 Wishbone II交易總線:速度的另一個等級
Wishbone II交易總線:速度的另一個等級
OpenCore和Silicore的Wishbone規范,旨在提供標準的IP核互連方案,以滿足現代片上系統(SoC)設計的要求,包括CPU,DMA引擎,內存接口,外設接口等。
andEuros公司自成立以來一直使用Wishbone規范,并開發了Wishbone總線的改進版本,稱為Wishbone II,以提出一種先進的流水線架構,其中讀寫事務是分開的,總線充當事務總線。通過這種方式,可以同時進行多個事務,通過采用新的每單元鎖定概念,消除路徑上的所有延遲并停止 RMW 周期。當然,最終的好處是最終總線吞吐量已增加到最大。
大規模FPGA/ASIC SoC設計的設計和開發迫使設計人員實現具有標準化模塊接口的模塊化架構,該接口以任何可能的配置連接各種IP模塊。OpenCores發布了最流行的互連架構之一,稱為Wishbone B.3總線。以類似的方式,Altera引入了自己的互連方案,稱為Avalon Bus,SOPC Builder和Nios(II)系統就是圍繞該方案制造的。Xilinx 還推出了自己的總線,稱為片上外設總線與處理器本地總線 相結合。
這些互連架構是面向單事務主/從的,這意味著只要沒有收到該字,從給定地址請求單詞的 CPU 就會停止自身和到目標的路徑(總線)。以這種方式丟失了大量總線周期,盡管系統總線頻率相對較高,但實際數據吞吐量仍低于預期。即使特殊信號引入了快速突發讀取和寫入,總線周期仍然會丟失,直到接收到第一個字,代價是源和目標兩端的突發邏輯加倍。當訪問具有較大延遲的較慢模塊時,總線停滯更為明顯。在這些情況下,系統性能會顯著下降;例如,100 MHz 系統的吞吐量可能會下降到每秒幾 MB。
這就是為什么迫切需要開發采用新概念的總線架構的原因。引入了一些新信號來支持基于 Wishbone B.3 架構的新事務總線概念,克服了延遲問題,同時保持了向后兼容性。
叉骨II交易總線概念
在我們提議的總線中,交易由一個交易向量表示,其中包含:
源(模塊)地址
目標(模塊)地址
算子
數據
源地址和目標地址定義路徑;操作員描述要沿路徑和/或目標地址執行的一個或多個操作;某些操作需要提供補充數據才能完成交易。實際實現需要額外的握手信號。
事務向量被放置在事務總線上,將向量從源傳輸到目標,并根據向量的請求執行面向總線的操作。一旦事務向量被放置(發送),源就沒有進一步的責任,事務總線將完全控制它。然后,源已準備好發出下一個事務向量。可以事先發出多個任務或請求,每個總線周期一個,這減少了目標模塊上任何預測邏輯的需求,以支持突發讀取或寫入作為各種突發讀取的預測邏輯。
有兩種類型的事務:
獨立
依賴(當它們的順序很重要時)
為了支持依賴事務,事務總線絕不能更改已放置事務的順序。事務總線具有完全確認的機制,用于接受新的事務向量、執行內部轉發并傳遞到目標模塊。透明架構將自身反映為一個簡單的輸入輸出黑匣子;但是,該實現基于多管道結構,其中每個 (FIFO) 行包含一個事務向量。
Wishbone II 事務總線僅提供四種基本操作:
單次讀取
單次寫入
細胞鎖
總線鎖
單次讀取和寫入由模塊發出,其中單元和總線鎖定操作位于事務總線域中。突發讀取和突發寫入是通過發出讀取或寫入事務流來完成的。RMW周期通過總線得到支持,甚至更好的是,可以使用新的單元鎖定概念來促進它們,該概念不會使整個SoC總線停滯,而是將單個或多個存儲單元鎖定到給定的所有者。只要未解鎖,其他人就無法訪問這些單元格。
叉骨II信號
Wishbone II 事務向量由 Wishbone B.3 規范組成,引入了以下新信號:
WB_ACW寫入確認
WB_ACR閱讀致謝
WB_TGA雙向地址標簽
WB_ALK地址鎖
在進一步的文本中,前綴WB可以更改為WBM表示主接口,WBS表示從接口,也可以留空以描述任何主接口或從接口。輸入信號附加在末尾_I,輸出信號帶有_O。建議的總線丟棄了Wishbone B.3 ACK信號,因為它的功能現在在ACR和ACW信號之間分配。表1列出了主機和從站的完整基本信號說明。新信號以粗體標記。
叉骨二期巴士交易
寫入事務
寫入事務幾乎與 Wishbone B.3 規范中給出的寫入事務相同,除了 Wishbone II 使用 ACW 信號來確認寫入周期。讀寫事務由與寫入事務相同的讀取請求組成,只是設置了目標操作信號 WE。
