 Google的深度學習框架TensorFlow的優勢分析
Google的深度學習框架TensorFlow的優勢分析
1、Scalar、Vector、Marix、Tensor,點線面體一個都不少
我們先從點線面體的視角形象理解一下。點,標量(scalar);線,向量(vector);面,矩陣(matrix);體,張量(tensor)。我們再詳細看一下他們的定義
Scalar定義:標量是只有大小、沒有方向的“量”。一個具體的數值就能表征,如重量、溫度、長度等。
Vector定義:向量是即有大小、又有方向的“量”。由大小和方向共同決定,如力、速度等。
Matrix定義:矩陣是一個“按照長方陣列排列”的數組,而行數與列數都等于N的矩陣稱為N階矩陣,在卷積核中我們常用3x3或5x5矩陣。
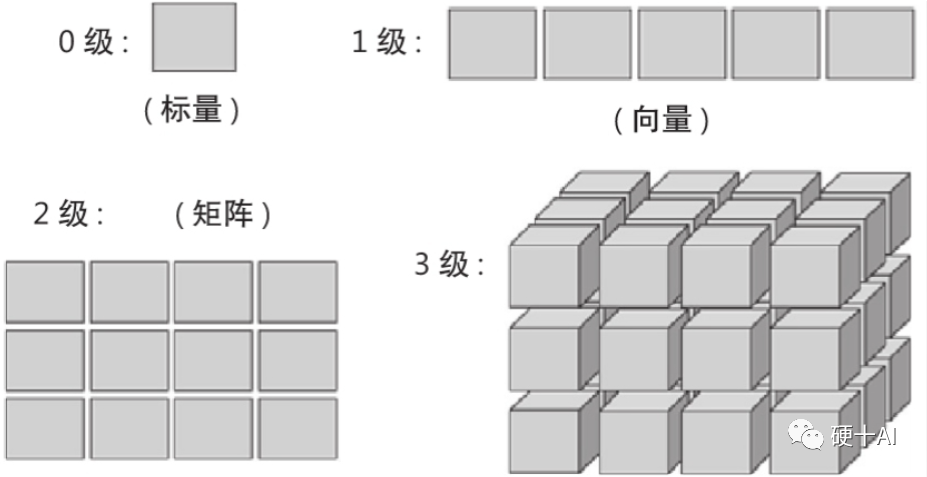
Tensor定義:張量是一個“維度很多”的數組,它創造出了更高維度的矩陣、向量,在深度學習知識域的術語中張量也可解釋為數學意義的標量、向量和矩陣等的抽象。即標量定義為0級張量,向量定義為1級張量,矩陣定義為2級張量,將在三維堆疊的矩陣定義為3級張量,參考下圖。
2、深度學習依賴Tensor運算,GPU解決了算力瓶頸(1)卷積網絡神經中有海量的矩陣運算,包括矩陣乘法和矩陣加法 參考機器學習中的函數(4) - 全連接限制發展,卷積網絡閃亮登場卷積神經網絡(CNN)作為是實現深度學習的重要方法之一,整個網絡第一步就是應用卷積進行特征提取,通過幾輪反復后獲得優質數據,達成改善數據品質的目標,我們一起復習一下卷積層工作的這兩個關鍵步驟。
首先,進行圖像轉換:先把我們眼中的“圖像”變成計算機眼中的“圖像”。

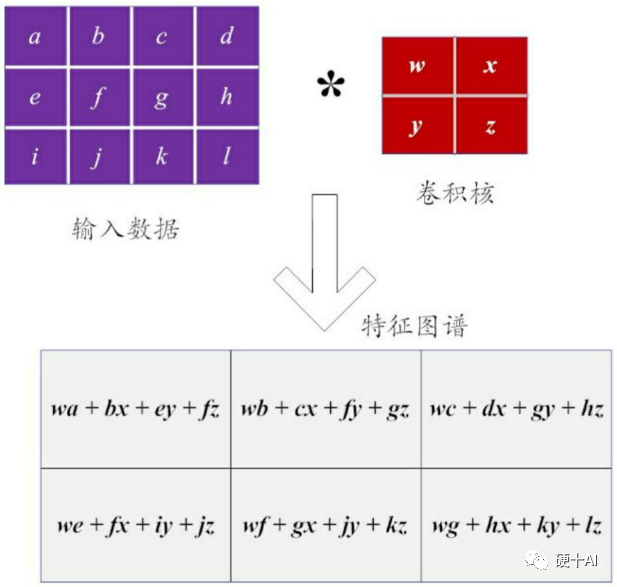
下一步,選擇一個卷積核進行“濾波”:假設以一個2×2的小型矩陣作為卷積核,這樣的矩陣也被稱為“濾波器”。如果把卷積核分別應用到輸入的圖像數據矩陣上(如上圖計算機眼中的貓),執行卷積運算得到這個圖像的特征圖譜(Feature Map)。從下圖體現看到,圖像的特性提取本質上就是一個線性運算,這樣的卷積操作也被稱為線性濾波。
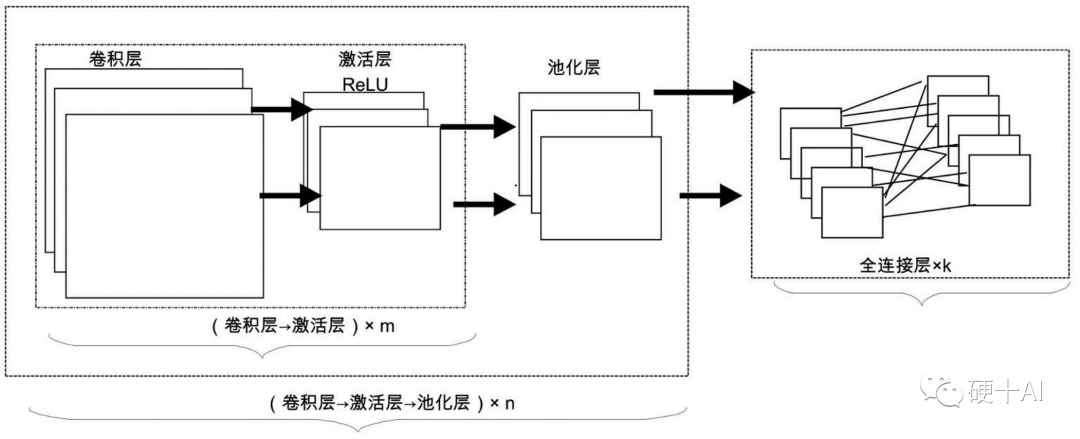
2012年,辛頓(Hinton)和他的博士生(Alex Krizhevsky)等提出了經典的Alexnet,它強化了典型CNN的架構,這個網絡中卷積層更深更寬,通過大量的”卷積層->激活層->池化層”的執行過程提純數據,因此在這個網絡中有海量的矩陣運算,包括矩陣乘法和矩陣加法。
(2)應用GPU解決算力瓶頸,Tensor是最基礎的運算單元
