 CV-CUDA 高性能圖像處理加速庫
CV-CUDA 高性能圖像處理加速庫
隨著短視頻 APP、視頻會議平臺以及 VR/AR 等技術的發展,視頻與圖像已逐漸成為全球互聯網流量的主要組成部分。包含我們平時接觸到的這些視頻圖像,也有很多是被 AI 和計算機視覺(CV)算法處理并增強過的。然而,隨著社交媒體和視頻分享服務的快速增長,作為 AI 圖像算法基礎的視頻圖像處理部分,也早已成為計算流程中不可忽視的成本和瓶頸。
CV-CUDA 應用場景
我們先帶大家簡單回顧一下圖像處理的一些常見的例子,以更好地理解 CV-CUDA(Computer Vision - Compute Unified Device Architecture)應用場景。
(1)AI 算法圖像背景模糊化

圖 1. AI 背景模糊(CPU 前后處理方案)
圖像背景模糊化通常會被應用于視頻會議,美圖修圖等場景。在這些場景中,我們通常希望 AI 算法可以把主體之外的背景部分模糊化,這樣可以保護用戶隱私,美化圖像等。圖像背景模糊化的流程大體可以分為 3 個過程:前處理,DNN 網絡以及后處理過程。前處理過程,通常包含了對圖像做 Resize、Padding、Image2Tensor 等操作;DNN 網絡可以是一些常見 segmentation network,比如 Unet 等;后處理過程,通常包括 Tensor2Mask、Crop、Resize、Denoise 等操作。
在傳統的圖像處理流程中,前處理和后處理部分通常都是使用 CPU 進行操作,這導致整個圖像背景模糊化流程中,有 90% 的工作時間消耗在前后處理部分,因而成為了整個算法流水線的瓶頸。若能把前后處理妥善利用 GPU 加速,這將能大幅提升整體的計算性能。

圖 2. AI 背景模糊(GPU 前后處理方案)
當我們把前后處理部分都放到 GPU 上后,我們就可以對整個 pipeline 進行端到端的 GPU 加速。經過測試,在單個 GPU 上,相比于傳統圖像處理方式,把整個 pipeline 移植到 GPU 后,可以獲得 20 倍以上的吞吐率提升。這無疑會大大的節省計算成本。
(2)AI 算法圖像分類

圖 3. AI 圖像分類
圖像分類是最常見的 AI 圖像算法之一,通常可以用于物體識別,以圖搜圖等場景,幾乎是所有 AI 圖像算法的基礎。圖像分類的 pipeline 大體可以分為 2 個部分:前處理部分和 DNN 部分。其中前處理部分,在訓練和推理過程中最常見的 4 種操作包括:圖片解碼、Resize、Padding、Normalize。DNN 部分已經有了 GPU 的加速,而前處理部分通常都會使用 CPU 上的庫函數進行處理。如果能夠把前處理部分也移植到 GPU 上,那么一方面可以釋放 CPU 資源,另一方面也可以進一步提升 GPU 利用率,從而可以對整個 pipeline 進行加速。
當前圖像處理主流方案
針對前后處理部分,我們總結一下目前已有的一些主流應用方案:
(1)目前應用最廣泛的圖像處理庫是 OpenCV
前后處理中的操作,往往是依賴于任務類型的,這導致了前后處理相關的操作種類繁多,數量龐雜。利用 OpenCV 確實可以實現大部分的圖像處理操作,不過,這些操作大部分是用 CPU 實現的,缺少對應的 GPU 加速版本。而部分 CPU 操作雖然存在對應的 GPU 版本,但是這些 GPU 版本的實現可能存在一些問題,包括:
