") IPMT:用于小樣本語義分割的中間原型挖掘Transformer
IPMT:用于小樣本語義分割的中間原型挖掘Transformer
本文簡要介紹發(fā)表在NeurIPS 2022上關(guān)于小樣本語義分割的論文《Intermediate Prototype Mining Transformer for Few-Shot Semantic Segmentation》。該論文針對現(xiàn)有研究中忽視查詢和支持圖像之間因類內(nèi)多樣性而帶來的類別信息的差距,而強(qiáng)行將支持圖片的類別信息遷移到查詢圖片中帶來的分割效率低下的問題,引入了一個(gè)中間原型,用于從支持中挖掘確定性類別信息和從查詢中挖掘自適應(yīng)類別知識,并因此設(shè)計(jì)了一個(gè)中間原型挖掘Transformer。文章在每一層中實(shí)現(xiàn)將支持和查詢特征中的類型信息到中間原型的傳播,然后利用該中間原型來激活查詢特征圖。借助Transformer迭代的特性,使得中間原型和查詢特征都可以逐步改進(jìn)。相關(guān)代碼已開源在:
https://github.com/LIUYUANWEI98/IPMT
一、研究背景
目前在計(jì)算機(jī)視覺取得的巨大進(jìn)展在很大程度上依賴于大量帶標(biāo)注的數(shù)據(jù),然而收集這些數(shù)據(jù)是一項(xiàng)耗時(shí)耗力的工作。為了解決這個(gè)問題,通過小樣本學(xué)習(xí)來學(xué)習(xí)一個(gè)模型,并將該模型可以推廣到只有少數(shù)標(biāo)注圖像的新類別。這種設(shè)置也更接近人類的學(xué)習(xí)習(xí)慣,即可以從稀缺標(biāo)注的示例中學(xué)習(xí)知識并快速識別新類別。
