 為AI端點應用選擇合適的閃存
為AI端點應用選擇合適的閃存
人工智能的起源
從1955年到1956年,達特茅斯學院助理教授約翰·麥卡錫(John McCarthy)被廣泛認為是人工智能(AI)之父。哈佛大學的Marvin Minsky,IBM的Claude Shannon和美國貝爾實驗室的Nathaniel Rochester共同創造了人工智能(AI)的概念,他們說:“如果機器可以使用不同的語言來形成抽象或概念,解決現在留給人類的各種問題,并通過自主學習提高自己,我們稱之為AI。
牛津詞典將人工智能定義為“能夠執行通常需要人類智能的任務的計算機系統的理論和發展,例如視覺感知、語音識別、決策和語言之間的翻譯。
隨著系統的發展,人工智能技術將出現在更多的物聯網應用中,如傳感、智能手機、網絡搜索、人臉或車輛車牌識別、智能電表、工業控制和自動駕駛。
在自動駕駛領域,美國已經進行了4級測試(被認為是完全自動駕駛,盡管人類駕駛員仍然可以請求控制)。隨著5級(真正的自動駕駛,汽車完成所有駕駛,沒有駕駛艙)自動駕駛指日可待,我們不僅要依靠交通法律法規,還要依靠人工智能算法的開發人員來確保車輛和行人的安全。
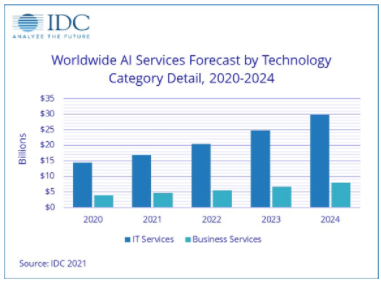
根據國際數據公司(IDC)的統計數據,到2024年,全球人工智能服務預計將上升到18.4%,市值約為378億美元。這包括定制應用程序以及定制平臺的相關支持和服務,例如深度學習架構、卷積神經網絡(一類人工神經網絡,最常用于分析視覺圖像)和人工智能相關芯片(CPU、GPU、FPGA、TPU、ASIC)等等。
IDC還預測,全球數據存儲將從2018年的33ZB飆升至2025年的175ZB,其中超過50%將來自物聯網設備。
考慮到到2025年全球將部署約140億臺物聯網設備,我們大幅增加云中的計算單元數量和計算能力以應對海量數據增長不是最重要的嗎?
好吧,簡短的回答是否定的。它沒有考慮從端點到云的數據傳輸鏈中的帶寬和延遲等實際挑戰,這就是“邊緣計算”如此迅速涌現的原因。
沒有必要增加帶寬和服務器數量來應對物聯網設備的快速增長。最好將應用程序移動到端點設備,這樣就無需將所有數據發送到云進行處理、傳輸、存儲和分析。例如,在工業自動化應用中,數據存儲距離會影響效率——如果不加強端點人工智能并改革計算存儲架構,5G移動設備制造商可能會遇到嚴重的電池壽命困難。
安全性是另一個重要問題,尤其是在萬物互聯(IoE)時代,機密信息,數據泄漏或黑客事件很常見。在邊緣進行計算可以最大限度地減少數據在“云-管道-端點”路徑中傳輸的次數,在這種情況下,功耗和系統總擁有成本降低,同時確保數據和網絡安全。
比較人工智能芯片
人工智能技術分為兩類;訓練和推理。訓練由 CPU、GPU 和 TPU 在云中執行,以不斷增加用于構建數據模型的數據庫資源。推理依賴于經過訓練的數據模型,更適合完成邊緣設備和特定應用。它通常由ASIC和FPGA芯片處理。
與AI相關的芯片包括CPU,GPU,FPGA,TPU和ASIC。為了了解這些芯片之間的比較情況,以下是 5 個關鍵因素的比較重點。這些是:
計算機科學
靈活性
兼容性
權力
成本。
-中央處理器
CPU的開發具有強大的計算能力和首屈一指的軟件和硬件兼容性。但由于馮諾依曼架構的限制,數據需要在存儲器和處理器之間來回傳輸。與其他解決方案相比,這限制了平均處理速度以及推動功耗和成本的能力。
- 顯卡
例如,由于采用了計算統一設備架構,英偉達的GPU可以主觀地讀取內存位置,并通過共享虛擬內存來提高計算能力。平均計算能力超過CPU數百甚至數千倍。
GPU已經發展出良好的軟件和硬件兼容性,但需要提高功耗和成本效益。對硬件(如附加冷卻系統)的投資對于減少任何熱量問題也至關重要。
- 專用集成電路
ASIC芯片專為特定應用而設計。它們的計算能力、整體功耗和成本效益可以在驗證和調整后進行優化。
- FPGA