a. 部分算子的 CPU 和 GPU 結果無法對齊。在某些場景下,我們的算法團隊使用了 CPU 的算子進行訓練,而在推理階段負責部署的同學考慮到性能問題,決定使用 GPU 算子,然而在測試過程中,發現 CPU 和 GPU 算子結果無法對齊,這可能會導致端到端的處理結果出現精度異常。
b. 部分算子 GPU 性能比 CPU 性能還弱。除了某些算法本身就不太適合 GPU 化之外,我們還發現部分 GPU 實現并不是很高效。比如,有些算子會在運行過程中,臨時申請顯存空間,導致增加了額外的耗時。
c. 在真實的部署 pipeline 中,可能有些算子只有 CPU 版本,而有些算子既有 CPU 版本又有 GPU 版本。如果 pipeline 里既有 CPU 算子又有 GPU 算子,那么會存在 GPU 和 CPU 同步,以及 H2D,D2H 內存拷貝問題,從而引入額外的耗時。
(2)使用 PyTorch 框架進行模型訓練引入的 torchvision 圖像處理庫
在算法開發階段,出于訓練考慮,算法工程師可能會優先使用 torchvision 來完成圖像處理操作。然而在模型部署階段,負責模型部署的工程師通常會使用 C++ 作為開發語言,沒有辦法使用 torchvision 完成圖像處理操作,那么可能會使用其他的 C++ 圖像處理庫,比如 OpenCV,然而這就涉及到,torchvision 和 OpenCV 結果對齊的問題。此外,與使用 OpenCV 的情況類似,torchvision 中的算子也有不支持 GPU 加速,或者 GPU 加速效果不佳的情況。
CV-CUDA 特點
如上所述,傳統的圖像預處理操作一般在 CPU 上進行,一方面會占用大量的 CPU 資源,使得 CPU 和 GPU 的負載不均衡;另一方面由于基于 CPU 的圖像加速庫不支持 batch 操作,導致預處理的效率低下。為了解決當前主流的圖像處理庫所存在的一些問題,NVIDIA 和字節跳動的機器學習團隊聯合開發了基于 GPU 的圖像處理加速庫 CV-CUDA,并擁有以下特點:
(1)Batch
支持 batch 操作,可以充分利用 GPU 高并發、高吞吐的并行加速特性,提升計算效率和吞吐率。
(2)Variable Shape
支持同一 batch 中圖片尺寸各不相同,保證了使用上的靈活性。此外,在對圖片進行處理時,可以對每張圖片指定不同的參數。例如調用 RotateVarShape 算子時,可以對 batch 中每張圖片指定不同的旋轉角度。
在部署機器學習算法時需要對齊訓練和推理流程。一般來說,訓練時利用 python 進行快速驗證,推理時利用 C++ 進行高性能部署,然而一些圖像處理庫僅支持 python,這給部署帶來了極大的不便。如果在訓練和推理采用不同的圖像處理庫,則又需要在推理端重新實現一遍邏輯,過程會非常繁瑣。
CV-CUDA 提供了 C、C++ 和 Python 接口,可以同時服務于訓練和推理場景。從訓練遷移到推理場景時,也可免去繁瑣的對齊流程,提高部署效率。
(4)獨立算子設計