Alexnet之所以是經典中的經典,除了它強化了典型CNN的架構外,還有其它創新點,如首次在CNN中應用了ReLU激活函數、Dropout機制,最大池化(Max pooling)等技術等。還有一點特別重要,Alexnet成功使用GPU加速訓練過程(還開源了CUDA代碼),上世紀90年代限制Yann LeCun等人工智能科學家的計算機硬件“算力瓶頸”被逐步打開。
深度學習為什么需要GPU呢?因為只有GPU能夠提供“暴力計算”能力,降低訓練時間。大家都知道,GPU處理器擁有豐富的計算單元ALU,它相對于CPU處理器架構的優勢就在于能執行“并行運算”,參考下圖中的一個簡單的矩陣乘法就是矩陣某一行的每一個數字,分別和向量的每一個數字相乘之后再相加,這就是并行運算。
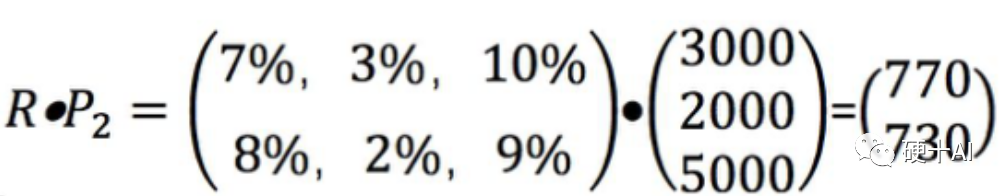
而如剛才討論的深度學習中的運算大部分都是矩陣運算,讓計算從“單個的”變成“批處理的”,充分利用GPU的資源。而Tensor是專門針對GPU來設計的,Tensor作為一個可以運行在GPU上的多維數據,加速運算速度,提升運算效率。參考深度學習靠框架,期待國產展雄風中的討論,在一個框架中,必須有“張量對象”和“對張量的計算”作基礎,TensorFlow、PyTorch等等主流框架中,張量Tensor都是最基礎的運算單元。
3、提升Tensor效率,大家各顯神通 現在主要的GPU廠家為了能夠提高芯片在AI、HPC等應用場景下的加速能力,都在芯片計算單元的設計上花大力氣,不斷創新優化。比如AMD的CDNA架構中計算是通過Compute Unit來實現的,在Compute unit中就有Scalar、Vector、Matrix等不同的計算功能模塊,針對不同的計算需求各司其職。Nvidia的計算是通過SM來實現的,SM中計算從Cuda Core發展到Tensor Core,針對Tensor的計算效率越來越高,到今年三月份發布的H100系列中,Tensor Core已經發展到了第四代。而Google干脆就把自己的芯片定義為TPU(Tensor processing Unit),充分發揮Tensor加速能力,其中主要的模塊就是海量的矩陣乘法單元。(1)英偉達的Tensor Core 今年3月份黃教主穿著皮衣發布了H100(Hopper系列),Nvidia每一代GPU都是用一個大神的名字命名,這個系列是向Grace Hopper致敬,她被譽為計算機軟件工程***、編譯語言COBOL之母。她也被譽為是計算機史上第一個發現Bug的人,有這樣一個故事,1947年9月9日當人們測試Mark II計算機時,它突然發生了故障。經過幾個小時的檢查后,工作人員發現了一只飛蛾被打死在面板F的第70號繼電器中,飛蛾取出后,機器便恢復了正常。當時為Mark II計算機工作的女計算機科學家Hopper將這只飛蛾粘帖到當天的工作手冊中,并在上面加了一行注釋,時間是15:45。隨著這個故事傳開,更多的人開始使用Bug一詞來指代計算機中的設計錯誤,而Hopper登記的那只飛蛾看作是計算機里上第一個被記錄在文檔中的Bug,以后debug(除蟲)變成了排除故障的計算機術語。