FPGA在軟硬件上的兼容性值得稱道,即使整體算力、成本效率和功耗都不是最好的。對于開發人員來說,從FPGA開始AI芯片開發仍然是一個好主意。
突破馮·諾依曼建筑的界限
馮諾依曼架構被傳統計算設備廣泛采用,它沒有將計算和存儲分開,而是更側重于計算。處理器和內存之間的無休止數據傳輸消耗了大約 80% 的時間和功率。學術界已經提出了許多不同的方法來解決這個問題 - 通過光互連和2.5D / 3D堆疊實現高帶寬數據通信。通過增加緩存層和近數據存儲(如高密度片上存儲)的數量來降低內存訪問延遲和功耗。
但是人腦中的計算和存儲有什么區別嗎?我們是否使用左半球進行計算,使用右半球進行存儲?顯然不是。人腦的計算和存儲發生在同一個地方,不需要數據遷移。
然后,學術界和工業界都渴望找到一種類似于人腦結構的新架構,能夠有機地結合計算和存儲,這并不奇怪。解決方案是“計算存儲設備”,它直接使用存儲單元進行計算或對計算單元進行分類,以便它們對應于不同的存儲單元 - 最大限度地減少數據遷移引起的功耗。
存儲行業的一些制造商已經探索了不同的選擇。例如,非易失性存儲器(NVM)存儲數模轉換器產生的模擬信號并輸出計算能力。同時,輸入電壓和輸出電流在NVM中起著可變電阻的作用,模擬電流信號通過模數轉換器轉換為數字信號。這樣就完成了從數字信號輸入到數字信號輸出的轉換過程。這種方法的最大優點是可以充分利用成熟的20/28nm CMOS工藝,而不是像CPU/GPU那樣追求昂貴的7nm/5nm高級工藝。
隨著成本和功耗的降低,延遲得到了顯著改善,這對于無人機、智能機器人、自動駕駛和安全監控等應用至關重要。
一般來說,端點推理過程的計算復雜度較低,涉及的任務相對固定。由于硬件加速功能的通用性要求較低,因此無需頻繁更改架構。這更適合實現內存計算。相關統計數據顯示,在2017年之前,人工智能無論是訓練還是參考,都是在云端完成的;但到2023年,邊緣端設備/芯片上的AI參考將占到市場的一半以上,總計200-300億美元。對于IC制造商來說,這是一個巨大的市場。
AI需要什么樣的閃存?
每個人都會同意高質量、高可靠性和低延遲的閃存對AI芯片和應用的重要性。為不同的應用找到性能、功耗、安全性、可靠性和高效率的適當平衡至關重要。成本雖然重要,但不應是最重要的考慮因素。
華邦的產品組合為人工智能應用提供了合適的選擇,包括高性能OctalNAND閃存W35N、用于低功耗應用的W25NJW系列,以及與安全相關的W77Q/W75F系列安全閃存。例如,華邦QspiNAND閃存的數據傳輸速率約為每秒83MB,OctalNAND系列的最快速度高達近3倍,接近每秒240MB。
我們的AG1 125C NOR系列和AG2+ 115C NAND系列閃存正在為汽車應用量產。華邦亦提供高性價比的解決方案,例如W25N/W29N NAND閃存系列,適用于生產線機器人應用。
除了華邦廣泛的閃存產品外,華邦的SpiStack(NOR+NAND)也提供了一個可行的替代方案。它將NOR和NAND芯片堆疊到一個封裝中,例如64MB串行NOR和1Gb QspiNAND芯片堆棧,使設計人員能夠靈活地在NOR芯片上存儲代碼,在NAND芯片上存儲數據。雖然它是兩個芯片(NOR+NAND)的堆棧,但SpiStack的單個封裝僅使用6個信號引腳。
“華邦提供多種閃存選項來保護客戶開發的代碼模型。就像在籃球比賽中一樣,芯片制造商扮演中鋒或前鋒,用強大的算力和算法得分;而華邦就像一個捍衛者,用高質量、高性能的閃存產品保護客戶,確保他們在市場上不斷得分。
審核編輯:郭婷
-
芯片
+關注
關注
454文章
50430瀏覽量
421877 -
人工智能
+關注
關注
1791文章
46872瀏覽量
237600
發布評論請先 登錄
相關推薦
為應用選擇合適的射頻放大器指南

靈活地為汽車選擇合適的閃存解決方案
平面分割應如何選擇合適的方法?
為AI端點應用選擇合適的閃存

為正確的工作選擇合適的穩壓器:組件選擇






 工商網監
工商網監
評論