CV-CUDA 作為基礎圖像處理庫,采用了獨立算子設計,不需要預先定義流水線。獨立算子的設計具有更高的靈活性,使調試變得更加的容易,而且可以使其與其他的圖像處理交互,或者將其集成在用戶自己的圖像處理上層框架中。
(5)結果對齊 OpenCV
不同的圖像處理庫由于對一些算子的實現方式不一致導致計算結果難以對齊。例如常見的 Resize 操作,OpenCV、OpenCV-gpu 以及 torchvision 的實現方式都不一樣,計算結果存在差異。因此如果在訓練時用 OpenCV CPU 版本而推理時若要采用 GPU 版本或其他圖像處理庫,就會面臨結果存在誤差的問題。
在設計之初,我們考慮到當前圖像處理庫中,很多用戶習慣使用 OpenCV 的 CPU 版本,因此在設計算子時,不管是函數參數還是圖像處理結果上,盡可能對齊 OpenCV CPU 版本的算子。當用戶從 OpenCV 遷移到 CV-CUDA 時,只需做少許改動便可使用,且圖片處理結果和 OpenCV 一致,不需要重新訓練模型。
(6)易用性
CV-CUDA 提供了 Image、ImageBatchVarShape 等結構體,方便用戶的使用。同時還提供了 Allocator 類,用戶可以自定義顯存分配策略(例如用戶可以設計顯存池分配策略來提高顯存分配速度),方便上層框架集成和管理資源。目前 CV-CUDA 提供了 PyTorch、OpenCV 和 Pillow 的數據轉化接口,方便用戶進行算子替換和進行不同圖像庫之間的混用。
(7)針對不同 GPU 架構的性能高度優化
CV-CUDA 可以支持 Volta、Turing、Ampere 等 GPU 架構,并針對不同架構 GPU 的特點,在 CUDA kernel 層面進行了性能上的高度優化,可在云服務場景中規模化部署。
算子數量及其性能
(1) CV-CUDA 目前提供了 50 多種算子
包括常用的 CvtColor、Resize、Crop、PadStack、Normalize 等。當前算子能夠覆蓋大部分應用場景,后續將會支持更多算子。
算子清單:

圖 4. CV-CUDA 支持算子清單
(2) 性能對比
在本文開頭的背景模糊算法里,采用 CV-CUDA 替代 OpenCV 和 TorchVision 的前后處理后,整個推理流程的吞吐率提升了 20 倍以上。下圖展示了在同一個計算節點上(2x Intel Xeon Platinum 8168 CPUs,1x NVIDIA A100 GPU),以 30fps 的幀率處理 1080p 視頻,采用不同的 CV 庫所能支持的最大的并行流數。測試采用了 4 個進程,每個進程 batchSize 為 64。
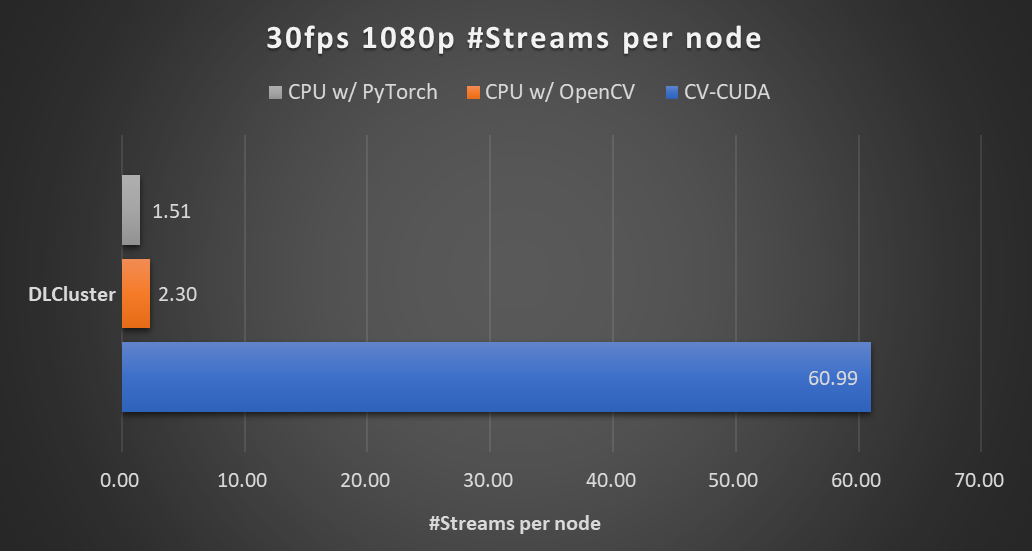
圖 5. AI 背景模糊(2x Intel Xeon Platinum 8168 CPUs , 1x NVIDIA A100 GPU)
其中涉及到的前處理操作有:
Resize (Downscale)、Padding、Convert Data Type、Normalize 及 Image to Tensor
涉及到的后處理操作有:
