 一種基于深度注意力感知特征的視覺定位框架
一種基于深度注意力感知特征的視覺定位框架
0.筆者個人體會:
這個工作來自于Baidu ADT部門,是該團隊繼L3-Net之后的在自動駕駛領域內關于定位的又一力作,其利用圖像數據取得了與基于Lidar的方法相當的定位精度。 其突出的優勢在于:
1.該方法達到了極高的精度。即使是在訓練以及建圖是用到了激光雷達(點云數據),但在實際線上使用時,只用了圖像數據。在這種設置下,本方法大大節省了實際使用時的成本,并達到了厘米級別的精度。
2.該方法繼承了L3-Net在求解位姿時的做法,即基于Cost volume求解位姿修正量。這種設置可以滿足端到端訓練的需求,并在某種程度上等價于對候選的位姿進行遍歷對比,求解了一定范圍內的最優解。
3.該方法的時間效率可控。隨著選擇較少的關鍵點數量,該方法可以達到極高的時間效率。
但此方法也有一定的不足,即該方法嚴重依賴于給定初始預測位姿的精度。基于Cost volume的定位本質上是在候選位姿集合上做一個遍歷,選擇其中的最優解。
但如果給定的初始預測位姿精度不夠時,所有候選位姿的精度都有限,即無法得到一個精度較高的定位結果。這個問題可能為實際使用帶來一定的局限性。
1、論文相關內容介紹:
摘要:針對自動駕駛應用領域,本文提出了一種基于深度注意力感知特征的視覺定位框架,該框架可達到厘米級的定位精度。傳統的視覺定位方法依賴于手工制作的特征或道路上的人造物體。然而,它們要么容易由于嚴重的外觀或光照變化而導致不穩定的匹配,要么太過稀少,無法在具有挑戰性的場景中提供穩定和魯棒的定位結果。
在這項工作中,本文利用深度注意力機制,通過一種新的端到端深度神經網絡來尋找場景中有利于長距離匹配的顯著的、獨特的和穩定的特征。此外,此學習的特征描述符被證明有能力建立魯棒的匹配,因此成功地估計出最優的、具有高精度的相機姿態。
本文使用新收集的具有高質量的地面真實軌跡和傳感器之間硬件同步的數據集全面驗證了本方法的有效性。
結果表明,與基于lidar的定位解決方案相比,在各種具有挑戰性的環境下,本文的方法獲得了具有競爭力的定位精度,這是一種潛在的低成本自動駕駛定位解決方案。
