估應該拋出異常還是返回一個兜底結果。
比如下單場景如果扣減庫存接口發生熔斷,由于扣減庫存在下單接口是必要條件,所以熔斷后只能拋出異常讓整個鏈路失敗回滾,如果是獲取商品評論相關的接口發生熔斷,那么可以選擇返回一個空,不影響整個鏈路。
4.8資源隔離
如果一個服務的多個下游同時出現阻塞,單個下游接口一直達不到熔斷標準(比如異常比例跟慢請求比例沒達到閾值),那么將會導致整個服務的吞吐量下降和更多的線程數占用,極端情況下甚至導致線程池耗盡。引入資源隔離后,可以限制單個下游接口可使用的最大線程資源,確保在未熔斷前盡可能小的影響整個服務的吞吐量。
說到隔離機制,這里可以擴展說一下,由于每個接口的流量跟RT都不一樣,很難去設置一個比較合理的可用最大線程數,并且隨著業務迭代,這個閾值也難以維護。這里可以采用共享加獨占來解決這個問題,每個接口有自己的獨占線程資源,當獨占資源占滿后,使用共享資源,共享池在達到一定水位后,強制使用獨占資源,排隊等待。這種機制優點比較明顯就是可以在資源利用最大化的同時保證隔離性。
這里的線程數只是資源的一種,資源也可以是連接數、內存等等。
4.9系統性保護

系統性保護是一種無差別限流,一句話概念就是在系統快要崩潰之前對所有流量入口進行無差別限流,當系統恢復到健康水位后停止限流。具體一點就是結合應用的 Load、總體平均 RT、入口 QPS 和線程數等幾個維度的監控指標,讓系統的入口流量和系統的負載達到一個平衡,讓系統盡可能跑在最大吞吐量的同時保證系統整體的穩定性。
4.10 可觀測性&告警
 ?
?
當系統出現故障時,我們首先需找到故障的原因,然后才是解決問題,最后讓系統恢復。排障的速度很大程度上決定了整個故障恢復的時長,而可觀測性的最大價值在于快速排障。其次基于Metrics、Traces、Logs三大支柱配置告警規則,可以提前發現系統可能存在的風險&問題,避免故障的發生。
4.11 變更流程三板斧
變更是可用性最大的敵人,99%的故障都是來自于變更,可能是配置變更,代碼變更,機器變更等等。那么如何減少變更帶來的故障呢?
可灰度
用小比例的一部分流量來驗證變更后的內容,減小影響用戶群。
可回滾
出現問題后,能有有效的回滾機制。涉及到數據修改的,發布后會引起臟數據的寫入,需要有可靠的回滾流程,保證臟數據的清除。
可觀測
通過觀察變更前后的指標變化,很大程度上可以提前發現問題。 除了以上三板斧外,還應該在其他開發流程上做規范,比如代碼控制,集成編譯、自動化測試、靜態代碼掃描等。
五、總結
對于一個動態演進的系統而言,我們沒有辦法將故障發生的概率降為0,能做的只有盡可能的預防和縮短故障時的恢復時間。當然我們也不用一味的追求可用性,畢竟提升穩定性的同時,維護成本、機器成本等也會跟著上漲,所以需要結合系統的業務SLO要求,適合的才是最好的。
如何做好穩定性和高可用保障是一個很龐大的命題,本篇文章沒有太多的深入細節,只聊了整體的一些思路,主要是為了大家在以后的系統高可用建設過程中,有一套系統的框架可以參考。最后感謝耐心看完的同學。
審核編輯:劉清
-
互聯網
+關注
關注
54文章
11107瀏覽量
103019 -
數據庫
+關注
關注
7文章
3766瀏覽量
64277 -
QPS
+關注
關注
0文章
24瀏覽量
8788 -
ECS
+關注
關注
0文章
48瀏覽量
20101
原文標題:淺談系統穩定性與高可用保障的幾種思路
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
聯想將進軍互聯網
工業互聯網
工業互聯網
互聯網與工業物聯網之間的區別與聯系
什么是產業互聯網?
來聊一聊Altium中Fill,Polygon Pour,Plane的區別和用法
聊一聊stm32的低功耗調試

如何保證備自投裝置可靠性和穩定性






 工商網監
工商網監
評論