讀取事務
讀取事務由兩個事務組成:
源發出的讀取請求事務
目標發出的讀取響應事務
讀取請求由表示源的主模塊發送,方法是首先發出一個寫入事務,并將目標操作 WE 設置為讀取。主機應設置地址標記寫入向量以識別讀取響應。(如果只有一個主控形狀,則不需要這樣做。讀取請求事務的確認方式與寫入事務相同。
目標通過返回由確認信號 ACR 標記的單獨讀取響應事務并提供有效數據和地址標記讀取信息來完成事務。地址標記讀取是地址標記寫入的副本。
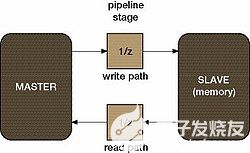
圖1顯示了一個示例系統,在源(主)和目標(從)設備之間的寫入(輸入)和讀取(輸出)路徑上有一個流水線級。該系統在兩個方向上都有 1 個循環方向;因此,請求-響應循環至少需要 2 個等待周期。從屬(內存)還可以執行一些內部管理,如刷新,這增加了等待狀態的總數。
圖1
您可以看到,圖 2 描述了給定示例的事務總線數據流圖,其中主站放置的三個讀取請求事務為 AD0、AD1 和 AD2,以及關聯的返回讀取響應事務為 DO0、DO1 和 DO2。假設所有三個事務的信號 WE 都被清除,以指示讀取操作。事務 AD0 和 AD1 是突發事務,這意味著 AD1 = AD0 + 1,而 AD2 是同時觸發的獨立事務,可能是加載其中斷向量的外部中斷的原因,依此類推。
圖2
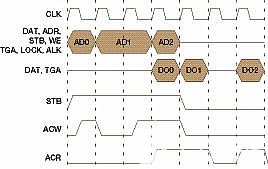
每個讀取請求事務由 ACW 信號確認,返回的讀取響應事務由 ACR 信號標記(確認)。請注意,由于其他更高優先級的主節點或內存刷新函數等原因,延遲順序可能不同。在前面的示例中,AD0 會立即得到確認,但需要 3 個等待周期才能返回 DO0;AD1 在 1 個周期后得到確認,而 DO1 僅在 2 個等待周期內返回,DO2 再次需要 3 個等待周期。所有三筆交易都在 9 個周期內完成;理論上,如果不添加兩個說明性等待周期,它們只會在 7 個周期內完成。使用 Wishbone B.3 規范時,圖 3 顯示了相同的場景。
圖3
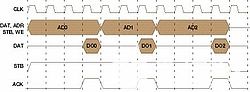
AD0和AD1再次為突發,AD1 = AD0 + 1,AD2為獨立請求。所有三個事務都在 12 個周期內完成,性能降低了 41%(在 Wishbone II 中至少 7 個周期),即使額外的硅成本,這是源和目標兩端的內存突發邏輯實現。
想象一下,當系統中共存多個主站以發出第一個單詞時,連續突發 Wishbone II 將在從屬端執行 0 個等待周期(完全消除延遲)并且絕對沒有損失(再次是 0 個等待周期)。對于以 150 MHz 運行的系統來說,更能說明問題,固定延遲為 2 個周期的長突發將產生 150 M 字的 Wishbone II 帶寬,而 Wishbone B.3 僅產生 50 Mwords 的帶寬。
讀寫周期和專用總線/地址鎖定
可以使用總線 LOCK 信號進行讀-修改-寫循環,方法是發出讀取請求和 LOCK 信號集,等待讀取響應,然后進行寫入,最后釋放 LOCK。為了不使整個總線失速,Wishbone II 引入了使用 ALK 信號的每單元內存鎖定功能,該功能的使用方式與 Wishbone LOCK 信號幾乎相同,只是它不會停止整個總線,而是授予對由源 TGA 區分的給定模塊的獨占權限。
叉骨II駛向未來
Wishbone II 總線為 FPGA 和 ASIC 的 SoC 設計提出了一種面向事務總線的高級架構,其中架構寫入和讀取操作作為單獨的寫入和讀取事務處理。每個事務都存儲在一行中,多管道架構充當 FIFO 緩沖區,從多個源模塊和目標模塊傳輸多個事務。先進的鎖定機制使用臨時的每單元鎖定機制,防止整個總線因 RMW 周期而失速。通過這種方式,整體設計數據吞吐量提高到最大,同時設計成功集成了慢速和高速、低延遲和高延遲外設和 CPU。
審核編輯:郭婷
-
接口
+關注
關注
33文章
8504瀏覽量
150843 -
soc
+關注
關注
38文章
4122瀏覽量
217951 -
總線
+關注
關注
10文章
2868瀏覽量
87993
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論