主要貢獻:
1.提出一種新穎的自動駕駛視覺定位框架,在各種具有挑戰性的照明條件下達到了厘米級定位精度。
2.通過一種新的端到端深度神經網絡使用了注意力機制和深層特征,這有效的提高了算法性能。
3.使用具有高質量的地面真實軌跡和硬件(相機、激光雷達、IMU)同步的新數據集對所提出的方法進行嚴格測試,并驗證了其性能。
方法介紹:
該系統分為三個階段:(1)網絡訓練;(2)地圖生成;(3)在線定位。地圖生成和在線定位都可以看作是經過訓練的網絡的應用。提出的網絡架構如圖1所示。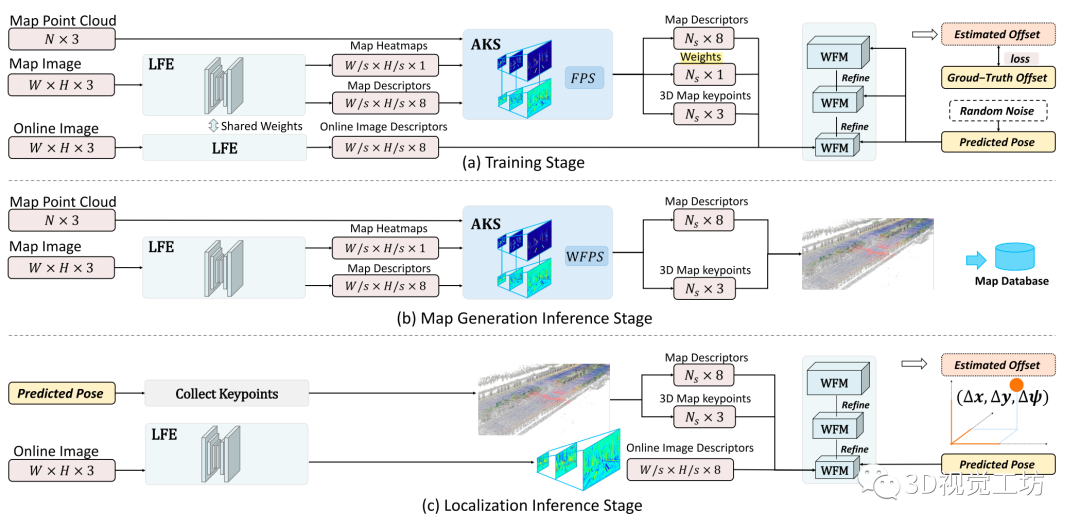
Fig1:基于端到端深度注意力感知特征的視覺定位框架在三個不同階段的網絡架構和系統工作流:a)訓練;bb)地圖生成;c)在線定位。
一、系統工作流
1. 訓練:
訓練階段包括三個模塊,LFE, AKS和WFM。首先,給定一個預測位姿,并選取其在歐氏距離內最接近的地圖圖像;接下來,LFE模塊分別從在線圖像和地圖圖像中提取稠密特征,并從地圖圖像中提取相應的注意力熱圖。AKS模塊根據熱圖的注意力得分,從地圖圖像中選擇具備好的特征的點作為關鍵點。
然后通過激光雷達點云投影得到它們的相應的三維坐標。最后,以這些三維關鍵點和特征描述符作為輸入,WFM模塊在一個三維代價卷中搜索,尋找最優位姿偏移量,并將最優位姿偏移量與地面真實位姿進行比較,構造損失函數。
2.地圖生成:
訓練結束后,使用如圖2所示的網絡的部分子網絡,可以完成地圖生成。給定激光雷達掃描和車輛真實位姿,可以很容易地獲得激光雷達點的全局三維坐標。注意,激光雷達傳感器和車輛位姿真值僅用于建圖。首先,在給定車輛真實位姿的情況下,通過將三維激光雷達點投影到圖像上,將地圖圖像像素與全局三維坐標關聯起來。
然后利用LFE網絡求解地圖圖像的注意力熱圖和不同分辨率的特征圖。接下來,在AKS模塊的金字塔中為不同的分辨率選擇一組關鍵點。總體而言,本方法將關鍵點及其特征描述符,以及其3D坐標保存到地圖數據庫中。