Tensor to Mask、Convert Data Type、Crop、Resize (Upscale)、Bilateral Filter (Denoise)、Gaussian Blur 及 Composite
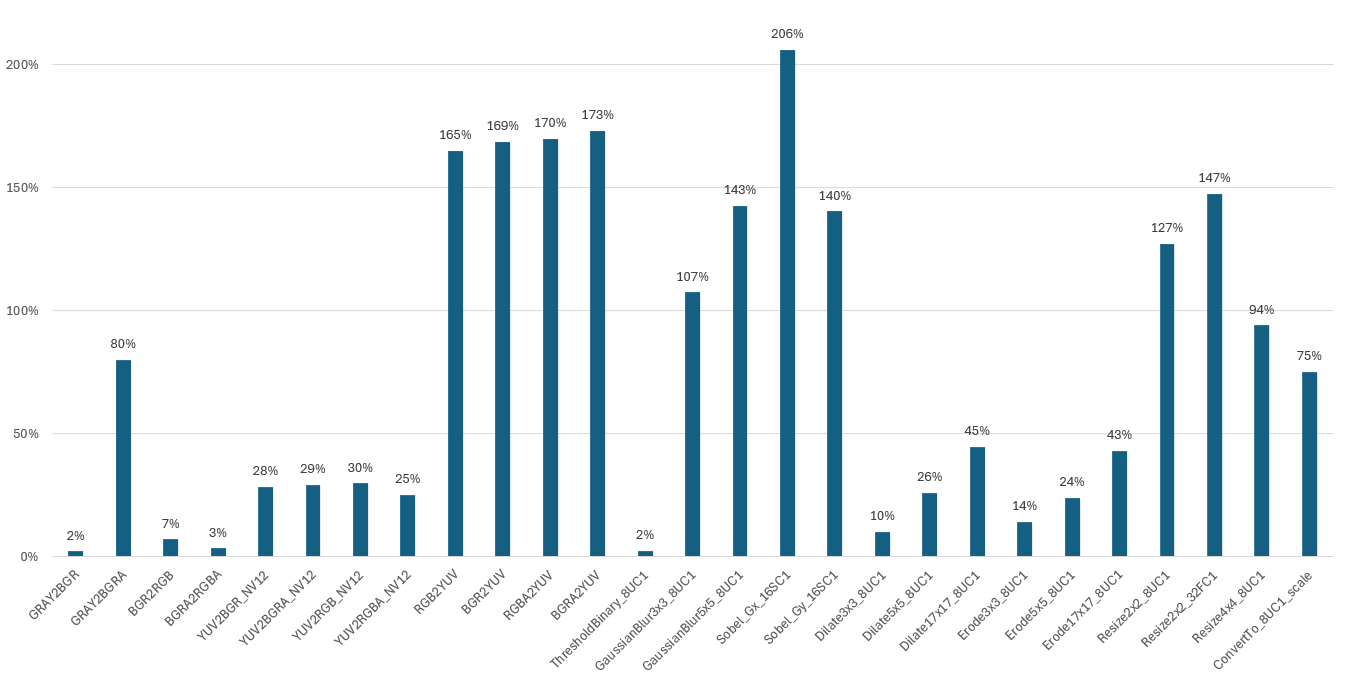
對于單個算子的性能,我們也做了性能測試,下圖的測試場景選用的圖片大小為 480*360,CPU 選擇為 Intel(R) Core(TM) i9-7900X,BatchSize 大小為 1,進程數為 1。
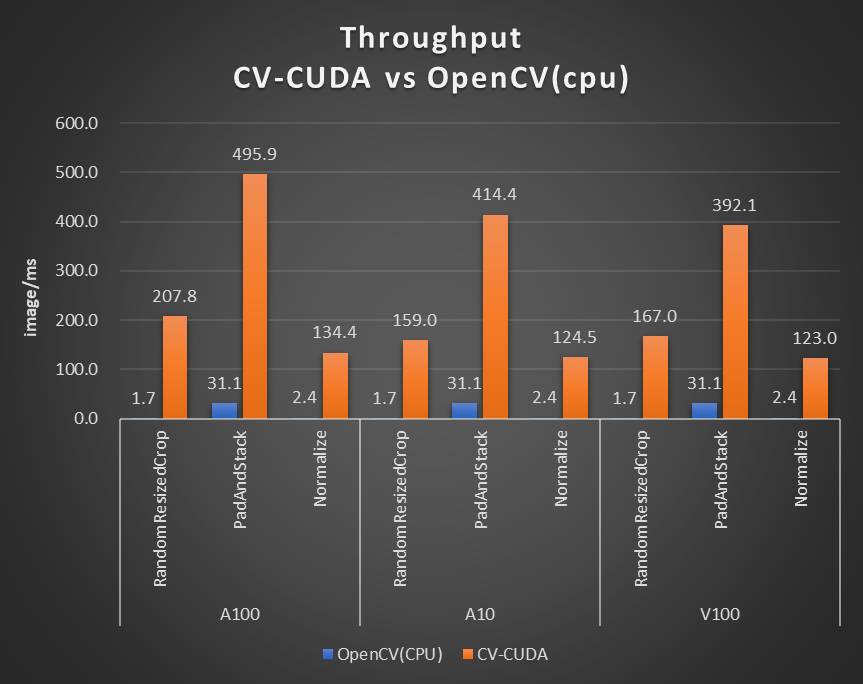
圖 6. CV-CUDA 性能對比(CPU: Intel(R) Core(TM) i9-7900X CPU @ 3.30 GHz)
性能優化手段及例子
為了使 CV-CUDA 能夠更加高效的運行在 GPU 上,我們采取了一系列的優化手段。
(1)kernel 融合
采用了大量的 kernel 融合策略,減少了 kernel launch 和 global memory 的訪問時間。
(2)訪存優化
采用了合并訪存,向量化讀寫,shared memory 等策略,提高了數據讀寫的效率。
(3)異步處理
CV-CUDA 中所有算子均采用異步處理的方式,可以減少同步帶來的等待耗時。
(4)高效計算
采用了 fast math、warp/block reduce、table lookup 等優化手段,可以有效提升計算效率。
(5)預分配顯存
CV-CUDA 采用了預分配顯存策略,并且提供了 Allocator 類,幫助使用者自定義顯存分配策略或者可采取默認的顯存分配策略。算子所需要的 buffer 和圖片顯存會在初始化階段分配好,而在執行階段不會再進行耗時的顯存分配操作。
框架和 API
(1)CV-CUDA 整體架構
整個 CV-CUDA 庫包含了以下幾個組成部分
a. CV-CUDA 核心模塊
核心模塊包含了 C/C++ 和 Python API、NVCV 模塊,Operator 算子模塊以及 CV-CUDA Tools。
b. CV-CUDA Interop 模塊
這個模塊包含了和其他圖像處理庫以及推理框架的交互接口,目前支持 OpenCV、Pytorch 和 Pillow,后續將陸續加入其他圖像處理庫的交互接口。
c. CV-CUDA Tools/Tests
包含一些單元測試模塊和工具函數
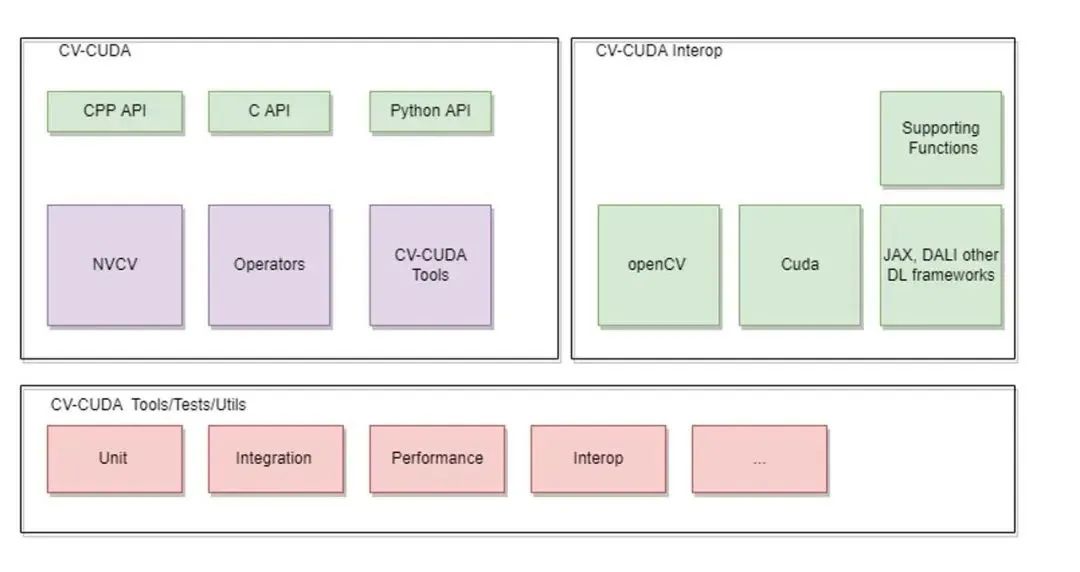
圖 7. CV-CUDA 整體架構
(2)CV-CUDA 核心模塊
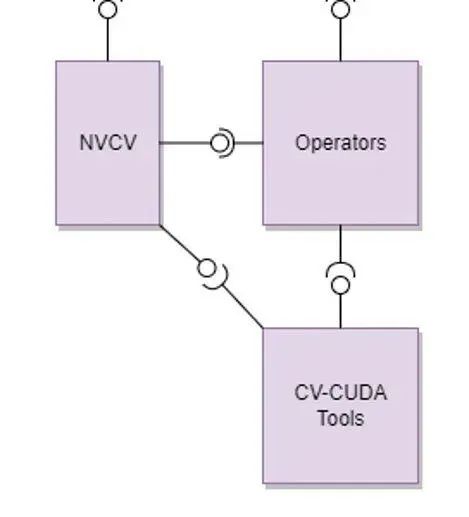
圖 8. CV-CUDA 核心模塊
核心模塊包含以下幾個部分
a. NVCV 核心支持庫
包含 Image 抽象類、Memory workspace 類、Allocator 和 Batch/VarShapeBatch 類
b. Operators CV 算子
包含了各種獨立算子(resize、filter 等等)
c. CV-CUDA Tools
包含了用于開發算子所需的各種功能函數
(3)API
圖 9. ImageBatchVarShape
圖 10. Resize