本文專注于小樣本學(xué)習(xí)在語義分割上的應(yīng)用,即小樣本語義分割。該任務(wù)旨在用一些帶標(biāo)注的支持樣本來分割查詢圖像中的目標(biāo)物體。然而,目前的研究方法都嚴(yán)重依賴從支持集中提取的類別信息。盡管支持樣本能提供確定性的類別信息指導(dǎo),但大家都忽略了查詢和支持樣本之間可能存在固有的類內(nèi)多樣性。
在圖1中,展示了一些支持樣本原型和查詢圖像原型的分布。從圖中可以觀察到,對于與查詢圖像相似的支持圖像(在右側(cè)標(biāo)記為“相似支持圖像”),它們的原型在特征空間中與查詢原型接近,在這種情況下匹配網(wǎng)絡(luò)可以很好地工作。然而,對于與查詢相比在姿勢和外觀上具有較大差異的支持圖像(在左側(cè)標(biāo)記為“多樣化支持圖像”),支持和查詢原型之間的距離會(huì)很遠(yuǎn)。在這種情況下,如果將支持原型中的類別信息強(qiáng)行遷移到查詢中,則不可避免地會(huì)引入較大的類別信息偏差。
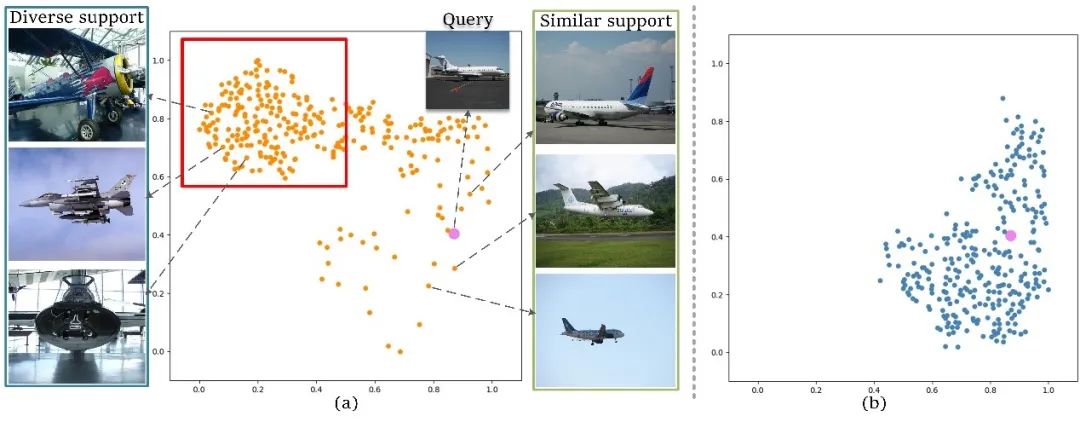
圖1 支持樣本原型與查詢圖像原型分布圖
因此,本文在通過引入一個(gè)中間原型來緩解這個(gè)問題,該原型可以通過作者提出的中間原型挖掘Transformer彌補(bǔ)查詢和支持圖像之間的類別信息差距。每層Transformer由兩個(gè)步驟組成,即中間原型挖掘和查詢激活。在中間原型挖掘中,通過結(jié)合來自支持圖像的確定性類別信息和來自查詢圖像的自適應(yīng)類別知識來學(xué)習(xí)中間原型。然后,使用學(xué)習(xí)到的原型在查詢特征激活模塊中激活查詢特征圖。此外,中間原型挖掘Transformer以迭代方式使用,以逐步提高學(xué)習(xí)原型和激活查詢功能的質(zhì)量。
二、方法原理簡述
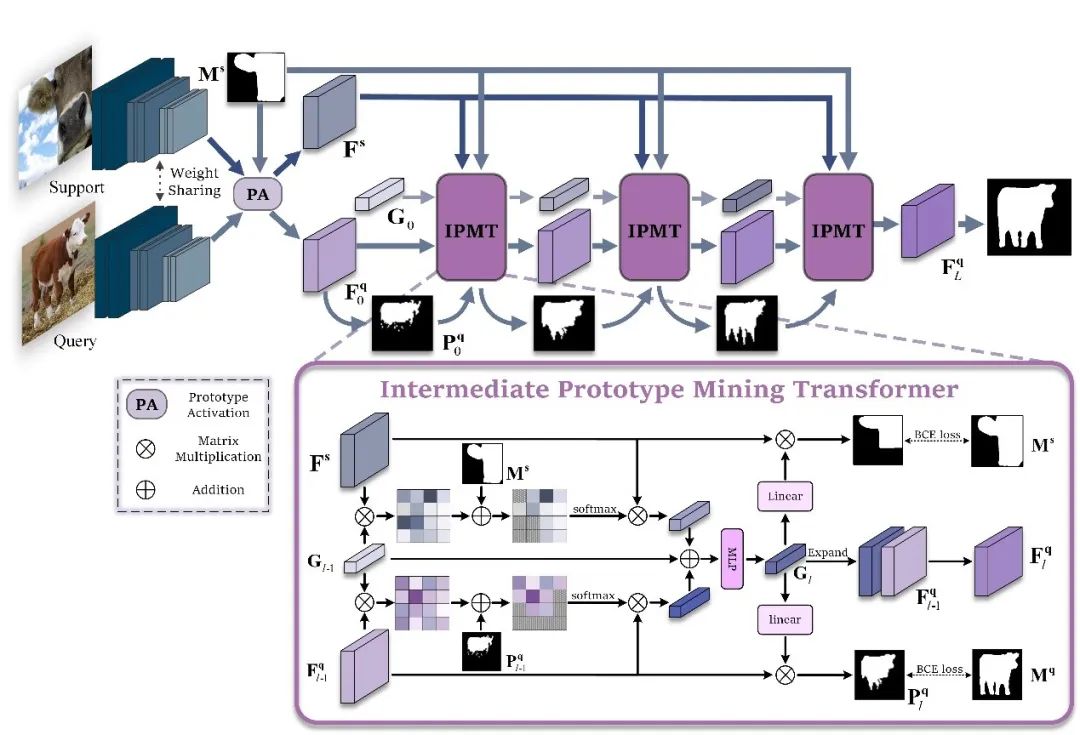
圖2 方法總框圖