3.在線定位:
在定位階段,利用LFE網絡再次估計在線圖像中不同分辨率的特征圖。本方法從給定的相機的預測位姿的最近的地圖圖像中收集關鍵點及其特征描述符和全局3D坐標。
然后,在WFM模塊中,構建的成本卷中給出了候選位姿,而這些關鍵點則被利用這些候選位姿投影到在線圖像上。通過三個不同分辨率的特征匹配網絡級聯實現由粗到細的位姿估計。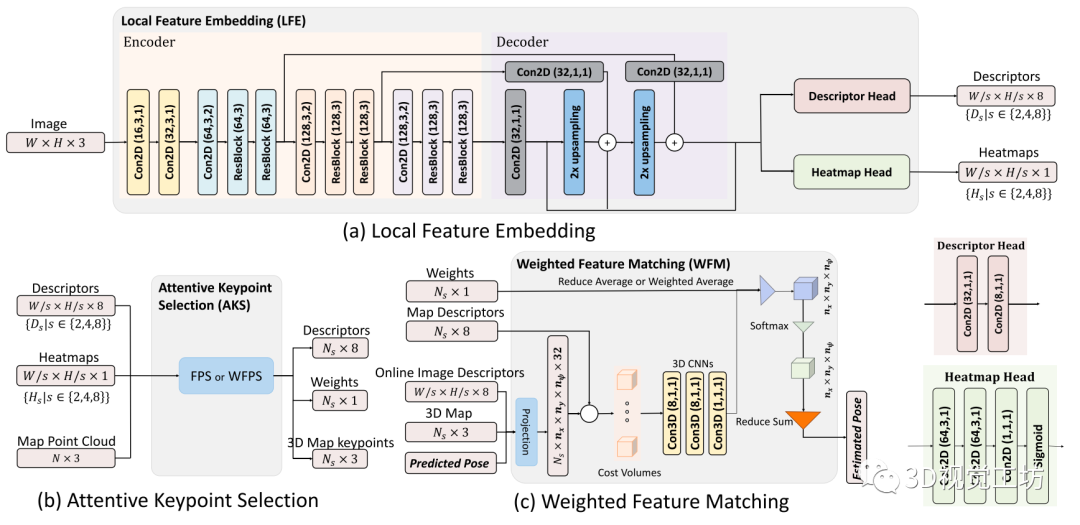
Fig.2 三個主要模塊的網絡結構說明:(a)局部特征學習(LFE);(b)關鍵點選取(AKS);(c)加權特征匹配(WFM)。
二、局部特征學習
在所有三個不同的階段都使用相同的LFE模塊。本文采用了一種類似于特征金字塔網絡(FPN)的網絡架構,如圖2(a)所示。通過將編碼器和解碼器中相同大小的特征圖級聯起來,FPN可以在所有尺度上增強高級語義特征,從而獲得更強大的特征提取器。
在本方法的編碼器中有一個FPN,其由17層網絡組成,可以分解為4個階段。第一階段由兩個二維卷積層組成,其中括號中的數字分別是通道、核和步幅大小。從第二階段開始,每個階段包括一個二維卷積層和兩個殘差塊。每個殘差塊由兩個3 × 3卷積層組成。
在解碼器中,經過二維卷積層后,上采樣層被應用于從更粗糙但語義更強的特征中產生更高分辨率的特征。來自編碼器的相同分辨率的特征被通過按元素平均來合并以增強解碼器中的這些特征。解碼器的輸出是原始圖像的不同分辨率的特征圖。再通過如圖2右下角所示的兩個不同的網絡頭,分別用于提取特征描述符和估計注意力熱圖
。特征描述符表示為d維向量,能夠在不同光照或視點條件引起的嚴重外觀變化下進行魯棒匹配。該熱圖由[0-1]標量組成,這些標量在后文的基于注意力的關鍵點選擇和特征匹配模塊中用作相關性權重。更具體地說,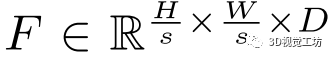
是描述符學習模塊輸出, 其中s∈2,4,8是尺度因子,D = 8為特征維度。注意力熱圖輸出是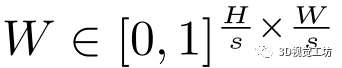 .
.