字節跳動機器學習團隊應用案例
最初,CV-CUDA 項目的啟動,主要目的是為了解決內部模型訓練和推理過程中預處理瓶頸問題。以模型訓練為例,正如大家所熟知的,傳統的數據讀取和預處理過程都是由 CPU 完成的。當 CPU 多核算力足夠時,能為模型訓練提供穩定高效的數據,但當 CPU 算力不足時,數據準備過程即會成為瓶頸,從而導致 GPU 利用率低下,造成 GPU 資源的浪費。一直以來,工業界有不少模型的訓練推理過程,都存在因為 CPU 資源競爭而影響著性能的問題。這個問題在圖像類模型,尤其是針對圖像有比較復雜的預處理的場景中尤為明顯。而隨著 GPU 算力的不斷提升,CPU 資源競爭將會越來越凸顯出來。為了解決這個問題,非常樸素的一個想法是,將造成 CPU 算力不足的預處理邏輯搬到 GPU 上來進行,利用 GPU 龐大的算力,來高效的產生模型所需的數據。
但我們對這個 GPU 預處理算子庫顯然是有要求的。首先是性能需要足夠好,如果預處理部分 GPU kernel 的實現跑起來非常慢,可能反而得不償失;其次預處理搬到 GPU 上做,對模型迭代本身的影響要小,我們的預期是預處理 kernel 是見縫插針似的,在模型迭代過程中僅用一點點 GPU 閑散資源即可;最后,預處理 kernel 需要支持定制化,字節跳動機器學習團隊內部訓練的模型多,需要的預處理邏輯也多種多樣,因此有許多定制的預處理邏輯需求。而 CV-CUDA 就很好的滿足了以上幾點的要求:每個 op 支持 batch 數據輸入的設計,減少了頻繁 Kernel launch 的開銷,保證了高效的運行性能;每個 op 都支持 stream 對象和顯存指針的傳入,使得我們能更加靈活的配置相應的 GPU 資源;每個 op 設計開發時,既兼顧了通用性,也能按需提供定制化接口,能夠覆蓋內部的圖片類預處理需求。
CV-CUDA 目前在抖音集團內部的多個線上線下場景得到了應用,比如搜索多模態,圖片分類等,下面分模型訓練和推理分別介紹一個典型應用。(模型相關的細節這里就不多做介紹了,主要展示下 CV-CUDA 的應用場景和獲得的收益。)
(1)模型訓練
在字節跳動機器學習團隊內部,CV-CUDA 在預處理邏輯復雜的訓練任務上加速效果明顯。在模型訓練過程中,數據準備和模型迭代是個異步的過程,數據準備只要不比模型迭代來的慢,其性能就是滿足需求的。但隨著新一代強力 GPU 的投入使用,模型本身的計算時間被進一步縮短,因而對數據準備的性能要求越來越高。此時預處理邏輯一復雜,CPU 競爭就會變得激烈,這個時候 CV-CUDA 就能發揮很大的作用。
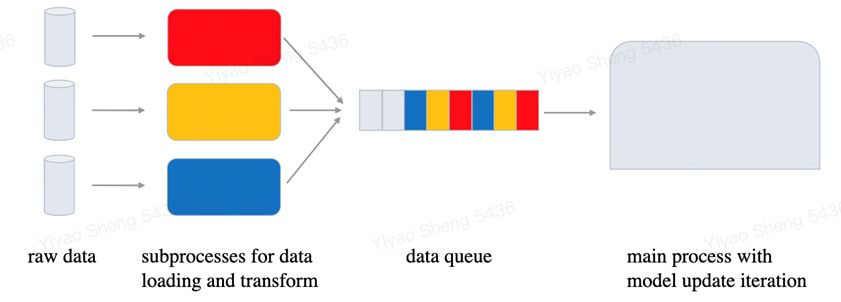
圖 11. 模型訓練流程示意圖
字節跳動機器學習團隊某個視頻相關的多模態任務,CV-CUDA 應用后就獲得了不小的性能收益。該任務預處理部分邏輯很復雜,既有多幀視頻的解碼,也有很多的數據增強,導致在 A100 上多卡訓練時 CPU 資源競爭非常明顯,因而雖然已經充分利用了 CPU(Intel Xeon Platinum 8336C)的多核性能,但數據預處理的速度仍然滿足不了模型計算的需求。而使用了 CV-CUDA,預處理邏輯被全部遷移到了 GPU,相應的訓練瓶頸也由數據預處理轉移到了模型計算本身,從而在模型訓練的整體性能上我們獲得了近 90% 的收益。另一個獲得收益的 OCR 任務也十分相似,其預處理鏈路有十幾個算子,使用 CV-CUDA 后我們在 V100 上訓練即獲得了 80% 的加速。