讓我們回到英偉達GPU的計算單元設計,Nvidia的9代GPU中計算單元架構演進過程如下,Tesla2.0(初代)-> Fermi(Cuda core提升算力)-> Kepler(core數量大量增長)-> Maxwell(Cuda core結構優化)-> Pascal(算力提升)-> Volta(第一代Tensor core提出,優化對深度學習的能力) -> Turning(第二代Tensor core)-> Ampere(第三代Tensor core)-> Hopper(第四代Tensor core),其中從Volta開始,每一代Tensor Core的升級都能帶來算力X倍的提升。Tensor core專門為深度學習矩陣運算設計,和前幾代的“全能型”的浮點運算單元CUDA core相比,Tensor core運算場景更有針對性,算力能力更強,下圖就是NV一個計算單元SM中各種模塊的組成,各種類型的計算模塊配置齊全。
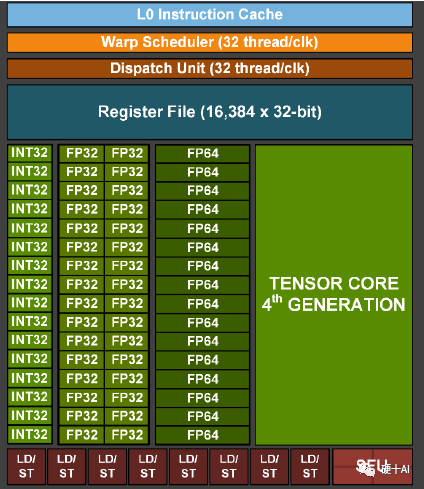
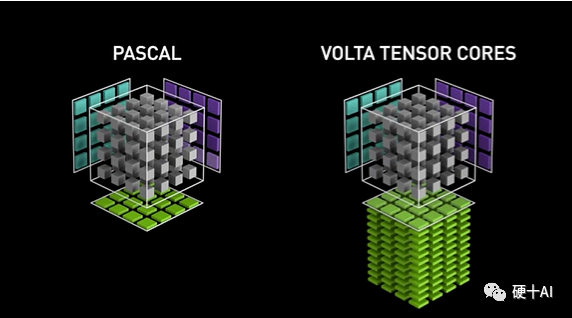
再詳細討論一下Tensor Core,Tensor Core是專為執行張量或矩陣運算而設計的專用執行單元,每個時鐘執行一次矩陣乘法,包含批次的混合精度乘法操作(區別于Cuda core每個時鐘執行單次混合精度的乘加操作),矩陣乘法(GEMM)運算是神經網絡訓練和推理的核心,Tenore Core更加高效。參考下圖(藍色和紫色為輸入,綠色是計算結果,中心的灰色部分就是計算單元),第一代Tencor Core加入Votal后,以4x4 矩陣乘法運算時為例,參考英偉達白皮書上的數據,優化后與前一代的Pascal相比,用于訓練的算力峰值提升了 12 倍,用于推理的算力峰值提升了6 倍。
(2)Google的TPU
2013年,Google意識到數據中心快速增長的算力需求方向,從神經網絡興起開始矩陣乘加成為重要的計算loading,同時商用GPU很貴,也為了降低成本,Google選擇了擼起袖子自己干,定制了Tensor Processing Unit(TPU)專用芯片,發展到現在已經經歷了4代了。
TPU V1:2014年推出,主要用于推理,第一代TPU指令很少,能夠支持矩陣乘法(MatrixMultiple / Convole) 和特定的激活功能(activation)。
TPU V2:2017年推出,可用于訓練,這一代芯片指令集豐富了;提升計算能力,可以支持反向傳播了;內存應用了高帶寬的HBM;針對集群方案提供了芯片擴展能力。
TPU V3:2018年推出,在V2的結構上進一步優化,對各個功能模塊的性能都做了提升。
