 面向Aspect情感分析的自動生成離散意見樹結構
面向Aspect情感分析的自動生成離散意見樹結構
在本文中,我們探索了一種簡單的方法,為每個方面自動生成離散意見樹結構。用到了RL。
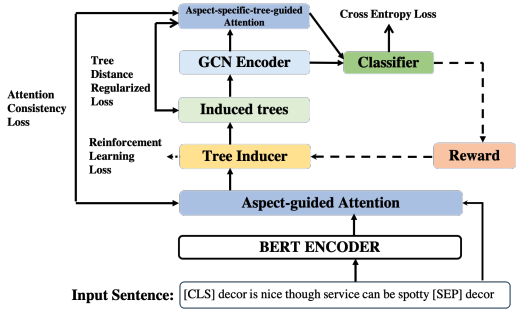
首先為每個方面生成離散意見樹,設方面詞的位置為[b,e],則首先將方面跨度[b, e]作為根節點,然后分別從跨度[1,b?1]和[e+1, n]構建它的左子節點和右子節點。為了構建左子樹或右子樹,我們首先選擇span中「得分最大的元素」作為子樹的根節點,然后遞歸地對相應的span分區使用build_tree調用。(除了方面詞外其他node都是單個詞)。
關于得分分數的計算,選擇將""作為BERT的輸入得到特殊于方面詞的句子表達H,然后按照如下計算得分:
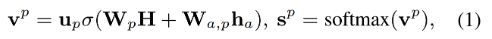
其中h是H中方面詞部分的平均池化,構建樹的這部分包含的參數有三個以及BERT參數部分。
構建樹的這一部分稱為,輸入為x和a(用于打分),輸出為一棵樹,參數 ? 包括上述參數。這一部分參數使用RL進行更新而不是最終損失函數的反向傳播。
生成樹以后開始正式執行預測任務,模型非常簡單。
將上面得到的樹生成鄰接矩陣,經過GCN(可能多層),取最后一層GCN的輸出結果的方面詞部分以及[CLS]這個token的表達之和作為query,與GCN的輸入的初始向量特征(也就是原句子經過句子編碼器得到的)做注意力機制,用輸入去表達最終的方面級分類特征。
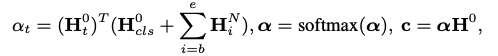
最后輸出分類結果
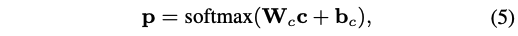
損失函數:
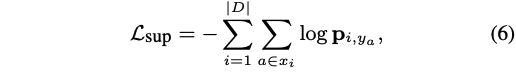
注意這個論文分為兩個模塊,第一個是生成樹,利用得到t;第二部分是預測, ,這里的 θ 包括GCN模塊的參數和輸出(等式5)的部分,PS注意力模塊沒有引進參數哦。