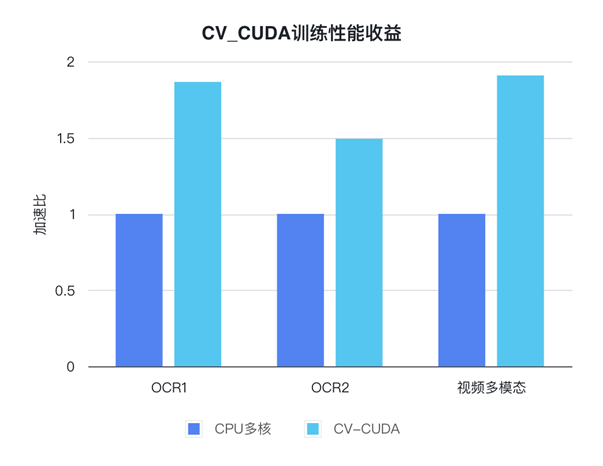
圖 12. CV-CUDA 訓練性能收益
需要注意的是,前后處理耗時占比不同的應用在使用 CV-CUDA 后帶來的收益提升會有所差異。例如前后處理耗時占比為 50% 的應用,使用 CV-CUDA 后,端到端吞吐率提升的理論上限為原始的 2 倍(理論上限是指預處理耗時為 0,端到端中模型的耗時占比為 100%,實際上前后處理加速后,依然會有耗時,因此理論上限僅用于分析理想情況能達到的最大加速比);而前后處理占比 90% 以上的應用,使用 CV-CUDA 后的吞吐率提升理論上限為原始的 10 倍以上。此外,CPU 性能的差異也會影響到最終的加速效果。
(2) 模型推理
模型推理和訓練略有不同:因為模型訓練時數據讀取和模型更新是異步的,所以基本上提升模型訓練性能可以與提高 GPU 利用率劃等號。但模型推理過程,數據讀取和模型計算是一個串行的過程,加速數據準備過程本身即會對整體性能造成直接影響。再加上模型推理時只涉及到模型前向的計算,計算量一般都較小,GPU 通常有足夠的剩余資源來進行其他的工作。因而模型推理階段,把預處理邏輯搬到 GPU 上來加速性能,既合理而又有可行性。

圖 13. 模型推理流程示意圖
字節跳動機器學習團隊的某個搜索多模態任務,在使用 CV-CUDA 之后,整體的上線吞吐相比于用 CPU 做預處理時有了 2 倍多的提升,值得一提的是,這里的基線本身即是經過 CPU(Intel Xeon Platinum 8336C)多核等方式優化過后的結果,雖然涉及到的預處理邏輯較簡單,但使用 CV-CUDA 之后加速效果依然非常明顯。
附錄
(1)開源計劃
(2)代碼示例
以圖片分類為例,以下代碼展示了如何利用 CV-CUDA 對圖片進行預處理,以及如何和 Pytorch 進行交互。
流程圖:

Python 代碼:
import torch
from torchvision import models
from torchvision.io.image import read_file, decode_jpeg
import numpy as np
# Import CV-CUDA module
import nvcv
"""
Image Classification python sample
The image classification sample uses Resnet50 based model trained on Imagenet
The sample app pipeline includes preprocessing, inference and post process stages
which takes as input a batch of images and returns the TopN classification results
of each image.