支持圖像和查詢圖像輸入到主干網(wǎng)絡(luò)分別提取除支持特征和查詢特征。查詢特征在原型激活(PA)模塊中經(jīng)過簡單的利用支持圖像原型進(jìn)行激活后,分割成一個(gè)初始預(yù)測掩碼,并將該掩碼和激活后的查詢特征作為中間原型挖掘Transformer層的一個(gè)輸入。同時(shí),將支持特征、支持圖片掩碼和隨機(jī)初始化的一個(gè)中間原型也做為第一層中間原型挖掘Transformer的輸入。在中間原型挖掘Transformer層中,首先進(jìn)行掩碼注意力操作。具體來說,計(jì)算中間原型與查詢或支持特征之間的相似度矩陣,并利用下式僅保留前景區(qū)域的特征相似度矩陣:
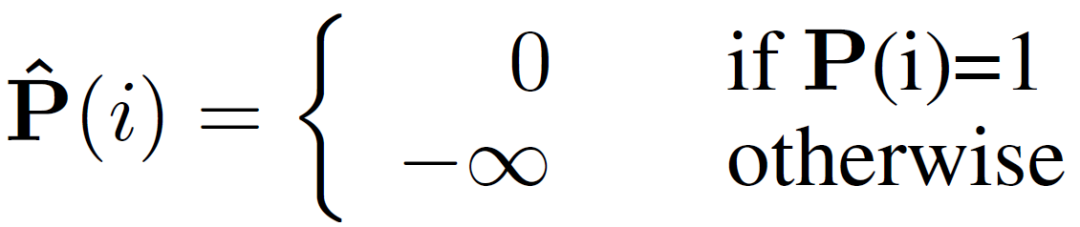
處理后的相似度矩陣作為權(quán)重,分別捕獲查詢或支持特征中的類別信息并形成新的原型。
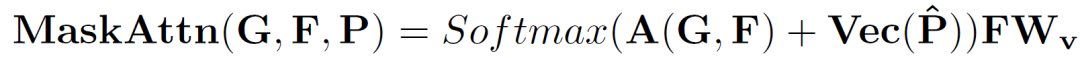
查詢特征新原型、支持特征新原型和原中間原型結(jié)合在一起形成新的中間原型,完成對中間原型的挖掘。
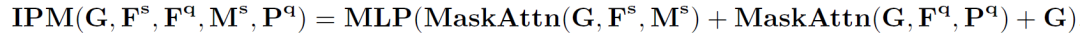
而后,新的中間原型在查詢特征激活模塊中對查詢特征中的類別目標(biāo)予以激活。
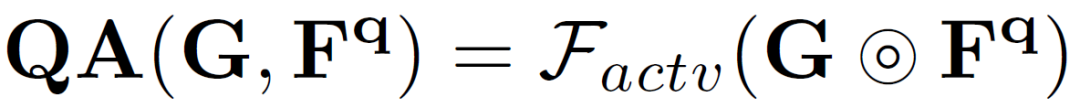
為了便于學(xué)習(xí)中間原型中的自適應(yīng)類別信息,作者使用它在支持和查詢圖像上生成兩個(gè)分割掩碼,并計(jì)算兩個(gè)分割損失。
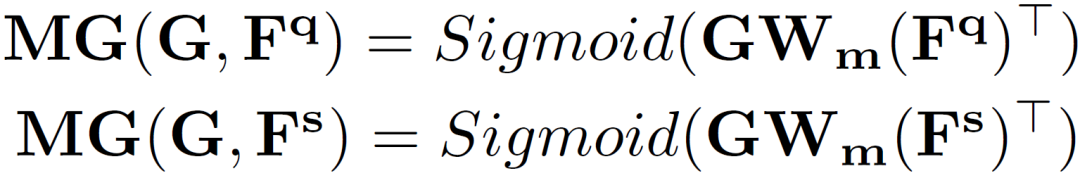
并設(shè)計(jì)雙工分割損失(DSL):
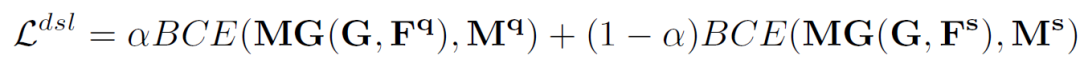
由于一個(gè)中間原型挖掘Transformer層可以更新中間原型、查詢特征圖和查詢分割掩碼,因此,作者通過迭代執(zhí)行這個(gè)過程,得到越來越好的中間原型和查詢特征,最終使分割結(jié)果得到有效提升。假設(shè)有L 層,那么對于每一層有:
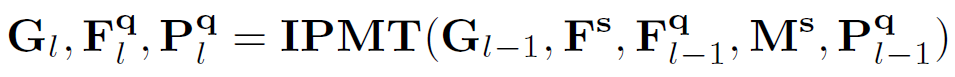
上式中具體過程又可以分解為以下環(huán)節(jié):
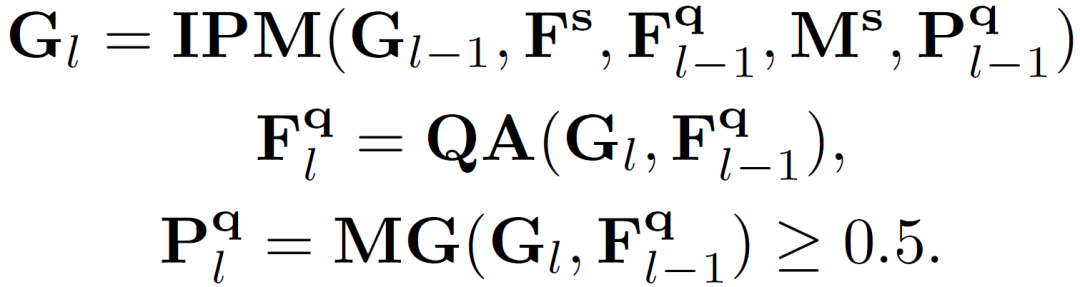
三、實(shí)驗(yàn)結(jié)果及可視化

圖3 作者提出方法的結(jié)果的可視化與比較
在圖3中,作者可視化了文章中方法和僅使用支持圖像的小樣本語義分割方法[1]的一些預(yù)測結(jié)果。可以看出,與第 2 行中僅使用支持信息的結(jié)果相比,第3行中的結(jié)果展現(xiàn)出作者的方法可以有效地緩解由固有的類內(nèi)多樣性引起的分割錯(cuò)誤。
表4 與先前工作在PASCAL-5i[2]數(shù)據(jù)集上的效果比較
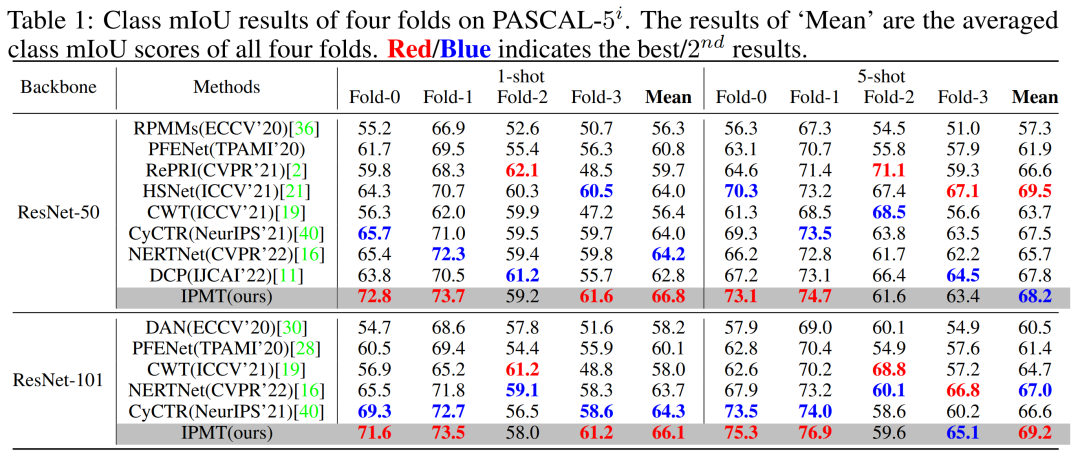
從表4中可以發(fā)現(xiàn),作者的方法大大超過了所有其他方法,并取得了新的最先進(jìn)的結(jié)果。在使用 ResNet-50 作為主干網(wǎng)絡(luò)時(shí), 在 1-shot 設(shè)置下與之前的最佳結(jié)果相比,作者將 mIoU 得分提高了 2.6。此外,在使用 ResNet-101作為主干網(wǎng)絡(luò)時(shí),作者方法實(shí)現(xiàn)了 1.8 mIoU(1-shot)和 2.2 mIoU(5-shot )的提升。
表5 各模塊消融實(shí)驗(yàn)
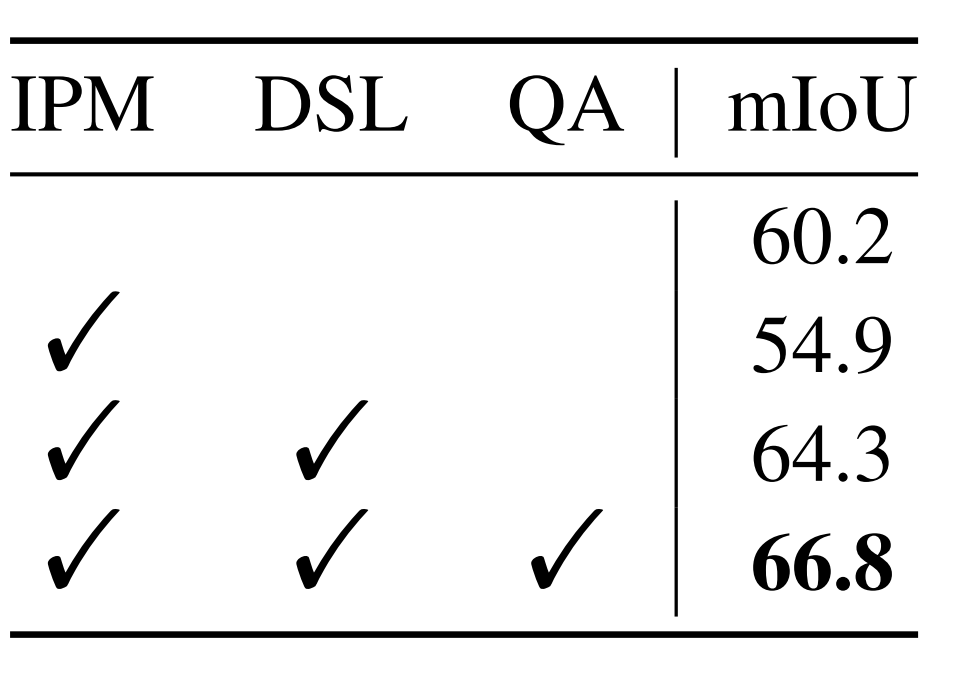