TPU V4:2022年推出,算力繼續大幅度提升,尤其是集群能力不斷優化后,TPU成為谷歌云平臺上很關鍵的一環。
相信Google會在Tensor processing unit的路徑上繼續加速,對于云大廠來說,這是業務底座。
4、只有硬件是不夠的,TensorFlow讓Tenor流動起來 我們看到了各個廠家在硬件上的不懈努力和快速進步,當然,只有硬件是遠遠不夠的,一個好的Deep Learning Framework才能發揮這些硬件的能力,我們還是從最出名的框架TensorFlow說起。
2011年,Google公司開發了它的第一代分布式機器學習系統DistBelief。著名計算機科學家杰夫·迪恩(Jeff Dean)和深度學習專家吳恩達(Andrew )都是這個項目的成員。通過杰夫·迪恩等人設計的DistBelief,Google可利用它自己數據中心數以萬計的CPU核,建立深度神經網絡。借助DistBelief,Google的語音識別正確率比之前提升了25%。除此之外,DistBelief在圖像識別上也大顯神威。2012年6月,《紐約時報》報道了Google通過向DistBelief提供數百萬份YouTube視頻,來讓該系統學習貓的關鍵特征,DistBelief展示了他的自學習能力。DistBelief作為谷歌X-實驗室的“黑科技”開始是是閉源的,Google在2015年11月,Google將它的升級版實現正式開源(遵循Apache 2.0)。而這個升級版的DistBelief,也有了一個我們熟悉的名字,它就是未來深度學習框架的主角“TensorFlow”。
TensorFlow命名源于其運行原理,即“讓張量(Tensor)流動起來(Flow)”,這是深度學習處理數據的核心特征。TensorFlow顯示了張量從數據流圖的一端流動到另一端的整個計算過程,生動形象地描述了復雜數據結構在人工神經網絡中的流動、傳輸、分析和處理模式。
Google的深度學習框架TensorFlow的有三大優點
形象直觀:TensorFlow有一個非常直觀的構架,它有一個“張量流”,用戶可以借助它的工具(如TensorBoard)很容易地、可視化地看到張量流動的每一個環節。
部署簡單:TensorFlow可輕松地在各種處理器上部署,進行分布式計算,為大數據分析提供計算能力的支撐。
平臺兼容:TensorFlow跨平臺性好,不僅可在Linux、Mac和Windows系統中運行,還可在移動終端下工作。
審核編輯:郭婷
-
Google
+關注
關注
5文章
1757瀏覽量
57414 -
深度學習
+關注
關注
73文章
5492瀏覽量
120976
原文標題:【AI】深度學習框架(1)
文章出處:【微信號:Hardware_10W,微信公眾號:硬件十萬個為什么】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論