This sample gives an overview of the interoperability of pytorch with CVCUDA
tensors and operators
"""
# Set the image and labels file
filename = "./assets/tabby_tiger_cat.jpg"
labelsfile = "./models/imagenet-classes.txt"
# Read the input imagea file
data = read_file(filename) # raw data is on CPU
# NvJpeg can be used to decode the image
# to the necessary color format on the device
inputImage = decode_jpeg(data, device="cuda") # decoded image in on GPU
imageWidth = inputImage.shape[2]
imageHeight = inputImage.shape[1]
# decode_jpeg is currently limited to batchSize 1
# and Planar format (CHW)
# A torch tensor can be wrapped into a CV-CUDA Object using the "as_tensor"
# function in the specified layout. The datatype and dimensions are derived
# directly from the torch tensor.
nvcvInputTensor = nvcv.as_tensor(inputImage, "CHW")
# The input image is now ready to be used
# The Reformat operator can be used to convert CHW format to NHWC
# for the rest of the preprocessing operations
nvcvInterleavedTensor = nvcvInputTensor.reformat("NHWC")
"""
Preprocessing includes the following sequence of operations.
Resize -> DataType Convert(U8->F32) -> Normalize(Apply mean and std deviation)
-> Interleaved to Planar
"""
# Model settings
layerHeight = 224
layerWidth = 224
batchSize = 1
# Resize
# Resize to the input network dimensions
nvcvResizeTensor = nvcvInterleavedTensor.resize(
(batchSize, layerWidth, layerHeight, 3), nvcv.Interp.CUBIC
)
# Convert to the data type and range of values needed by the input layer
# i.e uint8->float. A Scale is applied to normalize the values in the range 0-1
nvcvConvertTensor = nvcvResizeTensor.convertto(np.float32, scale=1 / 255)
"""
The input to the network needs to be normalized based on the mean and
std deviation value to standardize the input data.
"""
# Create a torch tensor to store the mean and standard deviation values for R,G,B
scale = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
scaleTensor = torch.Tensor(scale)
stdTensor = torch.Tensor(std)
# Reshape the the number of channels. The R,G,B values scale and offset will be
# applied to every color plane respectively across the batch
scaleTensor = torch.reshape(scaleTensor, (1, 1, 1, 3)).cuda()
stdTensor = torch.reshape(stdTensor, (1, 1, 1, 3)).cuda()
# Wrap the torch tensor in a CV-CUDA Tensor
nvcvScaleTensor = nvcv.as_tensor(scaleTensor, "NHWC")
nvcvBaseTensor = nvcv.as_tensor(stdTensor, "NHWC")
# Apply the normalize operator and indicate the scale values are std deviation
# i.e scale = 1/stddev
nvcvNormTensor = nvcvConvertTensor.normalize(
nvcvBaseTensor, nvcvScaleTensor, nvcv.NormalizeFlags.SCALE_IS_STDDEV
)
# The final stage in the preprocess pipeline includes converting the RGB buffer
# into a planar buffer
nvcvPreprocessedTensor = nvcvNormTensor.reformat("NCHW")
# Inference uses pytorch to run a resnet50 model on the preprocessed input and outputs
# the classification scores for 1000 classes
# Load Resnet model pretrained on Imagenet
resnet50 = models.resnet50(pretrained=True)
resnet50.to("cuda")
resnet50.eval()
# Run inference on the preprocessed input
torchPreprocessedTensor = torch.as_tensor(nvcvPreprocessedTensor.cuda(), device="cuda")
inferOutput = resnet50(torchPreprocessedTensor)
"""
Postprocessing function normalizes the classification score from the network and sorts
the scores to get the TopN classification scores.
"""
# top results to print out
topN = 5
# Read and parse the classes
with open(labelsfile, "r") as f:
classes = [line.strip() for line in f.readlines()]
# Apply softmax to Normalize scores between 0-1
scores = torch.nn.functional.softmax(inferOutput, dim=1)[0]
# Sort output scores in descending order
_, indices = torch.sort(inferOutput, descending=True)
# Display Top N Results
[
print("Class : ", classes[idx], " Score : ", scores[idx].item())
for idx in indices[0][:topN]
]
關于作者

張毅 | NVIDIA GPU 計算專家團隊的工程師
主要從事計算機視覺領域的算法加速工作,同時也是 CV-CUDA 項目的發起人,負責 CV-CUDA 項目早期的框架設計和算子開發工作。此外,他還是 PyTorch 轉 TensorRT 編譯工具 Torch-TensorRT 的核心開發人員。在加入 NVIDIA 之前,于騰訊優圖從事計算機視覺算法研發工作。分別于浙江大學和上海交通大學獲得學士和碩士學位。

郭若乾 | NVIDIA GPU 計算專家團隊的工程師
于浙江大學取得碩士學位后,他在 2020 年加入 NVIDIA,主要從事計算機視覺領域的算法加速工作,以及 PyTorch 模型轉 TensorRT 編譯工具 Torch-Tensor 的開發工作。作為 CV-CUDA 項目的主要開發人員,負責了 CV-CUDA 項目背景調研以及早期算子的開發優化工作。

盛一耀 | 字節跳動機器學習系統團隊工程師
他是 CV-CUDA 項目主要的開發者之一。他于美國卡耐基梅隆大學獲得碩士學位后,2019 年加入字節跳動,主要從事機器學習系統相關工作,對模型訓練和推理性能優化有較深刻的理解。在 CV-CUDA 項目中,他在把握并提供字節跳動內部視覺相關算子需求的同時,也參與開發了許多 GPU 視覺類算子。
原文標題:CV-CUDA 高性能圖像處理加速庫
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3748瀏覽量
90836
原文標題:CV-CUDA 高性能圖像處理加速庫
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
摩爾線程開源高性能線性代數模板庫MUTLASS
AI高性能計算平臺是什么
XCVU9P 板卡設計原理圖:616-基于6U VPX XCVU9P+XCZU7EV的雙FMC信號處理板卡 高性能數字計算卡
怎么在TMDSEVM6678: 6678自帶的FFT接口和CUDA提供CUFFT函數庫選擇?