三、關鍵點選取
在研究過程中,了解到不同的關鍵點選擇策略對系統的整體性能有相當大的影響。AKS模塊分為兩個階段:訓練和地圖生成。當在解決一個幾何問題時,眾所周知,相較于聚集在一起的關鍵點,在幾何空間中幾乎均勻分布的一組關鍵點是至關重要的。
本方法發現,提出的方法優于其他更自然的選擇,例如top-K。本方法考慮了兩種選擇策略,即最遠點采樣(FPS)算法及其變體,加權FPS (WFPS)算法(如圖2(b)所示)。給定一組已選點S和未選點Q,如果試圖迭代地從Q中選擇一個新點, FPS算法會計算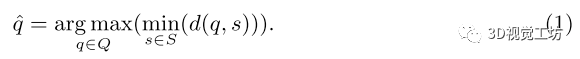
在本方法的WFPS算法中,取而代之的是計算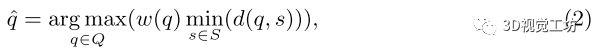
在訓練階段,本方法的目標是統一學習所有的候選者的注意力分數,因此必須要有一個有效的隨機選擇策略。為此,首先隨機抽取K個候選點,然后,本方法應用FPS算法來選擇其中的關鍵點。 在地圖生成階段,本方法通過有效地結合學習的注意力權重實現了一個能夠選擇好的關鍵點的算法。
本方法再次隨機選擇K個候選點,然后在地圖生成過程中使用WFPS,并以熱圖為采樣概率來使用稠密采樣。 為了將二維特征描述符與三維坐標相關聯,本方法將3D激光雷達點投射到圖像上。考慮到并非所有的圖像像素都與LiDAR點相關聯,本方法只考慮與已知三維坐標有關聯的稀疏2D像素作為候選點,從中選擇適合匹配的關鍵點。
四、加權特征匹配
傳統方法通常利用RANSAC框架中的PnP求解器來求解給定2D-3D對應的攝像機位姿估計問題。不幸的是,這些包括異常值拒絕步驟的匹配方法是不可微的,從而阻礙了他們在訓練階段的反向傳播。
L3-Net引入了一種特征匹配和位姿估計方法,該方法利用可微分的三維代價卷來評估給定的位姿偏移量下,來自在線圖像和地圖圖像的對應特征描述符對的匹配代價。 下面,本方法對原來的L3-Net設計進行改進,提出將注意力權重納入解決方案,并使其有效訓練。網絡架構如圖2(c)所示。
代價卷:與L3-Net的實現類似,本方法建立了一個
的代價卷,其中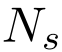 為所選關鍵點的個數,
為所選關鍵點的個數,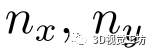 和
和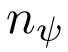 為每個維度的網格大小。具體來說,給定預測位姿作為代價卷中心,將其相鄰空間均勻劃分為一個三維網格,記為
為每個維度的網格大小。具體來說,給定預測位姿作為代價卷中心,將其相鄰空間均勻劃分為一個三維網格,記為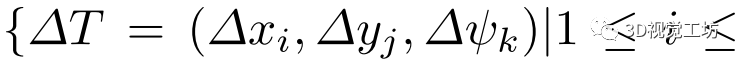
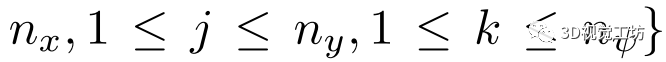 。
。
該代價卷中的節點是候選位姿,本方法希望從中評估其對應的特征對并找到最優解。具體而言,利用每個候選位姿將地圖圖像中選定的三維關鍵點投影到在線圖像上,通過對在線圖像特征圖進行雙線性插值,計算出對應的局部特征描述符。通過計算在線和地圖圖像的兩個描述符之間的元素的總的L2距離,本方法實現了一個單維代價標量。然后,由一個以Conv3D(8,1,1)-Conv3D(8,1,1)-Conv3D(1,1,1)為內核的三層三維CNN對代價卷進行處理,結果記為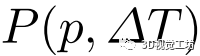
邊緣化:通過應用平均操作,在關鍵點維度上將匹配代價卷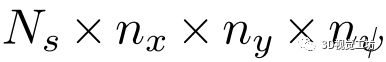 邊緣化為