第二部分使用上述損失函數進行優化,由于樹的采樣過程是一個離散的決策過程,因此它是不可微的,第一部分使用的是RL進行優化。
強化學習實現訓練部分還沒看。
實驗效果和分析
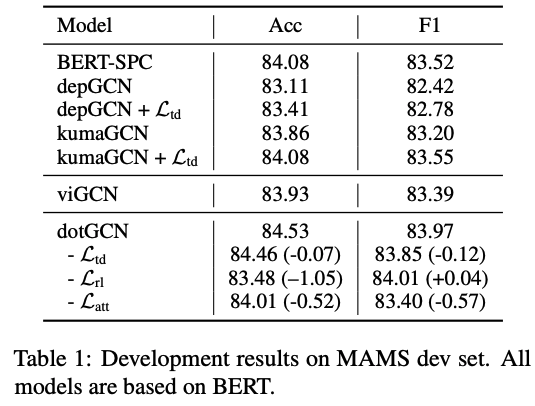
MAMS 開發集效果
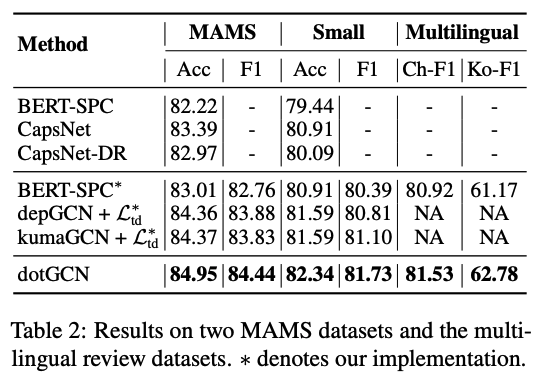
在MAMS數據上和多語言評論數據的結果
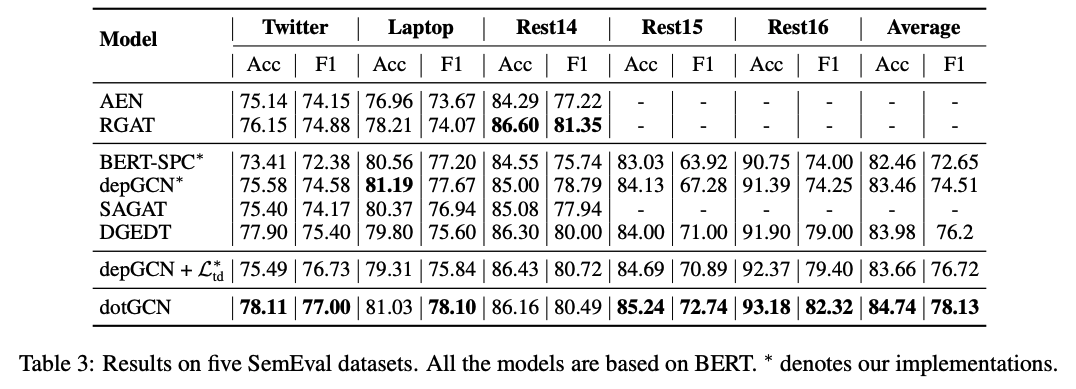
SemEval數據集上的效果
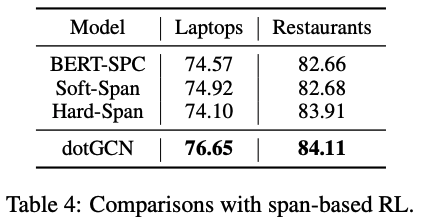
和span-based RL作對比
圖3a和圖3b分別顯示了方面術語“scallops”的induced tree和dependency parse:
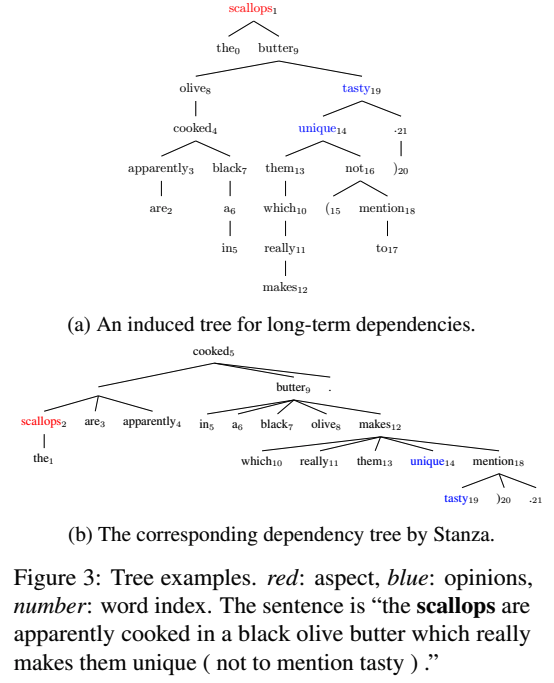
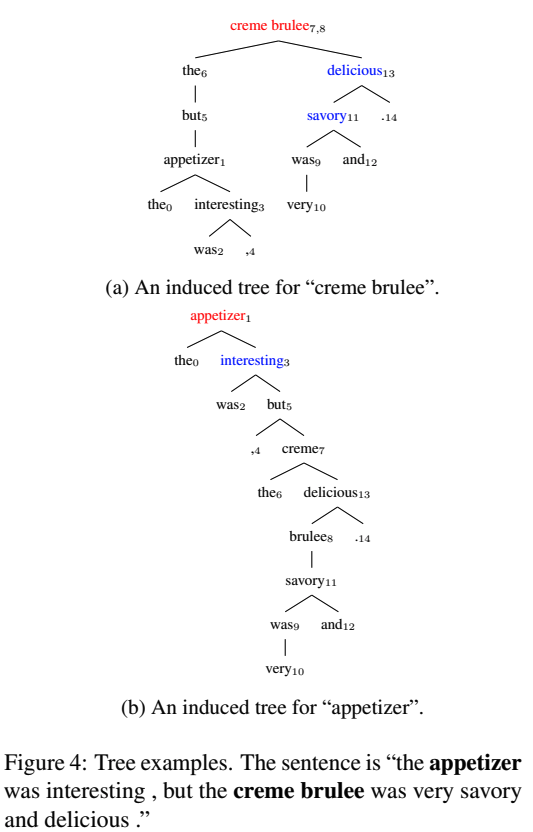
圖4a和圖4b顯示了兩個情緒極性不同的方面術語的induced tree:
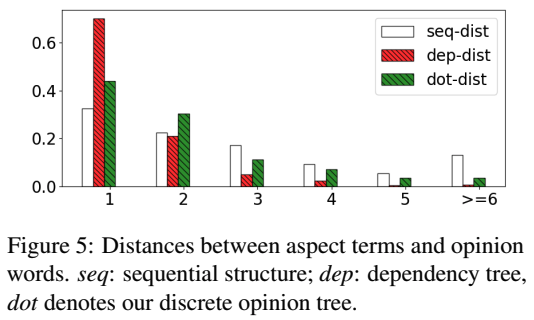
aspect 和 opinion word的距離分析:
基于MAMS的測試集分類精度與訓練集中各方面頻率的關系:

審核編輯:郭婷
-
編碼器
+關注
關注
45文章
3600瀏覽量
134196
原文標題:ACL'22 | 西湖大學提出:面向Aspect情感分析的離散意見樹歸納方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AIGC與傳統內容生成的區別 AIGC的優勢和挑戰
RNN的應用領域及未來發展趨勢
基于LSTM神經網絡的情感分析方法
AIGC與傳統內容生成的區別
關于Makefile自動生成-autotools的使用

流程工業和離散工業是什么?
ΣΔ(Sigma-Delta)技術詳解(上):離散ΣΔ調制器
利用邊緣計算網關解決離散行業數采的方案【天拓四方】





 工商網監
工商網監
評論