利用NVIDIA RAPIDS加速DolphinDB Shark平臺提升計算性能
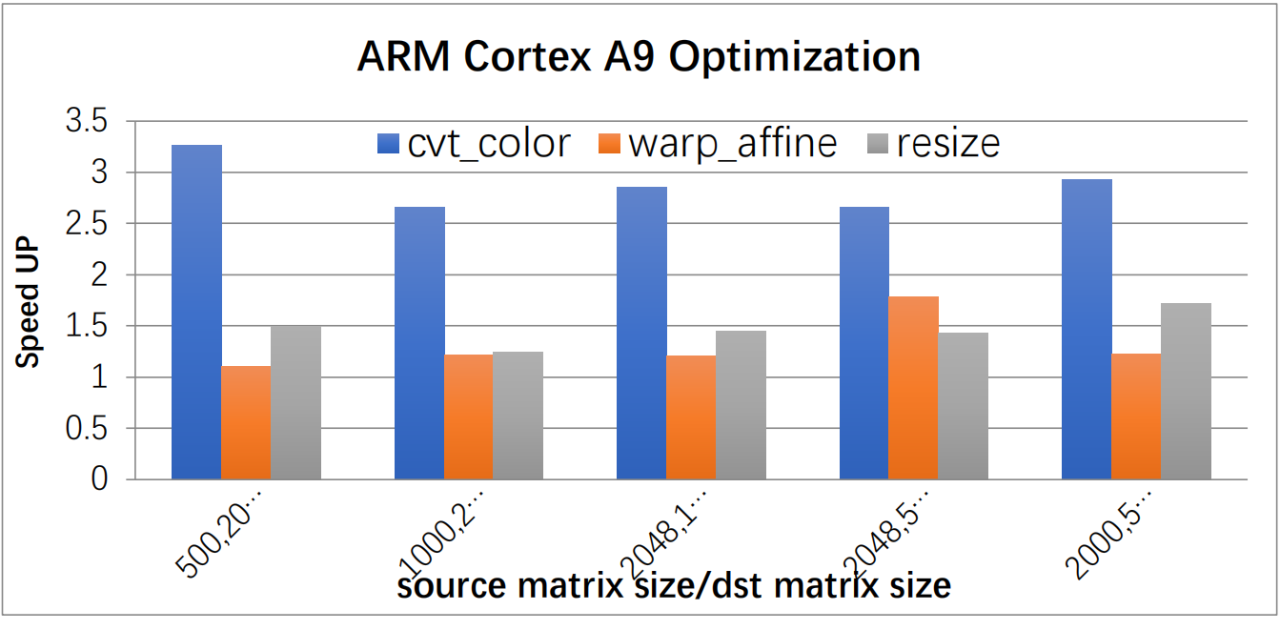
使用Arm KleidiCV開源庫加速圖像處理性能
澎峰科技高性能計算庫PerfIPP介紹
OpenCV圖像識別C++代碼
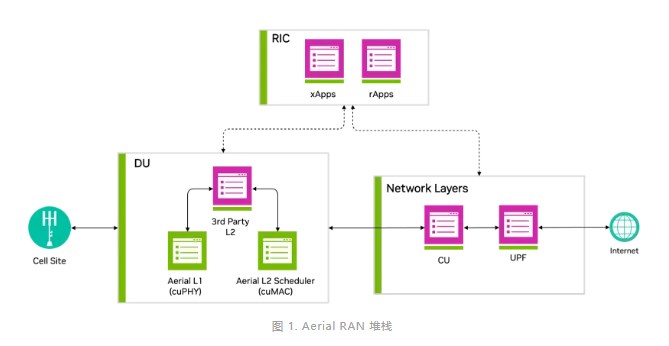
借助NVIDIA Aerial CUDA增強5G/6G的DU性能和工作負載整合
基于FPGA的實時邊緣檢測系統設計,Sobel圖像邊緣檢測,FPGA圖像處理
NVIDIA 通過 CUDA-Q 平臺為全球各地的量子計算中心提供加速

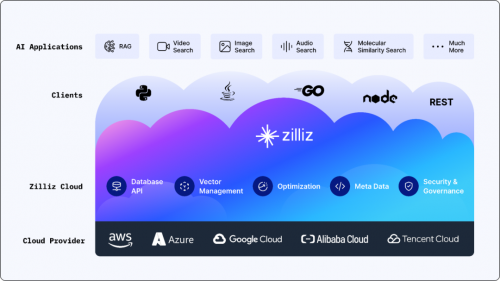
搭載英偉達GPU,全球領先的向量數據庫公司Zilliz發布Milvus2.4向量數據庫





 工商網監
工商網監
評論