表5中指出,當(dāng)僅使用 IPM 會(huì)導(dǎo)致 5.3 mIoU 的性能下降。然而,當(dāng)添加 DSL 時(shí),模型的性能在baseline上實(shí)現(xiàn)了 4.1 mIoU 的提升。作者認(rèn)為這種現(xiàn)象是合理的,因?yàn)闊o法保證 IPM 中的可學(xué)習(xí)原型將在沒有 DSL 的情況下學(xué)習(xí)中間類別知識。同時(shí),使用 QA 激活查詢特征圖可以進(jìn)一步將模型性能提高 2.5 mIoU。這些結(jié)果清楚地驗(yàn)證了作者提出的 QA 和 DSL 的有效性。
表6 中間原型Transformer有效性的消融研究
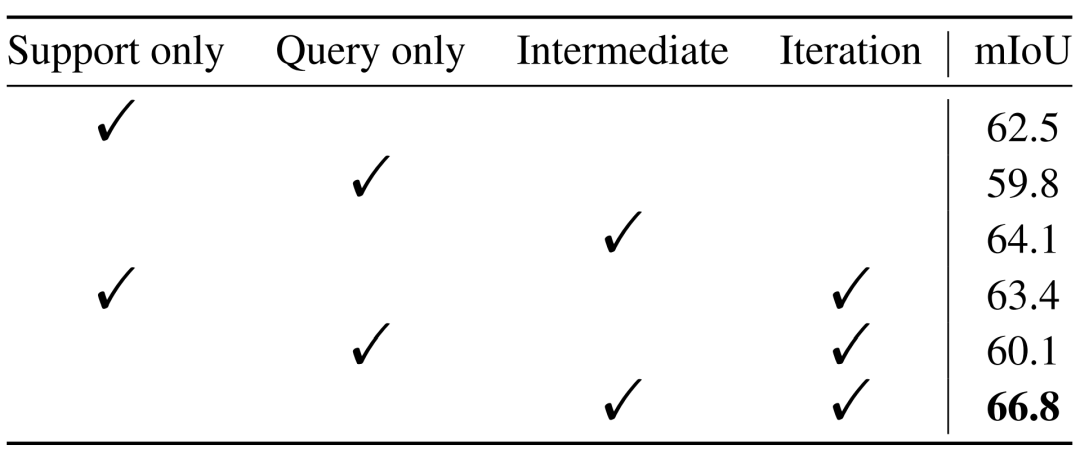
在表6中,作者對比了僅使用support或者query提供類別信息時(shí),和是否使用迭代方式提取信息時(shí)的模型的性能情況。可以看出,借助中間原型以迭代的方式從support和query中都獲取類型信息所取得的效果更為出色,也驗(yàn)證了作者提出方法的有效性。
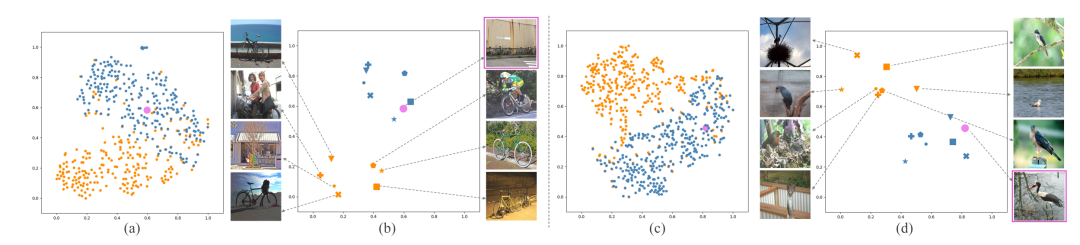
圖7 支持原型和中間原型分別的可視化比較
如圖7所示,作者將原本的支持原型可視化為橘色,學(xué)習(xí)到的中間原型可視化為藍(lán)色,查詢圖像原型可視化為粉色。可以看到,在特征空間中,中間原型比支持原型更接近查詢原型,因此驗(yàn)證了作者的方法有效地緩解了類內(nèi)多樣性問題并彌補(bǔ)了查詢和支持圖像之間的類別信息差距。
四、總結(jié)及結(jié)論
在文章中,作者關(guān)注到查詢和支持之間的類內(nèi)多樣性,并引入中間原型來彌補(bǔ)它們之間的類別信息差距。核心思想是通過設(shè)計(jì)的中間原型挖掘Transformer并采取迭代的方式使用中間原型來聚合來自于支持圖像的確定性類型信息和查詢圖像的自適應(yīng)的類別信息。令人驚訝的是,盡管它很簡單,但作者的方法在兩個(gè)小樣本語義分割基準(zhǔn)數(shù)據(jù)集上大大優(yōu)于以前的最新結(jié)果。為此,作者希望這項(xiàng)工作能夠激發(fā)未來的研究能夠更多地關(guān)注小樣本語義分割的類內(nèi)多樣性問題。