邊緣化為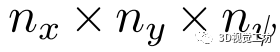 。
。
在LFE模塊的熱圖學習訓練中,成功的關鍵在于如何有效地結合所有關鍵點特征的注意力權重。與沒有注意力權重的平均相比,最直接的解決方案是使用加權平均操作取代直接平均。
本方法在訓練時使用加權平均,在在線定位化階段使用直接平均。 其余部分估計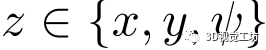 的最優偏移量
的最優偏移量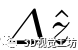 及其概率分布
及其概率分布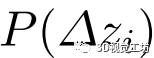 與圖2 (c)所示的L3-Net的設計相同。
與圖2 (c)所示的L3-Net的設計相同。
五、損失函數設計
1)絕對損失:以估計偏移量 與真值
與真值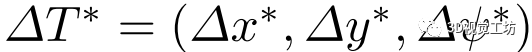 之間的絕對距離作為第一個損失:
之間的絕對距離作為第一個損失: 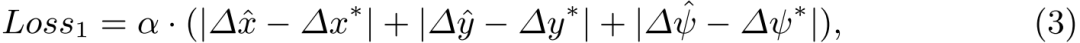
其中α是一個平衡因子。
2)聚集損失:除上述絕對損失外,概率分布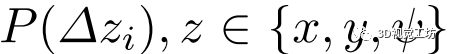 對估計的魯棒性也有相當大的影響。因此,取
對估計的魯棒性也有相當大的影響。因此,取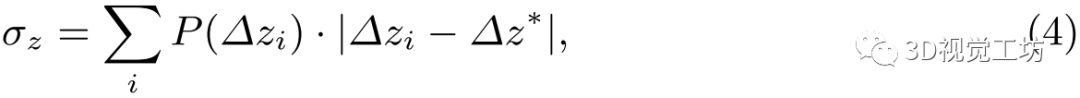
其中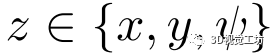 。
。
從而第二個損失函數定義為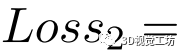
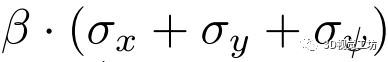 。
。
3)相似損失:除幾何約束外,對應的2D-3D關鍵點該有相似的描述符。因此,本方法將第三個損失定義為: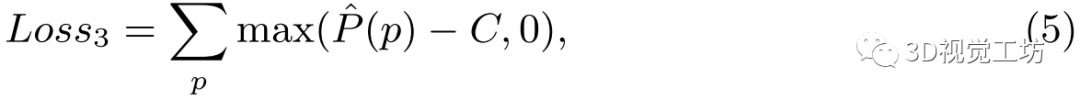
其中,為關鍵點P的三維CNN的輸出,當使用真值位姿將地圖中的關鍵點投影到在線圖像上時,在在線圖像中找到對應的點,并計算匹配點對之間的描述符的距離。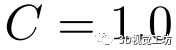 是一個常數。
是一個常數。
審核編輯:劉清
-
ADT
+關注
關注
0文章
11瀏覽量
9482 -
激光雷達
+關注
關注
967文章
3939瀏覽量
189598 -
自動駕駛
+關注
關注
783文章
13684瀏覽量
166147
原文標題:視覺定位在自動駕駛領域可否比肩基于Lidar的方法?
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于視覺語言模型的導航框架VLMnav
一種基于因果路徑的層次圖卷積注意力網絡

一種創新的動態軌跡預測方法
一種將NeRFs應用于視覺定位任務的新方法

一種完全分布式的點線協同視覺慣性導航系統
一種半動態環境中的定位方法
2024 年 19 種最佳大型語言模型

TensorFlow與PyTorch深度學習框架的比較與選擇
基于深度學習的鳥類聲音識別系統
激光焊接視覺定位引導方法

一種利用光電容積描記(PPG)信號和深度學習模型對高血壓分類的新方法
采用單片超構表面與元注意力網絡實現快照式近紅外光譜成像

淺析自動駕駛行業的視覺感知主流框架設計
基于機器視覺和深度學習的焊接質量檢測系統
理解KV cache的作用及優化方法






 工商網監
工商網監
評論