審核編輯 :李倩
-
模塊
+關(guān)注
關(guān)注
7文章
2672瀏覽量
47345 -
圖像
+關(guān)注
關(guān)注
2文章
1083瀏覽量
40418 -
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1696瀏覽量
45928
原文標(biāo)題:?NeurIPS 2022 | IPMT:用于小樣本語義分割的中間原型挖掘Transformer
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
手冊上新 |迅為RK3568開發(fā)板NPU例程測試
語義分割25種損失函數(shù)綜述和展望

手冊上新 |迅為RK3568開發(fā)板NPU例程測試
圖像語義分割的實(shí)用性是什么
圖像分割和語義分割的區(qū)別與聯(lián)系
迅為RK3568手冊上新 | RK3568開發(fā)板NPU例程測試
Transformer語言模型簡介與實(shí)現(xiàn)過程
圖像分割與語義分割中的CNN模型綜述
中間繼電器主要用于信號傳遞和放大的原因
中間繼電器的型號怎么表示
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
中間繼電器的應(yīng)用 中間繼電器在使用中的注意事項(xiàng)
助力移動(dòng)機(jī)器人下游任務(wù)!Mobile-Seed用于聯(lián)合語義分割和邊界檢測

三項(xiàng)SOTA!MasQCLIP:開放詞匯通用圖像分割新網(wǎng)絡(luò)
異構(gòu)信號驅(qū)動(dòng)下小樣本跨域軸承故障診斷的GMAML算法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論